
Bagaimana Apache Spark dapat memberikan sayap pada analitik maskapai?
Diterbitkan: 2015-10-30Industri penerbangan global terus berkembang pesat, tetapi profitabilitas yang konsisten dan kuat belum terlihat. Menurut Asosiasi Transportasi Udara Internasional (IATA), industri ini telah melipatgandakan pendapatannya selama dekade terakhir, dari US$369 miliar pada 2005 menjadi diharapkan US$727 miliar pada 2015.

Di sektor penerbangan komersial, setiap pemain dalam rantai nilai — bandara, pabrikan pesawat terbang, pembuat mesin jet, agen perjalanan, dan perusahaan jasa menghasilkan keuntungan yang besar.
Semua pemain ini secara individual menghasilkan volume data yang sangat tinggi karena churn transaksi penerbangan yang lebih tinggi. Mengidentifikasi dan menangkap permintaan adalah kunci di sini yang memberikan peluang lebih besar bagi maskapai penerbangan untuk membedakan diri mereka sendiri. Oleh karena itu, industri Penerbangan dapat memanfaatkan wawasan data besar untuk meningkatkan penjualan dan meningkatkan margin keuntungan.
Data besar adalah istilah untuk kumpulan kumpulan data yang begitu besar dan kompleks sehingga komputasinya tidak dapat ditangani oleh sistem pemrosesan data tradisional atau alat DBMS yang ada.
Apache Spark adalah open source, kerangka kerja komputasi cluster terdistribusi yang dirancang khusus untuk kueri interaktif dan algoritme iteratif.
Abstraksi Spark DataFrame adalah objek data tabular yang mirip dengan dataframe asli R atau paket panda Python, tetapi disimpan di lingkungan cluster.
Menurut survei terbaru Fortunes, Apache Spark adalah teknologi paling populer tahun 2015.
Vendor Hadoop terbesar Cloudera juga mengucapkan Selamat Tinggal kepada Hadoops MapReduce dan Halo untuk Spark .
Apa yang benar-benar memberi Spark keunggulan atas Hadoop adalah kecepatan . Spark menangani sebagian besar operasinya di memori – menyalinnya dari penyimpanan fisik terdistribusi ke memori RAM logis yang jauh lebih cepat. Ini mengurangi jumlah waktu yang digunakan untuk menulis dan membaca ke dan dari hard drive mekanis yang lambat dan kikuk yang perlu dilakukan di bawah sistem Hadoops MapReduce.
Selain itu, Spark menyertakan alat (pemrosesan waktu nyata, pembelajaran mesin, dan SQL interaktif) yang dibuat dengan baik untuk mendukung tujuan bisnis seperti menganalisis data waktu nyata dengan menggabungkan data historis dari perangkat yang terhubung, juga dikenal sebagai Internet of things .
Hari ini, mari kumpulkan beberapa wawasan tentang sampel data bandara menggunakan Apache Spark .
Di blog sebelumnya kami melihat cara menangani data terstruktur dan semi terstruktur di Spark menggunakan API Dataframe baru dan juga membahas cara memproses data JSON secara efisien.
Di blog ini kita akan memahami cara meng-query data di DataFrames menggunakan SQL serta menyimpan output ke filesystem dalam format CSV.
Menggunakan perpustakaan penguraian Databricks CSV
Untuk ini saya akan menggunakan perpustakaan penguraian CSV yang disediakan oleh Databricks , sebuah perusahaan yang didirikan oleh Pembuat Apache Spark dan yang menangani Pengembangan dan distribusi Spark saat ini.
Komunitas Spark terdiri dari sekitar 600 kontributor yang menjadikannya proyek paling aktif di seluruh Apache Software Foundation, badan pengatur utama untuk perangkat lunak sumber terbuka, dalam hal jumlah kontributor.
Pustaka Spark-csv membantu kami mengurai dan mengkueri data csv di percikan. Kita dapat menggunakan perpustakaan ini untuk membaca dan menulis data csv ke dan dari sistem file apa pun yang kompatibel dengan Hadoop.
Memuat data ke dalam Spark DataFrames
Mari kita memuat file input kita ke dalam Spark DataFrames menggunakan perpustakaan parsing spark-csv dari Databricks.
Anda dapat menggunakan perpustakaan ini di shell Spark dengan menentukan –packages com.databricks: spark-csv_2.10:1.0.3
Saat memulai shell seperti yang ditunjukkan di bawah ini:
$ bin/spark-shell –paket com.databricks:spark-csv_2.10:1.0.3
Ingat Anda harus terhubung ke internet, karena paket spark-csv akan diunduh secara otomatis ketika Anda memberikan perintah ini. Saya menggunakan versi spark 1.4.0
Mari buat sqlContext dengan objek SparkContext(sc) yang sudah dibuat
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Sekarang mari kita muat data csv kita dari file airports.csv (airport csv github) yang skemanya seperti di bawah ini
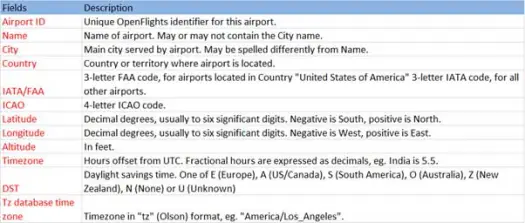
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))Operasi pemuatan akan mengurai file *.csv menggunakan pustaka Databricks spark-csv dan mengembalikan kerangka data dengan nama kolom yang sama seperti pada baris header pertama dalam file.
Berikut ini adalah parameter yang diteruskan ke metode load.
- Sumber : "com.databricks.spark.csv" memberi tahu spark bahwa kami ingin memuat sebagai file csv.
- Pilihan:
- path – path file, di mana ia berada.
- Header : "header" -> "true" memberitahu spark untuk memetakan baris pertama file ke nama kolom untuk dataframe yang dihasilkan.
Mari kita lihat apa skema dari Dataframe kami
Lihat data sampel di kerangka data kami
scala> airportDF.show

Membuat kueri data CSV menggunakan tabel sementara:

Untuk mengeksekusi kueri terhadap tabel, kami memanggil metode sql() pada SQLContext.
Kami telah membuat Airports DataFrame dan memuat data CSV, untuk mengkueri data DF ini kami harus mendaftarkannya sebagai tabel sementara yang disebut airports.
>
scala> airportDF.registerTempTable("airports")
Mari kita cari tahu berapa banyak bandara yang ada di bagian tenggara di dataset kami
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Kami dapat melakukan agregasi dalam kueri sql di Spark
Kami akan mencari tahu berapa banyak kota unik yang memiliki bandara di setiap negara
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Berapa Ketinggian rata-rata (dalam kaki) bandara di setiap Negara?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Sekarang untuk mengetahui di setiap zona waktu berapa banyak bandara yang beroperasi?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Kami juga dapat menghitung garis lintang dan bujur rata-rata untuk bandara-bandara ini di setiap negara
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Mari kita hitung ada berapa DST yang berbeda
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Menyimpan data dalam format CSV
Sampai sekarang kami memuat dan menanyakan data csv. Sekarang kita akan melihat cara menyimpan hasil dalam format CSV kembali ke sistem file.
Misalkan kita ingin mengirim laporan ke klien tentang semua bandara di bagian barat laut semua negara.
Mari kita hitung dulu.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
Dan simpan ke file CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Berikut ini adalah parameter yang dilewatkan untuk menyimpan metode.
- Sumber : sama dengan load method com.databricks.spark.csv yang memberitahu spark untuk menyimpan data sebagai csv.
- SaveMode : Ini memungkinkan pengguna untuk menentukan terlebih dahulu apa yang perlu dilakukan jika jalur keluaran yang diberikan sudah ada. Sehingga data yang ada tidak akan hilang/tertimpa secara tidak sengaja. Anda dapat membuang kesalahan, menambahkan atau menimpa. Di sini, kami telah membuat kesalahan ErrorIfExists karena kami tidak ingin menimpa file yang ada.
- Opsi : Opsi ini sama dengan yang kami berikan untuk memuat metode. Pilihan:
- path – path file, di mana ia harus disimpan.
- Header : "header" -> "true" memberitahu spark untuk memetakan nama kolom dari dataframe ke baris pertama dari file output yang dihasilkan.
Mengonversi format data lain ke CSV
Kami juga dapat mengonversi format data lain seperti JSON, parket, teks ke CSV menggunakan pustaka ini.
Di blog sebelumnya kami telah membuat data json. Anda dapat menemukannya di github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
mari kita simpan sebagai CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Kesimpulan:
Dalam posting ini kami mengumpulkan beberapa wawasan tentang data bandara menggunakan kueri interaktif SparkSQL
dan menjelajahi perpustakaan penguraian csv dari Spark
Blog berikutnya kita akan mengeksplorasi komponen yang sangat penting dari Spark yaitu Spark Streaming.
Spark Streaming memungkinkan pengguna untuk mengumpulkan data waktu nyata ke dalam Spark dan memprosesnya saat itu terjadi dan memberikan hasil secara instan.