
Cara mendapatkan hasil maksimal dari Google Search Console API menggunakan regex
Diterbitkan: 2022-11-02Google Search Console adalah alat luar biasa yang menyediakan data pencarian yang tak ternilai oleh pengguna nyata langsung dari Google. Meskipun bagan dan tabel mudah digunakan, sebagian besar data tidak dapat diakses dari UI.
Satu-satunya cara untuk mendapatkan data tersembunyi ini adalah dengan menggunakan API dan mengekstrak semua data pencarian berharga yang tersedia untuk Anda – jika Anda tahu caranya. Ini dimungkinkan dengan ekspresi reguler.
Inilah cara Anda dapat memaksimalkan Google Search Console API menggunakan ekspresi reguler, menurut Eric Wu, Wakil Presiden Pertumbuhan Produk di Honey, Perusahaan PayPal, yang berbicara di SMX Advanced.
Mendiagnosis masalah SEO dengan GSC
Bekerja di situs web yang mengalami pertumbuhan stagnan atau menurun atau penurunan pembaruan inti?
Sebagian besar profesional SEO beralih ke Google Search Console (GSC) untuk mendiagnosis masalah tersebut.
(Atau jika sumber daya mengizinkan, Anda bahkan dapat menggunakan alat berbayar seperti Ryte atau membangun platform Anda sendiri.)
Untungnya bagi komunitas SEO, tidak ada kekurangan dasbor Looker Studio (sebelumnya Google Data Studio) yang berguna untuk analisis GSC, termasuk:
- Dasbor gratis Aleyda Solis, yang menggunakan data GSC untuk dengan mudah mengidentifikasi potensi perubahan peringkat dalam beberapa hari terakhir dari Pembaruan Google Core.
- Dasbor pemantauan lalu lintas pencarian Google, yang sekarang menarik data lalu lintas Discover dan Google News.
- Studio Penjelajah Search Console milik Hannah Butler. (Dan jika Anda ingin memanipulasi data GSC secara langsung dan menemukan wawasan cepat, Anda dapat menggunakan Lembar Penjelajah Search Console Butler.)
Dasbor memungkinkan SEO untuk melihat ikhtisar tren yang berbeda dibandingkan dengan menggunakan GSC dan melakukan beberapa klik untuk mendapatkan data yang Anda butuhkan.
Tetapi jika Anda menganalisis situs perusahaan, Anda dapat mengalami beberapa hambatan.
- Looker Studio dan Google Sheets memuat dengan lambat, terutama saat Anda berurusan dengan situs besar.
- Antarmuka GSC memiliki batas ekspor 1.000 baris.
- GSC memiliki masalah pengambilan sampel yang sangat besar. Tim SEO perusahaan kehilangan 90% kata kunci GSC mereka, menurut Similar.ai. Dan jika Anda tahu cara mengekstrak data, Anda sebenarnya bisa mendapatkan 14x kata kunci.
Mengatasi masalah pengambilan sampel GSC
Explorer for Search adalah alat lain yang dapat Anda gunakan untuk analisis GSC. Dari Noah Learner dan tim di Two Octobers, ini dibuat dengan pipeline data menggunakan API GSC yang kemudian mengeluarkan data ke BigQuery (pada dasarnya mengabaikan Google Spreadsheet dan mendownload file CSV), lalu memvisualisasikan informasi dengan Data Studio.
Dengan ini, Anda dapat yakin bahwa Anda mendapatkan hampir semua data.
Masih ada peringatan karena masalah pengambilan sampel GSC, terutama untuk situs e-niaga besar dengan banyak kategori berbeda. GSC tidak serta merta menampilkan semua data yang masuk dari direktori tersebut.
Setelah melakukan berbagai pengujian untuk mendapatkan data yang maksimal dari GSC API, tim Similar.ai menemukan cara untuk menutup gap sampling GSC.
Mereka menemukan bahwa dengan menambahkan lebih banyak subdirektori sebagai profil yang berbeda dalam dasbor GSC Anda, Anda dapat mengekstrak lebih banyak data karena Google memberi Anda lebih banyak informasi di tingkat yang lebih rendah itu.
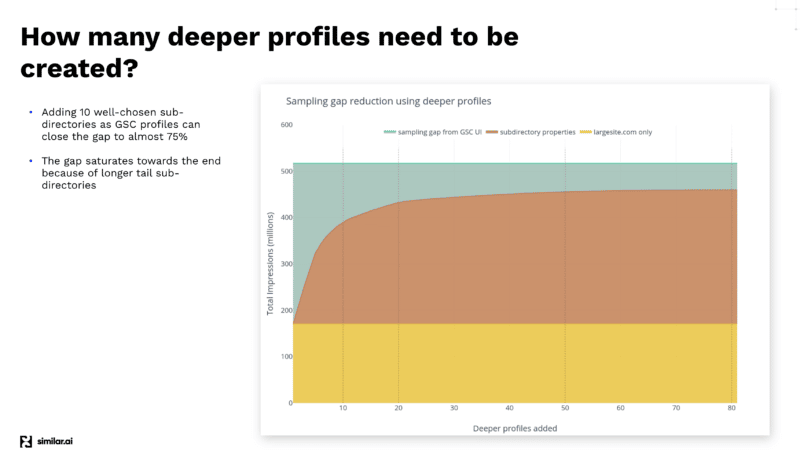
Misalnya, jika Anda melihat example.com/televisions dan Anda menambahkan "televisi" sebagai subdirektori di profil GSC Anda, Google hanya akan memberi Anda kata kunci dan informasi klik untuk subdirektori itu dan seterusnya.
Dan dengan menambahkan banyak subdirektori yang berbeda ini, Anda dapat mengekstrak lebih banyak informasi.
Itu memecahkan masalah pengambilan sampel, tetapi Anda bisa mendapatkan lebih banyak data dengan menggunakan ekspresi reguler.
Mendapatkan lebih banyak data GSC dengan ekspresi reguler
Ekspresi reguler, atau regex, adalah alat yang ampuh untuk memahami data Anda.
Pada April 2021, Google menambahkan dukungan regex ke GSC – memberi SEO lebih banyak cara untuk memotong dan memotong data pencarian organik.
Sering kali, data tidak berguna kecuali Anda dapat memahaminya. Dan regex membantu mengekstrak wawasan yang dapat ditindaklanjuti dari data kaya GSC.
Tapi sekuat mungkin, regex bisa sulit untuk dipelajari.
Tempat terbaik untuk memahami dan mendalami ekspresi reguler adalah dokumentasi resmi Google di GitHub. (Google menggunakan RE2 dalam produknya, yang merupakan cita rasa dari ekspresi reguler.)
Meskipun regex tersedia dalam semua jenis bahasa pemrograman yang berbeda, Anda akan menemukannya hampir di mana-mana bahkan bagi mereka yang memodifikasi file .htaccess.
Dalam beberapa bagian berikutnya adalah kasus penggunaan untuk memanfaatkan regex untuk GSC.
Kueri informasi regex
Saat melihat kueri penelusuran informasi aktual di GSC, Anda biasanya ingin memahami:
- Bagaimana sebenarnya orang-orang datang ke situs Anda?
- Pertanyaan apa yang mereka ambil?
Melihat hal-hal itu dari sudut pandang satu kali, dalam GSC bisa jadi sulit.
Anda selalu mencari kata “apa”, “bagaimana”, “mengapa”, dan kemudian “kapan”.
Ada beberapa cara untuk membuat penggalian kueri informasi tidak terlalu membosankan dengan regex.
Daniel K. Cheung membagikan string regex yang akan menampilkan semua kueri yang berisi "apa", "bagaimana", "mengapa", dan "kapan" yang mendapat klik atau tayangan:
-
"what|how|why|when"
Dan string regex yang dibagikan oleh Steve Toth ini mengambil contoh sebelumnya:
-
^(who|what|where|when|why|how)[" "]
Anda dapat menggunakan string ini jika Anda ingin menangkap kueri berbasis pertanyaan yang dimulai dengan "siapa", "apa", "di mana", "kapan", "mengapa" dan "bagaimana" dan kemudian diikuti dengan spasi.
Ini adalah daftar yang bagus untuk digunakan saat Anda mencari jenis kata apa pun yang akan memulai pertanyaan:
- adalah, bisa, tidak bisa, bisa, tidak bisa, lakukan, tidak, lakukan, tidak, tidak, bagaimana, jika, adalah, tidak, seharusnya, tidak, adalah, tidak, adalah, tidak, apa, kapan, di mana, siapa, siapa, siapa, mengapa, akan, tidak akan, akan, tidak akan
Menempatkan semua ini ke dalam bentuk regex akan terlihat seperti ini:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
Dalam string 178 karakter ini:
- Anda memiliki tanda sisipan (
^) yang memberi tahu Anda bahwa kueri harus dimulai dengan kata ini: - Kata-kata dipisahkan dengan pipa (
|) bukan koma. - Semua kata dibungkus dalam tanda kurung.
- Ada garis miring terbalik dan "s" (
\s) yang menunjukkan spasi setelah kata.
Ini bagus, tetapi juga bisa membosankan untuk dilakukan.
Di bawah, Wu menyederhanakan daftar kata sebelumnya menjadi lebih ramah-regex dan lebih pendek yang ideal untuk menyalin dan menempel. Mempertahankannya dengan cara ini juga membantu efisiensi.
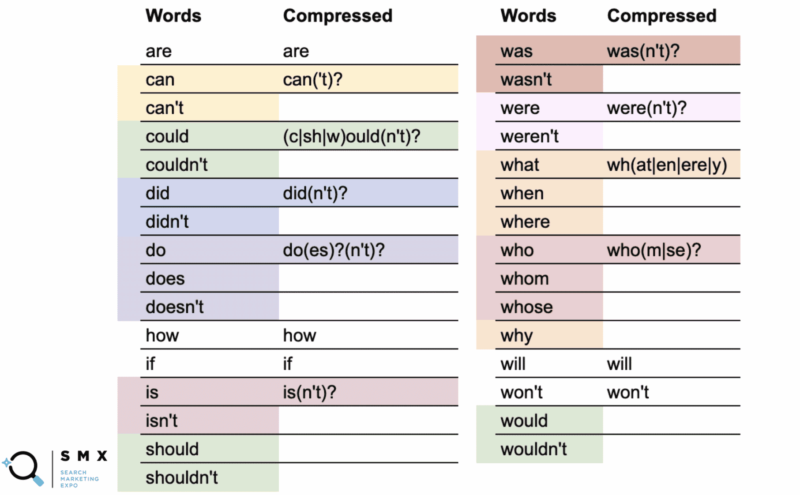
Di kolom pertama adalah kata-kata normal dan di kolom kedua, regex terkompresi.
Misalnya, kata "bisa" menggunakan versi terkompresi can('t)? .
Apa yang ditunjukkan oleh tanda tanya adalah bahwa apa pun di dalam tanda kurung adalah opsional. Sintaks terkompresi memungkinkan Anda untuk menutupi kata "bisa" dan "tidak bisa."
Lebih menarik lagi, Anda dapat melakukan ini dengan bisa/tidak bisa, harus/tidak, dan akan/tidak akan di mana bagian -ould dari kata-kata adalah basis umum, seperti (c|sh|w)ould(n't)? . String pendek ini mencakup keenam kasus tersebut.
Saat menyederhanakan daftar panjang kata-kata itu membuat string menjadi kurang mudah dibaca, yang hebat adalah string ini lebih cocok dengan bidang regex dan memungkinkan Anda untuk menyalin-menempel dengan lebih mudah.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Jika Anda melangkah lebih jauh, Anda dapat mengompresnya lebih banyak lagi. Dalam hal ini, Wu mengurangi jumlah karakter dari 135 menjadi 113 karakter.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Ekspresi reguler bisa menjadi sangat rumit. Jika Anda mendapatkan string regex dari orang lain dan ingin membedakan apa yang melakukan apa, Anda dapat menggunakan Regexper untuk membantu Anda memvisualisasikannya.
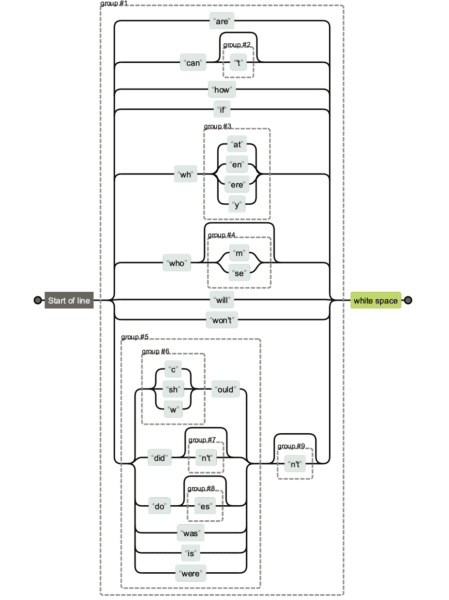
Di bawah ini Anda akan melihat perbandingan versi string regex yang berbeda. Lebih mudah untuk mempertahankan yang pertama, dan jelas lebih sulit untuk mempertahankan dan membaca yang terakhir.

Tetapi terkadang jumlah karakter sangat penting terutama jika Anda memiliki ekspresi reguler yang lebih panjang.
Batas filter regex untuk GSC adalah 4.096 karakter, menurut Google Search Advocate Daniel Waisberg.
Itu akan terlihat sedikit. Namun, jika Anda memiliki situs e-niaga dan harus menambahkan nama domain, subdomain, atau direktori yang lebih panjang, kemungkinan besar Anda akan mencapai batas itu.
Kueri bermerek regex
Contoh lain di mana Anda mungkin mulai mencapai batas karakter regex di GSC adalah saat Anda menggunakannya untuk kueri bermerek.
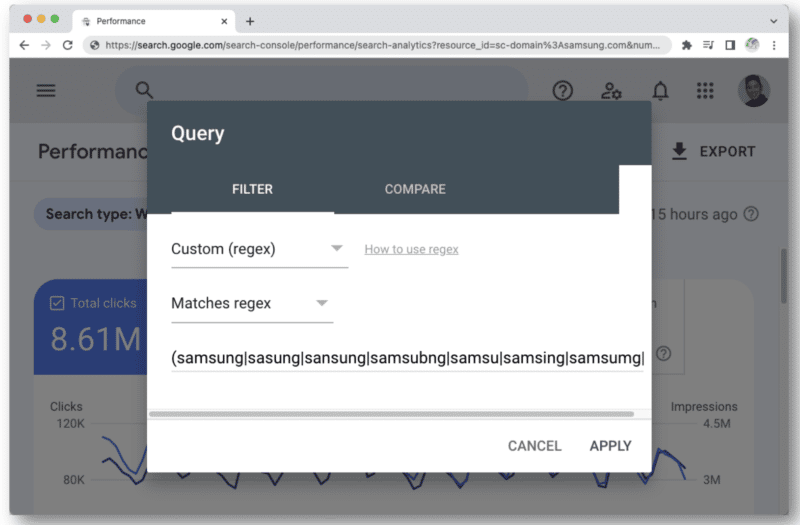
Ketika Anda memikirkan semua jenis kesalahan ejaan yang berbeda dari nama merek yang dapat diketik seseorang, Anda akan segera menemukan 4.096 karakter itu. Contohnya:
- samsamsamung, damsung, mamsang, sam sung, samaung, samdung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag , samsun g, samsunb, samsun, samsun, samsunh, samsun…
Di sinilah pemahaman regex membantu. Dengan string ini, Anda dapat menangkap nama merek "samsung" bersama dengan salah ejaan:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Sering kali, orang akan salah mengeja bagian tengah kata. Tetapi secara umum, mereka mendapatkan format dan panjang yang tepat dan Anda dapat mendekati sintaks Anda dengan cara ini.

Untuk kesalahan ejaan kueri merek, pertimbangkan hal berikut:
- Huruf utama yang membentuk kueri merek.
- Konsonan .
- Huruf-huruf yang mengelilingi konsonan keras .

Warna merah adalah konsonan keras yang biasanya tidak dilewatkan orang saat mereka mengetikkan nama merek. Ini adalah huruf utama yang membentuk merek tertentu. Untuk "samsung", "s" di awal, "m" di tengah, dan kemudian "n" dan "g" di akhir.
Huruf biru yang mengelilingi konsonan utama pada keyboard adalah huruf yang biasanya salah ketik orang. Dalam contoh, di sekitar "s", Anda melihat "a", "d" dan "z". (Meskipun tata letaknya berbeda untuk keyboard internasional, konsepnya tetap sama.)
String regex di atas menangkap semua kemungkinan varian "samsung".
Trik utama lainnya di sini adalah di [az\s]{1,4} .
Dalam bentuk regex, ini pada dasarnya mengatakan, "Saya ingin mencocokkan huruf apa pun "a" hingga "z", atau spasi, satu hingga empat kali."
Ini menangkap semua kesalahan ejaan aneh yang dapat terjadi di tengah kueri merek – di mana seseorang berpotensi menekan tombol yang sama beberapa kali atau secara tidak sengaja menekan spasi.
Selain itu, nama merek memiliki panjang tertentu ("samsung" memiliki tujuh karakter). Orang-orang kemungkinan besar tidak akan mengetik 20–50 karakter.
Jadi dalam ekspresi reguler ini, kami menebak bahwa antara "s" dan "m" di "samsung", seseorang akan salah mengetik 1-4 karakter. Dan kemudian dari "m" ke "g" di akhir, mereka akan salah ketik 1–6 karakter, dengan spasi disertakan.
Menambahkan semua ini memungkinkan Anda menangkap banyak variasi kueri bermerek secara komprehensif.
Hal lain yang perlu diperhatikan adalah bahwa nama merek dapat muncul di bagian kueri yang berbeda.

Jadi kita perlu memastikan bahwa nama merek itu sendiri, ditangkap. Seharusnya:
- Di awal kueri.
- Di tengah kueri (dengan demikian dikelilingi oleh spasi).
- Atau di akhir kueri.
Ekspresi reguler untuk ini adalah sebagai berikut:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Ini menangkap semua kueri di mana nama merek "samsung" berada di awal, tengah, atau akhir.
- Awal string =
^ - Dikelilingi oleh spasi =
\s - Akhir string =
$
Posting JC Chouinard, Regular Expressions (RegEx) di Google Search Console, menyelam lebih dalam ke contoh regex.
Regex dan API GSC beraksi
Ekspresi reguler berguna bagi Wu dan timnya ketika mereka bekerja dengan klien yang mengalami penurunan lalu lintas setelah pembaruan inti.
Setelah melihat berbagai masalah situs e-niaga, mereka menemukan bahwa masalahnya ada di beberapa halaman detail produk.
Mereka perlu mengelompokkan jenis halaman untuk analisis di GSC. Tapi ini adalah tugas yang kompleks karena struktur URL yang berbeda untuk produk AS dan internasional.

URL produk internasional situs menyertakan kode bahasa dan negara, sedangkan URL produk AS tidak.
Bahkan menggunakan sintaks regex itu rumit karena huruf dan tanda hubung ada di slug, kategori, dan subkategori produk. Selain itu, mereka perlu memfilter URL produk internasional untuk menangkap hanya halaman AS.
Untuk mendapatkan semua halaman arahan + detail produk AS ( bukan halaman i18n), mereka datang dengan string regex berikut:
Sertakan: /([^/]+/){1,2}p?
Kecualikan: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Berikut rinciannya:

Tim ingin mencocokkan kategori, subkategori, dan semua produk sehingga mereka menyertakan:
- Karakter apa pun yang bukan garis miring =
[^/]+ - 1 atau 2 direktori =
/){1,2} - Terkadang diikuti oleh product slug =
p?
Tanda sisipan ( ^ ) biasanya berarti awal dari string. Tetapi ketika berada di dalam tanda kurung (seperti dalam [^/] ), ini menunjukkan negasi (yaitu, "tidak ada apa pun di dalam kotak ini").
Jadi string ini /([^/]+/){1,2}p? berarti "Saya ingin sejumlah karakter yang bukan garis miring, mengarah ke garis miring (yang menunjukkan direktori), dan kadang-kadang diikuti dengan huruf 'p' (awalan untuk slug produk)."
Pada saat yang sama, tim tidak ingin mencocokkan kombinasi negara dan bahasa yang juga mengandung huruf dan tanda hubung, sehingga mereka mengecualikan:
- Direktori 2 huruf apa saja =
[a-zA-Z]{2} - 2 huruf + 2 huruf lang-country combo =
[a-zA-Z]{2}-[a-zA-Z]{2}
Membuat ekspresi reguler untuk mencocokkan semua bahasa dan kode negara sendiri akan membosankan karena semua kemungkinan kombinasi, jadi mereka tidak dapat mendekati ini seperti yang dilakukan untuk kueri informasi (di mana setiap jenis kombinasi dikecualikan).
Tetapi bahkan setelah membuat string regex ini, mereka memiliki masalah.
Di Google Search Console, hanya ada satu bidang untuk menempelkan string regex. Anda harus memilih Cocok dengan regex atau Tidak cocok dengan regex – Anda tidak dapat menggunakan keduanya secara bersamaan.
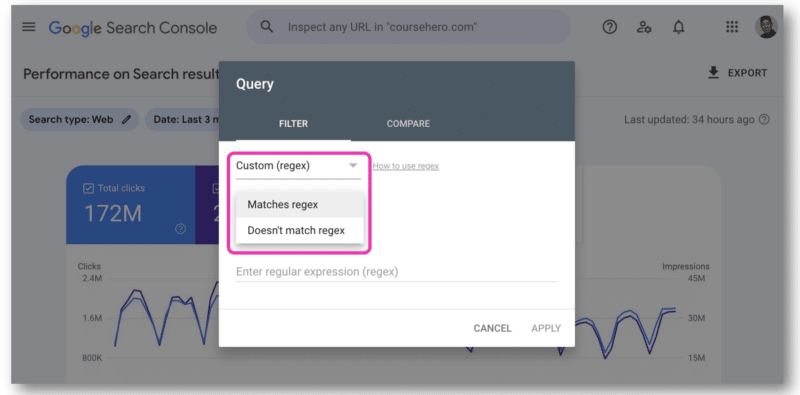
Di sinilah GSC API berguna karena memungkinkan penggabungan string regex.
Dalam dokumentasi API Google Search Console, ada tautan Coba sekarang .
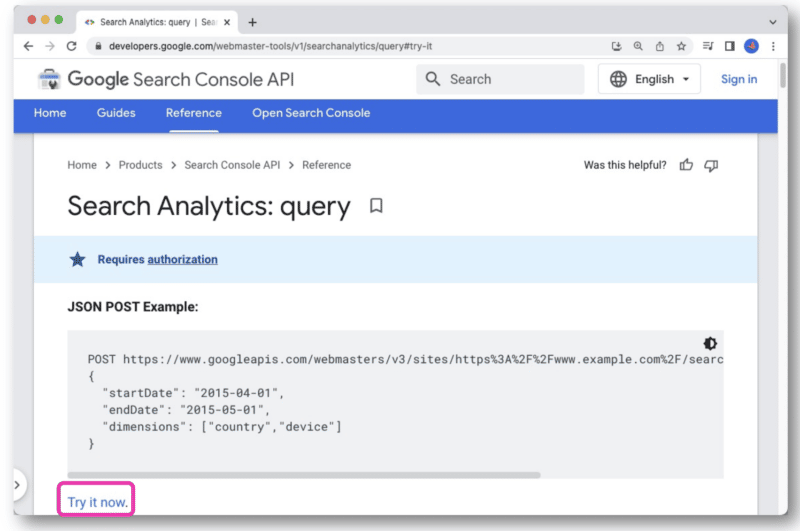
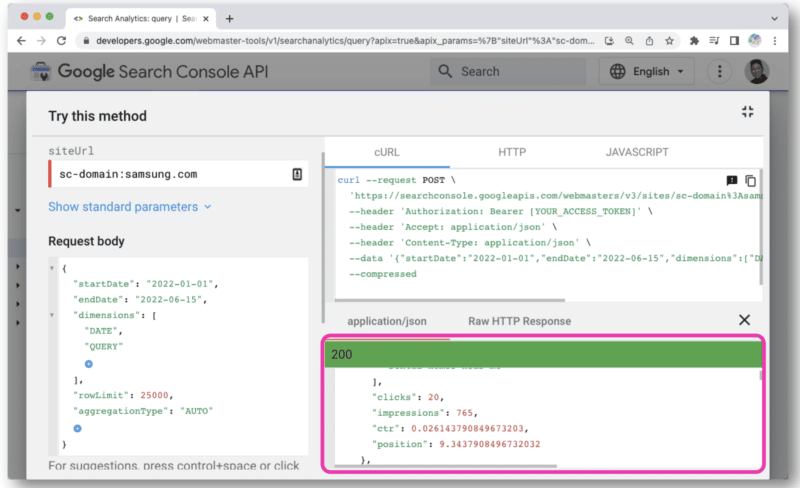
Setelah diklik, itu akan membuka konsol yang memungkinkan Anda memilih situs dan membuat permintaan API Anda melalui tampilan web.
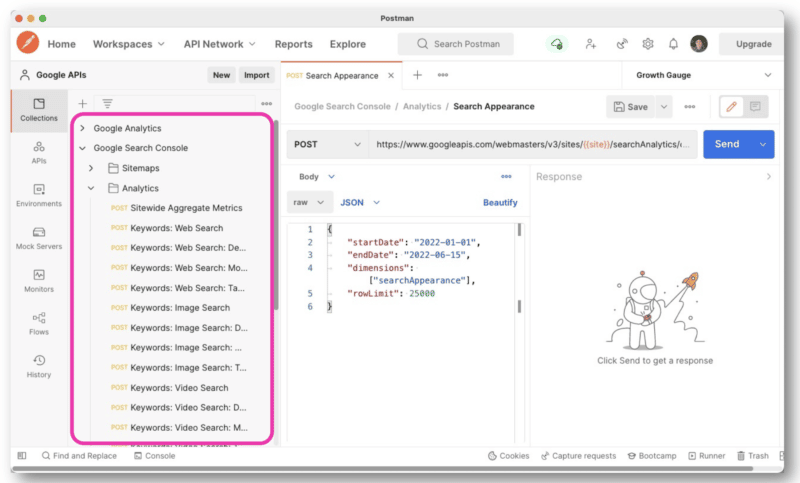
Tetapi untuk mengelola kueri API dengan lebih baik, Wu merekomendasikan penggunaan Postman di desktop atau Paw (yang asli untuk Mac).
Tukang pos memungkinkan Anda membuat kueri dan menyimpannya untuk nanti. Dan jika Anda memiliki akses ke situs lain, Anda tidak perlu membuat kueri baru setiap kali. Anda cukup mengganti nama situs dengan variabel dan kemudian membuat beberapa permintaan.
Paw, di sisi lain, jauh lebih mudah untuk dilihat dan digunakan.
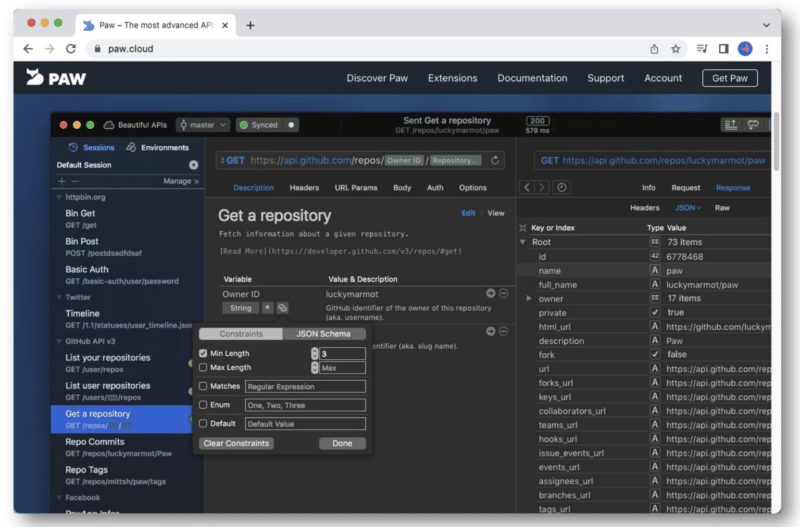
Untuk mengakses API, Anda harus mendapatkan kunci API Anda. (Inilah tutorial bermanfaat dari Chouinard.)
Setelah mendapatkan info ini, Anda akan memiliki ID klien dan rahasia klien, yang akan Anda tambahkan ke autentikasi OAuth 2.0 dalam Postman atau Paw.
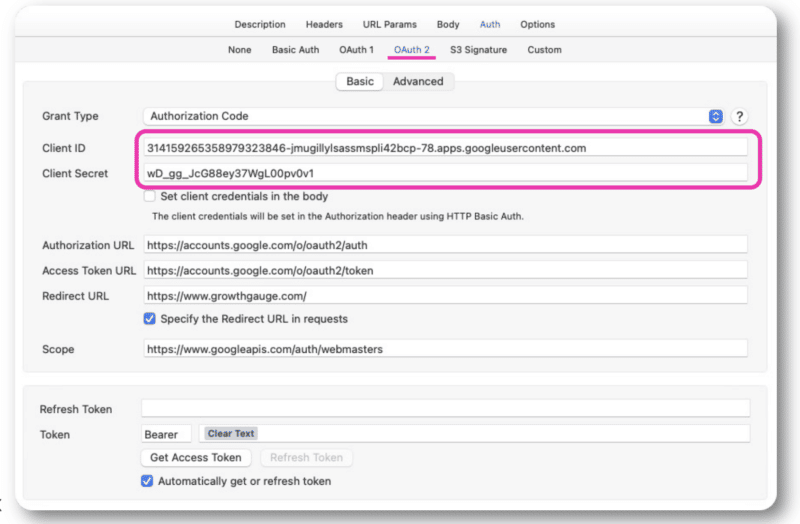
Dari sana, Anda dapat masuk dengan akun biasa.
Wu terutama membuat permintaan API GSC menggunakan string regex di Paw. Kueri dimasukkan di tengah antarmuka.
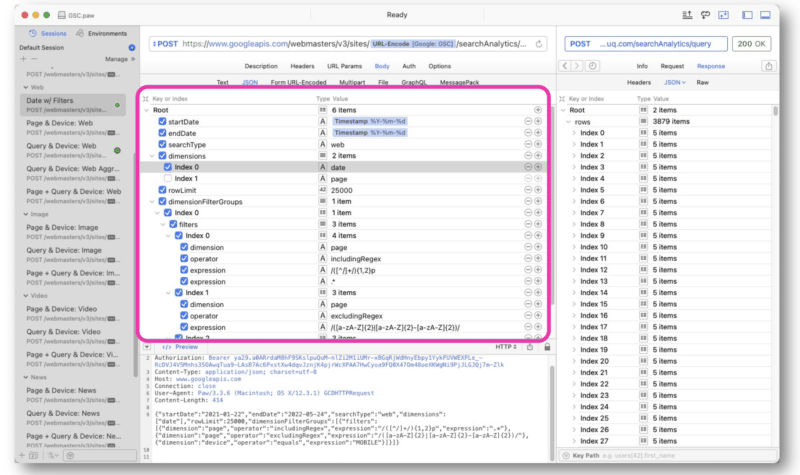
Respons dari Google mirip dengan tampilan web GSC API. Data tersebut kemudian dapat diekspor untuk diproses.
Karena data dalam JSON, informasinya bisa berantakan dan sulit dibaca.

Untuk ini, Anda dapat menggunakan prosesor JSON baris perintah sumber terbuka dan gratis yang disebut JQ untuk mencetak informasi dengan cantik.

Data tidak begitu berguna sampai Anda memasukkannya ke dalam spreadsheet. Pipa dalam file yang telah Anda ekspor dari Paw ke JQ. Buka dan ulangi setiap baris – simpan setiap elemen sehingga Anda dapat menampilkannya ke CSV.
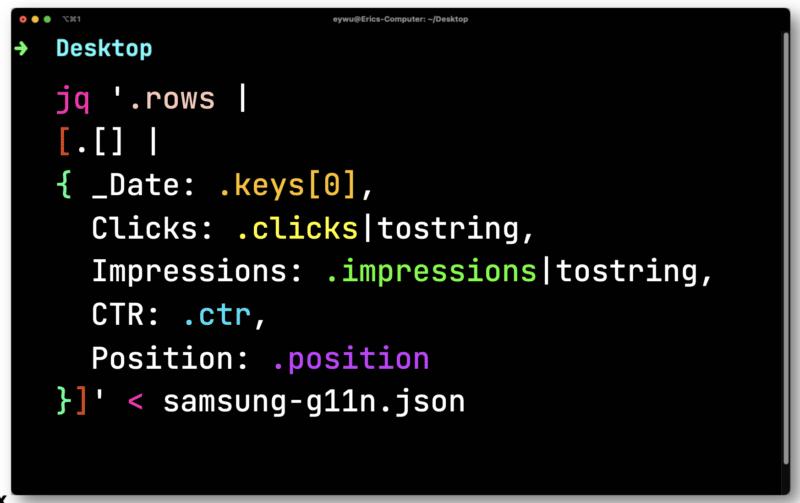
Di sini, Anda harus mengonversi klik dan tayangan yang mengambang (angka yang memiliki tempat desimal). Keduanya perlu diubah menjadi string yang kompatibel dengan CSV.
JQ kemudian akan menampilkan format yang jauh lebih sederhana berikut.
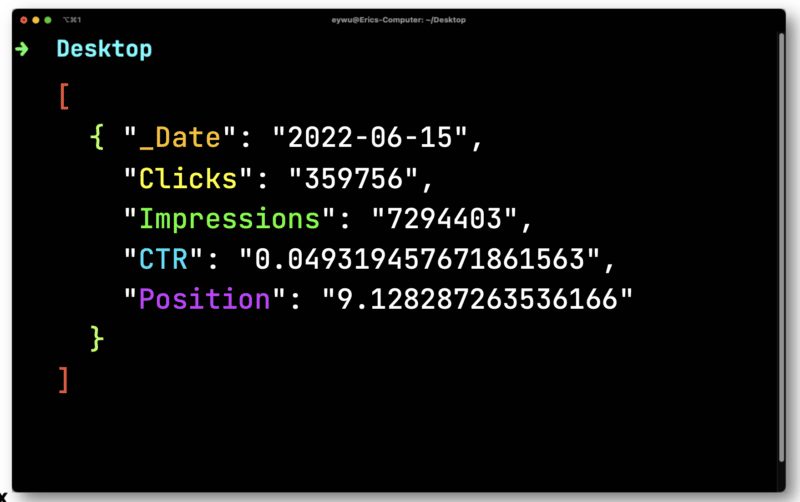
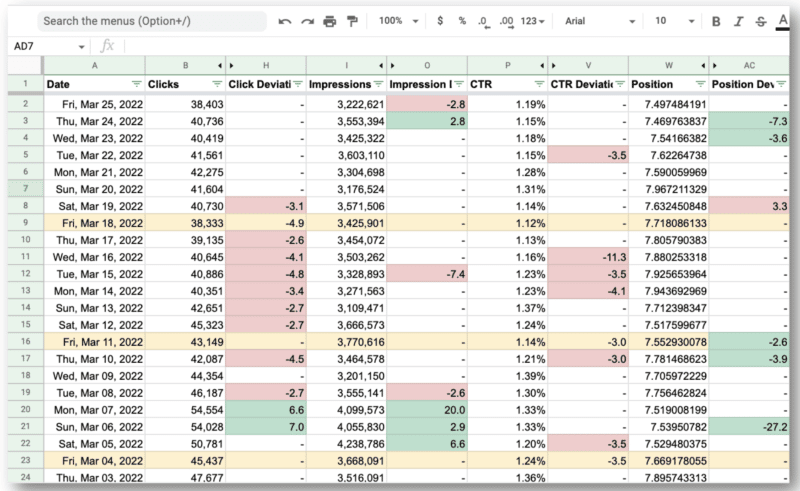
Selanjutnya, Anda akan menggunakan Dasel untuk mengambil format ini dan kemudian membuatnya menjadi CSV.
Dan inilah hasil akhirnya.
Yang luar biasa bagi tim Wu adalah mereka dapat menggunakan API Google Search Console dan ekspresi reguler untuk:
- Saring semua pertanyaan internasional dan lihat hanya AS di mana mereka mengalami masalah utama.
- Identifikasi hari-hari situs mengalami masalah.
Tonton: Mendapatkan hasil maksimal dari Google Search Console API
Di bawah ini adalah video lengkap dari presentasi Wu SMX Advanced.