
Apakah Google menggunakan sistem mirip ChatGPT untuk pendeteksian konten spam dan AI serta peringkat situs web?
Diterbitkan: 2023-02-01Judulnya sengaja menyesatkan – tetapi hanya sejauh menggunakan istilah “ChatGPT”.
"Seperti ChatGPT" segera memungkinkan Anda, pembaca, mengetahui jenis teknologi yang saya maksud, alih-alih mendeskripsikan sistem sebagai "model pembuatan teks seperti GPT-2 atau GPT-3". (Juga, yang terakhir benar-benar tidak dapat diklik…)
Apa yang akan kita lihat dalam artikel ini adalah makalah Google yang lebih tua, tetapi sangat relevan dari tahun 2020, "Model Generatif adalah Prediktor Kualitas Halaman yang Tidak Diawasi: Studi Skala Besar."
Tentang apa kertas itu?
Mari kita mulai dengan deskripsi penulis. Mereka memperkenalkan topik sebagai berikut:
“Banyak yang telah menyuarakan keprihatinan tentang potensi bahaya dari generator teks saraf di alam liar, sebagian besar karena kemampuan mereka untuk menghasilkan teks yang tampak seperti manusia dalam skala besar.
Pengklasifikasi dilatih untuk membedakan antara manusia dan teks yang dihasilkan mesin baru-baru ini digunakan untuk memantau keberadaan teks yang dihasilkan mesin di web [29]. Sedikit pekerjaan, bagaimanapun, telah dilakukan dalam menerapkan pengklasifikasi ini untuk kegunaan lain, meskipun sifat menarik mereka tidak memerlukan label - hanya kumpulan teks manusia dan model generatif. Dalam karya ini, kami menunjukkan melalui evaluasi manusia yang ketat bahwa pembeda manusia vs. mesin siap pakai berfungsi sebagai pengklasifikasi mutu laman yang ampuh . Artinya, teks yang tampak dibuat oleh mesin cenderung tidak koheren atau tidak dapat dipahami. Untuk memahami adanya kualitas halaman rendah di alam liar, kami menerapkan pengklasifikasian ke sampel setengah miliar halaman web berbahasa Inggris.”
Apa yang mereka katakan pada dasarnya adalah bahwa mereka telah menemukan bahwa pengklasifikasi yang sama yang dikembangkan untuk mendeteksi salinan berbasis AI, menggunakan model yang sama untuk membuatnya, dapat berhasil digunakan untuk mendeteksi konten berkualitas rendah.
Tentu saja, ini meninggalkan kita dengan pertanyaan penting:
Apakah ini sebab -akibat (yaitu, apakah sistem mengambilnya karena benar-benar bagus) atau korelasi (yaitu, apakah banyak spam saat ini dibuat dengan cara yang mudah dilakukan dengan alat yang lebih baik)?
Namun, sebelum kita menjelajahinya, mari kita lihat beberapa karya penulis dan temuan mereka.
Pengaturan
Sebagai referensi, mereka menggunakan yang berikut dalam percobaan mereka:
- Dua model pembuatan teks , detektor GPT-2 berbasis Roberta OpenAI (detektor yang menggunakan model RoBERTa dengan keluaran GPT-2 dan memprediksi apakah kemungkinan dihasilkan oleh AI atau tidak) dan model GLTR, yang juga memiliki akses ke atas Keluaran GPT-2 dan beroperasi dengan cara yang sama.
Kita bisa melihat contoh keluaran model ini pada konten yang saya salin dari kertas di atas:
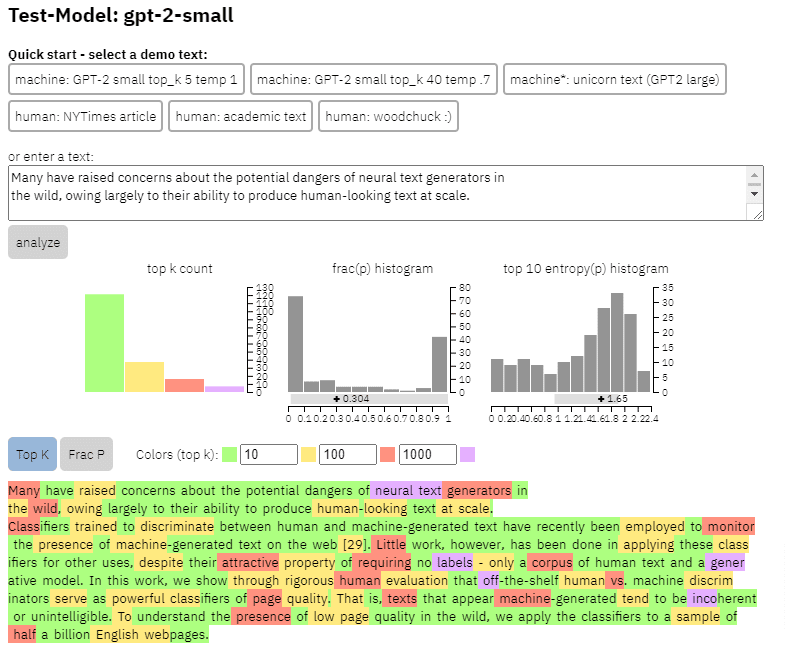
- Tiga kumpulan data Web500M (sampel acak dari 500 juta halaman web berbahasa Inggris), GPT-2 Output (250k GPT-2 generasi teks) dan Grover-Output (mereka menghasilkan 1,2 juta artikel secara internal menggunakan model Grover-Base pra-terlatih, yang dirancang untuk mendeteksi berita palsu).
- The Spam Baseline , pengklasifikasi yang dilatih di Enron Spam Email Dataset. Mereka menggunakan pengklasifikasi ini untuk menetapkan nomor Kualitas Bahasa yang akan mereka tetapkan, jadi jika model menentukan bahwa dokumen bukan spam dengan probabilitas 0,2, skor Kualitas Langage (LQ) yang ditetapkan adalah 0,2.
Dapatkan buletin pencarian harian yang diandalkan pemasar.
Lihat persyaratan.
Selain tentang prevalensi spam
Saya ingin menyingkir sejenak untuk membahas beberapa temuan menarik yang penulis temukan. Salah satunya diilustrasikan pada gambar berikut (Gambar 3 dari kertas):
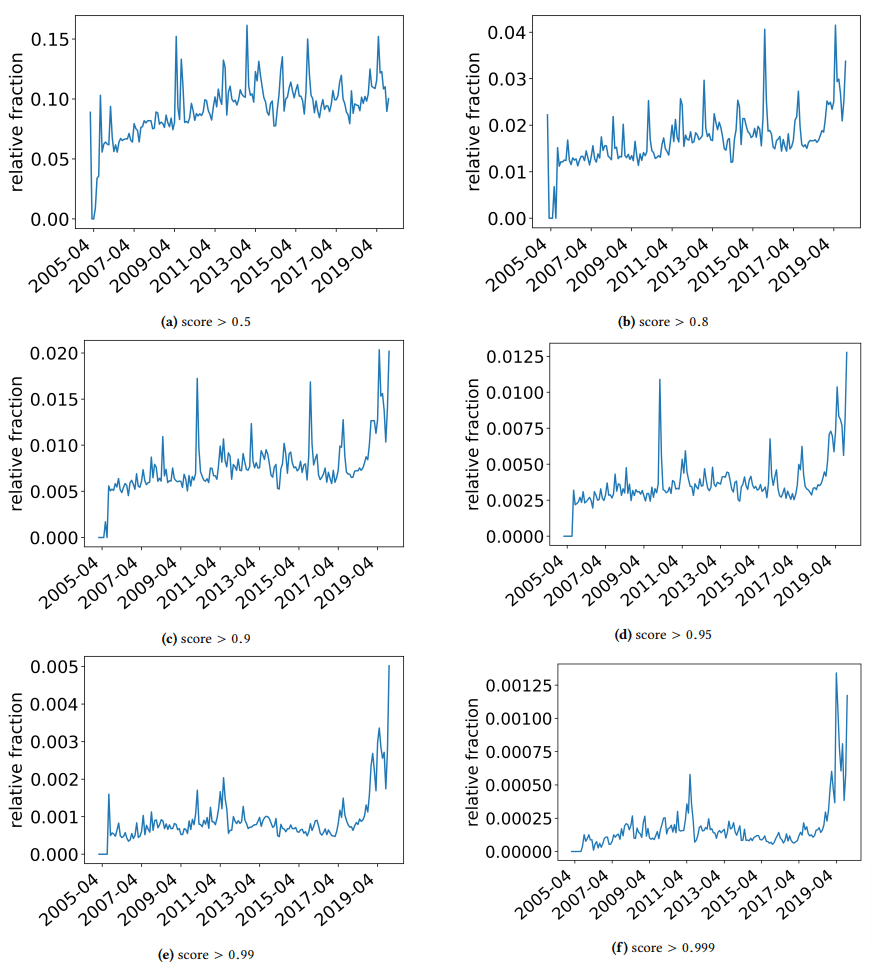
Penting untuk memperhatikan skor di bawah setiap grafik. Angka menuju 1.0 bergerak ke keyakinan bahwa konten tersebut adalah spam. Apa yang kami lihat kemudian adalah bahwa sejak 2017 dan seterusnya – dan melonjak pada 2019 – ada prevalensi dokumen berkualitas rendah.
Selain itu, mereka menemukan dampak dari konten berkualitas rendah lebih tinggi di beberapa sektor daripada yang lain (mengingat bahwa skor yang lebih tinggi mencerminkan kemungkinan spam yang lebih tinggi).
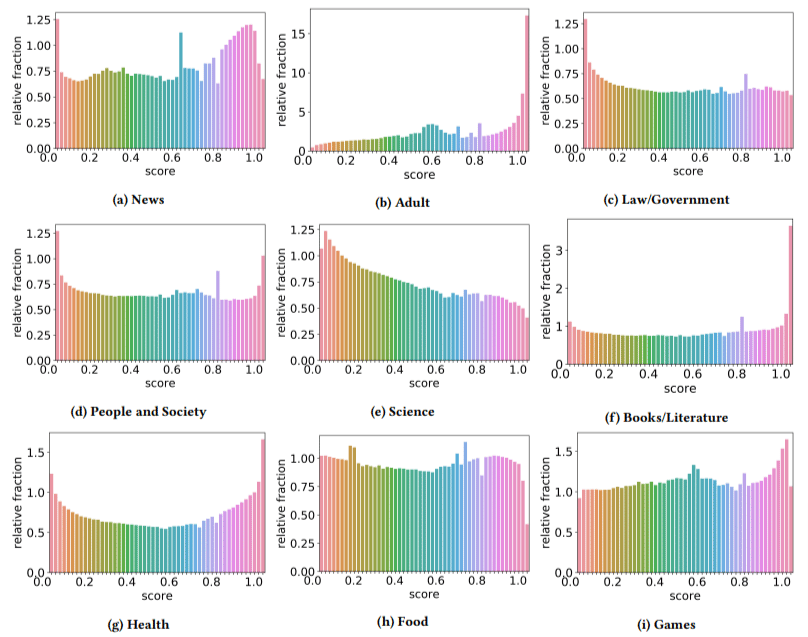
Aku menggaruk kepalaku pada beberapa ini. Dewasa masuk akal, jelas.
Tetapi buku dan literatur sedikit mengejutkan. Begitu pula kesehatan – sampai penulis mengangkat Viagra dan situs "produk kesehatan dewasa" lainnya sebagai "kesehatan" dan peternakan esai sebagai "literatur" - begitulah.
Temuan mereka
Selain dari apa yang kita bahas tentang sektor dan lonjakan pada tahun 2019, penulis juga menemukan sejumlah hal menarik yang dapat dipelajari dan harus diingat oleh SEO, terutama saat kita mulai bersandar pada alat seperti ChatGPT.
- Konten berkualitas rendah cenderung lebih pendek (memuncak pada 3.000 karakter).
- Sistem deteksi yang dilatih untuk menentukan apakah teks ditulis oleh mesin atau tidak juga bagus dalam mengklasifikasikan konten tingkat rendah vs. tinggi.
- Mereka menyebut konten kami yang dirancang untuk peringkat sebagai pelakunya, meskipun saya curiga mereka mengacu pada sampah yang kita semua tahu seharusnya tidak ada di sana.
Para penulis tidak mengklaim bahwa ini adalah solusi akhir dari segalanya, melainkan titik awal dan saya yakin mereka telah memajukan standar dalam beberapa tahun terakhir.
Catatan tentang konten buatan AI
Model bahasa juga telah berkembang selama bertahun-tahun. Sementara GPT-3 ada saat makalah ini ditulis, detektor yang mereka gunakan didasarkan pada GPT-2 yang merupakan model yang jauh lebih rendah.
GPT-4 kemungkinan sudah dekat dan Google's Sparrow akan dirilis akhir tahun ini. Ini berarti bahwa tidak hanya teknologi menjadi lebih baik di kedua sisi medan pertempuran (generator konten vs. mesin pencari), kombinasi akan lebih mudah untuk dimainkan.
Bisakah Google mendeteksi konten yang dibuat oleh Sparrow atau GPT-4? Mungkin.
Tetapi bagaimana jika itu dibuat dengan Sparrow dan kemudian dikirim ke GPT-4 dengan perintah penulisan ulang?
Faktor lain yang perlu diingat adalah bahwa teknik yang digunakan dalam makalah ini didasarkan pada model auto-regresif. Sederhananya, mereka memprediksi skor untuk sebuah kata berdasarkan apa yang akan mereka prediksi dari kata yang akan diberikan pada kata yang mendahuluinya.
Saat model mengembangkan tingkat kecanggihan yang lebih tinggi dan mulai membuat ide lengkap pada satu waktu daripada satu kata yang diikuti oleh yang lain, deteksi AI mungkin tergelincir.
Di sisi lain, pendeteksian konten sampah seharusnya meningkat – yang mungkin berarti bahwa satu-satunya konten "berkualitas rendah" yang akan menang, adalah yang dihasilkan oleh AI.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.