
Ekosistem Hadoop dan komponennya
Diterbitkan: 2015-04-23Big Data adalah kata buzz yang beredar di industri TI sejak tahun 2008. Jumlah data yang dihasilkan oleh jaringan sosial, manufaktur, ritel, saham, telekomunikasi, asuransi, perbankan, dan industri perawatan kesehatan jauh di luar imajinasi kita.
Sebelum munculnya Hadoop, penyimpanan dan pemrosesan data besar merupakan tantangan besar. Tetapi sekarang setelah Hadoop tersedia, perusahaan telah menyadari dampak bisnis dari Big Data dan bagaimana memahami data ini akan mendorong pertumbuhan. Sebagai contoh:
• Sektor perbankan memiliki kesempatan yang lebih baik untuk memahami nasabah setia, mangkir dan transaksi penipuan.
• Sektor ritel sekarang memiliki cukup data untuk memperkirakan permintaan.
• Sektor manufaktur tidak perlu bergantung pada mekanisme pengujian kualitas yang mahal. Menangkap data sensor dan menganalisisnya akan mengungkapkan banyak pola.
• E-Commerce, jejaring sosial dapat mempersonalisasi halaman berdasarkan minat pelanggan.
• Pasar saham menghasilkan sejumlah besar data, yang berkorelasi dari waktu ke waktu akan mengungkapkan wawasan yang indah.
Big Data memiliki banyak aplikasi yang berguna dan berwawasan luas.
Hadoop adalah jawaban langsung untuk memproses Big Data. Ekosistem Hadoop adalah kombinasi teknologi yang memiliki keunggulan mahir dalam memecahkan masalah bisnis.
Mari kita memahami komponen dalam Hadoop Ecosytem untuk membangun solusi yang tepat untuk masalah bisnis tertentu.
Ekosistem Hadoop:
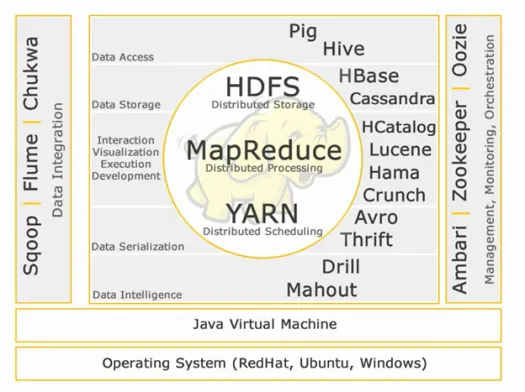

Inti Hadoop:
HDFS:
HDFS adalah singkatan dari Hadoop Distributed File System untuk mengelola kumpulan data besar dengan Volume, Kecepatan, dan Variasi Tinggi. HDFS mengimplementasikan arsitektur master slave. Master adalah simpul Nama dan budak adalah simpul data.
Fitur:
• Dapat diskalakan
• Dapat diandalkan
• Perangkat Keras Komoditas
HDFS adalah yang terkenal untuk penyimpanan Big Data.
Pengurangan Peta:
Map Reduce adalah model pemrograman yang dirancang untuk memproses data terdistribusi volume tinggi. Platform dibangun menggunakan Java untuk penanganan pengecualian yang lebih baik. Map Reduce mencakup dua deamon, Job tracker dan Task Tracker.
Fitur:
• Pemrograman Fungsional.
• Bekerja sangat baik pada Big Data.
• Dapat memproses kumpulan data yang besar.
Map Reduce adalah komponen utama yang dikenal untuk memproses data besar.
BENANG:
YARN adalah singkatan dari Yet Another Resource Negotiator. Ini juga disebut sebagai MapReduce 2(MRv2). Dua fungsi utama Job Tracker di MRv1, manajemen sumber daya dan penjadwalan/pemantauan pekerjaan dibagi menjadi daemon terpisah yaitu ResourceManager, NodeManager dan ApplicationMaster.
Fitur:
• Manajemen sumber daya yang lebih baik.
• Skalabilitas
• Alokasi dinamis sumber daya cluster.
Akses data:
Babi:
Apache Pig adalah bahasa tingkat tinggi yang dibangun di atas MapReduce untuk menganalisis kumpulan data besar dengan program analisis data adhoc sederhana. Babi juga dikenal sebagai bahasa Data Flow. Ini terintegrasi dengan sangat baik dengan python. Ini awalnya dikembangkan oleh yahoo.
Ciri-ciri babi yang menonjol:
• Kemudahan pemrograman
• Peluang pengoptimalan
• Ekstensibilitas.
Skrip babi secara internal akan dikonversi ke program pengurangan peta.

Sarang lebah:
Apache Hive adalah bahasa kueri tingkat tinggi lainnya dan infrastruktur gudang data yang dibangun di atas Hadoop untuk menyediakan peringkasan, kueri, dan analisis data. Ini awalnya dikembangkan oleh yahoo dan dibuat open source.
Fitur yang menonjol dari sarang:
• SQL seperti bahasa query yang disebut HQL.
• Partisi dan bucketing untuk pemrosesan data yang lebih cepat.
• Integrasi dengan alat visualisasi seperti Tableau.
Kueri sarang secara internal akan dikonversi ke program pengurangan peta.
Jika Anda ingin menjadi seorang analis big data, dua bahasa tingkat tinggi ini wajib Anda ketahui!!

Penyimpanan data:
Hbase:
Apache HBase adalah database NoSQL yang dibuat untuk menampung tabel besar dengan miliaran baris dan jutaan kolom di atas mesin perangkat keras komoditas Hadoop. Gunakan Apache Hbase saat Anda membutuhkan akses baca/tulis acak dan realtime ke Big Data Anda.
Fitur:
• Membaca dan menulis dengan sangat konsisten. Dalam operasi memori.
• Mudah digunakan Java API untuk akses klien.
• Terintegrasi dengan baik dengan babi, sarang dan sqoop.
• Merupakan sistem yang konsisten dan toleran terhadap partisi dalam teorema CAP.

Kasandra:
Cassandra adalah database NoSQL yang dirancang untuk skalabilitas linier dan ketersediaan tinggi. Cassandra didasarkan pada model nilai kunci. Dikembangkan oleh Facebook dan dikenal dengan respons yang lebih cepat terhadap pertanyaan.
Fitur:
• Indeks kolom
• Dukungan untuk de-normalisasi
• Pandangan yang terwujud
• Caching built-in yang kuat.

Interaksi -Visualisasi- eksekusi-pengembangan:
Katalog:

HCatalog adalah lapisan manajemen tabel yang menyediakan integrasi metadata sarang untuk aplikasi Hadoop lainnya. Ini memungkinkan pengguna dengan alat pemrosesan data yang berbeda seperti Apache pig, Apache MapReduce dan Apache Hive untuk lebih mudah membaca dan menulis data.
Fitur:
• Tampilan tabular untuk format yang berbeda.
• Pemberitahuan ketersediaan data.
• REST API untuk sistem eksternal untuk mengakses metadata.
Lusen:
Apache LuceneTM adalah perpustakaan mesin pencari teks berkinerja tinggi dan berfitur lengkap yang seluruhnya ditulis dalam Java. Ini adalah teknologi yang cocok untuk hampir semua aplikasi yang membutuhkan pencarian teks lengkap, terutama lintas platform.
Fitur:
• Scalable, High – Performance indexing.
• algoritma pencarian Powerfull, Akurat dan Efisien.
• Solusi lintas platform.
Hama:
Apache Hama adalah kerangka kerja terdistribusi berdasarkan komputasi Bulk Synchronous Parallel (BSP). Mampu dan terkenal dengan komputasi ilmiah besar-besaran seperti matriks, grafik, dan algoritma jaringan.
Fitur:
• Model pemrograman sederhana
• Sangat cocok untuk algoritme iteratif
• BENANG didukung
• Pemfilteran kolaboratif machine learning tanpa pengawasan.
• Pengelompokan K-Means.
Kegentingan:
Apache crunch dibangun untuk menyalurkan program MapReduce yang sederhana dan efisien. Kerangka kerja ini digunakan untuk menulis, menguji, dan menjalankan jalur pipa MapReduce.
Fitur:
• Berfokus pada pengembang.
• Abstraksi minimal
• Model data yang fleksibel.
Serialisasi Data:
avro:
Apache Avro adalah kerangka kerja serialisasi data yang netral bahasa. Didesain untuk portabilitas bahasa, memungkinkan data untuk secara potensial hidup lebih lama dari bahasa untuk membaca dan menulisnya.

Penghematan:
Thrift adalah bahasa yang dikembangkan untuk membangun antarmuka untuk berinteraksi dengan teknologi yang dibangun di atas Hadoop. Ini digunakan untuk mendefinisikan dan membuat layanan untuk berbagai bahasa.
Kecerdasan Data:
Mengebor:
Apache Drill adalah mesin kueri SQL latensi rendah untuk Hadoop dan NoSQL.
Fitur:
• Kelincahan
• Fleksibilitas
• Keakraban.

Sais gajah:
Apache Mahout adalah perpustakaan pembelajaran mesin skalabel yang dirancang untuk membangun analitik prediktif pada Big Data. Mahout sekarang memiliki implementasi apache spark untuk lebih cepat dalam komputasi memori.
Fitur:
• Penyaringan kolaboratif.
• Klasifikasi
• Pengelompokan
• Pengurangan dimensi

Integrasi data:
Apache Sqoop:

Apache Sqoop adalah alat yang dirancang untuk transfer data massal antara database relasional dan Hadoop.
Fitur:
• Impor dan ekspor ke dan dari HDFS.
• Impor dan ekspor ke dan dari Hive.
• Impor dan ekspor ke HBase.
Apache Flume:
Flume adalah layanan terdistribusi, andal, dan tersedia untuk mengumpulkan, menggabungkan, dan memindahkan data log dalam jumlah besar secara efisien.
Fitur:
• Kokoh
• Toleran terhadap kesalahan
• Arsitektur sederhana dan fleksibel berdasarkan aliran data streaming.

Apache Chukwa:
Pengumpul log yang dapat diskalakan digunakan untuk memantau sistem file terdistribusi besar.
Fitur:
• Skala ke ribuan node.
• pengiriman Handal.
• Harus dapat menyimpan data tanpa batas.

Manajemen, Pemantauan dan Orkestrasi:
Apache Ambari:
Ambari dirancang untuk membuat manajemen hadoop lebih sederhana dengan menyediakan antarmuka untuk penyediaan, pengelolaan, dan pemantauan Cluster Apache Hadoop.
Fitur:
• Penyediaan Hadoop Cluster.
• Mengelola Cluster Hadoop.
• Memantau Cluster Hadoop.

Penjaga Kebun Binatang Apache:
Zookeeper adalah layanan terpusat yang dirancang untuk memelihara informasi konfigurasi, penamaan, menyediakan sinkronisasi terdistribusi, dan menyediakan layanan grup.
Fitur:
• Serialisasi
• Atomisitas
• Keandalan
• API Sederhana

Apache Oozie:
Oozie adalah sistem penjadwal alur kerja untuk mengelola pekerjaan Apache Hadoop.
Fitur:
• Sistem yang dapat diskalakan, andal, dan dapat diperluas.
• Mendukung beberapa jenis pekerjaan Hadoop seperti Map-Reduce, Hive, Pig dan Sqoop.
• Sederhana dan mudah digunakan.

Kami akan membahas tentang komponen secara rinci di artikel mendatang. Pantau terus.