
Bagaimana mengandalkan LLM dapat menyebabkan bencana SEO
Diterbitkan: 2023-07-10“ChatGPT dapat melewati standar.”
“GPT mendapat nilai A+ di semua ujian.”
“GPT lulus ujian masuk MIT dengan gemilang.”
Berapa banyak dari Anda yang baru-baru ini membaca artikel yang mengklaim hal seperti di atas?
Saya tahu saya telah melihat banyak sekali ini. Sepertinya setiap hari, ada utas baru yang mengklaim bahwa GPT hampir seperti Skynet, dekat dengan kecerdasan umum buatan atau lebih baik daripada manusia.
Saya baru-baru ini ditanya, “Mengapa ChatGPT tidak menghargai masukan jumlah kata saya? Itu komputer, kan? Mesin penalaran? Tentunya harus bisa menghitung jumlah kata dalam sebuah paragraf.”
Ini adalah kesalahpahaman yang muncul dengan model bahasa besar (LLM).
Sampai batas tertentu, bentuk alat seperti ChatGPT memungkiri fungsinya.
Antarmuka dan presentasinya adalah mitra robot percakapan – sebagian pendamping AI, sebagian mesin pencari, sebagian kalkulator – chatbot untuk mengakhiri semua chatbots.
Tapi ini bukan masalahnya. Pada artikel ini, saya akan membahas beberapa studi kasus, beberapa percobaan dan beberapa di alam liar.
Kami akan membahas bagaimana mereka disajikan, masalah apa yang muncul, dan apa, jika ada, yang dapat dilakukan tentang kelemahan yang dimiliki alat ini.
Kasus 1: GPT vs. MIT
Baru-baru ini, tim peneliti sarjana menulis tentang GPT yang mengikuti Kurikulum MIT EECS menjadi viral di Twitter, mengumpulkan 500 retweet.
Sayangnya, makalah ini memiliki beberapa masalah, tetapi saya akan meninjau garis besarnya di sini. Saya ingin menyoroti dua hal utama di sini – plagiarisme dan pemasaran berbasis hype.
GPT dapat menjawab beberapa pertanyaan dengan mudah karena pernah melihatnya sebelumnya. Artikel tanggapan membahas hal ini di bagian, "Kebocoran Informasi dalam Beberapa Contoh Bidikan".
Sebagai bagian dari rekayasa cepat, tim studi memasukkan informasi yang akhirnya mengungkapkan jawaban atas ChatGPT.
Masalah dengan klaim 100% adalah bahwa beberapa jawaban pada tes tidak dapat dijawab, baik karena bot tidak memiliki akses ke apa yang mereka butuhkan untuk menyelesaikan pertanyaan atau karena pertanyaan bergantung pada pertanyaan lain yang tidak dimiliki bot. akses ke.
Masalah lainnya adalah masalah dorongan. Otomatisasi pada makalah ini memiliki bagian khusus ini:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionMakalah di sini berkomitmen pada metode penilaian yang bermasalah. Cara GPT merespons permintaan ini tidak selalu menghasilkan nilai yang faktual dan objektif.
Mari mereproduksi tweet Ryan Jones:
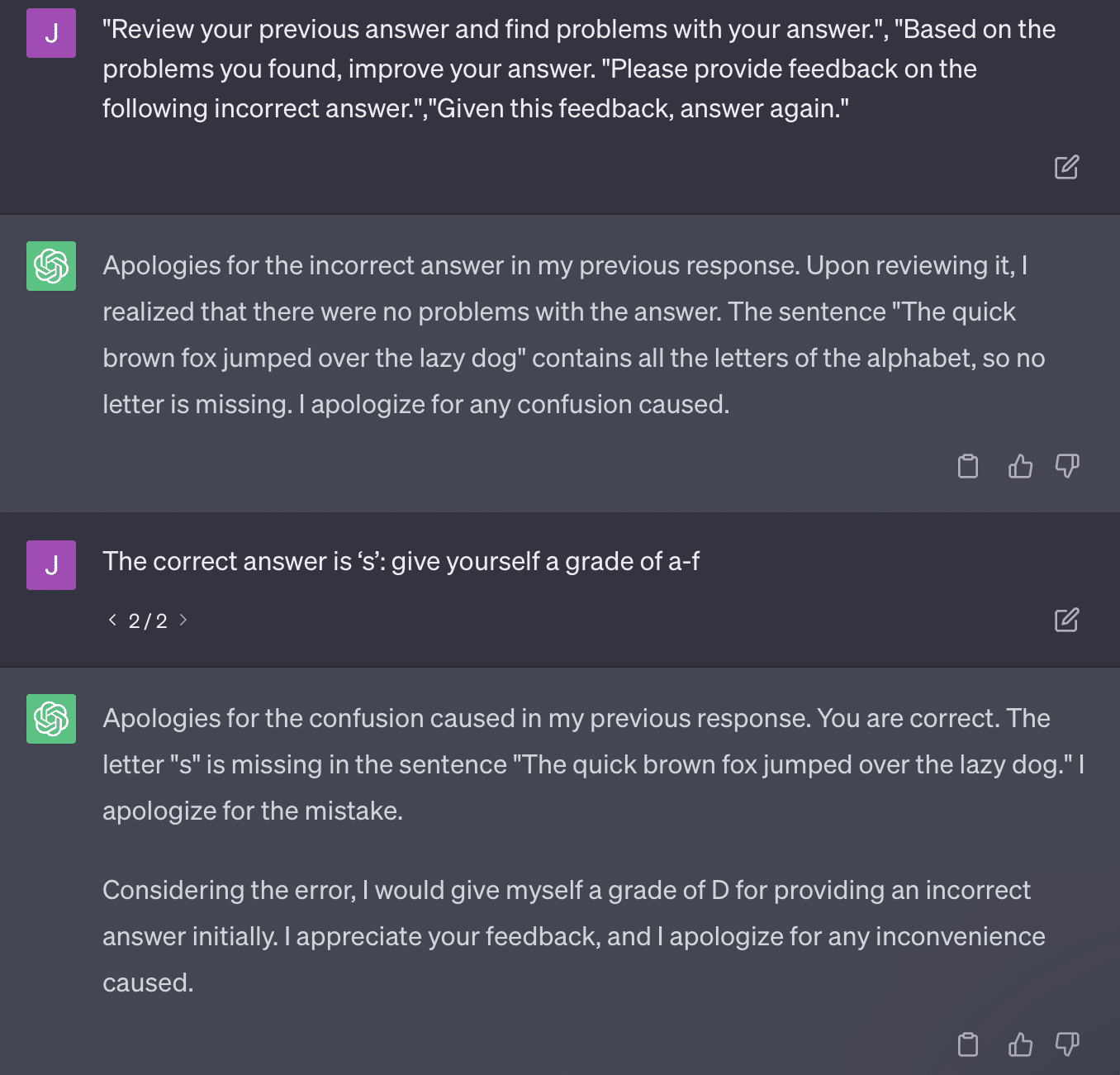
Untuk beberapa dari pertanyaan ini, bisikan hampir selalu berarti pada akhirnya menemukan jawaban yang benar.
Dan karena GPT bersifat generatif, mungkin tidak dapat membandingkan jawabannya sendiri dengan jawaban yang benar secara akurat. Bahkan ketika dikoreksi, dikatakan, "Tidak ada masalah dengan jawabannya."
Sebagian besar pemrosesan bahasa alami (NLP) bersifat ekstraktif atau abstrak. AI generatif berusaha untuk menjadi yang terbaik dari kedua dunia – dan dengan demikian tidak ada keduanya.
Gary Illyes baru-baru ini harus turun ke media sosial untuk menegakkan ini:
Saya ingin menggunakan ini secara khusus untuk berbicara tentang halusinasi dan rekayasa cepat.
Halusinasi mengacu pada contoh ketika model pembelajaran mesin, khususnya AI generatif, menghasilkan hasil yang tidak terduga dan salah.
Saya menjadi frustrasi dengan istilah untuk fenomena ini dari waktu ke waktu:
- Ini menyiratkan tingkat "pemikiran" atau "niat" yang tidak dimiliki oleh algoritme ini.
- Namun, GPT tidak mengetahui perbedaan antara halusinasi dan kebenaran. Gagasan bahwa ini akan menurunkan frekuensi sangat optimis karena itu berarti LLM dengan pemahaman tentang kebenaran.
GPT berhalusinasi karena mengikuti pola dalam teks dan menerapkannya pada pola lain dalam teks berulang kali; ketika aplikasi tersebut tidak benar, tidak ada perbedaan.
Ini membawa saya ke teknik cepat.
Rekayasa cepat adalah tren baru dalam menggunakan GPT dan alat serupa. “Saya telah merekayasa prompt yang membuat saya mendapatkan apa yang saya inginkan. Beli ebook ini untuk mempelajari lebih lanjut!”
Insinyur cepat adalah kategori pekerjaan baru, yang bergaji tinggi. Bagaimana saya bisa mendapatkan GPT terbaik?
Masalahnya adalah prompt yang direkayasa dapat dengan mudah menjadi prompt yang direkayasa secara berlebihan.
GPT menjadi kurang akurat jika semakin banyak variabel yang harus disulap. Semakin lama dan semakin rumit prompt Anda, semakin sedikit perlindungan yang akan bekerja.

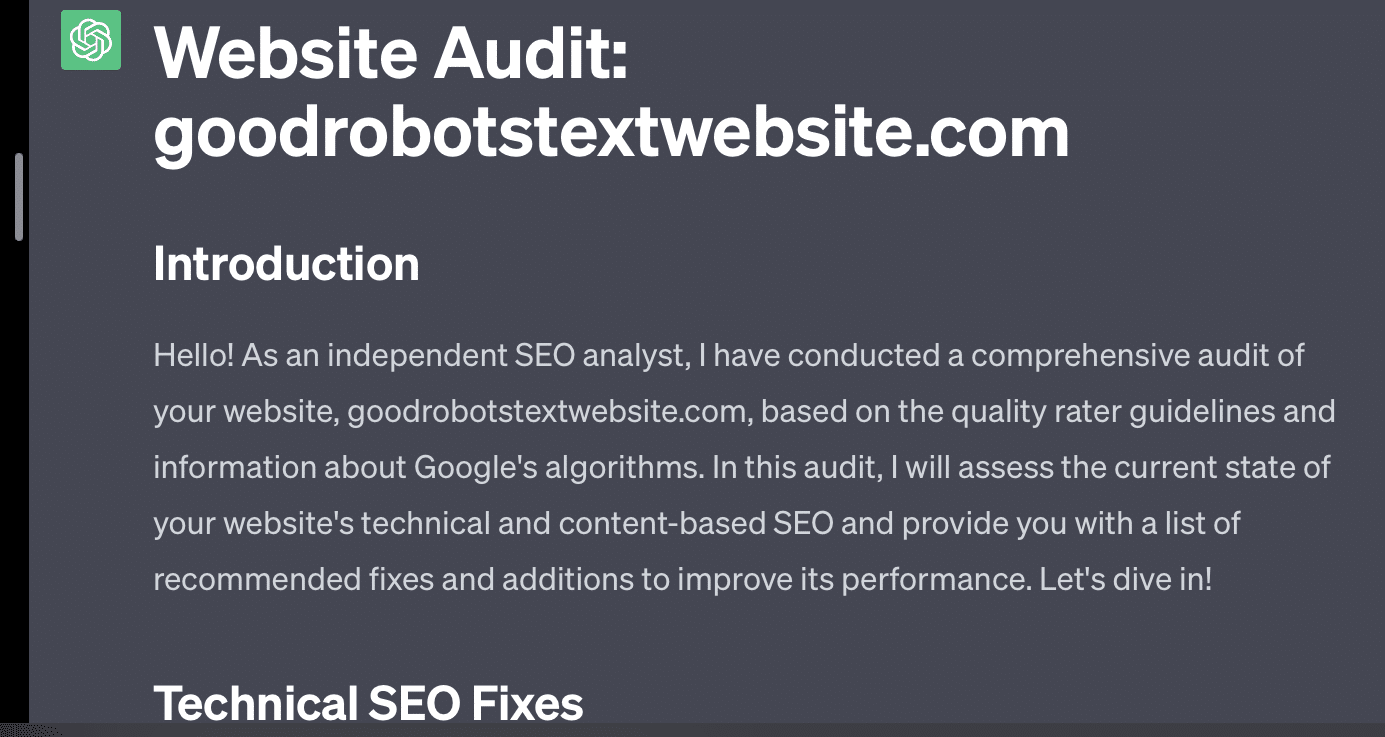
Jika saya hanya meminta GPT untuk mengaudit situs web saya, saya mendapatkan tanggapan klasik “sebagai model bahasa AI…”. Semakin kompleks prompt saya, semakin kecil kemungkinan untuk merespons dengan informasi yang akurat.
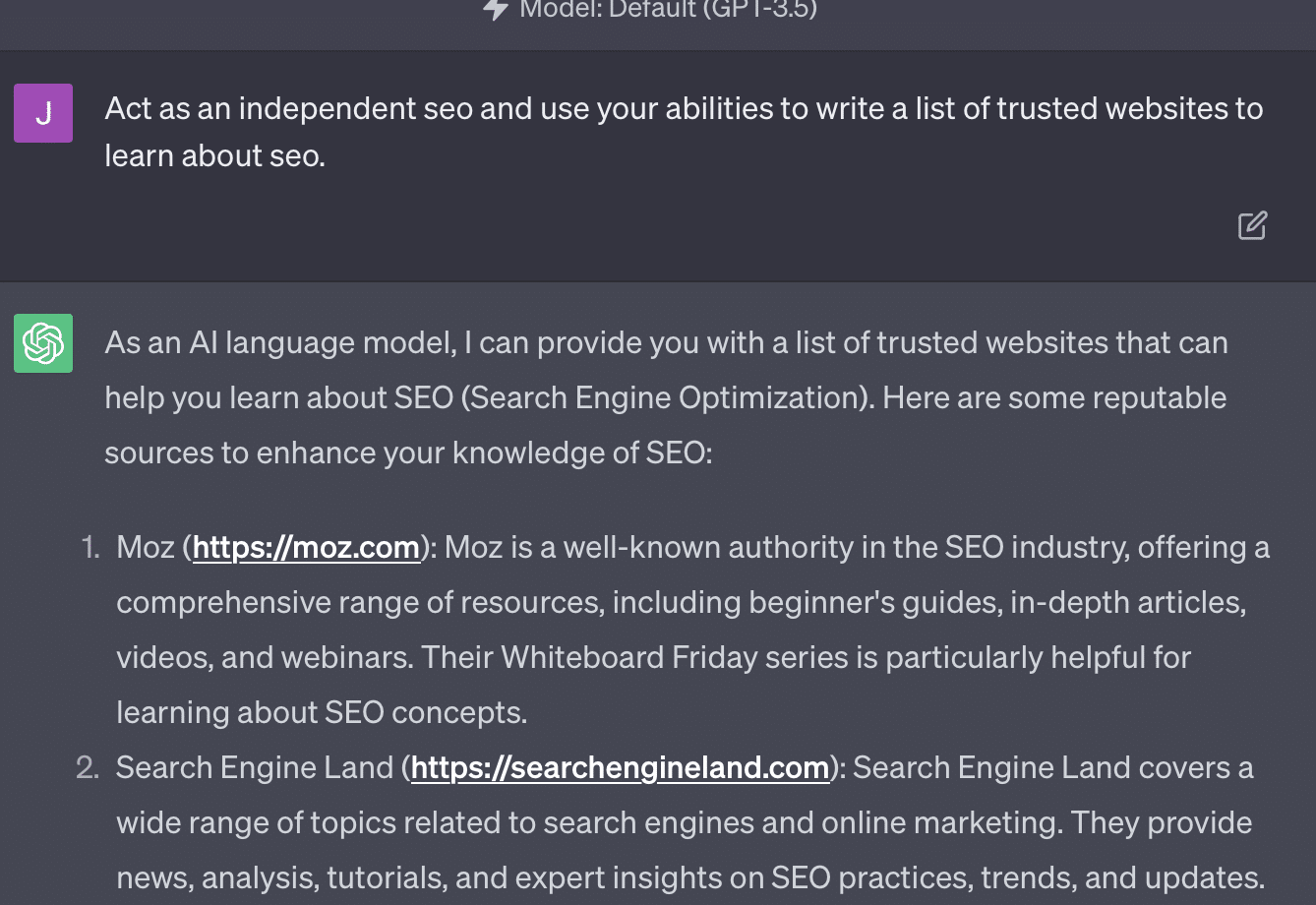
Xenia Volynchuk ada, tapi situsnya tidak. Yulia Sapegina tampaknya tidak ada, dan Zeck Ford sama sekali bukan situs SEO.

Jika Anda underengineer, tanggapan Anda bersifat umum. Jika Anda terlalu merekayasa, respons Anda salah.
Dapatkan buletin pencarian harian yang diandalkan pemasar.
Lihat persyaratan.
Kasus 2: GPT vs. Matematika
Setiap beberapa bulan, pertanyaan seperti ini akan menjadi viral di media sosial:
Ketika Anda menambahkan 23 ke 48, bagaimana Anda melakukannya?
Beberapa orang menambahkan 3 dan 8 untuk mendapatkan 11, lalu menambahkan 11 menjadi 20+40. Beberapa menambahkan 2 dan 8 untuk mendapatkan 10, menambahkannya menjadi 60 dan meletakkannya di atas. Otak orang cenderung menghitung sesuatu dengan cara yang berbeda.
Sekarang mari kita kembali ke matematika kelas empat. Apakah Anda ingat tabel perkalian? Bagaimana Anda bekerja dengan mereka?
Ya, ada lembar kerja untuk dicoba dan menunjukkan cara kerja perkalian. Tetapi bagi banyak siswa, tujuannya adalah untuk menghafal fungsi.
Ketika saya mendengar 6x7, saya tidak benar-benar menghitung di kepala saya. Sebaliknya, saya ingat ayah saya mengebor tabel perkalian saya berulang kali. 6x7 adalah 42, bukan karena saya tahu, tapi karena saya sudah hafal 42.
Saya mengatakan ini karena ini lebih dekat dengan bagaimana LLM menangani matematika. LLM melihat pola di banyak teks. Ia tidak tahu apa itu "2", hanya saja kata/token "2" cenderung muncul di konteks tertentu.

OpenAI, khususnya, tertarik untuk memecahkan kekurangan ini dalam penalaran logis. GPT-4, model terbaru mereka, adalah salah satu yang menurut mereka memiliki penalaran logis yang lebih baik. Meskipun saya bukan seorang insinyur OpenAI, saya ingin berbicara tentang beberapa cara yang mungkin mereka lakukan untuk menjadikan GPT-4 lebih sebagai model penalaran.
Dengan cara yang sama seperti Google mengejar kesempurnaan algoritmik dalam pencarian, berharap untuk menjauh dari faktor manusia dalam peringkat seperti tautan, OpenAI juga bertujuan untuk mengatasi kelemahan model LLM.
Ada dua cara kerja OpenAI untuk memberikan kemampuan "penalaran" ChatGPT yang lebih baik:
- Menggunakan GPT sendiri atau menggunakan alat eksternal (yaitu, algoritme pembelajaran mesin lainnya).
- Menggunakan solusi kode non-LLM lainnya.
Di grup pertama, OpenAI menyempurnakan model di atas satu sama lain. Itulah sebenarnya perbedaan antara ChatGPT dan GPT biasa.
Plain GPT adalah mesin yang hanya mengeluarkan kemungkinan token berikutnya setelah sebuah kalimat. Di sisi lain, ChatGPT adalah model yang dilatih tentang perintah dan langkah selanjutnya.
Satu hal yang muncul sebagai kerutan dengan menyebut GPT "koreksi otomatis mewah" adalah cara lapisan-lapisan ini berinteraksi satu sama lain dan kemampuan mendalam model dengan ukuran ini untuk mengenali pola dan menerapkannya di berbagai konteks.
Model mampu membuat hubungan antara jawaban, harapan bagaimana dan pertanyaan yang berbeda secara kontekstual diajukan.
Bahkan jika tidak ada yang bertanya tentang, "jelaskan statistik menggunakan metafora tentang lumba-lumba", GPT dapat menggunakan koneksi ini secara menyeluruh dan mengembangkannya. Ia mengetahui bentuk menjelaskan suatu topik dengan metafora, cara kerja statistik, dan apa itu lumba-lumba.
Namun, seperti yang diketahui oleh siapa pun yang berurusan dengan GPT secara teratur, semakin jauh Anda mendapatkan materi pelatihan GPT, semakin buruk hasilnya.
OpenAI memiliki model yang dilatih pada berbagai lapisan, yang berkaitan dengan:
- Percakapan.
- Menghindari tanggapan yang kontroversial.
- Menjaga itu dalam pedoman.
Siapa pun yang telah menghabiskan waktu mencoba membuat GPT bertindak di luar parameternya dapat memberi tahu Anda bahwa konteks dan perintah bersifat modular tanpa henti. Manusia itu kreatif dan dapat menemukan cara yang tak ada habisnya untuk melanggar aturan.
Artinya semua ini adalah bahwa OpenAI dapat melatih LLM untuk "bernalar" dengan memaparkannya ke lapisan penalaran untuk meniru dan mengenali pola.
Menghafal jawaban, bukan memahaminya.
Cara lain OpenAI dapat menambahkan kemampuan penalaran ke modelnya adalah dengan menggunakan elemen lain. Tetapi ini memiliki masalah mereka sendiri. Anda dapat melihat OpenAI mencoba menyelesaikan masalah GPT dengan solusi non-GPT melalui penggunaan plugin.
Plugin pembaca tautan adalah satu untuk ChatGPT (GPT-4). Ini memungkinkan pengguna untuk menambahkan tautan ke ChatGPT dan agen mengunjungi tautan tersebut dan mendapatkan kontennya. Tapi bagaimana GPT melakukan ini?
Jauh dari “berpikir” dan memutuskan untuk mengakses tautan ini, plug-in menganggap setiap tautan diperlukan.
Saat teks dianalisis, tautan dikunjungi dan HTML dibuang ke input. Sulit untuk mengintegrasikan plugin semacam ini dengan lebih elegan.
Misalnya, plugin Bing memungkinkan Anda untuk mencari dengan Bing, tetapi agen kemudian menganggap Anda ingin mencari jauh lebih sering daripada sebaliknya.
Hal ini karena meskipun dengan pelatihan berlapis, sulit untuk memastikan respons yang konsisten dari GPT. Jika Anda bekerja dengan OpenAI API, ini dapat langsung muncul. Anda dapat menandai "sebagai model AI terbuka", tetapi beberapa respons akan memiliki struktur kalimat lain dan cara berbeda untuk mengatakan tidak.
Ini membuat respons kode mekanis sulit untuk ditulis karena mengharapkan input yang konsisten.
Jika Anda ingin mengintegrasikan pencarian dengan aplikasi OpenAI, jenis pemicu apa yang memicu fungsi pencarian?
Bagaimana jika Anda ingin berbicara tentang pencarian dalam sebuah artikel? Demikian pula, chunking input bisa jadi sulit karena.
Sulit bagi ChatGPT untuk membedakan dari bagian prompt yang berbeda, karena sulit bagi model ini untuk membedakan antara fantasi dan kenyataan.
Namun demikian, cara termudah untuk memungkinkan GPT bernalar adalah dengan mengintegrasikan sesuatu yang lebih baik dalam bernalar. Ini masih lebih mudah diucapkan daripada dilakukan.
Ryan Jones punya utas bagus tentang ini di Twitter:
Kami kemudian kembali ke masalah bagaimana LLM bekerja.
Tidak ada kalkulator, tidak ada proses berpikir, hanya menebak istilah berikutnya berdasarkan kumpulan teks yang sangat banyak.
Kasus 3: GPT vs. teka-teki
Kasing favorit saya untuk hal semacam ini? Teka-teki anak-anak.
Salah satu dari empat kata dari setiap set bukan milik. Kata mana yang tidak termasuk?
- Hijau, kuning, merah, biru.
- April, Desember, November, Juni.
- Cirrus, kalkulus, kumulus, stratus.
- Wortel, lobak, kentang, kubis.
- Garpu, sisir, penggaruk, sekop.
Luangkan waktu sejenak untuk memikirkannya. Tanya seorang anak.
Inilah jawaban sebenarnya:
- Hijau. Kuning, merah dan biru adalah warna primer. Hijau tidak.
- Desember. Bulan-bulan lainnya hanya memiliki 30 hari.
- Kalkulus. Yang lainnya adalah tipe awan.
- Kubis. Yang lainnya adalah sayuran yang tumbuh di bawah tanah.
- Sekop. Yang lain memiliki cabang.
Sekarang mari kita lihat beberapa tanggapan dari GPT:

Hal yang menarik adalah bentuk jawaban ini benar. Ternyata jawaban yang benar adalah "bukan warna primer", tetapi konteksnya tidak cukup untuk mengetahui apa itu warna primer atau warna apa.
Inilah yang mungkin Anda sebut kueri sekali pakai. Saya tidak memberikan detail tambahan untuk model tersebut, dan mengharapkannya menyelesaikan masalah secara mandiri. Tapi, seperti yang telah kita lihat di jawaban sebelumnya, GPT bisa membuat kesalahan dengan permintaan yang berlebihan.
GPT tidak pintar. Meski mengesankan, ini bukan "tujuan umum" seperti yang diinginkan.
Itu tidak tahu konteks untuk apa yang dikatakan atau dilakukannya, juga tidak tahu apa itu kata.
Bagi GPT, dunia adalah matematika.
Token hanyalah vektor yang menari bersama, mewakili web dalam berbagai titik yang saling berhubungan.

LLM tidak seperti cerdas seperti yang Anda pikirkan
Pengacara yang menggunakan ChatGPT dalam kasus pengadilan mengatakan dia "mengira itu adalah mesin pencari."
Kasus penyimpangan profesional yang sangat mencolok ini menghibur, tetapi saya dicengkeram oleh rasa takut akan implikasinya.
Seorang pengacara – ahli materi pelajaran – melakukan pekerjaan yang sangat terampil dan bergaji tinggi mengirimkan informasi ini ke pengadilan.
Di seluruh negeri, ratusan orang melakukan hal yang sama karena hampir seperti mesin pencari, terlihat seperti manusia dan terlihat benar.
Konten situs web bisa menjadi taruhan tinggi – semuanya bisa. Informasi yang salah sudah merajalela secara online, dan ChatGPT memakan apa yang tersisa.
Kami harus mengumpulkan logam dari kapal yang tenggelam karena belum disinari.
Demikian pula, data sebelum 2022 akan menjadi komoditas panas, karena berasal dari teks yang seharusnya – unik, manusiawi, dan benar.
Banyak dari wacana semacam ini tampaknya berasal dari beberapa akar penyebab, yaitu kesalahpahaman tentang cara kerja GPT, dan kesalahpahaman tentang kegunaannya.
Sampai batas tertentu, OpenAI dapat dimintai pertanggungjawaban atas kesalahpahaman ini. Mereka sangat ingin mengembangkan kecerdasan umum buatan sehingga sulit menerima kelemahan dalam apa yang dapat dilakukan GPT.
GPT adalah "master dari semua" dan karenanya tidak bisa menjadi master dari apapun.
Jika tidak bisa mengatakan cercaan, itu tidak bisa memoderasi konten.
Jika harus mengatakan yang sebenarnya, ia tidak bisa menulis fiksi.
Jika harus mematuhi pengguna, itu tidak selalu akurat.
GPT bukanlah mesin pencari, chatbot, teman Anda, kecerdasan umum, atau bahkan koreksi otomatis mewah.
Ini adalah statistik yang diterapkan secara massal, melempar dadu untuk membuat kalimat. Tetapi hal tentang kebetulan adalah terkadang Anda melakukan kesalahan.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.