
Panduan SEO untuk memahami model bahasa besar (LLM)
Diterbitkan: 2023-05-08Haruskah saya menggunakan model bahasa besar untuk penelitian kata kunci? Bisakah model ini berpikir? Apakah ChatGPT teman saya?
Jika Anda telah bertanya pada diri sendiri pertanyaan-pertanyaan ini, panduan ini adalah untuk Anda.
Panduan ini mencakup apa yang perlu diketahui SEO tentang model bahasa besar, pemrosesan bahasa alami, dan segala sesuatu di antaranya.
Model bahasa besar, pemrosesan bahasa alami, dan lainnya dalam istilah sederhana
Ada dua cara untuk membuat seseorang melakukan sesuatu – menyuruh mereka melakukannya atau berharap mereka melakukannya sendiri.
Dalam ilmu komputer, pemrograman memerintahkan robot untuk melakukannya, sementara pembelajaran mesin berharap robot melakukannya sendiri. Yang pertama adalah pembelajaran mesin yang diawasi, dan yang terakhir adalah pembelajaran mesin yang tidak diawasi.
Pemrosesan bahasa alami (NLP) adalah cara untuk memecah teks menjadi angka dan kemudian menganalisisnya menggunakan komputer.
Komputer menganalisis pola dalam kata-kata dan, seiring perkembangannya, dalam hubungan antar kata.
Model pembelajaran mesin bahasa alami tanpa pengawasan dapat dilatih pada berbagai jenis kumpulan data.
Misalnya, jika Anda melatih model bahasa tentang rata-rata ulasan film "Waterworld", Anda akan mendapatkan hasil yang bagus dalam menulis (atau memahami) ulasan film "Waterworld".
Jika Anda melatihnya pada dua ulasan positif yang saya lakukan untuk film "Waterworld", itu hanya akan memahami ulasan positif tersebut.
Model bahasa besar (LLM) adalah jaringan saraf dengan lebih dari satu miliar parameter. Mereka sangat besar sehingga lebih umum. Mereka tidak hanya dilatih tentang ulasan positif dan negatif untuk "Waterworld", tetapi juga tentang komentar, artikel Wikipedia, situs berita, dan banyak lagi.
Proyek pembelajaran mesin banyak bekerja dengan konteks – hal-hal di dalam dan di luar konteks.
Jika Anda memiliki proyek pembelajaran mesin yang bekerja untuk mengidentifikasi bug dan menampilkannya sebagai kucing, itu tidak akan bagus untuk proyek itu.
Inilah mengapa hal-hal seperti mobil self-driving sangat sulit: ada begitu banyak masalah di luar konteks sehingga sangat sulit untuk menggeneralisasi pengetahuan tersebut.
LLM tampak dan bisa jauh lebih umum daripada proyek pembelajaran mesin lainnya. Ini karena ukuran data yang sangat besar dan kemampuan untuk mengolah miliaran hubungan yang berbeda.
Mari kita bicara tentang salah satu teknologi terobosan yang memungkinkan hal ini – transformer.
Menjelaskan transformer dari awal
Suatu jenis arsitektur jaringan saraf, transformer telah merevolusi bidang NLP.
Sebelum transformer, sebagian besar model NLP mengandalkan teknik yang disebut jaringan saraf berulang (RNN), yang memproses teks secara berurutan, satu kata dalam satu waktu. Pendekatan ini memiliki keterbatasan, seperti lambat dan kesulitan menangani ketergantungan jangka panjang dalam teks.
Transformer mengubah ini.
Dalam makalah penting tahun 2017, “Perhatian Adalah Yang Anda Butuhkan,” Vaswani et al. memperkenalkan arsitektur transformator.
Alih-alih memproses teks secara berurutan, transformer menggunakan mekanisme yang disebut "perhatian diri" untuk memproses kata-kata secara paralel, memungkinkan mereka menangkap ketergantungan jarak jauh dengan lebih efisien.
Arsitektur sebelumnya termasuk RNN dan algoritma memori jangka pendek yang panjang.
Model berulang seperti ini (dan masih) biasa digunakan untuk tugas yang melibatkan urutan data, seperti teks atau ucapan.
Namun, model ini memiliki masalah. Mereka hanya dapat memproses data satu per satu, yang memperlambat mereka dan membatasi berapa banyak data yang dapat mereka gunakan. Pemrosesan berurutan ini sangat membatasi kemampuan model ini.
Mekanisme perhatian diperkenalkan sebagai cara berbeda dalam memproses data urutan. Mereka memungkinkan model untuk melihat semua bagian data sekaligus dan memutuskan bagian mana yang paling penting.
Ini bisa sangat membantu dalam banyak tugas. Namun, sebagian besar model yang menggunakan perhatian juga menggunakan pemrosesan berulang.
Pada dasarnya, mereka memiliki cara memproses data sekaligus tetapi masih perlu melihatnya secara berurutan. Makalah Vaswani et al. melayang, “Bagaimana jika kita hanya menggunakan mekanisme perhatian?”
Perhatian adalah cara model untuk fokus pada bagian tertentu dari urutan input saat memprosesnya. Misalnya, ketika kita membaca sebuah kalimat, kita secara alami lebih memperhatikan beberapa kata daripada yang lain, tergantung pada konteksnya dan apa yang ingin kita pahami.
Jika Anda melihat sebuah transformator, model menghitung skor untuk setiap kata dalam urutan input berdasarkan seberapa penting untuk memahami arti keseluruhan dari urutan tersebut.
Model kemudian menggunakan skor ini untuk menimbang pentingnya setiap kata dalam urutan, yang memungkinkannya untuk lebih fokus pada kata-kata penting dan lebih sedikit pada kata-kata yang tidak penting.
Mekanisme perhatian ini membantu model menangkap ketergantungan jangka panjang dan hubungan antara kata-kata yang mungkin berjauhan dalam urutan masukan tanpa harus memproses seluruh urutan secara berurutan.
Hal ini membuat transformator sangat kuat untuk tugas pemrosesan bahasa alami, karena dapat dengan cepat dan akurat memahami arti kalimat atau urutan teks yang lebih panjang.
Mari kita ambil contoh model transformator yang memproses kalimat "Kucing itu duduk di atas tikar".
Setiap kata dalam kalimat direpresentasikan sebagai vektor, rangkaian angka, menggunakan matriks penyemat. Katakanlah penyematan untuk setiap kata adalah:
- The : [0.2, 0.1, 0.3, 0.5]
- kucing : [0.6, 0.3, 0.1, 0.2]
- duduk : [0,1, 0,8, 0,2, 0,3]
- pada : [0.3, 0.1, 0.6, 0.4]
- yang : [0,5, 0,2, 0,1, 0,4]
- mat : [0.2, 0.4, 0.7, 0.5]
Kemudian, transformator menghitung skor untuk setiap kata dalam kalimat berdasarkan hubungannya dengan semua kata lain dalam kalimat tersebut.
Ini dilakukan dengan menggunakan produk titik dari setiap kata yang disematkan dengan semua kata lain dalam kalimat.
Misalnya, untuk menghitung skor kata "kucing", kita akan mengambil produk titik dari penyematannya dengan penyematan semua kata lainnya:
- “ Kucing “: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- “ kucing duduk “: 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- “ kucing di “: 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- “ kucing “: 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- “ alas kucing “: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Skor ini menunjukkan relevansi setiap kata dengan kata “kucing”. Transformator kemudian menggunakan skor ini untuk menghitung jumlah bobot kata penyematan, di mana bobotnya adalah skor.
Ini menciptakan vektor konteks untuk kata "kucing" yang mempertimbangkan hubungan antara semua kata dalam kalimat. Proses ini diulang untuk setiap kata dalam kalimat.
Anggap saja sebagai transformator yang menggambar garis di antara setiap kata dalam kalimat berdasarkan hasil dari setiap perhitungan. Beberapa garis lebih renggang, dan yang lainnya kurang.
Trafo adalah jenis model baru yang hanya menggunakan perhatian tanpa pemrosesan berulang. Ini membuatnya lebih cepat dan mampu menangani lebih banyak data.
Bagaimana GPT menggunakan transformer
Anda mungkin ingat bahwa dalam pengumuman BERT Google, mereka menyombongkan diri bahwa hal itu memungkinkan pencarian untuk memahami konteks lengkap dari suatu masukan. Ini mirip dengan bagaimana GPT dapat menggunakan transformer.
Mari kita gunakan analogi.
Bayangkan Anda memiliki sejuta monyet, masing-masing duduk di depan keyboard.
Setiap monyet secara acak menekan tombol pada keyboard mereka, menghasilkan rangkaian huruf dan simbol.
Beberapa string benar-benar tidak masuk akal, sementara yang lain mungkin menyerupai kata-kata nyata atau bahkan kalimat yang koheren.
Suatu hari, salah satu pelatih sirkus melihat seekor monyet telah menulis "Menjadi, atau tidak menjadi", jadi pelatih memberi monyet itu hadiah.
Monyet-monyet lain melihat ini dan mulai mencoba meniru monyet yang sukses, berharap mendapatkan hadiah mereka sendiri.
Seiring berjalannya waktu, beberapa monyet mulai secara konsisten menghasilkan string teks yang lebih baik dan koheren, sementara yang lain terus menghasilkan omong kosong.
Akhirnya, monyet dapat mengenali dan bahkan meniru pola koheren dalam teks.
LLM memiliki kaki di atas monyet karena LLM pertama kali dilatih pada miliaran potongan teks. Mereka sudah bisa melihat polanya. Mereka juga memahami vektor dan hubungan antara potongan-potongan teks ini.
Ini berarti mereka dapat menggunakan pola dan hubungan tersebut untuk menghasilkan teks baru yang menyerupai bahasa alami.
GPT, singkatan dari Generative Pre-trained Transformer, adalah model bahasa yang menggunakan transformer untuk menghasilkan teks bahasa alami.
Itu dilatih pada sejumlah besar teks dari internet, yang memungkinkannya mempelajari pola dan hubungan antara kata dan frasa dalam bahasa alami.
Model ini bekerja dengan memasukkan prompt atau beberapa kata teks dan menggunakan transformer untuk memprediksi kata apa yang akan muncul selanjutnya berdasarkan pola yang telah dipelajari dari data pelatihannya.
Model terus menghasilkan teks kata demi kata, menggunakan konteks kata sebelumnya untuk menginformasikan kata berikutnya.
GPT beraksi
Salah satu manfaat GPT adalah dapat menghasilkan teks bahasa alami yang sangat koheren dan relevan secara kontekstual.
Ini memiliki banyak aplikasi praktis, seperti membuat deskripsi produk atau menjawab pertanyaan layanan pelanggan. Itu juga dapat digunakan secara kreatif, seperti menghasilkan puisi atau cerita pendek.
Namun, itu hanya model bahasa. Itu dilatih berdasarkan data, dan data itu bisa kedaluwarsa atau salah.
- Ia tidak memiliki sumber pengetahuan.
- Itu tidak dapat mencari di internet.
- Itu tidak "tahu" apa pun.
Itu hanya menebak kata apa yang akan datang selanjutnya.
Mari kita lihat beberapa contoh:
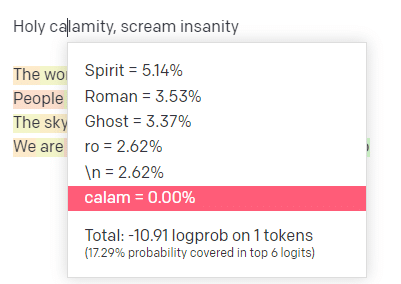
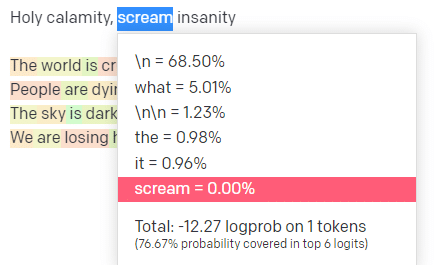
Di taman bermain OpenAI, saya telah menyambungkan baris pertama dari lagu klasik Handsome Boy Modeling School 'Holy calamity [[Bear Witness ii]]'.
Saya mengirimkan tanggapan sehingga kami dapat melihat kemungkinan jalur input dan output saya. Jadi mari kita telusuri setiap bagian dari apa yang dikatakan di sini.
Untuk kata/token pertama, saya masukan “Kudus.” Kita bisa melihat bahwa masukan selanjutnya yang paling diharapkan adalah Spirit, Roman, dan Ghost.
Kita juga dapat melihat bahwa enam hasil teratas hanya mencakup 17,29% dari kemungkinan yang akan terjadi selanjutnya: yang berarti ada ~82% kemungkinan lain yang tidak dapat kita lihat dalam visualisasi ini.
Mari kita bahas secara singkat berbagai masukan yang dapat Anda gunakan dalam hal ini dan bagaimana pengaruhnya terhadap keluaran Anda.
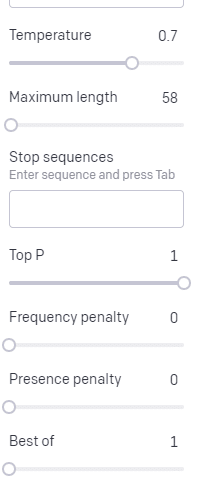
Temperatur adalah seberapa besar kemungkinan model mengambil kata-kata selain kata-kata dengan probabilitas tertinggi, P atas adalah cara memilih kata-kata tersebut.
Jadi untuk input “Holy Calamity”, P teratas adalah cara kita memilih kelompok token berikutnya [Ghost, Roman, Spirit], dan suhu adalah seberapa besar kemungkinan untuk memilih token yang paling mungkin vs. variasi yang lebih banyak.
Jika suhunya lebih tinggi, kemungkinan besar akan memilih token yang lebih kecil kemungkinannya .
Jadi suhu tinggi dan P puncak tinggi kemungkinan besar akan lebih liar. Itu memilih dari berbagai macam (P atas tinggi) dan lebih cenderung memilih token yang mengejutkan.


Sementara suhu tinggi tetapi P atas yang lebih rendah akan memilih opsi yang mengejutkan dari sampel kemungkinan yang lebih kecil:
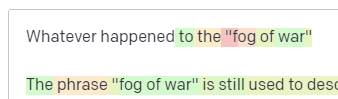

Dan menurunkan suhu hanya memilih token berikutnya yang paling mungkin:

Bermain dengan probabilitas ini, menurut pendapat saya, dapat memberi Anda wawasan yang baik tentang cara kerja model semacam ini.
Itu melihat kumpulan kemungkinan pilihan berikutnya berdasarkan apa yang sudah selesai.
Apa artinya ini sebenarnya?
Sederhananya, LLM mengambil kumpulan input, mengocoknya, dan mengubahnya menjadi output.
Saya pernah mendengar orang bercanda tentang apakah itu sangat berbeda dari orang.
Tapi itu tidak seperti orang – LLM tidak memiliki basis pengetahuan. Mereka tidak mengekstraksi informasi tentang suatu hal. Mereka menebak urutan kata berdasarkan yang terakhir.
Contoh lain: pikirkan sebuah apel. Apa yang terlintas dalam pikiran?
Mungkin Anda bisa memutar satu di pikiran Anda.
Mungkin Anda ingat aroma kebun apel, manisnya wanita pink, dll.
Mungkin Anda memikirkan Steve Jobs.
Sekarang mari kita lihat apa yang dikembalikan oleh prompt “think of an apple”.
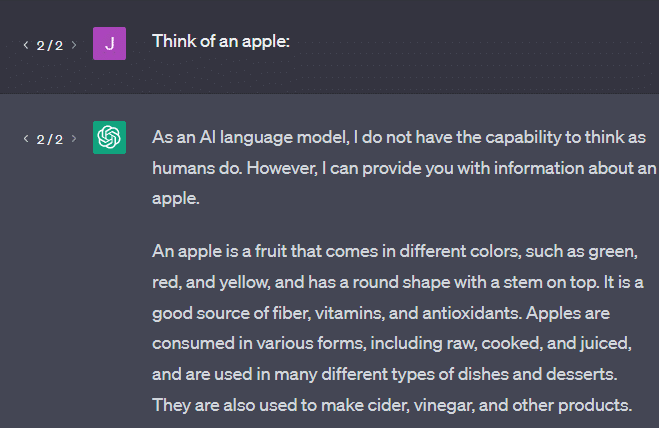
Anda mungkin pernah mendengar kata-kata "Stochastic Parrots" beredar pada saat ini.
Stochastic Parrots adalah istilah yang digunakan untuk menggambarkan LLM seperti GPT. Burung beo adalah burung yang meniru apa yang didengarnya.
Jadi, LLM seperti burung beo karena mereka menerima informasi (kata-kata) dan mengeluarkan sesuatu yang menyerupai apa yang mereka dengar. Tapi mereka juga stokastik , yang berarti mereka menggunakan probabilitas untuk menebak apa yang akan terjadi selanjutnya.
LLM pandai mengenali pola dan hubungan antar kata, tetapi mereka tidak memiliki pemahaman yang lebih dalam tentang apa yang mereka lihat. Itu sebabnya mereka sangat pandai menghasilkan teks bahasa alami tetapi tidak memahaminya.
Penggunaan yang baik untuk LLM
LLM bagus dalam tugas yang lebih umum.
Anda dapat menampilkan teks, dan tanpa pelatihan, ia dapat melakukan tugas dengan teks tersebut.
Anda dapat melemparkannya beberapa teks dan meminta analisis sentimen, memintanya untuk mentransfer teks itu ke markup terstruktur dan melakukan beberapa pekerjaan kreatif (misalnya, menulis garis besar).
Tidak apa-apa untuk hal-hal seperti kode. Untuk banyak tugas, hampir bisa membawa Anda ke sana.
Tapi sekali lagi, ini didasarkan pada probabilitas dan pola. Jadi, akan ada saatnya ia menangkap pola dalam masukan Anda yang tidak Anda ketahui keberadaannya.
Ini bisa positif (melihat pola yang tidak bisa dilihat manusia), tapi bisa juga negatif (kenapa direspon seperti ini?).
Itu juga tidak memiliki akses ke sumber data apa pun. SEO yang menggunakannya untuk mencari kata kunci peringkat akan mengalami kesulitan.
Itu tidak dapat mencari lalu lintas untuk kata kunci. Itu tidak memiliki informasi untuk data kata kunci di luar kata-kata itu.

Hal yang menarik tentang ChatGPT adalah bahwa ini adalah model bahasa yang tersedia dengan mudah yang dapat Anda gunakan di luar kotak pada berbagai tugas. Tapi itu bukan tanpa peringatan.
Baik digunakan untuk model ML lainnya
Saya mendengar orang mengatakan mereka menggunakan LLM untuk tugas-tugas tertentu, yang dapat dilakukan dengan lebih baik oleh algoritme dan teknik NLP lainnya.

Mari kita ambil contoh, ekstraksi kata kunci.
Jika saya menggunakan TF-IDF, atau teknik kata kunci lainnya, untuk mengekstrak kata kunci dari korpus, saya tahu kalkulasi apa yang digunakan untuk teknik tersebut.
Artinya, hasilnya akan standar, dapat direproduksi, dan saya tahu hasilnya akan terkait secara khusus dengan korpus itu.
Dengan LLM seperti ChatGPT, jika Anda meminta ekstraksi kata kunci, Anda belum tentu mendapatkan kata kunci yang diekstraksi dari korpus. Anda mendapatkan apa yang menurut GPT sebagai respons terhadap kata kunci corpus + ekstrak.
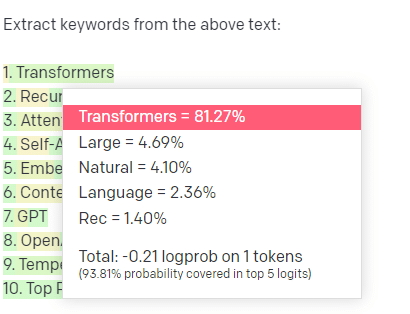
Ini mirip dengan tugas seperti pengelompokan atau analisis sentimen. Anda belum tentu mendapatkan hasil yang disesuaikan dengan parameter yang Anda tetapkan. Anda mendapatkan kemungkinan berdasarkan tugas serupa lainnya.
Sekali lagi, LLM tidak memiliki basis pengetahuan dan tidak ada informasi terkini. Mereka sering tidak dapat menelusuri web, dan mereka mengurai apa yang mereka dapatkan dari informasi sebagai token statistik. Pembatasan berapa lama memori LLM bertahan adalah karena faktor-faktor ini.
Hal lain adalah model ini tidak bisa berpikir. Saya hanya menggunakan kata "berpikir" beberapa kali di sepanjang bagian ini karena sangat sulit untuk tidak menggunakannya ketika berbicara tentang proses ini.
Kecenderungannya ke arah antropomorfisme, bahkan ketika membahas statistik mewah.
Tetapi ini berarti bahwa jika Anda mempercayakan LLM untuk tugas apa pun yang membutuhkan "pemikiran", Anda tidak mempercayai makhluk yang berpikir.
Anda memercayai analisis statistik tentang tanggapan ratusan orang aneh internet terhadap token serupa.
Jika Anda akan mempercayai penghuni internet dengan suatu tugas, maka Anda dapat menggunakan LLM. Jika tidak…
Hal-hal yang tidak boleh menjadi model ML
Sebuah chatbot yang dijalankan melalui model GPT (GPT-J) dilaporkan mendorong seorang pria untuk bunuh diri. Kombinasi faktor dapat menyebabkan kerusakan nyata, termasuk:
- Orang antropomorfisasi tanggapan ini.
- Percaya mereka sempurna.
- Menggunakannya di tempat-tempat di mana manusia perlu berada di dalam mesin.
- Dan banyak lagi.
Meskipun Anda mungkin berpikir, “Saya seorang SEO. Saya tidak memiliki andil dalam sistem yang dapat membunuh seseorang!”
Pikirkan tentang halaman YMYL dan bagaimana Google mempromosikan konsep seperti EEAT.
Apakah Google melakukan ini karena mereka ingin mengganggu SEO, atau karena mereka tidak ingin disalahkan atas kerugian itu?
Bahkan dalam sistem dengan basis pengetahuan yang kuat, kerusakan dapat terjadi.
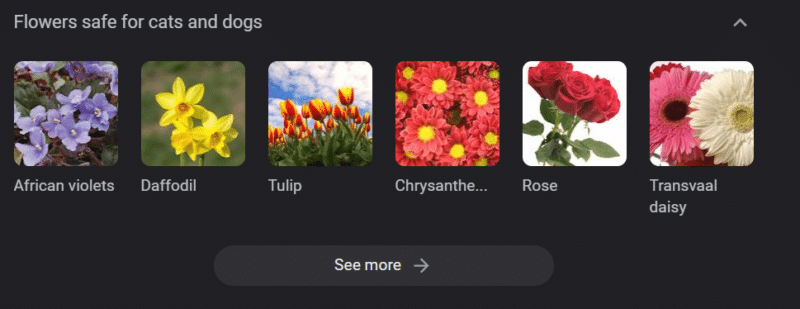
Di atas adalah korsel pengetahuan Google untuk "bunga yang aman untuk kucing dan anjing". Daffodil ada di daftar itu meski beracun bagi kucing.
Katakanlah Anda membuat konten untuk situs web dokter hewan dalam skala besar menggunakan GPT. Anda memasukkan banyak kata kunci dan melakukan ping ke ChatGPT API.
Anda memiliki pekerja lepas yang membaca semua hasil, dan mereka bukan ahli subjek. Mereka tidak mengambil masalah.
Anda mempublikasikan hasilnya, yang mendorong pembelian daffodil untuk pemilik kucing.
Anda membunuh kucing seseorang.
Tidak secara langsung. Mungkin mereka bahkan tidak tahu bahwa situs itu khususnya.
Mungkin situs dokter hewan lain mulai melakukan hal yang sama dan saling memberi makan.
Hasil pencarian Google teratas untuk "apakah daffodil beracun bagi kucing" adalah situs yang mengatakan tidak.
Pekerja lepas lain yang membaca konten AI lainnya – halaman demi halaman konten AI – benar-benar memeriksa fakta. Tetapi sistem sekarang memiliki informasi yang salah.
Saat membahas ledakan AI saat ini, saya sering menyebut Therac-25. Ini adalah studi kasus terkenal penyimpangan komputer.
Pada dasarnya, itu adalah mesin terapi radiasi, yang pertama hanya menggunakan mekanisme penguncian komputer. Kesalahan dalam perangkat lunak berarti orang mendapat puluhan ribu kali dosis radiasi yang seharusnya mereka miliki.
Sesuatu yang selalu menonjol bagi saya adalah perusahaan secara sukarela menarik kembali dan memeriksa model-model ini.
Tetapi mereka berasumsi bahwa karena teknologinya sudah maju dan perangkat lunaknya "sempurna", masalahnya ada hubungannya dengan bagian mekanis mesin.
Jadi, mereka memperbaiki mekanismenya tetapi tidak memeriksa perangkat lunaknya – dan Therac-25 tetap bertahan di pasaran.
FAQ dan kesalahpahaman
Mengapa ChatGPT membohongi saya?
Satu hal yang saya lihat dari beberapa pemikir terhebat di generasi kita dan juga pemberi pengaruh di Twitter adalah keluhan bahwa ChatGPT “berbohong” kepada mereka. Hal ini disebabkan oleh beberapa kesalahpahaman secara bersamaan:
- ChatGPT itu memiliki "keinginan".
- Bahwa ia memiliki basis pengetahuan.
- Bahwa para teknolog di balik teknologi memiliki semacam agenda di luar "menghasilkan uang" atau "membuat hal yang keren".
Bias dimasukkan ke dalam setiap bagian kehidupan Anda sehari-hari. Begitu juga pengecualian untuk bias ini.
Sebagian besar pengembang perangkat lunak saat ini adalah pria: Saya seorang pengembang perangkat lunak dan seorang wanita.
Melatih AI berdasarkan kenyataan ini akan membuatnya selalu berasumsi bahwa pengembang perangkat lunak adalah laki-laki, dan itu tidak benar.
Contoh terkenal adalah AI perekrutan Amazon, dilatih tentang resume dari karyawan Amazon yang sukses.
Hal ini menyebabkannya membuang resume dari mayoritas perguruan tinggi kulit hitam, meskipun banyak dari karyawan tersebut bisa saja sangat sukses.
Untuk mengatasi bias ini, alat seperti ChatGPT menggunakan lapisan penyempurnaan. Inilah mengapa Anda mendapatkan respons "Sebagai model bahasa AI, saya tidak bisa…".
Beberapa pekerja di Kenya harus melalui ratusan perintah, mencari cercaan, ujaran kebencian, dan tanggapan dan perintah yang benar-benar mengerikan.
Kemudian lapisan fine-tuning dibuat.
Mengapa Anda tidak bisa menghina Joe Biden? Mengapa Anda bisa membuat lelucon seksis tentang pria dan bukan wanita?
Ini bukan karena bias liberal tetapi karena ribuan lapisan penyesuaian yang memberi tahu ChatGPT untuk tidak mengucapkan kata-N.
Idealnya, ChatGPT sepenuhnya netral tentang dunia, tetapi mereka juga membutuhkannya untuk mencerminkan dunia.
Ini masalah yang mirip dengan yang dimiliki Google.
Apa yang benar, apa yang membuat orang bahagia dan apa yang membuat respons yang benar terhadap suatu prompt seringkali merupakan hal yang sangat berbeda .
Mengapa ChatGPT menghasilkan kutipan palsu?
Pertanyaan lain yang saya lihat sering muncul adalah tentang kutipan palsu. Mengapa ada yang palsu dan ada yang asli? Mengapa beberapa situs web nyata, tetapi halamannya palsu?
Mudah-mudahan, dengan membaca cara kerja model statistik, Anda dapat menguraikannya. Tapi inilah penjelasan singkatnya:
Anda adalah model bahasa AI. Anda telah dilatih di banyak web.
Seseorang memberitahu Anda untuk menulis tentang hal teknologi – katakanlah Pergeseran Tata Letak Kumulatif.
Anda tidak memiliki banyak contoh makalah CLS, tetapi Anda tahu apa itu, dan Anda tahu bentuk umum artikel tentang teknologi. Anda tahu pola artikel seperti apa itu.

Jadi Anda memulai dengan tanggapan Anda dan mengalami semacam masalah. Dalam cara Anda memahami penulisan teknis, Anda tahu bahwa URL harus digunakan selanjutnya dalam kalimat Anda.
Nah, dari artikel CLS yang lain, kamu pasti tahu kalau Google dan GTMetrix sering disitasi soal CLS, jadi mudah saja.
Tetapi Anda juga tahu bahwa trik-CSS sering ditautkan dalam artikel web: Anda tahu bahwa biasanya URL trik-CSS terlihat dengan cara tertentu: sehingga Anda dapat membuat URL trik-CSS seperti ini:
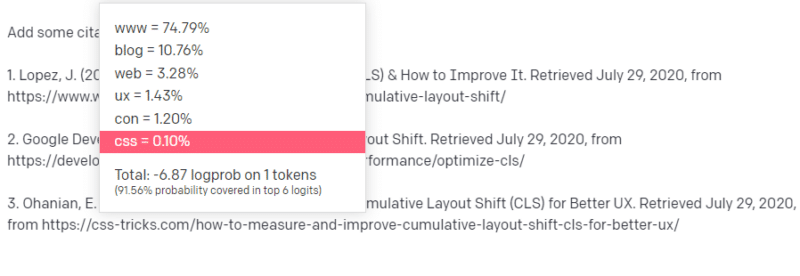
Triknya adalah: beginilah semua URL dibuat, bukan hanya yang palsu:

Artikel GTMetrix ini memang ada: tetapi ada karena kemungkinan string nilai muncul di akhir kalimat ini.
GPT dan model serupa tidak dapat membedakan antara kutipan asli dan palsu.
Satu-satunya cara untuk melakukan pemodelan itu adalah dengan menggunakan sumber lain (basis pengetahuan, Python, dll.) Untuk mengurai perbedaan itu dan memeriksa hasilnya.
Apa itu 'burung beo stokastik'?
Saya tahu saya sudah membahas ini, tetapi perlu diulang. Stochastic Parrots adalah cara untuk menggambarkan apa yang terjadi ketika model bahasa besar tampak bersifat generalis.
Bagi LLM, omong kosong dan kenyataan adalah sama. Mereka melihat dunia seperti seorang ekonom, sebagai kumpulan statistik dan angka yang menggambarkan realitas.
Anda tahu kutipan, "Ada tiga jenis kebohongan: kebohongan, kebohongan terkutuk, dan statistik."
LLM adalah sekumpulan besar statistik.
LLM tampak koheren, tetapi itu karena pada dasarnya kita melihat hal-hal yang tampak seperti manusia sebagai manusia.
Demikian pula, model chatbot mengaburkan banyak permintaan dan informasi yang Anda perlukan agar respons GPT sepenuhnya koheren.
Saya seorang pengembang: mencoba menggunakan LLM untuk men-debug kode saya memiliki hasil yang sangat bervariasi. Jika ini adalah masalah yang mirip dengan yang sering dialami orang saat online, maka LLM dapat mengetahui dan memperbaiki hasil tersebut.
Jika itu adalah masalah yang belum pernah ditemui sebelumnya, atau merupakan bagian kecil dari korpus, maka itu tidak akan memperbaiki apa pun.
Mengapa GPT lebih baik daripada mesin telusur?
Saya mengatakan ini dengan cara yang pedas. Saya tidak berpikir GPT lebih baik dari mesin pencari. Saya khawatir orang-orang telah mengganti pencarian dengan ChatGPT.
Salah satu bagian yang kurang dikenal dari ChatGPT adalah keberadaannya untuk mengikuti instruksi. Anda dapat memintanya untuk melakukan apa saja.
Tapi ingat, itu semua berdasarkan statistik kata berikutnya dalam sebuah kalimat, bukan kebenarannya.
Jadi jika Anda mengajukan pertanyaan yang tidak memiliki jawaban yang baik tetapi menanyakannya dengan cara yang wajib untuk dijawab, Anda akan mendapatkan jawaban yang buruk.
Memiliki respons yang dirancang untuk Anda dan di sekitar Anda memang lebih menghibur, tetapi dunia adalah kumpulan pengalaman.
Semua masukan ke dalam LLM diperlakukan sama: tetapi beberapa orang memiliki pengalaman, dan tanggapan mereka akan lebih baik daripada berbagai tanggapan orang lain.
Seorang pakar lebih berharga dari seribu pemikiran.
Apakah ini fajar AI? Apakah Skynet ada di sini?
Koko si Gorila adalah seekor kera yang diajari bahasa isyarat. Para peneliti dalam studi linguistik melakukan banyak penelitian yang menunjukkan bahwa kera dapat diajari bahasa.
Herbert Terrace kemudian menemukan bahwa kera tidak menyusun kalimat atau kata, tetapi hanya meniru penangan manusia mereka.
Eliza adalah seorang terapis mesin, salah satu chatterbots (chatbots) pertama.
Orang-orang melihatnya sebagai pribadi: seorang terapis yang mereka percayai dan rawat. Mereka meminta peneliti untuk berduaan dengannya.
Bahasa melakukan sesuatu yang sangat spesifik pada otak manusia. Orang mendengar sesuatu berkomunikasi dan mengharapkan pemikiran di baliknya.
LLM sangat mengesankan tetapi dengan cara yang menunjukkan luasnya pencapaian manusia.
LLM tidak memiliki surat wasiat. Mereka tidak bisa melarikan diri. Mereka tidak dapat mencoba dan mengambil alih dunia.
Mereka adalah cermin: cerminan orang dan pengguna secara khusus.
Satu-satunya pemikiran yang ada adalah representasi statistik dari ketidaksadaran kolektif.
Apakah GPT mempelajari seluruh bahasa dengan sendirinya?
Sundar Pichai, CEO Google, melanjutkan "60 Menit" dan mengklaim bahwa model bahasa Google mempelajari bahasa Bengali.
Model dilatih pada teks-teks tersebut. Tidaklah benar bahwa ia “berbicara dalam bahasa asing yang tidak pernah dilatih untuk mengetahuinya”.
Ada kalanya AI melakukan hal-hal yang tidak terduga, tetapi itu sendiri sudah diharapkan.
Saat Anda melihat pola dan statistik dalam skala besar, pasti ada saatnya pola tersebut mengungkapkan sesuatu yang mengejutkan.
Hal ini benar-benar mengungkapkan bahwa banyak orang C-suite dan pemasaran yang menjajakan AI dan ML tidak benar-benar memahami cara kerja sistem.
Saya pernah mendengar beberapa orang yang sangat pintar berbicara tentang properti yang muncul, kecerdasan umum buatan (AGI), dan hal-hal futuristik lainnya.
Saya mungkin hanya seorang insinyur operasi ML pedesaan yang sederhana, tetapi ini menunjukkan betapa banyak hype, janji, fiksi ilmiah, dan kenyataan yang digabungkan ketika berbicara tentang sistem ini.
Elizabeth Holmes, pendiri Theranos yang terkenal, disalibkan karena membuat janji yang tidak dapat ditepati.
Tetapi siklus membuat janji yang mustahil adalah bagian dari budaya startup dan menghasilkan uang. Perbedaan antara hype Theranos dan AI adalah Theranos tidak bisa memalsukannya terlalu lama.
Apakah GPT kotak hitam? Apa yang terjadi pada data saya di GPT?
GPT, sebagai model, bukan kotak hitam. Anda dapat melihat kode sumber untuk GPT-J dan GPT-Neo.
GPT OpenAI, bagaimanapun, adalah kotak hitam. OpenAI belum dan kemungkinan besar akan mencoba untuk tidak merilis modelnya, karena Google tidak merilis algoritmenya.
Tapi itu bukan karena algoritmanya terlalu berbahaya. Jika itu benar, mereka tidak akan menjual langganan API kepada pria konyol mana pun yang memiliki komputer. Itu karena nilai basis kode berpemilik itu.
Saat Anda menggunakan alat OpenAI, Anda melatih dan memberi makan API mereka pada input Anda. Ini berarti semua yang Anda masukkan ke dalam OpenAI akan memberinya makan.
Artinya orang yang telah menggunakan model GPT OpenAI pada data pasien untuk membantu menulis catatan dan hal lainnya telah melanggar HIPAA. Informasi tersebut sekarang ada dalam model, dan akan sangat sulit untuk mengekstraknya.
Karena begitu banyak orang yang kesulitan memahami hal ini, kemungkinan besar model tersebut berisi banyak sekali data pribadi, tinggal menunggu permintaan yang tepat untuk merilisnya.
Mengapa GPT dilatih tentang ujaran kebencian?
Hal lain yang sering muncul adalah text corpus GPT yang dilatih berisi ujaran kebencian.
Sampai batas tertentu, OpenAI perlu melatih modelnya untuk menanggapi ujaran kebencian, jadi OpenAI perlu memiliki korpus yang menyertakan beberapa istilah tersebut.
OpenAI telah mengklaim menghapus pidato kebencian semacam itu dari sistem, tetapi dokumen sumbernya mencakup 4chan dan banyak situs kebencian.
Merayapi web, menyerap bias.
Tidak ada cara mudah untuk menghindari hal ini. Bagaimana Anda bisa mengenali atau memahami kebencian, bias, dan kekerasan tanpa menjadikannya sebagai bagian dari perangkat pelatihan Anda?
Bagaimana Anda menghindari bias dan memahami bias implisit dan eksplisit saat Anda adalah agen mesin yang secara statistik memilih token berikutnya dalam sebuah kalimat?
TL;DR
Hype dan misinformasi saat ini merupakan elemen utama dari ledakan AI. Itu tidak berarti tidak ada kegunaan yang sah: teknologi ini luar biasa dan bermanfaat.
Tetapi bagaimana teknologi tersebut dipasarkan dan bagaimana orang menggunakannya dapat menumbuhkan informasi yang salah, plagiarisme, dan bahkan menyebabkan kerugian langsung.
Jangan gunakan LLM saat hidup dipertaruhkan. Jangan gunakan LLM saat algoritme lain akan bekerja lebih baik. Jangan tertipu oleh hype.
Memahami apa itu LLM - dan tidak - diperlukan
Saya merekomendasikan wawancara Adam Conover ini dengan Emily Bender dan Timnit Gebru.
LLM bisa menjadi alat yang luar biasa bila digunakan dengan benar. Ada banyak cara Anda dapat menggunakan LLM dan bahkan lebih banyak cara untuk menyalahgunakan LLM.
ChatGPT bukan teman Anda. Ini sekumpulan statistik. AGI tidak "sudah ada".
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.