
Spark vs Hadoop: Kerangka Data Besar Mana yang Akan Meningkatkan Bisnis Anda?
Diterbitkan: 2019-09-24“Data adalah bahan bakar Ekonomi Digital”
Dengan bisnis modern yang mengandalkan tumpukan data untuk lebih memahami konsumen dan pasar mereka, teknologi seperti Big Data mendapatkan momentum besar.
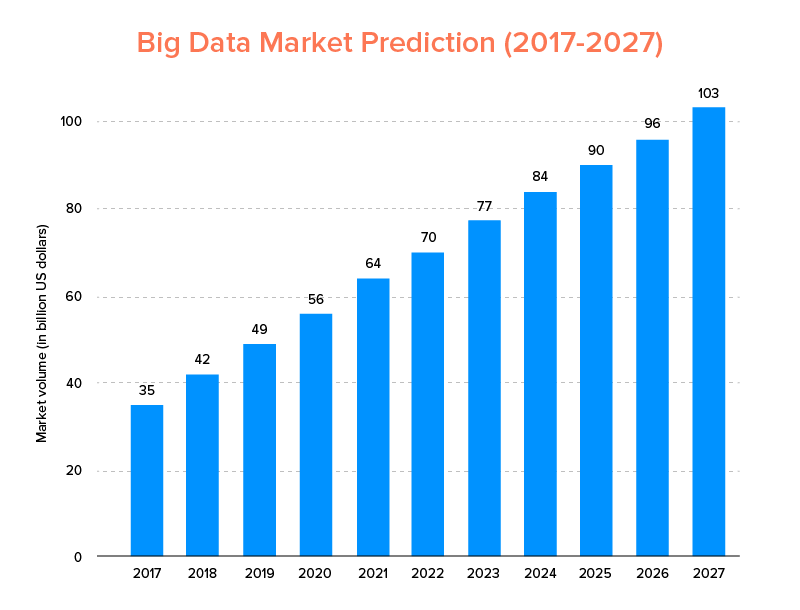
Big Data, seperti halnya AI, tidak hanya masuk dalam daftar tren teknologi teratas untuk tahun 2020 , tetapi juga diharapkan dapat digunakan oleh perusahaan rintisan dan perusahaan Fortune 500 untuk menikmati pertumbuhan bisnis yang eksponensial dan memastikan loyalitas pelanggan yang lebih tinggi. Indikasi yang jelas adalah bahwa pasar Big Data diperkirakan akan mencapai $103 miliar pada tahun 2027.
Sekarang, sementara ini di satu sisi setiap orang sangat termotivasi untuk mengganti alat analisis data tradisional mereka dengan Big Data – yang mempersiapkan dasar untuk kemajuan Blockchain dan AI, mereka juga bingung memilih alat Big data yang tepat. Mereka menghadapi dilema memilih antara Apache Hadoop dan Spark – dua raksasa dunia Big Data.
Jadi, dengan mempertimbangkan pemikiran ini, hari ini kami akan membahas artikel tentang Apache Spark vs Hadoop dan membantu Anda menentukan opsi mana yang tepat untuk kebutuhan Anda.
Tapi, pertama-tama, mari kita kenalan singkat tentang apa itu Hadoop dan Spark.
Apache Hadoop adalah kerangka kerja open-source, terdistribusi, dan berbasis Java yang memungkinkan pengguna untuk menyimpan dan memproses data besar di beberapa cluster komputer menggunakan konstruksi pemrograman sederhana. Ini terdiri dari berbagai modul yang bekerja sama untuk memberikan pengalaman yang ditingkatkan, yaitu: -
- Hadoop Umum
- Sistem File Terdistribusi Hadoop (HDFS)
- Benang Hadoop
- Peta Hadoop Kurangi
Padahal, Apache Spark adalah kerangka kerja data besar komputasi klaster terdistribusi open-source yang 'mudah digunakan' dan menawarkan layanan yang lebih cepat.
Dua kerangka kerja data besar didukung oleh banyak perusahaan besar karena serangkaian peluang yang mereka tawarkan.
Keuntungan dari Hadoop Big Data Framework
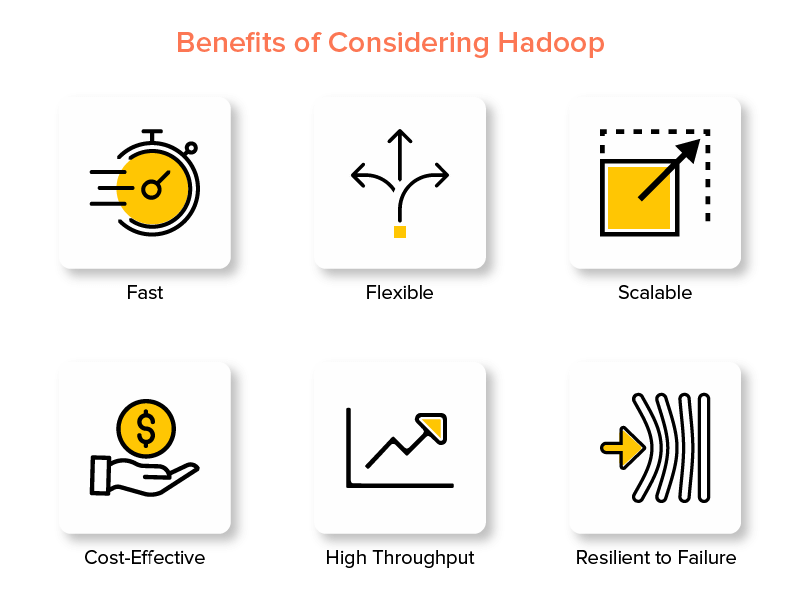
1. Cepat
Salah satu fitur Hadoop yang membuatnya populer di dunia big data adalah kecepatannya.
Metode penyimpanannya didasarkan pada sistem file terdistribusi yang terutama 'memetakan' data di mana pun berada di sebuah cluster. Selain itu, data dan alat yang digunakan untuk pemrosesan data biasanya tersedia di server yang sama, yang membuat pemrosesan data menjadi tugas yang tidak merepotkan dan lebih cepat.
Bahkan, telah ditemukan bahwa Hadoop dapat memproses terabyte data tidak terstruktur hanya dalam beberapa menit, sedangkan petabyte dalam hitungan jam.
2. Fleksibel
Hadoop, tidak seperti alat pemrosesan data tradisional, menawarkan fleksibilitas kelas atas.
Ini memungkinkan bisnis mengumpulkan data dari sumber yang berbeda (seperti media sosial, email, dll.), bekerja dengan tipe data yang berbeda (baik terstruktur dan tidak terstruktur), dan mendapatkan wawasan berharga untuk digunakan lebih lanjut untuk berbagai tujuan (seperti pemrosesan log, analisis kampanye pasar, deteksi penipuan, dll).
3. Dapat diukur
Keuntungan lain dari Hadoop adalah sangat skalabel. Platform, tidak seperti sistem basis data relasional tradisional (RDBMS) , memungkinkan bisnis untuk menyimpan dan mendistribusikan kumpulan data besar dari ratusan server yang beroperasi secara paralel.
4. Hemat Biaya
Apache Hadoop, jika dibandingkan dengan alat analisis data besar lainnya, jauh lebih murah. Ini karena tidak memerlukan mesin khusus; itu berjalan pada sekelompok perangkat keras komoditas. Juga, lebih mudah untuk menambahkan lebih banyak node dalam jangka panjang.
Artinya, satu kasus dengan mudah meningkatkan node tanpa mengalami downtime dari persyaratan pra-perencanaan.
5. Throughput Tinggi
Dalam kasus kerangka Hadoop, data disimpan secara terdistribusi sedemikian rupa sehingga pekerjaan kecil dibagi menjadi beberapa bagian data secara paralel. Hal ini memudahkan bisnis untuk menyelesaikan lebih banyak pekerjaan dalam waktu yang lebih singkat, yang pada akhirnya menghasilkan throughput yang lebih tinggi.
6. Tangguh terhadap Kegagalan
Last but not least, Hadoop menawarkan opsi toleransi kesalahan tinggi yang membantu mengurangi konsekuensi kegagalan. Ini menyimpan replika dari setiap blok yang memungkinkan untuk memulihkan data setiap kali ada node yang down.
Kekurangan Kerangka Hadoop
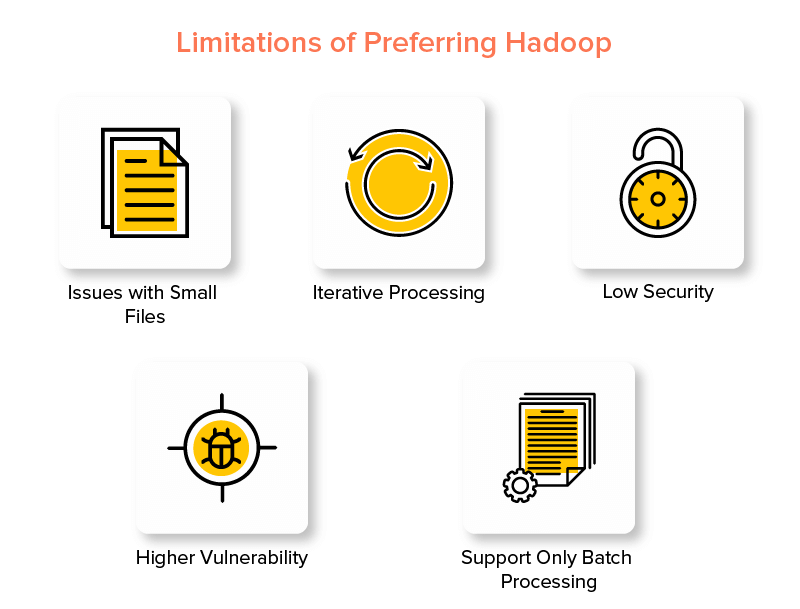
1. Masalah dengan File Kecil
Kelemahan terbesar dari mempertimbangkan Hadoop untuk analitik data besar adalah ia tidak memiliki potensi untuk mendukung pembacaan acak file kecil secara efisien dan efektif.
Alasan di balik ini adalah bahwa file kecil memiliki ukuran memori yang relatif lebih rendah daripada ukuran blok HDFS. Dalam skenario seperti itu, jika seseorang menyimpan sejumlah besar file kecil, ada kemungkinan lebih tinggi dari NameNode yang menyimpan namespace HDFS, yang secara praktis bukan ide yang baik.
2. Pemrosesan Iteratif
Aliran data dalam kerangka Hadoop big data berbentuk rantai, sehingga keluaran yang satu menjadi masukan bagi tahapan lainnya. Padahal, aliran data dalam pemrosesan iteratif bersifat siklik.
Karena itu, Hadoop adalah pilihan yang tidak tepat untuk solusi berbasis Machine Learning atau Iterative processing.
3. Keamanan Rendah
Kerugian lain menggunakan kerangka Hadoop adalah menawarkan fitur keamanan yang lebih rendah.
Kerangka kerja, misalnya, memiliki model keamanan yang dinonaktifkan secara default. Jika seseorang yang menggunakan alat data besar ini tidak tahu cara mengaktifkannya, data mereka dapat berisiko lebih tinggi dicuri/disalahgunakan. Selain itu, Hadoop tidak menyediakan fungsionalitas enkripsi di tingkat penyimpanan dan jaringan, yang sekali lagi meningkatkan kemungkinan ancaman pelanggaran data.
4. Kerentanan Lebih Tinggi
Kerangka kerja Hadoop ditulis dalam Java, bahasa pemrograman yang paling populer namun banyak dieksploitasi. Ini memudahkan penjahat dunia maya untuk dengan mudah mendapatkan akses ke solusi berbasis Hadoop dan menyalahgunakan data sensitif.
5. Dukungan untuk Pemrosesan Batch Saja
Tidak seperti berbagai kerangka data besar lainnya, Hadoop tidak memproses data yang dialirkan. Ini hanya mendukung pemrosesan batch , dan alasan di baliknya adalah bahwa MapReduce gagal memanfaatkan memori Hadoop Cluster secara maksimal.
Meskipun ini semua tentang Hadoop, fitur dan kekurangannya, mari kita lihat pro dan kontra dari Spark untuk menemukan kemudahan dalam memahami perbedaan antara keduanya.
Manfaat Kerangka Apache Spark
1. Dinamis di Alam
Karena Apache Spark menawarkan sekitar 80 operator tingkat tinggi, ini dapat digunakan untuk memproses data secara dinamis. Ini dapat dianggap sebagai alat big data yang tepat untuk mengembangkan dan mengelola aplikasi paralel.
2. Kuat
Karena kemampuan pemrosesan data dalam memori dengan latensi rendah dan ketersediaan berbagai pustaka bawaan untuk pembelajaran mesin dan algoritme analitik grafik, ini dapat menangani berbagai tantangan analitik. Ini menjadikannya pilihan data besar yang kuat di pasar untuk digunakan.
3. Analisis Lanjutan
Fitur khas lain dari Spark adalah tidak hanya mendorong 'MAP' dan 'mengurangi', tetapi juga mendukung Pembelajaran Mesin (ML), kueri SQL, algoritma Grafik , dan data Streaming. Ini membuatnya cocok untuk menikmati analitik tingkat lanjut.
4. Dapat digunakan kembali
Tidak seperti Hadoop, kode Spark dapat digunakan kembali untuk pemrosesan batch, menjalankan kueri ad-hoc pada status aliran, menggabungkan aliran terhadap data historis, dan banyak lagi.
5. Pemrosesan Aliran Waktu Nyata
Keuntungan lain menggunakan Apache Spark adalah memungkinkan penanganan dan pemrosesan data secara real-time.
6. Dukungan Multibahasa
Last but not least, alat analitik data besar ini mendukung banyak bahasa untuk pengkodean, termasuk Java, Python, dan Scala.
Keterbatasan Alat Data Besar Spark

1. Tidak Ada Proses Manajemen File
Kerugian utama menggunakan Apache Spark adalah ia tidak memiliki sistem manajemen file sendiri. Itu bergantung pada platform lain seperti Hadoop untuk memenuhi persyaratan ini.
2. Beberapa Algoritma
Apache Spark juga tertinggal di belakang kerangka data besar lainnya ketika mempertimbangkan ketersediaan algoritma seperti jarak Tanimoto.
3. Masalah File Kecil
Kerugian lain menggunakan Spark adalah tidak menangani file kecil secara efisien.
Ini karena ia beroperasi dengan Hadoop Distributed File System (HDFS) yang membuatnya lebih mudah untuk mengelola sejumlah kecil file besar daripada banyak file kecil.
4. Tidak Ada Proses Optimasi otomatis
Tidak seperti berbagai data besar dan platform berbasis cloud lainnya, Spark tidak memiliki proses pengoptimalan kode otomatis. Kita harus mengoptimalkan kode secara manual saja.
5. Tidak Cocok untuk Lingkungan Multi-Pengguna
Karena Apache Spark tidak dapat menangani banyak pengguna secara bersamaan, Apache Spark tidak beroperasi secara efisien di lingkungan multi-pengguna. Sesuatu yang sekali lagi menambah keterbatasannya.
Dengan dasar-dasar kedua kerangka data besar yang dibahas, kemungkinan Anda berharap untuk mengenal perbedaan antara Spark dan Hadoop.
Jadi, jangan tunggu lagi dan menuju perbandingan mereka untuk melihat mana yang memimpin pertempuran 'Spark vs Hadoop'.
Spark vs Hadoop: Bagaimana Dua Alat Data Besar Bertumpuk Satu Sama Lain
[id tabel=38 /]
1. Arsitektur
Ketika datang ke arsitektur Spark dan Hadoop, yang terakhir memimpin bahkan ketika keduanya beroperasi di lingkungan komputasi terdistribusi.
Ini karena, arsitektur Hadoop – tidak seperti Spark- memiliki dua elemen utama – HDFS (Hadoop Distributed File System) dan YARN (Yet Another Resource Negotiator). Di sini, HDFS menangani penyimpanan data besar di berbagai node, sedangkan YARN menangani tugas pemrosesan melalui alokasi sumber daya dan mekanisme penjadwalan pekerjaan. Komponen-komponen ini kemudian dibagi lagi menjadi lebih banyak komponen untuk memberikan solusi yang lebih baik dengan layanan seperti toleransi Kesalahan.
2. Kemudahan Penggunaan
Apache Spark memungkinkan pengembang untuk memperkenalkan berbagai API yang mudah digunakan seperti untuk Scala, Python, R, Java, dan Spark SQL di lingkungan pengembangan mereka. Selain itu, ia hadir dengan mode interaktif yang mendukung pengguna dan pengembang. Ini membuatnya mudah digunakan dan dengan kurva belajar yang rendah.
Padahal, ketika berbicara tentang Hadoop, ia menawarkan add-on untuk mendukung pengguna, tetapi bukan mode interaktif. Ini membuat Spark menang atas Hadoop dalam pertarungan 'big data' ini.
3. Toleransi dan Keamanan Kesalahan
Sementara Apache Spark dan Hadoop MapReduce menawarkan fasilitas toleransi kesalahan, yang terakhir memenangkan pertempuran.
Ini karena seseorang harus memulai dari awal jika ada proses yang mogok di tengah operasi di lingkungan Spark. Tapi, ketika datang ke Hadoop, mereka bisa melanjutkan dari titik crash itu sendiri.
4. Kinerja
Ketika mempertimbangkan kinerja Spark vs MapReduce, yang pertama menang atas yang terakhir.
Kerangka kerja Spark mampu berjalan 10 kali lebih cepat di disk dan 100 kali di memori. Hal ini memungkinkan untuk mengelola 100 TB data 3 kali lebih cepat daripada Hadoop MapReduce.
5. Pemrosesan Data
Faktor lain yang perlu dipertimbangkan selama perbandingan Apache Spark vs Hadoop adalah pemrosesan data.
Sementara Apache Hadoop menawarkan kesempatan untuk pemrosesan batch saja, kerangka data besar lainnya memungkinkan bekerja dengan pemrosesan interaktif, iteratif, streaming, grafik, dan batch. Sesuatu yang membuktikan bahwa Spark adalah pilihan yang lebih baik untuk menikmati layanan pemrosesan data yang lebih baik.
6. Kompatibilitas
Kompatibilitas Spark dan Hadoop MapReduce agak sama.
Meskipun terkadang, kedua kerangka kerja data besar bertindak sebagai aplikasi yang berdiri sendiri, mereka juga dapat bekerja bersama. Spark dapat berjalan secara efisien di atas Hadoop YARN, sementara Hadoop dapat dengan mudah berintegrasi dengan Sqoop dan Flume. Karena itu, keduanya saling mendukung sumber data dan format file.
7. Keamanan
Lingkungan Spark dimuat dengan berbagai fitur keamanan seperti pencatatan peristiwa dan penggunaan filter servlet javax untuk melindungi UI web. Selain itu, ini mendorong otentikasi melalui rahasia bersama dan dapat memanfaatkan potensi izin file HDFS, enkripsi antar-mode, dan Kerberos saat terintegrasi dengan YARN dan HDFS.
Padahal, Hadoop mendukung otentikasi Kerberos , otentikasi pihak ketiga, izin file konvensional, dan daftar kontrol akses, dan banyak lagi, yang pada akhirnya menawarkan hasil keamanan yang lebih baik.
Jadi, ketika mempertimbangkan perbandingan Spark vs Hadoop dalam hal Keamanan, yang terakhir memimpin.
8. Efektivitas Biaya
Saat membandingkan Hadoop dan Spark, yang pertama membutuhkan lebih banyak memori pada disk sementara yang kedua membutuhkan lebih banyak RAM. Juga, karena Spark cukup baru dibandingkan dengan Apache Hadoop, pengembang yang bekerja dengan Spark lebih jarang.
Ini membuat bekerja dengan Spark menjadi urusan yang mahal. Artinya, Hadoop menawarkan solusi hemat biaya ketika seseorang berfokus pada biaya Hadoop vs Spark.
9. Lingkup Pasar
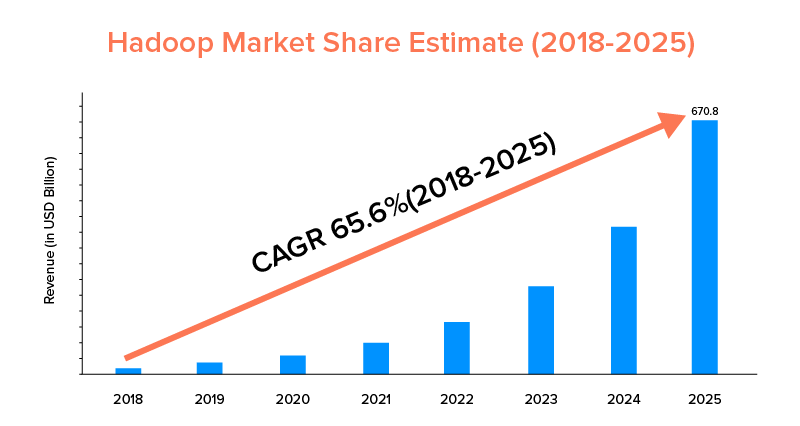
Sementara Apache Spark dan Hadoop didukung oleh perusahaan besar dan telah digunakan untuk tujuan yang berbeda, yang terakhir memimpin dalam hal cakupan pasar.
Sesuai dengan statistik pasar, pasar Apache Hadoop diprediksi akan tumbuh dengan CAGR sebesar 65,6% selama periode 2018 hingga 2025, jika dibandingkan dengan Spark dengan CAGR sebesar 33,9% saja.
Meskipun faktor-faktor ini akan membantu dalam menentukan alat big data yang tepat untuk bisnis Anda, akan sangat menguntungkan untuk mengenal kasus penggunaannya. Jadi, mari kita bahas di sini.
Gunakan Kasus Apache Spark Framework
Alat data besar ini digunakan oleh bisnis ketika mereka ingin:
- Streaming dan analisis data secara real-time.
- Nikmati kekuatan Machine Learning.
- Bekerja dengan analitik interaktif.
- Memperkenalkan Fog dan Edge Computing ke model bisnis mereka.
Gunakan Kasus Kerangka Apache Hadoop
Hadoop lebih disukai oleh perusahaan rintisan dan Perusahaan ketika mereka ingin: -
- Menganalisis data arsip.
- Nikmati opsi perdagangan dan perkiraan keuangan yang lebih baik.
- Jalankan operasi yang terdiri dari perangkat keras Komoditas.
- Pertimbangkan pemrosesan data linier.
Dengan ini, kami harap Anda telah memutuskan yang mana yang menjadi pemenang pertempuran 'Spark vs Hadoop' sehubungan dengan bisnis Anda. Jika tidak, jangan ragu untuk terhubung dengan Pakar Big Data kami untuk menghapus semua keraguan dan mendapatkan layanan teladan dengan rasio keberhasilan yang lebih tinggi.
PERTANYAAN YANG SERING DIAJUKAN
1. Kerangka Data Besar Mana yang Harus Dipilih?
Pilihannya tergantung sepenuhnya pada kebutuhan bisnis Anda. Jika Anda berfokus pada kinerja, kompatibilitas data, dan kemudahan penggunaan, Spark lebih baik daripada Hadoop. Padahal, kerangka data besar Hadoop lebih baik ketika Anda fokus pada arsitektur, keamanan, dan efektivitas biaya.
2. Apa Perbedaan antara Hadoop dan Spark?
Ada berbagai perbedaan antara Spark dan Hadoop. Sebagai contoh:-
- Spark adalah faktor 100 kali lipat dari Hadoop MapReduce.
- Sementara Hadoop digunakan untuk pemrosesan batch, Spark dimaksudkan untuk batch, grafik, pembelajaran mesin, dan pemrosesan berulang.
- Spark lebih ringkas dan lebih mudah daripada kerangka data besar Hadoop.
- Tidak seperti Spark, Hadoop tidak mendukung caching data.
3. Apakah Spark Lebih Baik dari Hadoop?
Spark lebih baik daripada Hadoop saat fokus utama Anda adalah pada kecepatan dan keamanan. Namun, dalam kasus lain, alat analitik data besar ini tertinggal dari Apache Hadoop.
4. Mengapa Spark Lebih Cepat dari Hadoop?
Spark lebih cepat daripada Hadoop karena jumlah siklus baca/tulis ke disk yang lebih rendah dan penyimpanan data perantara dalam memori.
5. Untuk Apa Apache Spark Digunakan?
Apache Spark digunakan untuk analisis data ketika seseorang ingin-
- Menganalisis data secara real-time.
- Perkenalkan ML, dan Fog Computing ke dalam model bisnis Anda.
- Bekerja dengan Analisis Interaktif.