
TW-BERT: Pembobotan istilah kueri menyeluruh dan masa depan Google Penelusuran
Diterbitkan: 2023-09-14Pencarian itu sulit, seperti yang ditulis Seth Godin pada tahun 2005.
Maksud saya, jika menurut kita SEO itu sulit (dan memang sulit), bayangkan jika Anda mencoba membangun mesin pencari di dunia di mana:
- Penggunanya sangat bervariasi dan mengubah preferensi mereka seiring waktu.
- Teknologi yang mereka akses kemajuan pencarian setiap hari.
- Pesaing terus-menerus mengejar Anda.
Selain itu, Anda juga berurusan dengan SEO yang mengganggu yang mencoba mempermainkan algoritma Anda untuk mendapatkan wawasan tentang cara terbaik untuk mengoptimalkan pengunjung Anda.
Itu akan membuat segalanya lebih sulit.
Sekarang bayangkan jika teknologi utama yang perlu Anda andalkan untuk maju memiliki keterbatasannya sendiri – dan, mungkin lebih buruk lagi, biayanya sangat besar.
Nah, jika Anda salah satu penulis makalah yang baru-baru ini diterbitkan, “Pembobotan Istilah Kueri End-to-End”, Anda melihat ini sebagai peluang untuk bersinar.
Apa yang dimaksud dengan pembobotan istilah kueri end-to-end?
Pembobotan istilah kueri end-to-end mengacu pada metode di mana bobot setiap istilah dalam kueri ditentukan sebagai bagian dari keseluruhan model, tanpa bergantung pada skema pembobotan istilah yang diprogram secara manual atau tradisional atau model independen lainnya.
Seperti apa bentuknya?
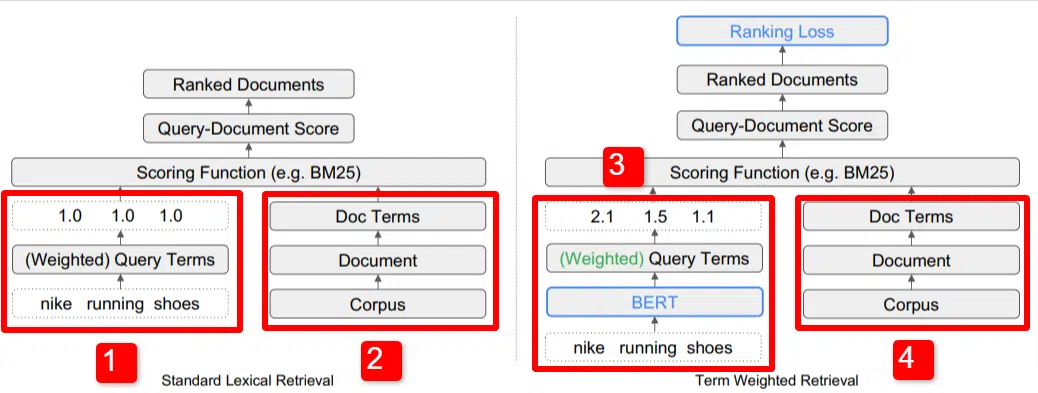
Di sini kita melihat ilustrasi salah satu pembeda utama model yang diuraikan dalam makalah (khususnya Gambar 1).
Di sisi kanan model standar (2) kita melihat hal yang sama seperti yang kita lakukan dengan model yang diusulkan (4), yaitu korpus (kumpulan dokumen lengkap dalam indeks), yang mengarah ke dokumen, yang mengarah ke istilah.
Ini menggambarkan hierarki sebenarnya ke dalam sistem, namun Anda dapat dengan santai memikirkannya secara terbalik, dari atas ke bawah. Kami punya persyaratan. Kami mencari dokumen dengan persyaratan tersebut. Dokumen-dokumen tersebut merupakan kumpulan dari semua dokumen yang kami ketahui.
Di kiri bawah (1) dalam arsitektur Information Retrieval (IR) standar, Anda akan melihat bahwa tidak ada lapisan BERT. Kueri yang digunakan dalam ilustrasi mereka (sepatu lari nike) memasuki sistem, dan bobot dihitung secara independen dari model dan diteruskan ke sistem.
Dalam ilustrasi di sini, bobot diberikan secara merata di antara tiga kata dalam kueri. Namun, tidak harus seperti itu. Ini hanyalah ilustrasi default dan bagus.
Yang penting untuk dipahami adalah bahwa bobot ditetapkan dari luar model dan dimasukkan dengan kueri. Kami akan membahas mengapa hal ini penting sebentar lagi.
Jika kita melihat versi istilah-berat di sisi kanan, Anda akan melihat bahwa kueri “sepatu lari nike” memasukkan BERT (Term Weighting BERT, atau TW-BERT, lebih spesifiknya) yang digunakan untuk menetapkan bobot yang akan lebih baik diterapkan pada kueri itu.
Dari sana, hal-hal mengikuti jalur yang sama untuk keduanya, fungsi penilaian diterapkan dan dokumen diberi peringkat. Namun ada langkah terakhir yang penting dalam model baru ini, yang merupakan inti dari semuanya, yaitu penghitungan kerugian peringkat.
Perhitungan ini, yang saya maksudkan di atas, membuat penentuan bobot dalam model menjadi sangat penting. Untuk memahami hal ini dengan baik, mari kita sejenak membahas fungsi kerugian, yang penting untuk benar-benar memahami apa yang terjadi di sini.
Apa itu fungsi kerugian?
Dalam pembelajaran mesin, fungsi kerugian pada dasarnya adalah penghitungan seberapa salah suatu sistem dengan sistem tersebut mencoba belajar untuk sedekat mungkin dengan kerugian nol.
Mari kita ambil contoh model yang dirancang untuk menentukan harga rumah. Jika Anda memasukkan semua statistik rumah Anda dan hasilnya bernilai $250.000, tetapi rumah Anda terjual seharga $260.000, selisihnya akan dianggap kerugian (yang merupakan nilai absolut).
Dari banyak contoh, model diajarkan untuk meminimalkan kerugian dengan memberikan bobot berbeda pada parameter yang diberikan hingga mendapatkan hasil terbaik. Parameter, dalam hal ini, dapat mencakup hal-hal seperti kaki persegi, kamar tidur, ukuran halaman, kedekatan dengan sekolah, dll.
Sekarang, kembali ke pembobotan istilah kueri
Melihat kembali dua contoh di atas, yang perlu kita fokuskan adalah hadirnya model BERT untuk memberikan bobot pada istilah down-funnel penghitungan kerugian peringkat.
Dengan kata lain, dalam model tradisional, bobot istilah dilakukan secara independen dari model itu sendiri sehingga tidak dapat merespons kinerja model secara keseluruhan. Ia tidak bisa belajar bagaimana meningkatkan bobotnya.

Dalam sistem yang diusulkan, hal ini berubah. Pembobotan dilakukan dari dalam model itu sendiri dan oleh karena itu, saat model berupaya meningkatkan kinerjanya dan mengurangi fungsi kerugian, model tersebut memiliki tombol tambahan untuk memasukkan pembobotan istilah ke dalam persamaan. Secara harfiah.
ngram
TW-BERT tidak dirancang untuk beroperasi dalam bentuk kata-kata, melainkan ngram.
Penulis makalah ini mengilustrasikan dengan baik mengapa mereka menggunakan ngram alih-alih kata-kata ketika mereka menunjukkan bahwa dalam kueri “sepatu lari nike” jika Anda cukup memberi bobot pada kata-katanya, maka halaman yang menyebutkan kata nike, lari, dan sepatu bisa mendapat peringkat yang baik bahkan jika membahas “kaos kaki lari nike” dan “sepatu skate”.
Metode IR tradisional menggunakan statistik kueri dan statistik dokumen, dan mungkin memunculkan halaman dengan masalah ini atau masalah serupa. Upaya-upaya di masa lalu untuk mengatasi hal ini berfokus pada kejadian bersama dan keteraturan.
Dalam model ini, ngram diberi bobot seperti kata pada contoh sebelumnya, sehingga kita mendapatkan hasil seperti:
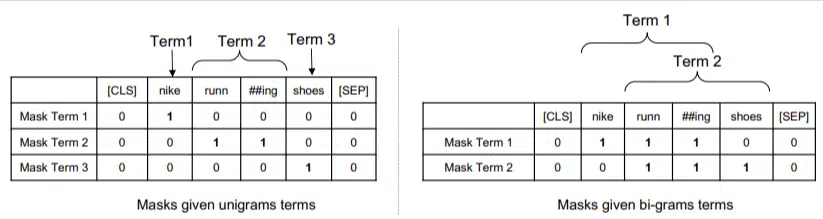
Di sebelah kiri kita melihat bagaimana kueri akan diberi bobot sebagai uni-gram (ngram 1 kata) dan di sebelah kanan, bi-gram (ngram 2 kata).
Sistem, karena pembobotan sudah terpasang di dalamnya, dapat melatih semua permutasi untuk menentukan ngram terbaik dan juga bobot yang sesuai untuk masing-masing permutasi, dibandingkan hanya mengandalkan statistik seperti frekuensi.
Tembakan nol
Fitur penting dari model ini adalah kinerjanya dalam tugas-tugas yang sangat singkat. Para penulis menguji pada:
- Kumpulan data MS MARCO – Kumpulan data Microsoft untuk pemeringkatan dokumen dan bagian
- Kumpulan data TREC-COVID – artikel dan studi COVID
- Robust04 – Artikel berita
- Common Core – Artikel pendidikan dan postingan blog
Mereka hanya memiliki sejumlah kecil kueri evaluasi dan tidak menggunakan satu pun untuk melakukan penyesuaian. Hal ini menjadikan pengujian ini sebagai pengujian zero-shot karena model tidak dilatih untuk menentukan peringkat dokumen pada domain tersebut secara spesifik. Hasilnya adalah:
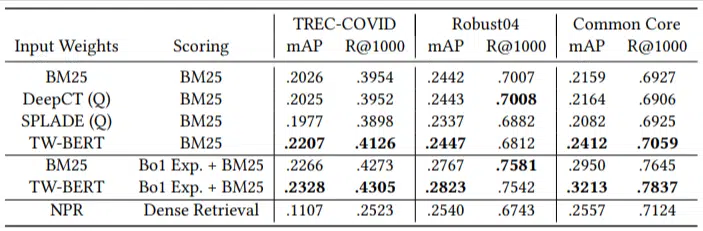
Ini mengungguli sebagian besar tugas dan berkinerja paling baik pada kueri yang lebih pendek (1 hingga 10 kata).
Dan itu plug-and-play!
Oke, itu mungkin terlalu menyederhanakan, tetapi penulis menulis:
“Menyelaraskan TW-BERT dengan pencetak skor mesin pencari meminimalkan perubahan yang diperlukan untuk mengintegrasikannya ke dalam aplikasi produksi yang ada , sedangkan metode pencarian berbasis pembelajaran mendalam yang ada akan memerlukan optimalisasi infrastruktur dan persyaratan perangkat keras lebih lanjut. Bobot yang dipelajari dapat dengan mudah digunakan oleh pengambilan leksikal standar dan teknik pengambilan lainnya seperti perluasan kueri.”
Karena TW-BERT dirancang untuk diintegrasikan ke dalam sistem yang ada saat ini, integrasinya jauh lebih sederhana dan lebih murah dibandingkan opsi lainnya.
Apa arti semua ini bagi Anda
Dengan model pembelajaran mesin, sulit untuk memprediksi contoh apa yang dapat Anda lakukan sebagai seorang SEO (selain penerapan yang terlihat seperti Bard atau ChatGPT).
Permutasi model ini pasti akan diterapkan karena perbaikan dan kemudahan penerapannya (dengan asumsi pernyataan tersebut akurat).
Meskipun demikian, ini adalah peningkatan kualitas hidup di Google, yang akan meningkatkan peringkat dan hasil yang tepat sasaran dengan biaya rendah.
Yang dapat kami andalkan hanyalah jika diterapkan, hasil yang lebih baik akan terlihat lebih andal. Dan itu kabar baik bagi para profesional SEO.
Pendapat yang diungkapkan dalam artikel ini adalah milik penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.