
Menggunakan Regresi Excel Untuk Lebih Memahami KPI
Diterbitkan: 2021-10-23Sekelompok dari kami di sini di Hanapin baru-baru ini berpartisipasi dalam Kursus Excel 21-Hari gratis yang diarahkan oleh pakar Microsoft Excel terkenal Dr. Wayne Winston. Kursus itu sendiri terasa lambat pada awalnya, tetapi pada akhirnya mengungkapkan beberapa kemampuan Excel yang tidak pernah saya ketahui. Yang paling menarik dari ini, bagi saya, adalah kemampuan untuk meregresi banyak variabel tanpa perangkat lunak statistik canggih (seperti STATA). Dalam posting ini, saya akan membagikan langkah demi langkah untuk menyiapkan dan menjalankan regresi di Excel, dan bagaimana alat ini dapat membantu dalam analisis PPC dan manajemen akun Anda.
Permisi, saya mundur
Sebelum kita mendalami implementasi teknisnya, Anda mungkin bertanya-tanya pada diri sendiri, “Apa sih regresi itu?” Singkatnya, regresi melihat hubungan antar variabel. Untuk setiap variabel dependen (“Y”), kumpulan variabel independen (“Xs”) apa yang berkontribusi terhadap variasi Y, dan seberapa banyak perilaku tersebut dijelaskan oleh model regresi? (Lihat di sini untuk tinjauan mendalam tentang analisis regresi)
Regresi linier (atau regresi linier berganda) adalah yang paling umum, cocok dengan persamaan yang dijumlahkan dalam bentuk:
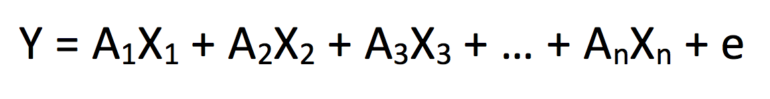
di mana Y adalah variabel terikat, X 1 – X n mewakili himpunan n variabel bebas dan A 1 – A n adalah konstanta koefisien yang bersesuaian dengan X 1 – X n . Ini adalah pembuatan model statistik dasar, jadi kami menyadari bahwa akan ada beberapa ketidakkonsistenan antara hasil yang kami prediksi dan yang diamati untuk setiap iterasi "y". Dengan demikian, istilah kesalahan "+ e" ditambahkan untuk memperhitungkan varians tersebut.
Mengapa Regres Di PPC?
Regresi dapat digunakan dalam sejumlah analisis. Misalnya, Anda mungkin ingin mempertimbangkan apa pengaruh perubahan tawaran BPK terhadap Rta. Posisi, Pangsa Tayangan Hilang, atau Angka Mutu. Anda dapat memeriksa elemen mana (RKT yang diharapkan, pengalaman laman landas, atau relevansi iklan) yang memiliki dampak paling kuat pada Angka Mutu tingkat akun, kampanye, atau kata kunci Anda. Mungkin, seperti yang akan kita lihat pada contoh di bawah, Anda ingin mengungkap peran yang dimainkan oleh BPK Penelusuran dan Display serta Rasio Konversi dalam BPA keseluruhan untuk akun Anda.
Apa pun tujuan akhir Anda, proses untuk menyiapkan dan menentukan nilai model regresi Anda adalah sama.
Langkah 1: Siapkan Data Anda
Seperti halnya analisis apa pun, hasil yang baik membutuhkan data berkualitas yang telah disiapkan dengan benar. Untuk hasil regresi yang baik, Anda memerlukan jumlah data yang cukup (setidaknya titik data sebanyak jumlah variabel independen, tetapi semakin banyak data yang Anda miliki, semakin akurat model regresi Anda). Untuk menambah jumlah titik data, Anda dapat mempertimbangkan untuk mengelompokkan data menurut hari, minggu, atau bulan (bergantung pada kerangka waktu yang diperiksa).
Sebagai contoh, kami menggunakan data dari 24 bulan terakhir di AdWords. Setelah mengunduh laporan kampanye (dibagi menurut bulan), kami membuat tabel pivot untuk memeriksa Klik, Biaya, dan Konversi menurut bulan dan jenis Kampanye:
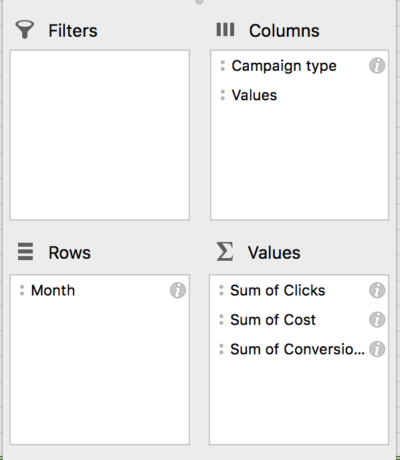
Dari sini, kita dapat menghitung CPA, CPC, dan CVR untuk setiap jaringan, serta Total CPA. Kemudian hanya dengan satu salin dan tempel cepat data ke lembar baru, kami siap untuk mulai mundur!
Langkah 2: Bangun Model Anda (Memilih Variabel)
Pembuatan model memiliki dua komponen utama: perencanaan yang matang dan revisi yang fleksibel. Perencanaan yang matang adalah tentang mempertimbangkan variabel mana yang paling cocok untuk model Anda secara logis (dan data apa yang tersedia untuk digunakan). Menghabiskan sedikit waktu ekstra dalam tahap perencanaan dapat menghemat waktu dan kewarasan Anda nanti saat Anda menguji dan menguji ulang model Anda. Bahkan dengan persiapan yang matang, Anda mungkin masih perlu secara fleksibel merevisi model Anda saat Anda mundur dan mengidentifikasi variabel yang signifikan dan tidak.
Dua catatan penting ketika memilih variabel independen:
- Variabel independen harus memiliki hubungan logis yang masuk akal dengan variabel dependen (yaitu curah hujan rata-rata di Tokyo dan # serangan jantung di Wisconsin akan menjadi rendah dalam daftar korelasi saya untuk diperiksa)
- Variabel independen tidak boleh berkorelasi tinggi satu sama lain (yaitu termasuk Biaya, Klik, dan BPK karena variabel independen dalam regresi yang sama akan menyebabkan kesalahan multikolinearitas dalam model)
Dalam contoh kami, kami ingin melihat apa yang mendorong BPA akun kami. Kami tahu bahwa ada dua jaringan tempat kami menjalankan iklan di AdWords—Penelusuran dan Display—dan kami tahu bahwa dua variabel utama yang mendorong BPA (Biaya/Konversi) untuk setiap jaringan adalah BPK (Biaya/Klik) dan CVR (Konversi/Klik ).
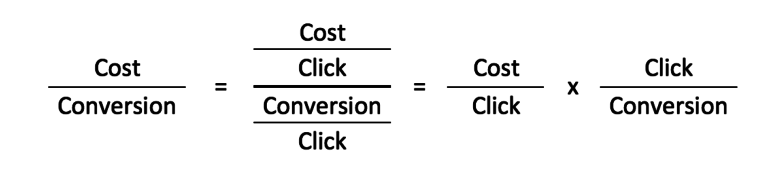
Oleh karena itu, kami akan mulai dengan regresi CPA pada CPC dan CVR untuk Penelusuran dan Display secara terpisah untuk menentukan variabel independen mana yang signifikan, dan dengan demikian harus disertakan dalam model akhir kami.
Langkah 3: Regres Dan Revisi
Untuk menjalankan regresi di Excel:
1. Sebelum memulai regresi di Excel, periksa terlebih dahulu untuk memastikan bahwa variabel independen (kolom data) saling bertetangga.
2. Selanjutnya, konfirmasikan bahwa Add-on “Analysis ToolPak” diaktifkan untuk Excel (terlihat di pita “Data” setelah diaktifkan).
3. Di dalam kotak alat Analisis Data, pilih “Regresi.”
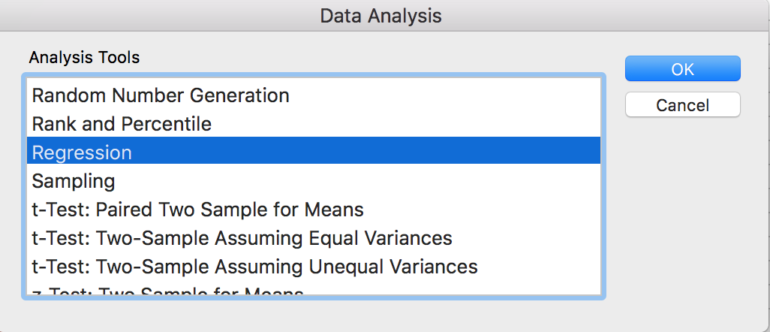
4. Masukkan rentang Variabel Dependen (Y), dan rentang Variabel Independen (X), pilih “Label” jika Anda memilih untuk menyertakan header kolom
5. Pilih penempatan untuk keluaran regresi Anda (lembar kerja baru atau yang sudah ada)
6. Pilih "sisa" jika Anda ingin memeriksa dan menghapus outlier dalam data
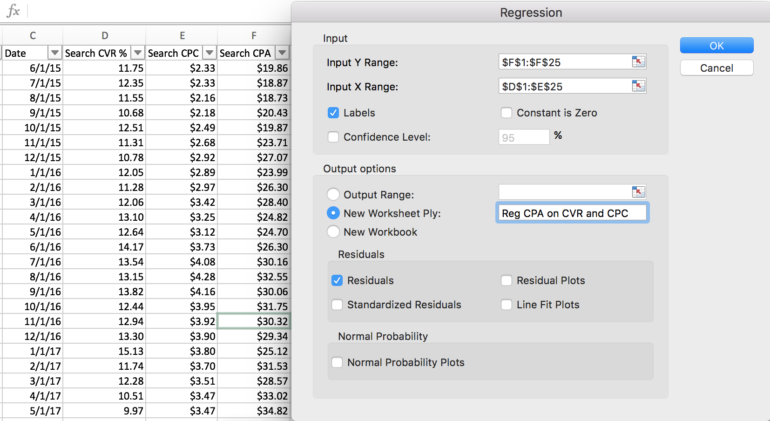
7. Klik “OK” untuk menjalankan regresi. Anda akan secara otomatis dinavigasi ke lembar yang berisi ringkasan dan detail keluaran.
8. Jika pemeriksaan output regresi menunjukkan variabel independen yang tidak signifikan (biasanya, nilai-p lebih besar dari .1) atau R-kuadrat yang lebih rendah dari yang diharapkan (lihat “A” di bawah), Anda dapat mengulangi proses yang diperlukan untuk menyempurnakan model.
Langkah 4: Memahami Outputnya
Melihat Keluaran Ringkasan untuk pertama kalinya dapat mengintimidasi dan mengecilkan hati. Untuk membuatnya lebih mudah, yang disorot di bawah ini adalah bagian utama dari output untuk membantu Anda menilai model regresi yang baru saja Anda buat.

(A) R Square dan Adjusted R Square: Ini adalah ukuran seberapa baik model Anda “cocok” dengan data. Singkatnya, R Square menunjukkan seberapa besar variasi dalam Variabel Dependen dijelaskan oleh Variabel Independen yang dipilih. Adjusted R Square pada dasarnya sama, tetapi juga mempertimbangkan jumlah Variabel Independen yang disertakan, memberikan ukuran yang sedikit lebih akurat. (Tidak ada yang namanya R Square “baik” atau “benar”, karena itu tergantung pada jenis model dan data yang Anda gunakan, tetapi semakin tinggi semakin baik).
(B) Kesalahan Standar: Akar kuadrat dari jumlah selisih kuadrat antara hasil yang diprediksi dan yang sebenarnya. Untuk distribusi normal, kira-kira 65% residu (lihat "E" di bawah) akan kurang dari satu Kesalahan Standar dan 95% akan kurang dari 2. Residu yang lebih besar dari dua kali Kesalahan Standar biasanya diberi label sebagai outlier dalam data.
(C) Koefisien Variabel Independen: Koefisien adalah istilah “A” dalam rumus regresi Anda. Jadi, untuk contoh ini, peningkatan BPK 1 unit harus sama dengan peningkatan BPA sebesar 8,4 (dengan asumsi CVR tetap konstan).
(D) Nilai-P Variabel Independen: Dalam istilah awam, nilai-P menunjukkan signifikansi variabel independen. Nilai-P yang rendah adalah signifikan (bertujuan untuk kurang dari .1), sedangkan nilai-P yang tinggi menunjukkan bahwa korelasi yang dirasakan bisa menjadi peluang murni. Variabel Independen dengan nilai P tinggi harus dikeluarkan selama tahap "revisi fleksibel".
(E) Residuals: Ini menunjukkan perbedaan antara nilai prediksi dari Variabel Dependen untuk setiap iterasi dan nilai yang tercatat sebenarnya. Seperti disebutkan di atas, sebagian besar residual harus kurang dari 1 Standard Error dan hampir semua harus kurang dari nilai 2 * Standard Error. Anda dapat memutuskan apakah akan menyertakan atau mengecualikan outlier yang teridentifikasi (sisa lebih besar dari dua kali Kesalahan Standar) dari model Anda.
Langkah 5: Menyatukannya (Bagian Takeaways!)
Setelah menjalankan tiga regresi, kami menemukan tiga persamaan berikut yang terkait dengan CPC Penelusuran dan Display dan CVR dengan jaringan dan Total CPA:



Persamaan ini memverifikasi apa yang telah kami ketahui (atau kami pikir telah kami lakukan): bahwa BPK Penelusuran dan Display serta CVR semuanya memainkan peran penting dalam perilaku BPA Total kami. Di luar itu, bagaimanapun, mereka juga mengungkapkan 3 hal yang tidak dimiliki oleh peta panas standar.
- Peningkatan CPC Penelusuran memiliki pengaruh 3,5x pada CPA Penelusuran dibandingkan peningkatan yang setara di CVR Penelusuran
- Fluktuasi dalam BPK Tampilan memiliki dampak hampir 5x lipat dari CVR Tampilan pada BPA Tampilan
- Secara keseluruhan, perubahan kinerja jaringan Display memengaruhi BPA Total secara lebih dramatis daripada pergeseran dengan besaran serupa dalam kinerja jaringan Penelusuran
Dari sini, jelas bahwa BPK Tampilan adalah target #1 untuk pengoptimalan jika saya ingin mengurangi BPA Total. Search CPC dan Display CVR adalah yang berikutnya, dengan Search CVR sebagai prioritas saya.
Regresi adalah alat yang ampuh dan tambahan yang bagus untuk sabuk alat Manajer PPC. Contoh dasar ini menunjukkan hanya satu dari banyak cara regresi dapat membantu Anda memahami hubungan antara KPI yang Anda sukai. Kami berharap Anda akan menguji atau terus menggunakan kemampuan regresi di Excel, dan berbagi pengalaman/pemikiran/temuan Anda dengan kami di Twitter!