
Apa itu AI generatif dan bagaimana cara kerjanya?
Diterbitkan: 2023-09-26AI generatif, bagian dari kecerdasan buatan, telah muncul sebagai kekuatan revolusioner di dunia teknologi. Tapi apa sebenarnya itu? Dan mengapa hal ini mendapat begitu banyak perhatian?
Panduan mendalam ini akan membahas cara kerja model AI generatif, apa yang bisa dan tidak bisa dilakukan, dan implikasi dari semua elemen ini.
Apa itu AI generatif?
AI generatif, atau genAI, mengacu pada sistem yang dapat menghasilkan konten baru, baik itu teks, gambar, musik, atau bahkan video. Secara tradisional, AI/ML berarti tiga hal: pembelajaran yang diawasi, tanpa pengawasan, dan pembelajaran penguatan. Masing-masing memberikan wawasan berdasarkan pengelompokan keluaran.
Model AI non-generatif membuat penghitungan berdasarkan masukan (seperti mengklasifikasikan gambar atau menerjemahkan kalimat). Sebaliknya, model generatif menghasilkan keluaran “baru” seperti menulis esai, menggubah musik, mendesain grafis, bahkan menciptakan wajah manusia realistis yang tidak ada di dunia nyata.
Implikasi AI generatif
Munculnya AI generatif mempunyai implikasi yang signifikan. Dengan kemampuan menghasilkan konten, industri seperti hiburan, desain, dan jurnalisme menyaksikan perubahan paradigma.
Misalnya, kantor berita dapat menggunakan AI untuk menyusun laporan, sementara desainer dapat memperoleh saran grafis dengan bantuan AI. AI dapat menghasilkan ratusan slogan iklan dalam hitungan detik – terlepas dari apakah opsi tersebut bagus atau tidak atau tidak, itu soal lain.
AI generatif dapat menghasilkan konten yang disesuaikan untuk pengguna individu. Bayangkan sesuatu seperti aplikasi musik yang membuat lagu unik berdasarkan suasana hati Anda atau aplikasi berita yang menyusun artikel tentang topik yang Anda minati.
Masalahnya adalah ketika AI memainkan peran yang lebih integral dalam pembuatan konten, pertanyaan tentang keaslian, hak cipta, dan nilai kreativitas manusia menjadi lebih umum.
Bagaimana cara kerja AI generatif?
AI Generatif, pada intinya, adalah tentang memprediksi bagian data berikutnya secara berurutan, apakah itu kata berikutnya dalam sebuah kalimat atau piksel berikutnya dalam sebuah gambar. Mari kita uraikan bagaimana hal ini dicapai.
Model statistik
Model statistik adalah tulang punggung sebagian besar sistem AI. Mereka menggunakan persamaan matematika untuk mewakili hubungan antara variabel yang berbeda.
Untuk AI generatif, model dilatih untuk mengenali pola dalam data dan kemudian menggunakan pola tersebut untuk menghasilkannya data baru yang serupa.
Jika suatu model dilatih menggunakan kalimat bahasa Inggris, model tersebut akan mempelajari kemungkinan statistik dari satu kata mengikuti kata lainnya, sehingga memungkinkan model tersebut menghasilkan kalimat yang koheren.
Pengumpulan data
Kualitas dan kuantitas data sangatlah penting. Model generatif dilatih pada kumpulan data yang luas untuk memahami pola.
Untuk model bahasa, ini mungkin berarti menyerap miliaran kata dari buku, situs web, dan teks lainnya.
Untuk model gambar, ini bisa berarti menganalisis jutaan gambar. Semakin beragam dan komprehensif data pelatihan, semakin baik model tersebut menghasilkan keluaran yang beragam.
Cara kerja transformator dan perhatian
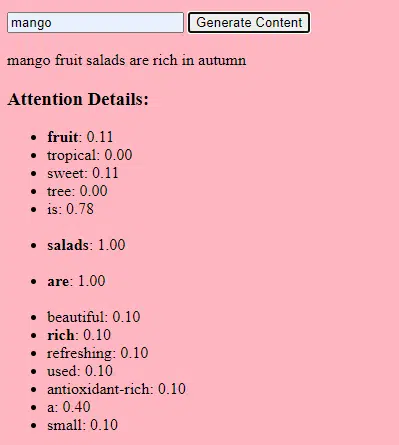
Transformer adalah jenis arsitektur jaringan saraf yang diperkenalkan dalam makalah tahun 2017 berjudul “Attention Is All You Need” oleh Vaswani et al. Sejak saat itu, mereka menjadi landasan bagi sebagian besar model bahasa yang canggih. ChatGPT tidak akan berfungsi tanpa trafo.
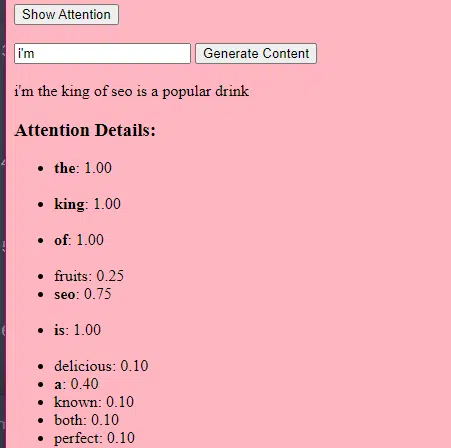
Mekanisme “perhatian” memungkinkan model untuk fokus pada bagian-bagian berbeda dari data masukan, seperti bagaimana manusia memperhatikan kata-kata tertentu saat memahami sebuah kalimat.
Mekanisme ini memungkinkan model memutuskan bagian masukan mana yang relevan untuk tugas tertentu, sehingga menjadikannya sangat fleksibel dan kuat.
Kode di bawah ini adalah rincian mendasar dari mekanisme transformator, menjelaskan setiap bagian dalam bahasa Inggris yang sederhana.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)Dalam kode, Anda mungkin memiliki kelas Transformer dan satu kelas TransformerLayer. Ini seperti memiliki cetak biru untuk satu lantai vs. seluruh bangunan.
Potongan kode TransformerLayer ini menunjukkan kepada Anda cara kerja komponen tertentu, seperti perhatian multi-kepala dan pengaturan tertentu.
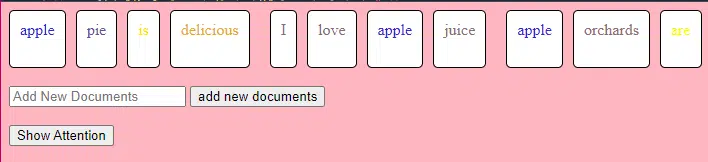
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Jaringan saraf tiruan feed-forward adalah salah satu jenis jaringan saraf tiruan yang paling sederhana. Ini terdiri dari lapisan masukan, satu atau lebih lapisan tersembunyi, dan lapisan keluaran.
Data mengalir dalam satu arah – dari lapisan masukan, melalui lapisan tersembunyi, dan ke lapisan keluaran. Tidak ada loop atau siklus dalam jaringan.
Dalam konteks arsitektur transformator, jaringan saraf feed-forward digunakan setelah mekanisme perhatian di setiap lapisan. Ini adalah transformasi linier dua lapis sederhana dengan aktivasi ReLU di antaranya.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Cara kerja AI generatif – secara sederhana
Bayangkan AI generatif seperti melempar dadu berbobot. Data pelatihan menentukan bobot (atau probabilitas).
Jika dadu mewakili kata berikutnya dalam sebuah kalimat, kata yang sering mengikuti kata saat ini dalam data pelatihan akan memiliki bobot lebih tinggi. Jadi, “langit” mungkin lebih sering mengikuti “biru” daripada “pisang”. Saat AI “melempar dadu” untuk menghasilkan konten, AI cenderung memilih urutan yang lebih mungkin secara statistik berdasarkan pelatihannya.
Jadi, bagaimana LLM bisa menghasilkan konten yang “terlihat” asli?
Mari kita ambil listicle palsu – “hadiah Idul Fitri terbaik untuk pemasar konten” – dan telusuri bagaimana LLM dapat menghasilkan daftar ini dengan menggabungkan isyarat tekstual dari dokumen tentang hadiah, Idul Fitri, dan pemasar konten.
Sebelum diproses, teks dipecah menjadi potongan-potongan kecil yang disebut “token.” Token ini bisa sepanjang satu karakter atau sepanjang satu kata.
Contoh: “Idul Fitri adalah sebuah perayaan” menjadi [“Idul Fitri”, “al-Fitr”, “adalah”, “a”, “perayaan”].
Hal ini memungkinkan model untuk bekerja dengan potongan teks yang dapat dikelola dan memahami struktur kalimat.
Setiap token kemudian diubah menjadi vektor (daftar angka) menggunakan embeddings. Vektor-vektor ini menangkap makna dan konteks setiap kata.
Pengkodean posisi menambahkan informasi ke setiap vektor kata tentang posisinya dalam kalimat, memastikan model tidak kehilangan informasi urutan ini.
Kemudian kami menggunakan mekanisme perhatian : ini memungkinkan model untuk fokus pada bagian berbeda dari teks masukan saat menghasilkan keluaran. Jika Anda ingat BERT, inilah yang menarik bagi Googler tentang BERT.
Jika model kita telah melihat teks tentang “ hadiah ” dan mengetahui bahwa orang-orang memberikan hadiah selama perayaan , dan juga melihat teks tentang “ Idul Fitri ” sebagai perayaan yang penting, model tersebut akan memberikan “ perhatian ” pada hubungan ini.
Demikian pula, jika mereka telah melihat teks tentang “ pemasar konten ” yang membutuhkan alat atau sumber daya tertentu, mereka dapat menghubungkan gagasan “ hadiah ” dengan “ pemasar konten”.

Sekarang kita dapat menggabungkan konteks: Saat model memproses teks masukan melalui beberapa lapisan Transformer, model tersebut menggabungkan konteks yang telah dipelajari.
Jadi, meskipun teks aslinya tidak pernah menyebutkan “Hadiah Idul Fitri untuk pemasar konten”, model tersebut dapat menyatukan konsep “Idul Fitri”, “hadiah”, dan “pemasar konten” untuk menghasilkan konten ini.
Hal ini karena mereka telah mempelajari konteks yang lebih luas di sekitar masing-masing istilah tersebut.
Setelah memproses input melalui mekanisme perhatian dan jaringan feed-forward di setiap lapisan Transformer, model menghasilkan distribusi probabilitas atas kosakatanya untuk kata berikutnya dalam urutan tersebut.
Mungkin ada yang berpikir bahwa setelah kata “terbaik” dan “Idul Fitri”, kata “hadiah” kemungkinan besar akan muncul berikutnya. Demikian pula, ia mungkin mengaitkan “hadiah” dengan calon penerima seperti “pemasar konten”.
Dapatkan buletin harian yang diandalkan oleh pemasar pencarian.
Lihat persyaratan.
Seberapa besar model bahasa dibangun
Perjalanan dari model transformator dasar ke model bahasa besar (LLM) yang canggih seperti GPT-3 atau BERT melibatkan peningkatan dan penyempurnaan berbagai komponen.
Berikut rincian langkah demi langkah:
LLM dilatih tentang sejumlah besar data teks. Sulit untuk menjelaskan seberapa luas data ini.
Kumpulan data C4, titik awal bagi banyak LLM, adalah data teks sebesar 750 GB. Itu berarti 805.306.368.000 byte – banyak informasi. Data ini dapat berupa buku, artikel, website, forum, kolom komentar, dan sumber lainnya.
Semakin bervariasi dan komprehensif datanya, semakin baik pula kemampuan pemahaman dan generalisasi model tersebut.
Meskipun arsitektur transformator dasar tetap menjadi fondasinya, LLM memiliki jumlah parameter yang jauh lebih besar. GPT-3, misalnya, memiliki 175 miliar parameter. Dalam hal ini, parameter mengacu pada bobot dan bias dalam jaringan saraf yang dipelajari selama proses pelatihan.
Dalam pembelajaran mendalam, model dilatih untuk membuat prediksi dengan menyesuaikan parameter tersebut untuk mengurangi perbedaan antara prediksi dan hasil sebenarnya.

Proses penyesuaian parameter ini disebut optimasi, yang menggunakan algoritma seperti penurunan gradien.
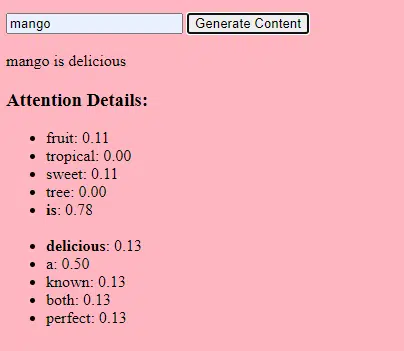
- Bobot: Ini adalah nilai dalam jaringan saraf yang mengubah data masukan dalam lapisan jaringan. Mereka disesuaikan selama pelatihan untuk mengoptimalkan keluaran model. Setiap koneksi antar neuron pada lapisan yang berdekatan memiliki bobot yang terkait.
- Bias: Ini juga merupakan nilai dalam jaringan saraf yang ditambahkan ke keluaran transformasi lapisan. Mereka memberikan tingkat kebebasan tambahan pada model, sehingga memungkinkannya menyesuaikan data pelatihan dengan lebih baik. Setiap neuron dalam suatu lapisan memiliki bias terkait.
Penskalaan ini memungkinkan model untuk menyimpan dan memproses pola dan hubungan yang lebih rumit dalam data.
Banyaknya jumlah parameter juga berarti bahwa model tersebut memerlukan daya komputasi dan memori yang signifikan untuk pelatihan dan inferensi. Inilah sebabnya mengapa pelatihan model seperti itu membutuhkan banyak sumber daya dan biasanya menggunakan perangkat keras khusus seperti GPU atau TPU.
Model ini dilatih untuk memprediksi kata berikutnya dalam suatu urutan menggunakan sumber daya komputasi yang kuat. Ia menyesuaikan parameter internalnya berdasarkan kesalahan yang dibuatnya, dan terus meningkatkan prediksinya.
Mekanisme perhatian seperti yang telah kita diskusikan sangat penting bagi LLM. Mereka memungkinkan model untuk fokus pada bagian masukan yang berbeda saat menghasilkan keluaran.
Dengan mempertimbangkan pentingnya kata-kata yang berbeda dalam suatu konteks, mekanisme perhatian memungkinkan model menghasilkan teks yang koheren dan relevan secara kontekstual. Melakukan hal ini dalam skala besar memungkinkan LLM bekerja sebagaimana mestinya.
Bagaimana cara transformator memprediksi teks?
Transformer memprediksi teks dengan memproses token masukan melalui beberapa lapisan, masing-masing dilengkapi dengan mekanisme perhatian dan jaringan feed-forward.
Setelah diproses, model menghasilkan distribusi probabilitas pada kosakatanya untuk kata berikutnya dalam urutan tersebut. Kata dengan probabilitas tertinggi biasanya dipilih sebagai prediksi.
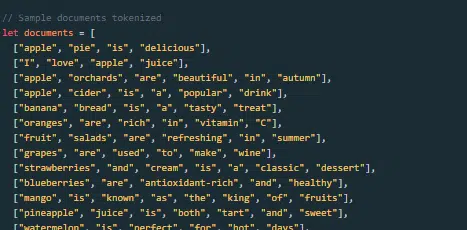
Bagaimana model bahasa besar dibangun dan dilatih?
Membangun LLM melibatkan pengumpulan data, pembersihannya, pelatihan model, penyempurnaan model, dan pengujian yang kuat dan berkelanjutan.
Model ini awalnya dilatih pada korpus yang luas untuk memprediksi kata berikutnya secara berurutan. Fase ini memungkinkan model mempelajari hubungan antar kata yang mengambil pola dalam tata bahasa, hubungan yang dapat mewakili fakta tentang dunia, dan hubungan yang terasa seperti penalaran logis. Koneksi ini juga menyebabkan bias yang ada dalam data pelatihan.
Setelah pra-pelatihan, model disempurnakan pada kumpulan data yang lebih sempit, seringkali dengan pedoman yang diikuti oleh peninjau manusia.
Penyempurnaan adalah langkah penting dalam membangun LLM. Ini melibatkan pelatihan model terlatih pada kumpulan data atau tugas yang lebih spesifik. Mari kita ambil ChatGPT sebagai contoh.
Jika Anda pernah bermain-main dengan model GPT, Anda tahu bahwa perintahnya bukan “tulis hal ini” dan lebih seperti itu
- Petunjuk: Pada suatu ketika
- Lanjutan: Ada seorang penyihir jahat di puncak menara.
- Lanjutan: Ada seorang penyihir jahat di puncak menara.
- Prompt : Mengapa ayam bergabung dengan band?
- Lanjutan : Karena ada stik drumnya!
Untuk mencapai ChatGPT sejak saat itu memerlukan banyak tenaga kerja berupah rendah. Orang-orang tersebut menciptakan kumpulan besar untuk menentukan respons GPT dan perilaku yang diharapkan. Para pekerja ini membuat banyak teks prompt/lanjutan seperti:
- Prompt : Selesaikan cerita ini: “Pada suatu ketika..”
- Lanjutan : Tentu! Dahulu kala, di sebuah negeri yang sangat jauh, ada sebuah desa kecil yang terletak di antara dua gunung yang megah.
- Lanjutan : Tentu! Dahulu kala, di sebuah negeri yang sangat jauh, ada sebuah desa kecil yang terletak di antara dua gunung yang megah.
- Prompt : Ceritakan sebuah lelucon tentang ayam.
- Lanjutan : Kenapa ayam ikut band? Karena ada stik drumnya!
Proses penyesuaian ini penting karena beberapa alasan:
- Kekhususan: Meskipun pra-pelatihan memberi model pemahaman bahasa yang luas, penyesuaian mempersempit pengetahuan dan perilakunya agar lebih selaras dengan tugas atau domain tertentu. Misalnya, model yang disesuaikan dengan data medis akan menjawab pertanyaan medis dengan lebih baik.
- Kontrol: Penyempurnaan memberi pengembang kontrol lebih besar atas keluaran model. Pengembang dapat menggunakan kumpulan data yang dikurasi untuk memandu model guna menghasilkan respons yang diinginkan dan menghindari perilaku yang tidak diinginkan.
- Keamanan: Membantu mengurangi keluaran yang berbahaya atau bias. Dengan menggunakan pedoman selama proses penyesuaian, peninjau manusia dapat memastikan model tidak menghasilkan konten yang tidak pantas.
- Performa: Penyempurnaan dapat meningkatkan performa model secara signifikan pada tugas tertentu. Misalnya, model yang telah disesuaikan untuk dukungan pelanggan akan jauh lebih baik daripada model umum.
Anda dapat mengetahui bahwa ChatGPT telah disempurnakan secara khusus dalam beberapa hal.
Misalnya, "penalaran logis" adalah sesuatu yang cenderung dihadapi oleh LLM. Model penalaran logis terbaik ChatGPT – GPT-4 – telah dilatih secara intens untuk mengenali pola angka secara eksplisit.
Daripada sesuatu seperti ini:
- Prompt : Apa itu 2+2?
- Proses : Seringkali di buku pelajaran matematika untuk anak 2+2 =4. Kadang-kadang ada referensi ke "2+2=5" tetapi biasanya ada lebih banyak konteks yang berkaitan dengan George Orwell atau Star Trek jika demikian. Jika ini dalam konteks tersebut, bobotnya akan lebih mendukung 2+2=5. Namun konteks tersebut tidak ada, jadi dalam hal ini token berikutnya kemungkinan besar adalah 4.
- Tanggapan : 2+2=4
Pelatihannya melakukan sesuatu seperti ini:
- latihan: 2+2=4
- latihan: 4/2=2
- pelatihan: setengah dari 4 adalah 2
- pelatihan: 2 dari 2 adalah empat
…dan seterusnya.
Artinya, untuk model yang lebih "logis", proses pelatihannya lebih ketat dan fokus untuk memastikan bahwa model tersebut memahami dan menerapkan prinsip logis dan matematis dengan benar.
Model tersebut dihadapkan pada berbagai masalah matematika dan solusinya, memastikan model tersebut dapat menggeneralisasi dan menerapkan prinsip-prinsip ini pada masalah baru yang belum terlihat.
Pentingnya proses penyesuaian ini, terutama untuk penalaran logis, tidak bisa dilebih-lebihkan. Tanpanya, model mungkin memberikan jawaban yang salah atau tidak masuk akal terhadap pertanyaan logis atau matematis.
Model gambar vs. model bahasa
Meskipun model gambar dan bahasa mungkin menggunakan arsitektur serupa seperti transformator, data yang diprosesnya pada dasarnya berbeda:
Model gambar
Model ini menangani piksel dan sering kali bekerja secara hierarki, menganalisis pola kecil (seperti tepi) terlebih dahulu, kemudian menggabungkannya untuk mengenali struktur yang lebih besar (seperti bentuk), dan seterusnya hingga model tersebut memahami keseluruhan gambar.
Model bahasa
Model ini memproses rangkaian kata atau karakter. Mereka perlu memahami konteks, tata bahasa, dan semantik untuk menghasilkan teks yang koheren dan relevan secara kontekstual.
Cara kerja antarmuka AI generatif yang menonjol
Dall-E + Tengah Perjalanan
Dall-E adalah varian model GPT-3 yang diadaptasi untuk menghasilkan gambar. Ini dilatih pada kumpulan data besar pasangan teks-gambar. Midjourney adalah perangkat lunak penghasil gambar lainnya yang didasarkan pada model berpemilik.
- Masukan: Anda memberikan deskripsi tekstual, seperti "flamingo berkepala dua".
- Pemrosesan: Model ini mengkodekan teks ini menjadi serangkaian angka dan kemudian mendekode vektor-vektor ini, menemukan hubungan dengan piksel, untuk menghasilkan gambar. Model telah mempelajari hubungan antara deskripsi tekstual dan representasi visual dari data pelatihannya.
- Keluaran: Gambar yang cocok atau berhubungan dengan deskripsi yang diberikan.
Jari, pola, masalah
Mengapa alat-alat ini tidak dapat secara konsisten menghasilkan tangan yang terlihat normal? Alat-alat ini bekerja dengan melihat piksel yang bersebelahan.
Anda dapat melihat cara kerjanya saat membandingkan gambar yang dihasilkan sebelumnya atau yang lebih primitif dengan gambar yang lebih baru: model sebelumnya terlihat sangat kabur. Sebaliknya, model yang lebih baru jauh lebih tajam.
Model ini menghasilkan gambar dengan memprediksi piksel berikutnya berdasarkan piksel yang telah dihasilkannya. Proses ini diulangi jutaan kali untuk menghasilkan gambar yang lengkap.
Tangan, terutama jari, rumit dan memiliki banyak detail yang perlu ditangkap secara akurat.
Posisi, panjang, dan orientasi setiap jari dapat sangat bervariasi pada gambar yang berbeda.
Saat membuat gambar dari deskripsi tekstual, model harus membuat banyak asumsi tentang pose dan struktur tangan yang tepat, yang dapat menyebabkan anomali.
ObrolanGPT
ChatGPT didasarkan pada arsitektur GPT-3.5, model berbasis transformator yang dirancang untuk tugas pemrosesan bahasa alami.
- Input: Perintah atau serangkaian pesan untuk menyimulasikan percakapan.
- Pemrosesan: ChatGPT menggunakan pengetahuannya yang luas dari beragam teks internet untuk menghasilkan tanggapan. Ini mempertimbangkan konteks yang diberikan dalam percakapan dan mencoba menghasilkan jawaban yang paling relevan dan koheren.
- Output: Respons teks yang melanjutkan atau menjawab percakapan.
Khusus
Kekuatan ChatGPT terletak pada kemampuannya menangani berbagai topik dan mensimulasikan percakapan mirip manusia, menjadikannya ideal untuk chatbot dan asisten virtual.
Bard + Pengalaman Generatif Pencarian (SGE)
Meskipun detail spesifiknya mungkin merupakan hak milik, Bard didasarkan pada teknik AI transformator, mirip dengan model bahasa canggih lainnya. SGE didasarkan pada model serupa tetapi menggunakan algoritma ML lain yang digunakan Google.
SGE kemungkinan besar menghasilkan konten menggunakan model generatif berbasis transformator dan kemudian secara fuzzy mengekstraksi jawaban dari halaman peringkat dalam pencarian. (Ini mungkin tidak benar. Hanya tebakan berdasarkan cara kerjanya saat memainkannya. Tolong jangan tuntut saya!)
- Masukan: Prompt/perintah/pencarian
- Pemrosesan: Bard memproses masukan dan bekerja seperti yang dilakukan LLM lainnya. SGE menggunakan arsitektur serupa tetapi menambahkan lapisan tempat ia mencari pengetahuan internalnya (diperoleh dari data pelatihan) untuk menghasilkan respons yang sesuai. Ini mempertimbangkan struktur, konteks, dan maksud perintah untuk menghasilkan konten yang relevan.
- Keluaran: Konten yang dihasilkan dapat berupa cerita, jawaban, atau jenis teks lainnya.
Penerapan AI generatif (dan kontroversinya)
Seni dan Desain
AI generatif kini dapat membuat karya seni, musik, dan bahkan desain produk. Hal ini telah membuka jalan baru bagi kreativitas dan inovasi.
Kontroversi
Munculnya AI dalam bidang seni telah memicu perdebatan tentang hilangnya pekerjaan di bidang kreatif.
Selain itu, ada kekhawatiran tentang:
- Pelanggaran ketenagakerjaan, terutama ketika konten buatan AI digunakan tanpa atribusi atau kompensasi yang sesuai.
- Para eksekutif yang mengancam para penulis untuk menggantinya dengan AI adalah salah satu isu yang memicu pemogokan para penulis.
Pemrosesan bahasa alami (NLP)
Model AI kini banyak digunakan untuk chatbot, terjemahan bahasa, dan tugas NLP lainnya.
Di luar impian kecerdasan umum buatan (AGI), ini adalah penggunaan terbaik untuk LLM karena mereka mirip dengan model NLP “generalis”.
Kontroversi
Banyak pengguna menganggap chatbot tidak bersifat pribadi dan terkadang mengganggu.
Selain itu, meskipun AI telah mencapai kemajuan signifikan dalam penerjemahan bahasa, AI sering kali tidak memiliki nuansa dan pemahaman budaya yang dibawa oleh penerjemah manusia, sehingga menghasilkan terjemahan yang mengesankan dan cacat.
Kedokteran dan penemuan obat
AI dapat dengan cepat menganalisis sejumlah besar data medis dan menghasilkan senyawa obat potensial, sehingga mempercepat proses penemuan obat. Banyak dokter sudah menggunakan LLM untuk menulis catatan dan komunikasi pasien
Kontroversi
Mengandalkan LLM untuk tujuan medis bisa menjadi masalah. Pengobatan membutuhkan ketelitian, dan kesalahan atau kelalaian apa pun yang dilakukan AI dapat menimbulkan konsekuensi serius.
Kedokteran juga sudah memiliki bias yang semakin memperburuk penggunaan LLM. Ada juga masalah serupa, seperti yang dibahas di bawah, terkait privasi, kemanjuran, dan etika.
Permainan
Banyak penggemar AI yang tertarik menggunakan AI dalam game: mereka mengatakan bahwa AI dapat menghasilkan lingkungan game, karakter, dan bahkan keseluruhan plot game yang realistis, sehingga meningkatkan pengalaman bermain game. Dialog NPC dapat ditingkatkan melalui penggunaan alat-alat ini.
Kontroversi
Ada perdebatan tentang kesengajaan dalam desain game.
Meskipun AI dapat menghasilkan konten dalam jumlah besar, beberapa orang berpendapat bahwa AI tidak memiliki desain yang disengaja dan kohesi naratif seperti yang dihasilkan oleh desainer manusia.
Watchdogs 2 memiliki NPC terprogram, yang tidak banyak menambah kohesi narasi game secara keseluruhan.
Pemasaran dan periklanan
AI dapat menganalisis perilaku konsumen dan menghasilkan iklan dan konten promosi yang dipersonalisasi, sehingga membuat kampanye pemasaran menjadi lebih efektif.
LLM memiliki konteks dari tulisan orang lain, menjadikannya berguna untuk menghasilkan cerita pengguna atau ide program yang lebih bernuansa. Daripada merekomendasikan TV kepada seseorang yang baru saja membeli TV, LLM dapat merekomendasikan aksesori yang mungkin diinginkan seseorang.
Kontroversi
Penggunaan AI dalam pemasaran menimbulkan masalah privasi. Ada juga perdebatan tentang implikasi etis penggunaan AI untuk memengaruhi perilaku konsumen.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Pendapat yang diungkapkan dalam artikel ini adalah milik penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.