
Apache Spark: stella scintillante nel firmamento dei big data.
Pubblicato: 2015-09-24- Consigliare milioni di prodotti ai clienti giusti.
- Traccia la cronologia delle ricerche e offre prezzi scontati per i viaggi in aereo.
- Confrontare le capacità tecniche della persona e suggerire in modo appropriato le persone con cui entrare in contatto nel tuo campo.
- Comprendere i modelli in miliardi di oggetti mobili, ripetitori di rete e transazioni di chiamata e calcolare le ottimizzazioni della rete di telecomunicazioni o trovare scappatoie di rete.
- Studio di milioni di caratteristiche dei sensori e analisi dei guasti nelle reti di sensori.
I dati di base necessari per essere utilizzati per ottenere risultati corretti per tutte le attività di cui sopra sono relativamente molto grandi. Non può essere gestita in modo efficiente (in termini sia di spazio che di tempo) dai sistemi tradizionali.
Questi sono tutti scenari di big data.
Per raccogliere, archiviare ed eseguire calcoli su questo tipo di dati voluminosi abbiamo bisogno di un sistema di cluster computing specializzato. Apache Hadoop ha risolto questo problema per noi.
Offre un sistema di archiviazione distribuito (HDFS) e una piattaforma di elaborazione parallela (MapReduce).
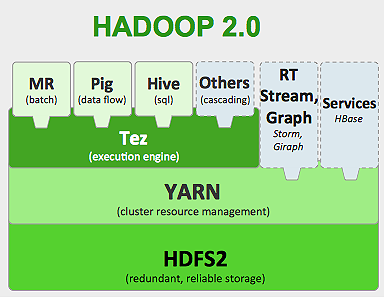
Il framework Hadoop funziona come di seguito:
- Suddivide i file di dati di grandi dimensioni in blocchi più piccoli per essere elaborati dalle singole macchine (Distribuzione dell'archiviazione).
- Divide il lavoro più lungo in compiti più piccoli da eseguire in parallelo (calcolo parallelo).
- Gestisce automaticamente gli errori.
Limitazioni di Hadoop
Hadoop ha strumenti specializzati nel suo ecosistema per eseguire diversi compiti. Quindi, se vuoi eseguire un ciclo di vita end-to-end di un'applicazione, devi utilizzare più strumenti. Ad esempio, per le query SQL utilizzerai hive/pig , per le sorgenti di streaming devi utilizzare lo streaming integrato di Hadoop o Apache Storm (che non fa parte dell'ecosistema Hadoop) o per algoritmi di machine learning devi usare Mahout . L'integrazione di tutti questi sistemi insieme per creare un unico caso d'uso della pipeline di dati è un compito piuttosto impegnativo.
Nel lavoro MapReduce ,
- Tutto l'output delle attività della mappa viene scaricato su dischi locali (o HDFS).
- Hadoop unisce tutti i file di spill in un file più grande che viene ordinato e partizionato in base al numero di riduttori.
- E ridurre le attività per caricarlo di nuovo in memoria.
Questo processo rallenta il lavoro causando I/O su disco e I/O di rete. Ciò rende Mapreduce non idoneo per l'elaborazione iterativa in cui è necessario applicare algoritmi di apprendimento automatico allo stesso gruppo di dati più e più volte.
Entra nel mondo di Apache Spark:
Apache Spark è stato sviluppato nell'UC Berkeley AMPLAB nel 2009 e nel 2010 è diventato il progetto open source con il miglior contributo di Apache fino ad oggi.
Apache Spark è un sistema più generalizzato , in cui è possibile eseguire lavori in batch e in streaming alla volta. Sostituisce in velocità il predecessore MapReduce aggiungendo funzionalità per elaborare i dati più velocemente in memoria. È anche più efficiente su disco. Sfrutta l'elaborazione della memoria utilizzando la sua unità dati di base RDD (Resilient Distributed Dataset). Questi contengono il maggior numero di set di dati possibile in memoria per il ciclo di vita completo del lavoro, risparmiando così sull'I/O del disco. Alcuni dati possono essere riversati sul disco dopo i limiti superiori della memoria.
Il grafico sottostante mostra il tempo di esecuzione in secondi di Apache Hadoop e Spark per il calcolo della regressione logistica. Hadoop ha impiegato 110 secondi mentre Spark ha terminato lo stesso lavoro in soli 0,9 secondi.
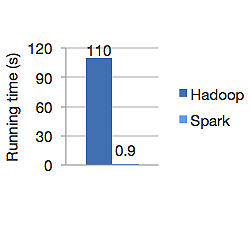
Spark non memorizza tutti i dati in memoria. Ma se i dati sono in memoria, utilizza al meglio la cache LRU per elaborarli più velocemente. È 100 volte più veloce durante il calcolo dei dati in memoria e ancora più veloce su disco rispetto a Hadoop.
Il modello di archiviazione dei dati distribuiti di Spark, i set di dati distribuiti resilienti (RDD), garantisce la tolleranza agli errori che a sua volta riduce al minimo l'I/O di rete. Spark paper dice:

"Gli RDD ottengono la tolleranza agli errori attraverso una nozione di lignaggio: se una partizione di un RDD viene persa, l'RDD ha informazioni sufficienti su come è stato derivato da altri RDD per essere in grado di ricostruire solo quella partizione".
Quindi non è necessario replicare i dati per ottenere la tolleranza agli errori.
In Spark MapReduce, l'output dei mappatori viene mantenuto nella cache del buffer del sistema operativo e i riduttori lo tirano dalla loro parte e lo scrivono direttamente nella loro memoria, a differenza di Hadoop in cui l'output viene riversato sul disco e lo legge di nuovo.
La cache in memoria di Spark lo rende adatto per algoritmi di apprendimento automatico in cui è necessario utilizzare gli stessi dati più e più volte. Spark può eseguire lavori complessi, pipeline di dati a più passaggi utilizzando il grafico aciclico diretto (DAG).
Spark è scritto in Scala e funziona su JVM (Java Virtual Machine). Spark offre API di sviluppo per i linguaggi Java, Scala, Python e R. Spark funziona su Hadoop YARN, Apache Mesos e dispone di un proprio cluster manager autonomo.
Nel 2014 si è assicurato il 1° posto nel record mondiale per l'ordinamento di benchmark di dati da 100 TB (1 trilione di record) in soli 23 minuti, mentre il precedente record di Hadoop di Yahoo era di circa 72 minuti. Ciò dimostra che Spark ha ordinato i dati 3 volte più velocemente e con 10 volte meno macchine. Tutto l'ordinamento è avvenuto su disco (HDFS), senza utilizzare effettivamente la capacità della cache in memoria Spark.
Ecosistema Scintilla
Spark è pensato per eseguire analisi avanzate in una volta sola, per ottenere i seguenti componenti:
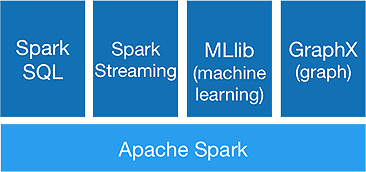
1.Spark Core:
L'API Spark core è la base del framework Apache Spark, che gestisce la pianificazione dei lavori, la distribuzione delle attività, la gestione della memoria, le operazioni di I/O e il ripristino da errori. L'unità dati logica principale in spark è denominata RDD (Resilient Distributed Dataset), che memorizza i dati in modo distribuito per essere elaborati in parallelo in seguito. Calcola pigramente le operazioni. Pertanto, la memoria non deve essere sempre occupata e altri lavori possono utilizzarla.
2.Spark SQL:
Offre funzionalità di query interattive con bassa latenza. La nuova API DataFrame può contenere dati strutturati e semi-strutturati e consentire a tutte le operazioni e funzioni SQL di eseguire calcoli.
3. Streaming scintillante:
Fornisce API di streaming in tempo reale , che raccolgono ed elaborano i dati in micro batch.
Utilizza Dstreams che non è altro che una sequenza continua di RDD , per calcolare le logiche di business sui dati in entrata e generare risultati immediatamente.
4.MLlib :
È la libreria di apprendimento automatico di Spark (quasi 9 volte più veloce di Mahout) che fornisce apprendimento automatico e algoritmi statistici come classificazione, regressione, filtraggio collaborativo ecc.
5.GraphX :
L'API GraphX fornisce funzionalità per gestire i grafici ed eseguire calcoli paralleli ai grafici. Include algoritmi grafici come PageRank e varie funzioni per analizzare i grafici.
Spark segnerà la fine dell'era Hadoop?
Spark è un sistema ancora giovane, non maturo come Hadoop. Non esiste uno strumento per NOSQL come HBase. Considerando l'elevata richiesta di memoria per un'elaborazione dei dati più rapida, non si può davvero dire che funzioni su hardware di base. Spark non ha un proprio sistema di archiviazione. Si basa su HDFS per questo.
Quindi, Hadoop MapReduce è ancora valido per alcuni lavori batch, che non includono molto il pipelining dei dati.
“La nuova tecnologia non sostituisce mai completamente quella vecchia; entrambi preferirebbero coesistere.
Conclusione
In questo blog abbiamo esaminato il motivo per cui hai bisogno di uno strumento come Spark, cosa rende più veloce il sistema di cluster computing e i suoi componenti principali. Nella parte successiva approfondiremo gli RDD, le trasformazioni e le azioni dell'API core di Spark.