
Efficacia della scansione: come aumentare di livello l'ottimizzazione della scansione
Pubblicato: 2022-10-27Non è garantito che Googlebot eseguirà la scansione di tutti gli URL a cui può accedere sul tuo sito. Al contrario, alla stragrande maggioranza dei siti manca una parte significativa di pagine.
La realtà è che Google non ha le risorse per eseguire la scansione di ogni pagina che trova. Tutti gli URL che Googlebot ha scoperto, ma non ha ancora scansionato, insieme agli URL che intende ripetere la scansione hanno la priorità in una coda di scansione.
Ciò significa che Googlebot esegue la scansione solo di quelli a cui è assegnata una priorità sufficientemente alta. E poiché la coda di scansione è dinamica, cambia continuamente mentre Google elabora nuovi URL. E non tutti gli URL si uniscono in fondo alla coda.
Quindi, come ti assicuri che gli URL del tuo sito siano VIP e salti la linea?
La scansione è di fondamentale importanza per la SEO

Affinché i contenuti ottengano visibilità, Googlebot deve prima eseguirne la scansione.
Ma i vantaggi sono più sfumati di così perché più velocemente viene eseguita la scansione di una pagina da quando è:
- Creato , prima i nuovi contenuti possono essere visualizzati su Google. Ciò è particolarmente importante per le strategie di contenuto a tempo limitato o first-to-market.
- Aggiornato , prima il contenuto aggiornato può iniziare a incidere sulle classifiche. Ciò è particolarmente importante sia per le strategie di ripubblicazione dei contenuti che per le tattiche SEO tecniche.
In quanto tale, la scansione è essenziale per tutto il tuo traffico organico. Eppure troppo spesso si dice che l'ottimizzazione della scansione sia vantaggiosa solo per i siti Web di grandi dimensioni.
Ma non si tratta delle dimensioni del tuo sito Web, della frequenza di aggiornamento dei contenuti o del fatto che tu abbia esclusioni "Scoperta - attualmente non indicizzata" in Google Search Console.
L'ottimizzazione della scansione è vantaggiosa per ogni sito web. L'idea sbagliata del suo valore sembra scaturire da misurazioni prive di significato, in particolare il crawl budget.
Il budget di scansione non ha importanza

Troppo spesso, la scansione viene valutata in base al crawl budget. Questo è il numero di URL di cui Googlebot eseguirà la scansione in un determinato periodo di tempo su un determinato sito web.
Google afferma che è determinato da due fattori:
- Limite della velocità di scansione (o ciò che Googlebot può scansionare): la velocità con cui Googlebot può recuperare le risorse del sito Web senza influire sulle prestazioni del sito. In sostanza, un server reattivo porta a una velocità di scansione più elevata.
- Domanda di scansione (o ciò che Googlebot vuole scansionare): il numero di URL visitati da Googlebot durante una singola scansione in base alla domanda di (ri)indicizzazione, influenzata dalla popolarità e dalla datazione dei contenuti del sito.
Una volta che Googlebot "spende" il suo budget di scansione, interrompe la scansione di un sito.
Google non fornisce una cifra per il crawl budget. La cosa più vicina è mostrare le richieste di scansione totali nel rapporto sulle statistiche di scansione di Google Search Console.
Così tanti SEO, incluso me stesso in passato, si sono dati da fare per cercare di dedurre il crawl budget.
I passaggi spesso presentati sono qualcosa sulla falsariga di:
- Determina quante pagine scansionabili hai sul tuo sito, consigliando spesso di guardare il numero di URL nella tua mappa del sito XML o di eseguire un crawler illimitato.
- Calcola le scansioni medie giornaliere esportando il rapporto Statistiche di scansione di Google Search Console o in base alle richieste di Googlebot nei file di registro.
- Dividi il numero di pagine per le scansioni medie giornaliere. Si dice spesso che se il risultato è superiore a 10, concentrati sull'ottimizzazione del crawl budget.
Tuttavia, questo processo è problematico.
Non solo perché presuppone che ogni URL venga scansionato una volta, quando in realtà alcuni vengono scansionati più volte, altri no.
Non solo perché presuppone che una scansione corrisponda a una pagina. Quando in realtà una pagina può richiedere molte scansioni di URL per recuperare le risorse (JS, CSS, ecc.) necessarie per caricarla.
Ma soprattutto, perché quando viene distillato in una metrica calcolata come le scansioni medie giornaliere, il crawl budget non è altro che una metrica di vanità.
Qualsiasi tattica mirata all'"ottimizzazione del crawl budget" (ovvero, mirare ad aumentare continuamente la quantità totale di scansione) è una commissione stupida.
Perché dovresti preoccuparti di aumentare il numero totale di scansioni se viene utilizzato su URL senza valore o pagine che non sono state modificate dall'ultima scansione? Tali scansioni non aiuteranno le prestazioni SEO.
Inoltre, chiunque abbia mai esaminato le statistiche di scansione sa che fluttuano, spesso in modo piuttosto sfrenato, da un giorno all'altro a seconda di un numero qualsiasi di fattori. Queste fluttuazioni possono essere correlate o meno alla rapida (re)indicizzazione di pagine rilevanti per la SEO.
Un aumento o una diminuzione del numero di URL scansionati non è né intrinsecamente positivo né negativo.
L'efficacia della scansione è un KPI SEO

Per le pagine che desideri vengano indicizzate, l'attenzione non dovrebbe essere sull'eventualità che sia stata sottoposta a scansione, ma piuttosto sulla velocità con cui è stata scansionata dopo essere stata pubblicata o modificata in modo significativo.
In sostanza, l'obiettivo è ridurre al minimo il tempo tra la creazione o l'aggiornamento di una pagina rilevante per la SEO e la successiva scansione di Googlebot. Io chiamo questo ritardo di tempo l'efficacia della scansione.
Il modo ideale per misurare l'efficacia della scansione è calcolare la differenza tra la data e l'ora di creazione o aggiornamento del database e la successiva scansione di Googlebot dell'URL dai file di registro del server.
Se è difficile ottenere l'accesso a questi punti dati, puoi anche utilizzare come proxy la data dell'ultima modifica della mappa del sito XML e gli URL di query nell'API di controllo degli URL di Google Search Console per il suo ultimo stato di scansione (fino a un limite di 2.000 query al giorno).
Inoltre, utilizzando l'API di ispezione degli URL puoi anche monitorare quando lo stato dell'indicizzazione cambia per calcolare l'efficacia dell'indicizzazione per gli URL appena creati, che è la differenza tra la pubblicazione e l'indicizzazione riuscita.
Perché la scansione senza che abbia un impatto sullo stato dell'indicizzazione o l'elaborazione di un aggiornamento del contenuto della pagina è solo uno spreco.
L'efficacia della scansione è una metrica praticabile perché, man mano che diminuisce, più contenuti critici per la SEO possono essere mostrati al tuo pubblico su Google.
Puoi anche usarlo per diagnosticare problemi SEO. Approfondisci i pattern URL per comprendere la velocità con cui viene eseguita la scansione dei contenuti delle varie sezioni del tuo sito e se questo è ciò che frena le prestazioni organiche.
Se vedi che Googlebot impiega ore, giorni o settimane per eseguire la scansione e quindi indicizzare i tuoi contenuti appena creati o aggiornati di recente, cosa puoi fare al riguardo?
Ricevi la newsletter quotidiana su cui fanno affidamento i marketer.
Vedi termini.
7 passaggi per ottimizzare la scansione
L'ottimizzazione della scansione consiste nel guidare Googlebot a eseguire la scansione di URL importanti veloce quando vengono (ri)pubblicati. Segui i sette passaggi seguenti.
1. Garantire una risposta del server rapida e sana
Un server ad alte prestazioni è fondamentale. Googlebot rallenterà o interromperà la scansione quando:
- La scansione del tuo sito influisce sulle prestazioni. Ad esempio, più eseguono la scansione, più lento sarà il tempo di risposta del server.
- Il server risponde con un numero notevole di errori o timeout di connessione.
D'altra parte, migliorare la velocità di caricamento della pagina consentendo la pubblicazione di più pagine può portare Googlebot a eseguire la scansione di più URL nello stesso lasso di tempo. Questo è un ulteriore vantaggio oltre al fatto che la velocità della pagina è un'esperienza utente e un fattore di ranking.
Se non lo fai già, considera il supporto per HTTP/2, in quanto consente la possibilità di richiedere più URL con un carico simile sui server.
Tuttavia, la correlazione tra prestazioni e volume di scansione è solo fino a un certo punto . Una volta superata tale soglia, che varia da sito a sito, è improbabile che eventuali miglioramenti aggiuntivi nelle prestazioni del server siano correlati a un aumento della scansione.
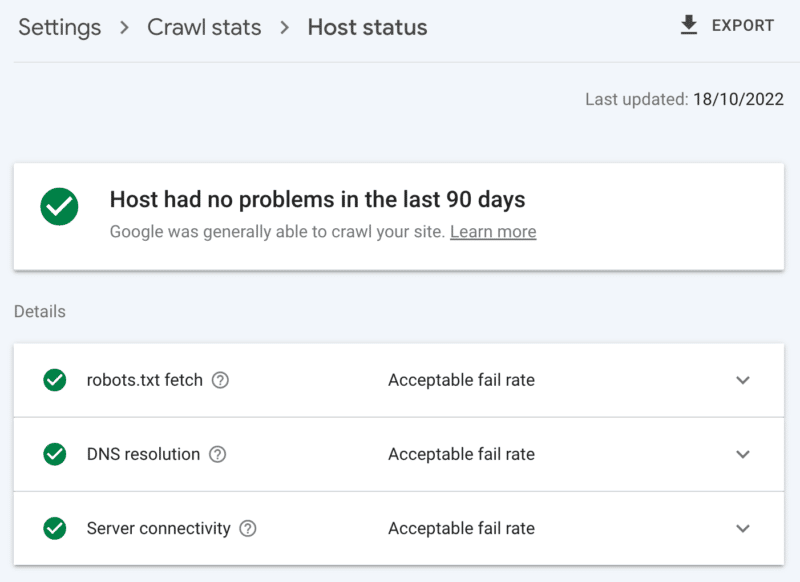
Come controllare lo stato del server
Il rapporto sulle statistiche di scansione di Google Search Console:
- Stato host: mostra segni di spunta verdi.
- Errori 5xx: Costituisce meno dell'1%.
- Grafico del tempo di risposta del server: trend inferiore a 300 millisecondi.
2. Ripulire i contenuti di basso valore
Se una quantità significativa di contenuto del sito è obsoleta, duplicata o di bassa qualità, provoca competizione per l'attività di scansione, ritardando potenzialmente l'indicizzazione di nuovi contenuti o la reindicizzazione di contenuti aggiornati.

Aggiungi che la pulizia regolare di contenuti di basso valore riduce anche il rigonfiamento dell'indice e la cannibalizzazione delle parole chiave ed è vantaggioso per l'esperienza dell'utente, questo è un gioco da ragazzi SEO.
Unisci il contenuto con un reindirizzamento 301, quando hai un'altra pagina che può essere vista come una chiara sostituzione; capire che questo ti costerà il doppio della scansione per l'elaborazione, ma è un sacrificio utile per l'equità del collegamento.
Se non sono presenti contenuti equivalenti, l'utilizzo di un 301 risulterà solo in un 404 soft. Rimuovi tale contenuto utilizzando un codice di stato 410 (migliore) o 404 (secondo vicino) per fornire un segnale forte per non eseguire nuovamente la scansione dell'URL.
Come verificare la presenza di contenuti di basso valore
Il numero di URL nelle pagine di Google Search Console riporta le esclusioni "scansionate - attualmente non indicizzate". Se questo è alto, esaminare i campioni forniti per i modelli di cartelle o altri indicatori di problema.
3. Rivedere i controlli di indicizzazione
Rel=link canonici sono un valido suggerimento per evitare problemi di indicizzazione, ma spesso sono troppo affidabili e finiscono per causare problemi di scansione poiché ogni URL canonico costa almeno due scansioni, una per se stesso e una per il suo partner.
Allo stesso modo, le direttive sui robot noindex sono utili per ridurre il rigonfiamento dell'indice, ma un gran numero può influire negativamente sulla scansione, quindi usale solo quando necessario.
In entrambi i casi chiediti:
- Queste direttive di indicizzazione sono il modo ottimale per gestire la sfida SEO?
- È possibile consolidare, rimuovere o bloccare alcuni percorsi URL in robots.txt?
Se lo stai utilizzando, riconsidera seriamente AMP come una soluzione tecnica a lungo termine.
Con l'aggiornamento dell'esperienza della pagina incentrato sui principali elementi vitali del Web e l'inclusione di pagine non AMP in tutte le esperienze di Google purché soddisfi i requisiti di velocità del sito, esamina attentamente se AMP vale la doppia scansione.
Come controllare l'eccessiva dipendenza dai controlli di indicizzazione
Il numero di URL nel rapporto sulla copertura di Google Search Console classificati nelle esclusioni senza un motivo chiaro:
- Pagina alternativa con tag canonico appropriato.
- Escluso dal tag noindex.
- Duplicato, Google ha scelto canonico diverso da quello dell'utente.
- URL inviato duplicato non selezionato come canonico.
4. Dì agli spider dei motori di ricerca cosa scansionare e quando
Uno strumento essenziale per aiutare Googlebot a dare priorità agli URL dei siti importanti e a comunicare quando tali pagine vengono aggiornate è una mappa del sito XML.
Per una guida efficace del crawler, assicurati di:
- Includi solo URL che sono sia indicizzabili che preziosi per la SEO: in genere, 200 codici di stato, pagine di contenuto canoniche e originali con un tag robots "index, follow" per il quale ti preoccupi della loro visibilità nelle SERP.
- Includi tag timestamp <lastmod> accurati sui singoli URL e sulla mappa del sito stessa il più vicino possibile al tempo reale.
Google non controlla una mappa del sito ogni volta che viene eseguita la scansione di un sito. Quindi, ogni volta che viene aggiornato, è meglio inviarlo all'attenzione di Google. Per farlo, invia una richiesta GET nel tuo browser o dalla riga di comando a:
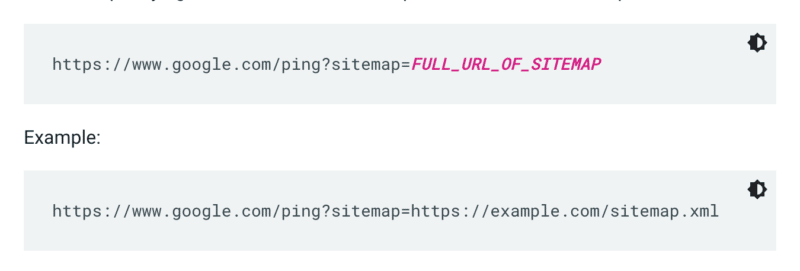
Inoltre, specifica i percorsi della mappa del sito nel file robots.txt e invialo a Google Search Console utilizzando il rapporto sulle mappe del sito.
Di norma, Google eseguirà la scansione degli URL nelle Sitemap più spesso di altri. Ma anche se una piccola percentuale di URL all'interno della tua mappa del sito è di bassa qualità, può dissuadere Googlebot dall'utilizzarla per la scansione dei suggerimenti.
Le mappe del sito e i collegamenti XML aggiungono URL alla normale coda di scansione. C'è anche una coda di ricerca per indicizzazione prioritaria, per la quale sono disponibili due metodi di immissione.
Innanzitutto, per coloro che hanno annunci di lavoro o video live, puoi inviare URL all'API di indicizzazione di Google.
Oppure, se vuoi attirare l'attenzione di Microsoft Bing o Yandex, puoi utilizzare l'API IndexNow per qualsiasi URL. Tuttavia, nei miei test, ha avuto un impatto limitato sulla scansione degli URL. Quindi, se usi IndexNow, assicurati di monitorare l'efficacia della scansione per Bingbot.
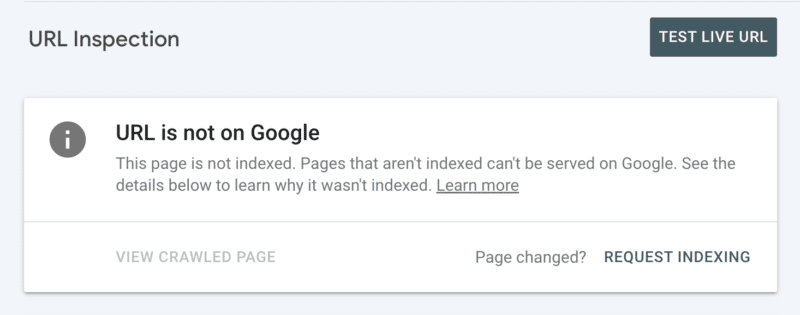
In secondo luogo, puoi richiedere manualmente l'indicizzazione dopo aver esaminato l'URL in Search Console. Sebbene tieni presente che esiste una quota giornaliera di 10 URL e la scansione può richiedere comunque alcune ore. È meglio vederlo come una patch temporanea mentre scavi per scoprire la radice del tuo problema di scansione.
Come verificare la guida essenziale per la scansione di Googlebot
In Google Search Console, la tua mappa del sito XML mostra lo stato "Success" ed è stata letta di recente.
5. Dì agli spider dei motori di ricerca cosa non eseguire la scansione
Alcune pagine possono essere importanti per gli utenti o per la funzionalità del sito, ma non desideri che vengano visualizzate nei risultati di ricerca. Impedisci a tali percorsi URL di distrarre i crawler con un disallow di robots.txt. Questo potrebbe includere:
- API e CDN . Ad esempio, se sei un cliente di Cloudflare, assicurati di non consentire la cartella /cdn-cgi/ che viene aggiunta al tuo sito.
- Immagini, script o file di stile non importanti, se le pagine caricate senza queste risorse non sono interessate in modo significativo dalla perdita.
- Pagina funzionale , ad esempio un carrello degli acquisti.
- Spazi infiniti , come quelli creati dalle pagine del calendario.
- Pagine dei parametri . Soprattutto quelli della navigazione a faccette che filtrano (ad esempio, ?price-range=20-50), riordinano (ad esempio, ?sort=) o cercano (ad esempio, ?q=) poiché ogni singola combinazione viene conteggiata dai crawler come una pagina separata.
Fare attenzione a non bloccare completamente il parametro di impaginazione. L'impaginazione scansionabile fino a un certo punto è spesso essenziale per Googlebot per scoprire contenuti ed elaborare l'equità dei link interni. (Guarda questo webinar Semrush sull'impaginazione per saperne di più dettagli sul perché.)
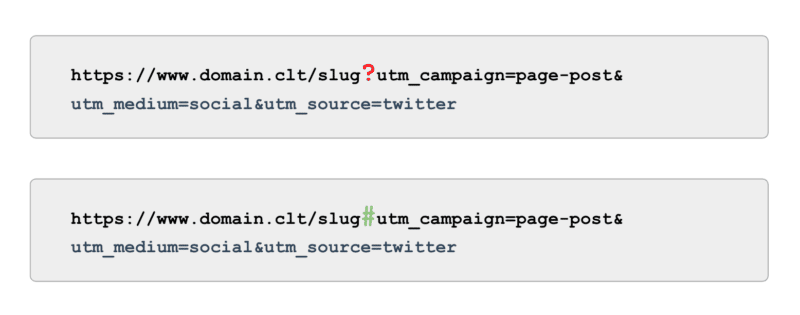
E quando si tratta di tracciamento, anziché utilizzare tag UTM basati su parametri (ovvero '?'), utilizzare ancoraggi (ovvero '#'). Offre gli stessi vantaggi di reporting in Google Analytics senza essere scansionabile.
Come verificare la presenza di Googlebot non esegue la scansione della guida
Esamina l'esempio di URL "Indicizzati, non inviati nella mappa del sito" in Google Search Console. Ignorando le prime pagine di impaginazione, quali altri percorsi trovi? Dovrebbero essere inclusi in una mappa del sito XML, bloccati dalla scansione o lasciati essere?
Inoltre, controlla l'elenco di "Scoperta - attualmente non indicizzata" - bloccando in robots.txt tutti i percorsi URL che offrono un valore basso o nullo per Google.
Per portare questo al livello successivo, esamina tutte le scansioni degli smartphone Googlebot nei file di registro del server per individuare percorsi privi di valore.
6. Cura i collegamenti pertinenti
I backlink a una pagina sono preziosi per molti aspetti della SEO e la scansione non fa eccezione. Ma i collegamenti esterni possono essere difficili da ottenere per determinati tipi di pagina. Ad esempio, pagine profonde come prodotti, categorie ai livelli inferiori nell'architettura del sito o persino articoli.
D'altra parte, i link interni rilevanti sono:
- Tecnicamente scalabile.
- Segnali potenti a Googlebot per dare la priorità a una pagina per la scansione.
- Particolarmente impattante per la scansione profonda delle pagine.
I breadcrumb, i blocchi di contenuto correlati, i filtri rapidi e l'uso di tag ben curati sono tutti vantaggi significativi per l'efficacia della scansione. Poiché sono contenuti SEO-critical, assicurati che tali collegamenti interni non dipendano da JavaScript, ma piuttosto utilizza un collegamento <a> standard e scansionabile.
Tenere presente che tali collegamenti interni dovrebbero anche aggiungere un valore effettivo per l'utente.
Come verificare la presenza di collegamenti pertinenti
Esegui una scansione manuale del tuo sito completo con uno strumento come lo spider SEO di ScreamingFrog, cercando:
- URL orfani.
- Collegamenti interni bloccati da robots.txt.
- Collegamenti interni a qualsiasi codice di stato diverso da 200.
- La percentuale di URL non indicizzabili collegati internamente.
7. Verificare i problemi di scansione rimanenti
Se tutte le ottimizzazioni di cui sopra sono complete e l'efficacia della scansione non è ottimale, esegui un audit approfondito.
Inizia esaminando gli esempi di eventuali restanti esclusioni di Google Search Console per identificare i problemi di scansione.
Una volta che questi sono stati risolti, approfondisci utilizzando uno strumento di scansione manuale per eseguire la scansione di tutte le pagine nella struttura del sito come farebbe Googlebot. Fai un riferimento incrociato con i file di registro ristretti agli IP di Googlebot per capire quali di queste pagine sono e non vengono sottoposte a scansione.
Infine, l'avvio dell'analisi dei file di registro si è ristretto all'IP di Googlebot per almeno quattro settimane di dati, idealmente di più.
Se non hai familiarità con il formato dei file di registro, utilizza uno strumento di analisi dei registri. In definitiva, questa è la migliore fonte per capire come Google esegue la scansione del tuo sito.
Una volta completata la verifica e disponi di un elenco di problemi di scansione identificati, classifica ogni problema in base al livello di impegno previsto e all'impatto sulle prestazioni.
Nota : altri esperti SEO hanno affermato che i clic dalle SERP aumentano la scansione dell'URL della pagina di destinazione. Tuttavia, non sono ancora stato in grado di confermarlo con i test.
Dai priorità all'efficacia della scansione rispetto al budget di scansione
L'obiettivo della scansione non è quello di ottenere il massimo numero di scansioni né di eseguire la scansione ripetuta di ogni pagina di un sito Web, ma di invogliare una scansione di contenuti rilevanti per la SEO il più vicino possibile a quando una pagina viene creata o aggiornata.
Nel complesso, i budget non contano. È ciò in cui investi che conta.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente di Search Engine Land. Gli autori dello staff sono elencati qui.