
Una guida alla diagnosi dei problemi SEO comuni di JavaScript
Pubblicato: 2023-07-10Siamo onesti, JavaScript e SEO non sempre giocano bene insieme. Per alcuni SEO, l'argomento può sembrare avvolto da un velo di complessità.
Bene, buone notizie: quando togli i livelli, molti problemi SEO basati su JavaScript tornano ai fondamenti di come i crawler dei motori di ricerca interagiscono con JavaScript in primo luogo.
Quindi, se capisci questi fondamenti, puoi scavare nei problemi, capirne l'impatto e lavorare con gli sviluppatori per risolvere quelli che contano.
In questo articolo, ti aiuteremo a diagnosticare alcuni problemi comuni quando i siti sono costruiti su framework JS. Inoltre, analizzeremo le conoscenze di base di cui ogni SEO tecnico ha bisogno quando si tratta di rendering.
Rendering in poche parole
Prima di entrare nelle cose più granulari, parliamo di una visione d'insieme.
Affinché un motore di ricerca comprenda i contenuti basati su JavaScript, deve eseguire la scansione e il rendering della pagina.
Il problema è che i motori di ricerca hanno solo così tante risorse da utilizzare, quindi devono essere selettivi su quando vale la pena utilizzarle. Non è scontato che una pagina venga renderizzata, anche se il crawler la invia alla coda di rendering.
Se sceglie di non eseguire il rendering della pagina o non è in grado di eseguire correttamente il rendering del contenuto, potrebbe essere un problema.
Dipende da come il front-end serve l'HTML nella risposta iniziale del server.
Quando un URL viene creato nel browser, un front-end come React, Vue o Gatsby genererà l'HTML per la pagina. Un crawler controlla se quell'HTML è già disponibile dal server (HTML "pre-renderizzato"), prima di inviare l'URL per attendere il rendering in modo che possa esaminare il contenuto risultante.
La disponibilità di HTML pre-renderizzato dipende dalla configurazione del front-end. Genererà l'HTML tramite il server o nel browser client.
Rendering lato server
Il nome dice tutto. In una configurazione SSR, il crawler riceve una pagina HTML completamente renderizzata senza richiedere l'esecuzione e il rendering JS aggiuntivi.
Quindi, anche se la pagina non viene visualizzata, il motore di ricerca può comunque eseguire la scansione di qualsiasi codice HTML, contestualizzare la pagina (metadati, copia, immagini) e comprendere la sua relazione con altre pagine (breadcrumb, URL canonico, collegamenti interni).
Rendering lato client
In CSR, l'HTML viene generato nel browser insieme a tutti i componenti JavaScript. È necessario eseguire il rendering di JavaScript prima che l'HTML sia disponibile per la scansione.
Se il servizio di rendering sceglie di non eseguire il rendering di una pagina inviata alla coda, la copia, gli URL interni, i collegamenti alle immagini e persino i metadati non sono disponibili per i crawler.
Di conseguenza, i motori di ricerca hanno poco o nessun contesto per comprendere la rilevanza di un URL per le query di ricerca.
Nota : può esserci una combinazione di HTML che viene servito nella risposta HTML iniziale, così come HTML che richiede l'esecuzione di JS per poter essere visualizzato (apparire). Dipende da diversi fattori, i più comuni dei quali includono il framework, la modalità di creazione dei singoli componenti del sito e la configurazione del server.
Il kit di strumenti SEO JavaScript
Esistono sicuramente strumenti là fuori che aiuteranno a identificare i problemi SEO relativi a JavaScript.
Puoi eseguire molte indagini utilizzando gli strumenti del browser e Google Search Console. Ecco la shortlist che costituisce un solido toolkit:
- Visualizza sorgente: fai clic con il pulsante destro del mouse su una pagina e fai clic su "Visualizza sorgente" per visualizzare l'HTML pre-renderizzato della pagina (la risposta iniziale del server).
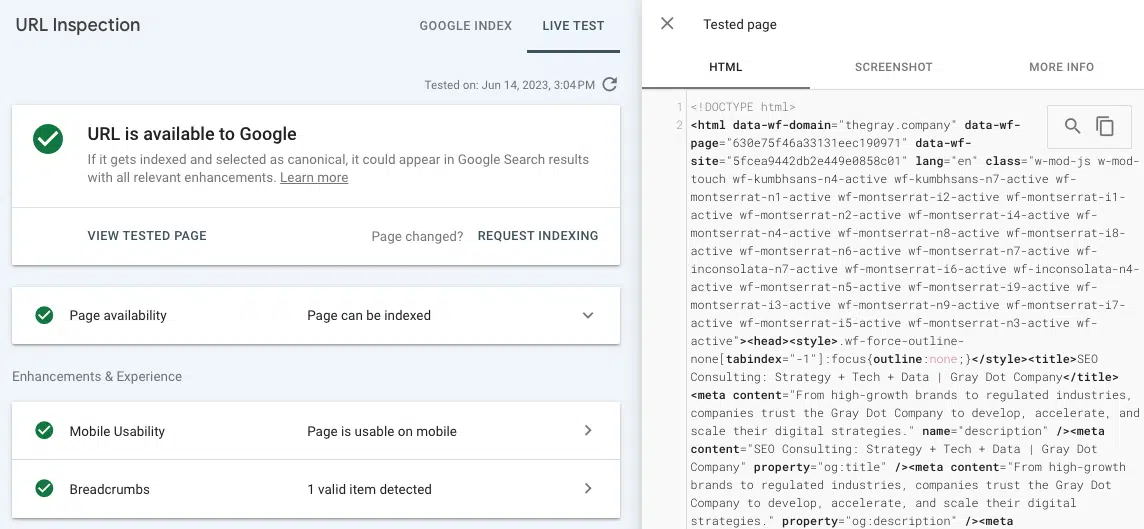
- Test live URL (controllo URL): visualizza uno screenshot, codice HTML e altri dettagli importanti di una pagina visualizzata nella scheda Controllo URL di Google Search Console. (Molti problemi di rendering possono essere trovati confrontando l'HTML pre-renderizzato da "visualizza sorgente" con l'HTML renderizzato dal test dell'URL live in GSC.)
- Strumenti per sviluppatori di Chrome: fai clic con il pulsante destro del mouse su una pagina e scegli "Ispeziona" per aprire gli strumenti per la visualizzazione degli errori JavaScript e altro.
- Wappalyzer: guarda lo stack su cui è costruito qualsiasi sito e cerca approfondimenti specifici del framework installando questa estensione gratuita di Chrome.
Problemi SEO comuni di JavaScript
Problema 1: l'HTML pre-renderizzato non è universalmente disponibile
Oltre alle implicazioni negative per la scansione e la contestualizzazione menzionate in precedenza, c'è anche il problema del tempo e delle risorse che potrebbero essere necessari a un motore di ricerca per eseguire il rendering di una pagina.
Se il crawler sceglie di inserire un URL nel processo di rendering, finirà nella coda di rendering. Ciò accade perché un crawler può rilevare una disparità tra la struttura HTML pre-renderizzata e quella renderizzata. (Il che ha molto senso se non c'è HTML pre-renderizzato!)
Non c'è alcuna garanzia sul tempo di attesa di un URL per il servizio di rendering web. Il modo migliore per influenzare il WRS in un rendering tempestivo è garantire che ci siano segnali di autorità chiave in loco che illustrino l'importanza di un URL (ad esempio, collegato nel menu di navigazione superiore, molti collegamenti interni, referenziati come canonici). Ciò diventa un po' complicato perché anche i segnali di autorità devono essere scansionati.
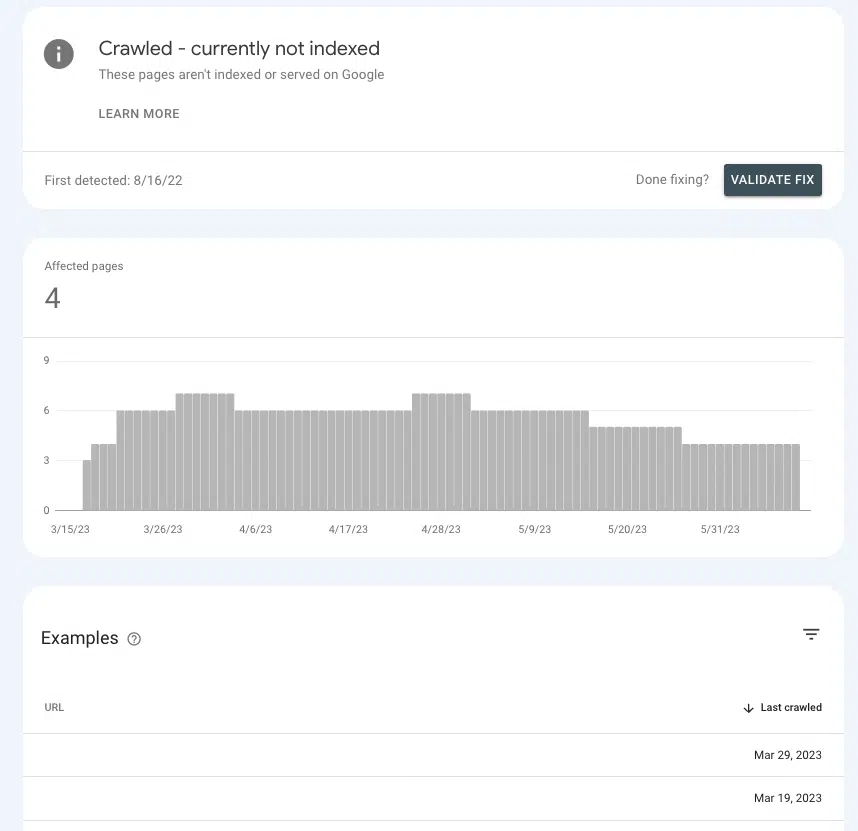
In Google Search Console, è possibile capire se stai inviando i giusti segnali di autorità alle pagine chiave o se le stai facendo sedere in un limbo.
Vai su Pagine > Indicizzazione pagina > Scansionato – attualmente non indicizzato e cerca la presenza di pagine prioritarie all'interno dell'elenco.
Se sono nella sala d'attesa, è perché Google non può accertare se sono abbastanza importanti da spendere risorse.
Cause comuni
Impostazioni predefinite
I front-end più popolari sono "out of the box" impostati sul rendering lato client, quindi c'è una buona possibilità che le impostazioni predefinite siano il colpevole.
Se ti stai chiedendo perché la maggior parte dei frontend passa automaticamente alla CSR, è a causa dei vantaggi in termini di prestazioni. Gli sviluppatori non amano sempre SSR, perché può limitare le possibilità di velocizzare un sito e implementare determinati elementi interattivi (ad esempio, transizioni uniche tra le pagine).
Applicazione a pagina singola
Se un sito è un'applicazione a pagina singola, è avvolto interamente in JavaScript e genera tutti i componenti di una pagina nel browser (ovvero tutto) viene visualizzato sul lato client e le nuove pagine vengono pubblicate senza ricaricare).
Ciò ha alcune implicazioni negative, forse la più importante delle quali è che le pagine sono potenzialmente non rilevabili.
Questo non vuol dire che sia impossibile allestire una SPA in un modo più SEO-friendly. Ma è probabile che ci sarà del lavoro di sviluppo significativo necessario per farlo accadere.
Problema 2: alcuni contenuti della pagina non sono accessibili ai crawler
Fare in modo che un motore di ricerca esegua il rendering di un URL è fantastico, purché tutti gli elementi siano disponibili per la scansione. Cosa succede se sta visualizzando la pagina, ma ci sono sezioni di una pagina che non sono accessibili?
Ad esempio, un SEO esegue un'analisi dei collegamenti interni e trova poco o nessun collegamento interno segnalato per un URL collegato su più pagine.
Se il collegamento non viene visualizzato nell'HTML visualizzato dallo strumento Test Live URL, è probabile che sia pubblicato in risorse JavaScript a cui Google non è in grado di accedere.
Per restringere il campo del colpevole, sarebbe una buona idea cercare punti in comune in termini di dove il contenuto della pagina mancante o i collegamenti interni si trovano nella pagina tra gli URL.
Ad esempio, se si tratta di un collegamento alle domande frequenti che appare nella stessa sezione di ogni pagina di prodotto, aiuta molto gli sviluppatori a restringere il campo di una correzione.
Cause comuni
Errori JavaScript
Cominciamo con un disclaimer qui. La maggior parte degli errori JavaScript che riscontri non ha importanza per la SEO.
Quindi, se vai a caccia di errori, porti un lungo elenco al tuo sviluppatore e inizi la conversazione con "Cosa sono tutti questi errori?", Potrebbero non riceverlo così bene.
Affronta il "perché" parlando del problema, in modo che possano essere gli esperti di JavaScript (perché lo sono!).
Detto questo, ci sono errori di sintassi che potrebbero rendere il resto della pagina non analizzabile (es. “render blocking”). Quando ciò accade, il renderer non può suddividere i singoli elementi HTML, strutturare il contenuto nel DOM o comprendere le relazioni.
Generalmente, questi tipi di errori sono riconoscibili perché hanno una sorta di effetto anche nella visualizzazione del browser.
Oltre alla conferma visiva, è anche possibile visualizzare gli errori JavaScript facendo clic con il pulsante destro del mouse sulla pagina, scegliendo "ispeziona" e accedendo alla scheda "Console".
Ottieni la newsletter quotidiana su cui si affidano i marketer di ricerca.
Vedi termini.
Il contenuto richiede l'interazione dell'utente
Una delle cose più importanti da ricordare sul rendering è che Google non può eseguire il rendering di alcun contenuto che richieda agli utenti di interagire con la pagina. O, per dirla più semplicemente, non può "fare clic" sulle cose.

Perché è importante? Pensa al nostro vecchio e fidato amico, il menu a discesa della fisarmonica e a quanti siti lo utilizzano per organizzare contenuti come dettagli sui prodotti e domande frequenti.
A seconda di come è codificata la fisarmonica, Google potrebbe non essere in grado di eseguire il rendering del contenuto nel menu a discesa se non viene popolato fino all'esecuzione di JS.
Per controllare, puoi "ispezionare" una pagina e vedere se il contenuto "nascosto" (quello che viene mostrato quando fai clic su una fisarmonica) è nell'HTML.
In caso contrario, significa che Googlebot e altri crawler non vedono questo contenuto nella versione visualizzata della pagina.
Problema 3: le sezioni di un sito non vengono sottoposte a scansione
Google può visualizzare o meno la tua pagina se la scansiona e la invia alla coda. Se non esegue la scansione della pagina, anche quell'opportunità è fuori discussione.
Per capire se Google sta eseguendo la scansione delle pagine, può tornare utile il rapporto Statistiche di scansione Impostazioni > Statistiche di scansione .
Selezionare Richieste di scansione: OK (200) per visualizzare tutte le istanze di scansione di 200 pagine di stato negli ultimi tre mesi. Quindi, utilizza i filtri per cercare singoli URL o intere directory.
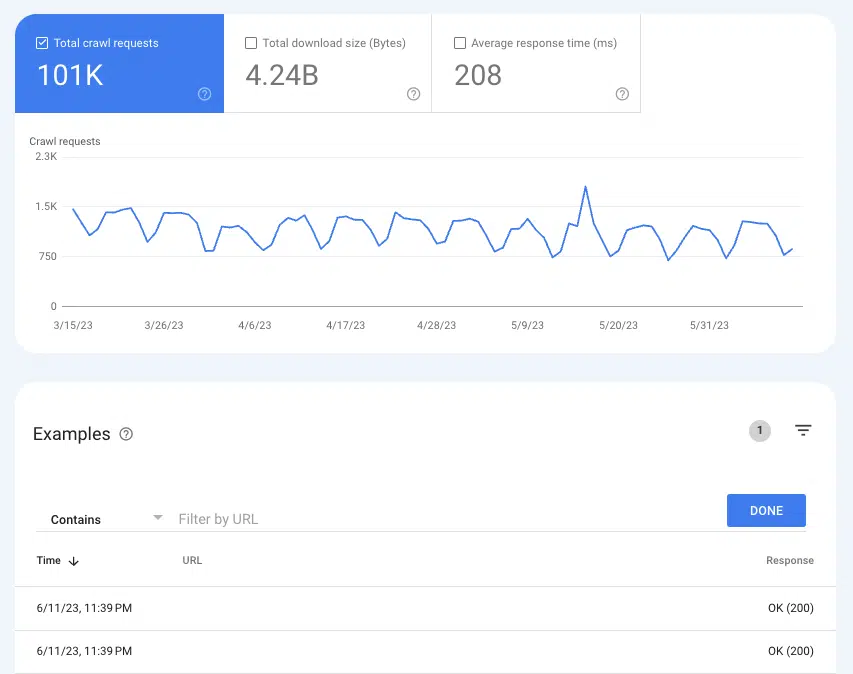
Se gli URL non vengono visualizzati nei registri di scansione, c'è una buona probabilità che Google non sia in grado di scoprire le pagine e scansionarle (o non sono 200 pagine, il che è un problema completamente diverso).
Cause comuni
I link interni non sono scansionabili
I collegamenti sono i segnali stradali che i crawler seguono verso nuove pagine. Questo è uno dei motivi per cui le pagine orfane sono un grosso problema.
Se disponi di un sito ben collegato e visualizzi pagine orfane nei controlli del tuo sito, è probabile che i collegamenti non siano disponibili nell'HTML pre-renderizzato.
Un modo semplice per controllare è andare a un URL che si collega alla pagina orfana segnalata. Fai clic con il pulsante destro del mouse sulla pagina e fai clic su "Visualizza sorgente".
Quindi, usa CMD + f per cercare l'URL della pagina orfana. Se non viene visualizzato nell'HTML pre-renderizzato ma viene visualizzato sulla pagina durante il rendering nel browser, vai al numero quattro.
Mappa del sito XML non aggiornata
La sitemap XML è fondamentale per aiutare Google a scoprire nuove pagine e capire a quali URL dare la priorità in una scansione.
Senza la mappa del sito XML, la scoperta della pagina è possibile solo seguendo i collegamenti.
Quindi, per i siti senza HTML pre-renderizzato, una mappa del sito obsoleta o mancante significa attendere che Google esegua il rendering delle pagine, segua i collegamenti interni ad altre pagine, le accodi, le visualizzi, ne segua i collegamenti e così via.
A seconda del front-end che stai utilizzando, potresti avere accesso a plug-in in grado di creare sitemap XML dinamiche.
Spesso hanno bisogno di personalizzazione, quindi è importante che i SEO documentino diligentemente tutti gli URL che non dovrebbero essere nella mappa del sito e la logica del perché.
Questo dovrebbe essere relativamente facile da verificare eseguendo la mappa del sito attraverso il tuo strumento SEO preferito.
Problema 4: mancano collegamenti interni
L'indisponibilità di collegamenti interni ai crawler non è solo un potenziale problema di scoperta, è anche un problema di equità. Poiché i collegamenti trasmettono l'equità SEO dall'URL di riferimento all'URL di destinazione, sono un fattore importante per aumentare l'autorità sia della pagina che del dominio.
I collegamenti dalla home page sono un ottimo esempio. In genere è la pagina più autorevole di un sito Web, quindi un collegamento a un'altra pagina dalla home page ha molto peso.
Se questi collegamenti non sono scansionabili, è un po' come avere una spada laser rotta. Uno dei tuoi strumenti più potenti è reso inutile (gioco di parole).
Cause comuni
Interazione dell'utente richiesta per accedere al collegamento
L'esempio della fisarmonica che abbiamo usato in precedenza è solo un'istanza in cui il contenuto è nascosto dietro un'interazione dell'utente. Un altro che può avere implicazioni diffuse è l'impaginazione a scorrimento infinito, in particolare per i siti di e-commerce con cataloghi sostanziali di prodotti.
In una configurazione a scorrimento infinito, innumerevoli prodotti su una pagina di elenco di prodotti (categoria) non verranno caricati a meno che un utente non scorra oltre un certo punto (caricamento lento) o tocchi il pulsante "mostra altro".
Pertanto, anche se viene eseguito il rendering del codice JavaScript, un crawler non può accedere ai collegamenti interni per i prodotti ancora da caricare. Tuttavia, il caricamento di tutti questi prodotti su una pagina avrebbe un impatto negativo sull'esperienza dell'utente a causa delle scarse prestazioni della pagina.
Questo è il motivo per cui i SEO generalmente preferiscono la vera paginazione in cui ogni pagina dei risultati ha un URL distinto e scansionabile.
Sebbene esistano modi in cui un sito può ottimizzare il caricamento lento e aggiungere tutti i prodotti all'HTML pre-renderizzato, ciò comporterebbe differenze tra l'HTML sottoposto a rendering e l'HTML pre-renderizzato.
In effetti, questo crea un motivo per inviare più pagine alla coda di rendering e costringere i crawler a lavorare più duramente del necessario, e sappiamo che non è eccezionale per la SEO.
Come minimo, segui i consigli di Google per ottimizzare lo scorrimento infinito.
Collegamenti non codificati correttamente
Quando Google esegue la scansione di un sito o esegue il rendering di un URL nella coda, sta scaricando una versione stateless di una pagina. Questa è una parte importante del motivo per cui è così importante utilizzare tag e ancore href appropriati (la struttura di collegamento che vedi più spesso). Un crawler non può seguire formati di collegamento come router, span o onClick.
Può seguire:
- <a href="https://example.com">
- <a href="/relative/path/file">
Non posso seguire:
- <a routerLink="some/path">
- <span href="https://example.com">
- <a>
Per gli scopi di uno sviluppatore, questi sono tutti modi validi per codificare i collegamenti. Le implicazioni SEO sono un ulteriore livello di contesto, e non è compito loro saperlo: è compito dei SEO.
Una parte enorme del lavoro di un buon SEO è fornire agli sviluppatori quel contesto attraverso la documentazione.
Problema 5: mancano i metadati
In una pagina HTML, i metadati come il titolo, la descrizione, l'URL canonico e il tag meta robots sono tutti nidificati nella testa.
Per ovvi motivi, la mancanza di metadati è dannosa per la SEO, ma ancora di più per le SPA. Elementi come un URL canonico autoreferenziale sono fondamentali per migliorare le possibilità che una pagina JS superi correttamente la coda di rendering.
Di tutti gli elementi che dovrebbero essere presenti nell'HTML pre-renderizzato, l'head è il più importante per l'indicizzazione.
Fortunatamente, questo problema è abbastanza facile da rilevare, perché attiverà un'abbondanza di errori per i metadati mancanti in qualsiasi strumento SEO utilizzato da un sito per i rapporti sull'igiene. Quindi, puoi confermare cercando la testa nel codice sorgente.
Cause comuni
Veicolo di metadati mancante o configurato in modo errato
In un framework JS, un plugin crea la testa e inserisce i metadati nella testa. (L'esempio più popolare è React Helmet.) Anche se un plug-in è già installato, di solito deve essere configurato correttamente.
Ancora una volta, questa è un'area in cui tutto ciò che i SEO possono fare è portare il problema allo sviluppatore, spiegare il perché e lavorare a stretto contatto verso criteri di accettazione ben documentati.
Problema 6: le risorse non vengono sottoposte a scansione
I file di script e le immagini sono elementi costitutivi essenziali nel processo di rendering.
Poiché hanno anche i propri URL, anche a loro si applicano le leggi sulla crawlability. Se la scansione dei file è bloccata, Google non può analizzare la pagina per renderla.
Per verificare se gli URL vengono sottoposti a scansione, puoi visualizzare le richieste precedenti in Statistiche di scansione di GSC.
- Immagini: vai su Impostazioni > Statistiche di scansione > Richieste di scansione: immagine
- JavaScript: vai su Impostazioni > Statistiche di scansione > Richieste di scansione: immagine
Cause comuni
Directory bloccata da robots.txt
Sia gli URL degli script che quelli delle immagini generalmente si annidano nel proprio sottodominio o sottocartella dedicati, quindi un'espressione non consentita nel file robots.txt impedirà la scansione.
Alcuni strumenti SEO ti diranno se qualche file di script o immagine è bloccato, ma il problema è abbastanza facile da individuare se sai dove sono nidificate le tue immagini e i file di script. Puoi cercare quelle strutture URL in robots.txt.
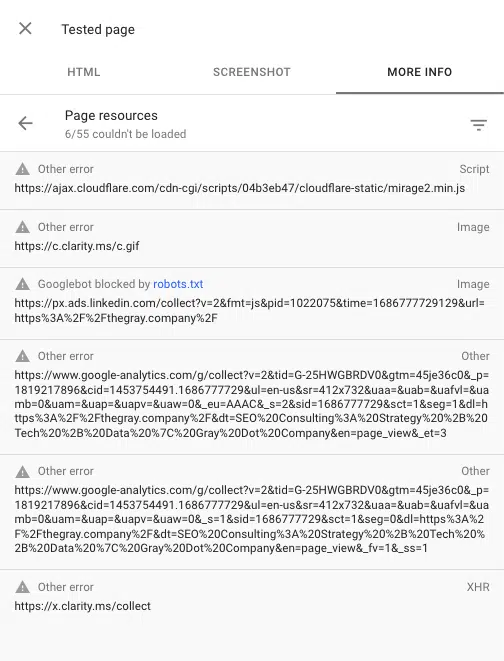
Puoi anche vedere eventuali script bloccati durante il rendering di una pagina utilizzando lo strumento di ispezione degli URL in Google Search Console. "Test Live URL", quindi vai a Visualizza pagina testata > Ulteriori informazioni > Risorse della pagina .
Qui puoi vedere tutti gli script che non riescono a caricarsi durante il processo di rendering. Se un file è bloccato da robots.txt, verrà contrassegnato come tale.
Fai amicizia con JavaScript
Sì, JavaScript può presentare alcuni problemi SEO. Ma con l'evolversi della SEO, le best practice stanno diventando sinonimo di un'ottima esperienza utente.
Un'ottima esperienza utente spesso dipende da JavaScript. Quindi, mentre il lavoro di un SEO non è quello di codificare JavaScript, abbiamo bisogno di sapere come i motori di ricerca interagiscono, lo visualizzano e lo usano.
Con una solida conoscenza del processo di rendering e di alcuni problemi SEO comuni nei framework JS, sei sulla buona strada per identificare i problemi e diventare un potente alleato per i tuoi sviluppatori.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.