
Entity SEO: la guida definitiva
Pubblicato: 2023-04-06Questo articolo è stato co-autore di Andrew Ansley .
Cose, non stringhe. Se non l'hai mai sentito prima, viene da un famoso post sul blog di Google che ha annunciato il Knowledge Graph.
Manca solo un mese all'11° anniversario dell'annuncio, eppure molti fanno ancora fatica a capire cosa significhi davvero "cose, non stringhe" per la SEO.
La citazione è un tentativo di comunicare che Google capisce le cose e non è più un semplice algoritmo di rilevamento delle parole chiave.
Nel maggio 2012, si potrebbe sostenere che sia nata l'entità SEO. L'apprendimento automatico di Google, aiutato da basi di conoscenza semi-strutturate e strutturate, potrebbe comprendere il significato di una parola chiave.
La natura ambigua del linguaggio ha finalmente trovato una soluzione a lungo termine.
Quindi, se le entità sono importanti per Google da oltre un decennio, perché i SEO sono ancora confusi riguardo alle entità?
Buona domanda. Vedo quattro ragioni:
- Entity SEO come termine non è stato usato abbastanza ampiamente perché i SEO si sentissero a proprio agio con la sua definizione e quindi la incorporassero nel loro vocabolario.
- L'ottimizzazione per le entità si sovrappone notevolmente ai vecchi metodi di ottimizzazione incentrati sulle parole chiave. Di conseguenza, le entità vengono confuse con le parole chiave. Inoltre, non era chiaro in che modo le entità avessero un ruolo nella SEO e la parola "entità" a volte è intercambiabile con "argomenti" quando Google parla dell'argomento.
- Comprendere le entità è un compito noioso. Se desideri una conoscenza approfondita delle entità, dovrai leggere alcuni brevetti di Google e conoscere le basi dell'apprendimento automatico. Entity SEO è un approccio molto più scientifico alla SEO e la scienza non è per tutti.
- Sebbene YouTube abbia avuto un impatto enorme sulla distribuzione della conoscenza, ha appiattito l'esperienza di apprendimento per molte materie. I creatori di maggior successo sulla piattaforma hanno storicamente scelto la strada più facile per educare il loro pubblico. Di conseguenza, i creatori di contenuti non hanno dedicato molto tempo alle entità fino a poco tempo fa. Per questo motivo, è necessario conoscere le entità dai ricercatori della PNL e quindi è necessario applicare la conoscenza alla SEO. Brevetti e documenti di ricerca sono fondamentali. Ancora una volta, questo rafforza il primo punto sopra.
Questo articolo è una soluzione a tutti e quattro i problemi che hanno impedito ai SEO di padroneggiare completamente un approccio SEO basato sull'entità.
Leggendo questo, imparerai:
- Cos'è un'entità e perché è importante.
- La storia della ricerca semantica.
- Come identificare e utilizzare le entità nella SERP.
- Come utilizzare le entità per classificare i contenuti web.
Perché le entità sono importanti?
Entity SEO è il futuro di dove sono diretti i motori di ricerca per quanto riguarda la scelta del contenuto da classificare e determinarne il significato.
Combina questo con la fiducia basata sulla conoscenza e credo che la SEO di entità sarà il futuro di come verrà eseguita la SEO nei prossimi due anni.
Esempi di entità
Allora come si riconosce un'entità?
La SERP ha diversi esempi di entità che probabilmente hai visto.
I tipi più comuni di entità sono correlati a luoghi, persone o aziende.
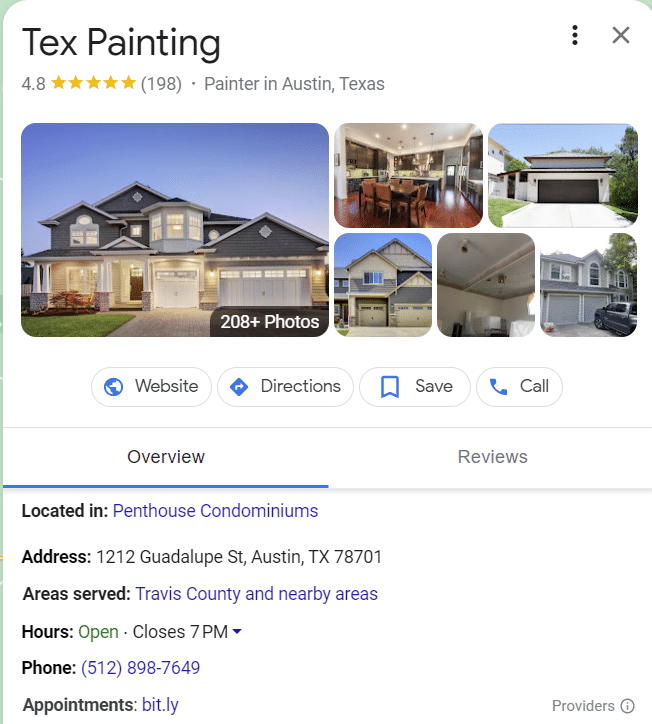
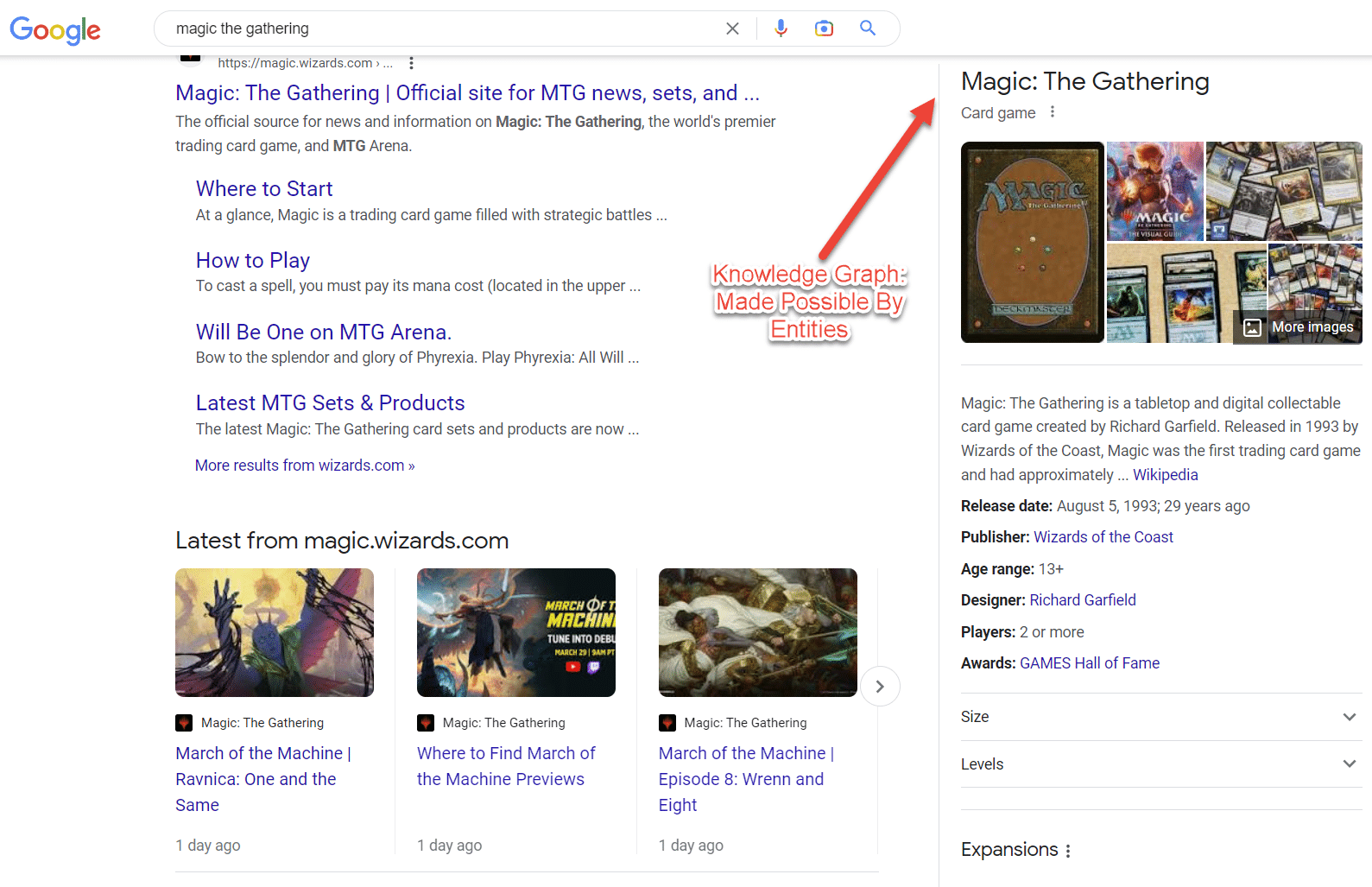
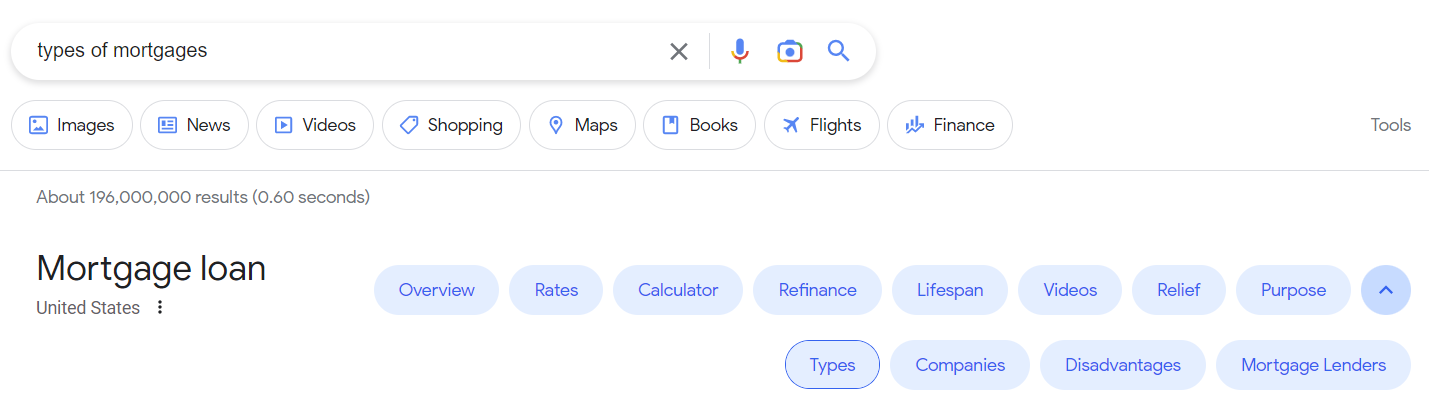
Forse il miglior esempio di entità nella SERP sono i cluster di intenti. Più un argomento viene compreso, più queste caratteristiche di ricerca emergono.
È interessante notare che una singola campagna SEO può alterare il volto della SERP quando sai come eseguire campagne SEO incentrate sull'entità.
Le voci di Wikipedia sono un altro esempio di entità. Wikipedia fornisce un ottimo esempio di informazioni associate alle entità.
Come puoi vedere dall'alto a sinistra, l'entità ha tutti i tipi di attributi associati al "pesce", che vanno dalla sua anatomia alla sua importanza per gli umani.
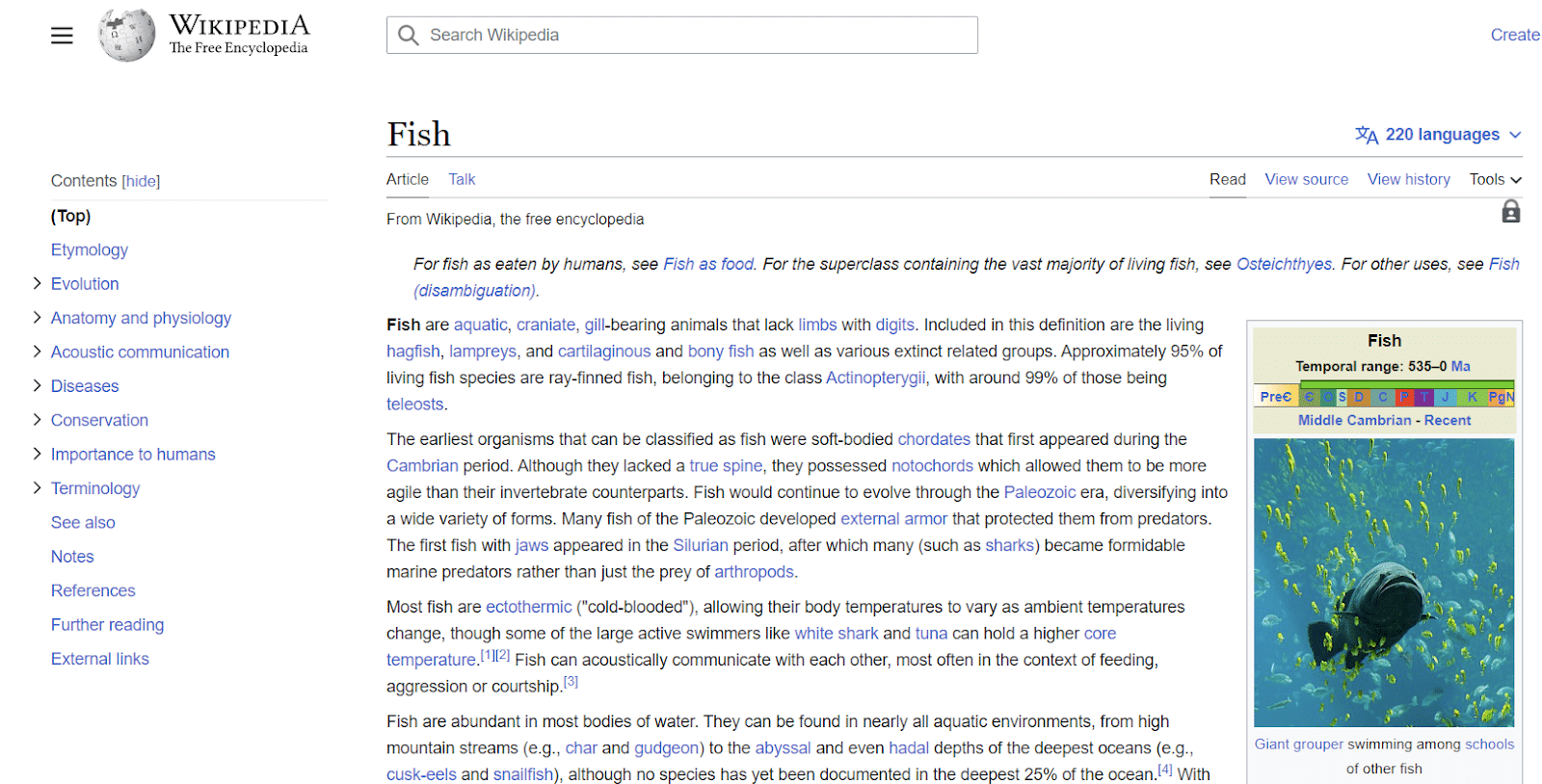
Sebbene Wikipedia contenga molti punti dati su un argomento, non è affatto esaustiva.
Cos'è un'entità?
Un'entità è un oggetto o una cosa identificabile in modo univoco caratterizzato da nome/i, tipo/i, attributi e relazioni con altre entità. Un'entità viene considerata esistente solo quando esiste in un catalogo di entità.
I cataloghi di entità assegnano un ID univoco a ciascuna entità. La mia agenzia dispone di soluzioni programmatiche che utilizzano l'ID univoco associato a ciascuna entità (servizi, prodotti e marchi sono tutti inclusi).
Se una parola o una frase non è all'interno di un catalogo esistente, non significa che la parola o la frase non sia un'entità, ma in genere puoi sapere se qualcosa è un'entità dalla sua esistenza nel catalogo.
È importante notare che Wikipedia non è il fattore decisivo sul fatto che qualcosa sia un'entità, ma la società è più nota per il suo database di entità.
Qualsiasi catalogo può essere utilizzato quando si parla di entità. In genere, un'entità è una persona, un luogo o una cosa, ma possono essere inclusi anche idee e concetti.
Alcuni esempi di cataloghi di entità includono:
- Wikipedia
- Wikidati
- DBpedia
- Base libera
- Jago

Le entità aiutano a colmare il divario tra il mondo dei dati strutturati e non strutturati.
Possono essere utilizzati per arricchire semanticamente il testo non strutturato, mentre le fonti testuali possono essere utilizzate per popolare basi di conoscenza strutturate.
Riconoscere le menzioni di entità nel testo e associare queste menzioni alle voci corrispondenti in una base di conoscenza è noto come attività di collegamento di entità.
Le entità consentono una migliore comprensione del significato del testo, sia per gli esseri umani che per le macchine.
Mentre gli esseri umani possono risolvere in modo relativamente semplice l'ambiguità delle entità in base al contesto in cui sono menzionate, ciò presenta molte difficoltà e sfide per le macchine.
La voce della base di conoscenza di un'entità riassume ciò che sappiamo su tale entità.
Poiché il mondo è in continua evoluzione, emergono anche nuovi fatti. Stare al passo con questi cambiamenti richiede uno sforzo continuo da parte di editori e gestori di contenuti. Questo è un compito impegnativo su larga scala.
Analizzando il contenuto dei documenti in cui sono menzionate entità, il processo di ricerca di nuovi fatti o fatti che necessitano di aggiornamento può essere supportato o addirittura completamente automatizzato.
Gli scienziati si riferiscono a questo come al problema della popolazione della base di conoscenza, motivo per cui il collegamento delle entità è importante.
Le entità facilitano una comprensione semantica del bisogno di informazioni dell'utente, come espresso dalla query con parole chiave, e del contenuto del documento. Le entità possono quindi essere utilizzate per migliorare le rappresentazioni di query e/o documenti.
Nel documento di ricerca Extended Named Entity, l'autore identifica circa 160 tipi di entità. Ecco due dei sette screenshot dall'elenco.


Alcune categorie di entità sono più facilmente definibili, ma è importante ricordare che i concetti e le idee sono entità. Queste due categorie sono molto difficili da scalare per Google da solo.
Non puoi insegnare a Google con una sola pagina quando lavori con concetti vaghi. La comprensione dell'entità richiede molti articoli e molti riferimenti sostenuti nel tempo.
La cronologia di Google con le entità
Il 16 luglio 2010, Google ha acquistato Freebase. Questo acquisto è stato il primo passo importante che ha portato all'attuale sistema di ricerca di entità.

Dopo aver investito in Freebase, Google ha capito che Wikidata aveva una soluzione migliore. Google ha quindi lavorato per fondere Freebase in Wikidata, un compito molto più difficile del previsto.
Cinque scienziati di Google hanno scritto un documento intitolato "Da Freebase a Wikidata: la grande migrazione". I punti chiave includono.
“Freebase si basa sulle nozioni di oggetti, fatti, tipi e proprietà. Ogni oggetto Freebase ha un identificatore stabile chiamato "mid" (per Machine ID)."
“Il modello di dati di Wikidata si basa sulle nozioni di item e statement. Un elemento rappresenta un'entità, ha un identificatore stabile chiamato "qid" e può avere etichette, descrizioni e alias in più lingue; ulteriori dichiarazioni e collegamenti a pagine sull'entità in altri progetti Wikimedia, in particolare Wikipedia. Contrariamente a Freebase, le dichiarazioni di Wikidata non mirano a codificare fatti veri, ma affermazioni provenienti da fonti diverse, che possono anche contraddirsi a vicenda…”
Le entità sono definite in queste basi di conoscenza, ma Google doveva ancora costruire la sua conoscenza delle entità per i dati non strutturati (ad esempio, i blog).
Google ha collaborato con Bing e Yahoo e ha creato Schema.org per svolgere questo compito.
Google fornisce indicazioni sullo schema in modo che i gestori dei siti web possano disporre di strumenti che aiutano Google a comprendere i contenuti. Ricorda, Google vuole concentrarsi sulle cose, non sulle stringhe.
Nelle parole di Google:
“Puoi aiutarci fornendo a Google indizi espliciti sul significato di una pagina includendo dati strutturati nella pagina. I dati strutturati sono un formato standardizzato per fornire informazioni su una pagina e classificare il contenuto della pagina; ad esempio, nella pagina di una ricetta, quali sono gli ingredienti, il tempo e la temperatura di cottura, le calorie e così via”.
Google continua dicendo:
"Devi includere tutte le proprietà richieste affinché un oggetto possa essere visualizzato nella Ricerca Google con visualizzazione avanzata. In generale, la definizione di più funzionalità consigliate può aumentare le probabilità che le tue informazioni vengano visualizzate nei risultati di ricerca con visualizzazione migliorata. Tuttavia, è più importante fornire meno proprietà consigliate ma complete e accurate piuttosto che cercare di fornire ogni possibile proprietà consigliata con dati meno completi, mal formati o imprecisi.
Si potrebbe dire di più sullo schema, ma basti dire che lo schema è uno strumento incredibile per i SEO che cercano di rendere il contenuto della pagina chiaro ai motori di ricerca.
L'ultimo pezzo del puzzle arriva dall'annuncio sul blog di Google intitolato "Migliorare la ricerca per i prossimi 20 anni".
Pertinenza e qualità del documento sono le idee principali alla base di questo annuncio. Il primo metodo utilizzato da Google per determinare il contenuto di una pagina era interamente incentrato sulle parole chiave.
Google ha quindi aggiunto livelli di argomenti alla ricerca. Questo livello è stato reso possibile dai grafici della conoscenza e dalla raschiatura e strutturazione sistematica dei dati sul Web.
Questo ci porta all'attuale sistema di ricerca. Google è passato da 570 milioni di entità e 18 miliardi di fatti a 800 miliardi di fatti e 8 miliardi di entità in meno di 10 anni. Con l'aumentare di questo numero, la ricerca di entità migliora.
In che modo il modello di entità rappresenta un miglioramento rispetto ai precedenti modelli di ricerca?
I tradizionali modelli di recupero delle informazioni (IR) basati su parole chiave hanno un limite intrinseco di non essere in grado di recuperare documenti (rilevanti) che non hanno corrispondenze di termini esplicite con la query.
Se usi ctrl + f per trovare il testo in una pagina, usi qualcosa di simile al tradizionale modello di recupero delle informazioni basato su parole chiave.
Ogni giorno sul web viene pubblicata una quantità folle di dati.
Semplicemente non è possibile per Google comprendere il significato di ogni parola, ogni paragrafo, ogni articolo e ogni sito web.
Invece, le entità forniscono una struttura da cui Google può ridurre al minimo il carico computazionale migliorando al contempo la comprensione.
“I metodi di recupero basati su concetti tentano di affrontare questa sfida facendo affidamento su strutture ausiliarie per ottenere rappresentazioni semantiche di query e documenti in uno spazio concettuale di livello superiore. Tali strutture includono vocabolari controllati (dizionari e thesauri), ontologie ed entità da un repository di conoscenza.
– Ricerca orientata all'entità , capitolo 8.3
Krisztian Balog, che ha scritto il libro definitivo sulle entità, identifica tre possibili soluzioni al modello tradizionale di recupero delle informazioni.
- Basato sull'espansione : utilizza le entità come origine per espandere la query con termini diversi.
- Basato sulla proiezione : la rilevanza tra una query e un documento viene compresa proiettandoli su uno spazio latente di entità
- Basato su entità : le rappresentazioni semantiche esplicite di query e documenti vengono ottenute nello spazio delle entità per aumentare le rappresentazioni basate sui termini.
L'obiettivo di questi tre approcci è ottenere una rappresentazione più ricca delle informazioni necessarie all'utente identificando entità fortemente correlate alla query.
Balog identifica quindi sei algoritmi associati a metodi di mappatura di entità basati sulla proiezione (i metodi di proiezione si riferiscono alla conversione di entità in uno spazio tridimensionale e alla misurazione dei vettori utilizzando la geometria).
- Analisi semantica esplicita (ESA) : la semantica di una data parola è descritta da un vettore che memorizza i punti di forza dell'associazione della parola ai concetti derivati da Wikipedia.
- Latent entity space model (LES) : Basato su un framework probabilistico generativo. Il punteggio di recupero del documento è considerato una combinazione lineare del punteggio dello spazio dell'entità latente e del punteggio di verosimiglianza della query originale.
- EsdRank: EsdRank serve per classificare i documenti, utilizzando una combinazione di funzionalità di query-entity e di entità-documento. Questi corrispondono alle nozioni di proiezione di query e componenti di proiezione di documenti di LES, rispettivamente, da prima. Utilizzando un framework di apprendimento discriminante, è possibile incorporare facilmente anche segnali aggiuntivi, come la popolarità dell'entità o la qualità del documento
- Classificazione semantica esplicita (ESR): il modello di classificazione semantica esplicita incorpora le informazioni sulle relazioni da un grafico della conoscenza per consentire la "corrispondenza morbida" nello spazio delle entità.
- Framework di duetti di entità di parole: incorpora interazioni interspaziali tra rappresentazioni basate su termini e rappresentazioni basate su entità, portando a quattro tipi di corrispondenze: termini di query con termini di documento, entità di query con termini di documento, termini di query con entità di documento ed entità di query documentare le entità.
- Modello di classificazione basato sull'attenzione : Questo è di gran lunga il più complicato da descrivere.
Ecco cosa scrive Balog:
“Sono progettate in totale quattro funzionalità di attenzione, che vengono estratte per ciascuna entità di query. Le caratteristiche di ambiguità dell'entità hanno lo scopo di caratterizzare il rischio associato a un'annotazione di entità. Questi sono: (1) l'entropia della probabilità che la forma superficiale sia collegata a entità diverse (ad esempio, in Wikipedia), (2) se l'entità annotata è il senso più popolare della forma superficiale (cioè, ha la più alta comunanza punteggio e (3) la differenza nei punteggi di comunanza tra i candidati più probabili e i secondi candidati più probabili per la forma di superficie data.La quarta caratteristica è la vicinanza, che è definita come la somiglianza del coseno tra l'entità di query e la query in uno spazio di incorporamento ". In particolare, un'incorporamento congiunto entità-termine viene addestrato utilizzando il modello skip-gram su un corpus, in cui le citazioni di entità vengono sostituite con i corrispondenti identificatori di entità. L'incorporamento della query è considerato il centroide degli incorporamenti dei termini della query."

Per ora, è importante avere familiarità a livello superficiale con questi sei algoritmi incentrati sull'entità.
Il punto principale è che esistono due approcci: proiezione di documenti su un livello di entità latente e annotazioni di entità esplicite di documenti.
Tre tipi di strutture dati
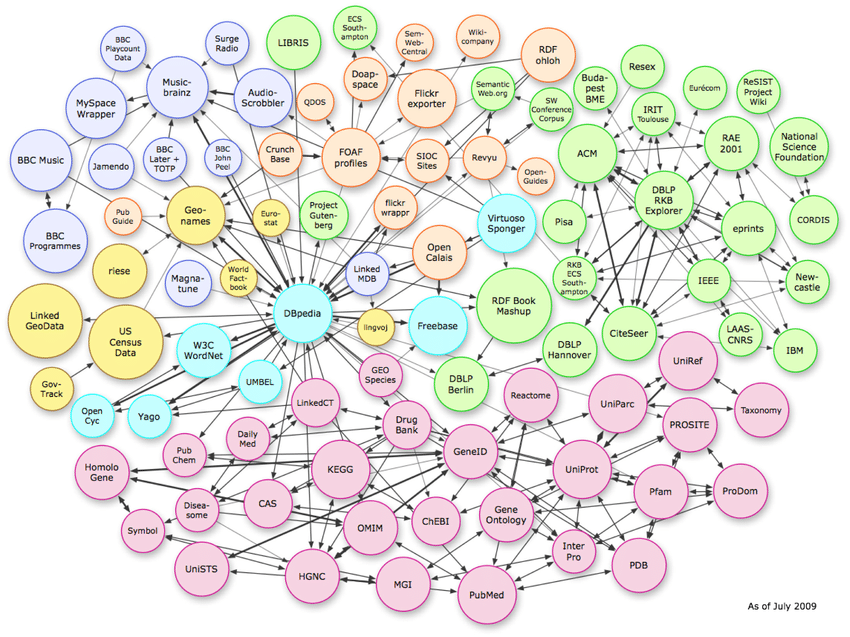
L'immagine sopra mostra le complesse relazioni che esistono nello spazio vettoriale. Sebbene l'esempio mostri le connessioni del grafico della conoscenza, questo stesso modello può essere replicato a livello di schema pagina per pagina.
Per comprendere le entità, è importante conoscere i tre tipi di strutture dati utilizzate dagli algoritmi.
- Utilizzando descrizioni di entità non strutturate , i riferimenti ad altre entità devono essere riconosciuti e disambiguati. I bordi diretti (collegamenti ipertestuali) vengono aggiunti da ciascuna entità a tutte le altre entità menzionate nella sua descrizione.
- In un ambiente semi-strutturato (es. Wikipedia), i collegamenti ad altre entità potrebbero essere esplicitamente forniti.
- Quando si lavora con dati strutturati , le triple RDF definiscono un grafico (cioè il grafo della conoscenza). Nello specifico, le risorse soggetto e oggetto (URI) sono nodi e i predicati sono bordi.
Il problema con un contesto semi-strutturato e fonte di distrazione per il punteggio IR è che se un documento non è configurato per un singolo argomento, il punteggio IR può essere diluito dai due diversi contesti risultando in una posizione relativa persa a favore di un altro documento testuale.
La diluizione del punteggio IR comporta relazioni lessicali scarsamente strutturate e vicinanza di parolacce.
Le parole rilevanti che si completano a vicenda dovrebbero essere usate strettamente all'interno di un paragrafo o di una sezione del documento per segnalare il contesto in modo più chiaro per aumentare il punteggio IR.
L'utilizzo di attributi e relazioni di entità produce miglioramenti relativi nell'intervallo del 5-20%. Lo sfruttamento delle informazioni di tipo entità è ancora più gratificante, con miglioramenti relativi che vanno dal 25% a oltre il 100%.
L'annotazione di documenti con entità può portare una struttura a documenti non strutturati, il che può aiutare a popolare le basi di conoscenza con nuove informazioni sulle entità.
Usando Wikipedia come struttura SEO della tua entità
Struttura delle pagine di Wikipedia
- Titolo (I.)
- Sezione principale (II.)
- Collegamenti di disambiguazione (II.a)
- Infobox (II.b)
- Testo introduttivo (II.c)
- Sommario (III.)
- Contenuto corporeo (IV.)
- Appendici e fondo (V.)
- Riferimenti e note (Va)
- Collegamenti esterni (Vb)
- Categorie (Vc)
La maggior parte degli articoli di Wikipedia include un testo introduttivo, il "lead", un breve riassunto dell'articolo, in genere non più lungo di quattro paragrafi. Questo dovrebbe essere scritto in un modo che crei interesse per l'articolo.
La prima frase e il paragrafo iniziale rivestono particolare importanza. La prima frase "può essere considerata come la definizione dell'entità descritta nell'articolo". Il primo paragrafo offre una definizione più elaborata senza troppi dettagli.
Il valore dei collegamenti va oltre gli scopi di navigazione; catturano le relazioni semantiche tra gli articoli. Inoltre, i testi di ancoraggio sono una ricca fonte di varianti di nomi di entità. I collegamenti di Wikipedia possono essere utilizzati, tra l'altro, per aiutare a identificare e disambiguare le menzioni di entità nel testo.
- Riassumi i fatti chiave sull'entità (infobox).
- Breve introduzione.
- Collegamenti interni. Una regola chiave data agli editor è quella di collegarsi solo alla prima occorrenza di un'entità o di un concetto.
- Includi tutti i sinonimi popolari per un'entità.
- Designazione della pagina della categoria.
- Modello di navigazione.
- Riferimenti.
- Speciali strumenti di analisi per comprendere le pagine Wiki.
- Più tipi di media.
Come ottimizzare per le entità
Di seguito sono riportate le considerazioni chiave per l'ottimizzazione delle entità per la ricerca:
- L'inclusione di parole semanticamente correlate in una pagina.
- Frequenza di parole e frasi su una pagina.
- L'organizzazione dei concetti in una pagina.
- Include dati non strutturati, dati semi-strutturati e dati strutturati in una pagina.
- Coppie soggetto-predicato-oggetto (SPO).
- Documenti Web su un sito che funzionano come pagine di un libro.
- Organizzazione di documenti web su un sito web.
- Includi concetti in un documento Web che sono caratteristiche note delle entità.
Nota importante: quando l'accento è posto sulle relazioni tra entità, una base di conoscenza viene spesso definita grafo di conoscenza.
Poiché l'intento viene analizzato insieme ai registri di ricerca degli utenti e ad altri frammenti di contesto, la stessa frase di ricerca della persona 1 potrebbe generare un risultato diverso dalla persona 2. La persona potrebbe avere un intento diverso con la stessa identica query.
Se la tua pagina copre entrambi i tipi di intenti, allora la tua pagina è un candidato migliore per il ranking web. Puoi utilizzare la struttura delle basi di conoscenza per guidare i tuoi modelli di intento di query (come menzionato in una sezione precedente).
Le persone chiedono anche, le persone cercano e il completamento automatico sono semanticamente correlate alla query inviata e si immergono più in profondità nella direzione di ricerca corrente o si spostano su un aspetto diverso dell'attività di ricerca.
Lo sappiamo, quindi come possiamo ottimizzarlo?
I tuoi documenti dovrebbero contenere il maggior numero possibile di varianti dell'intento di ricerca. Il tuo sito web dovrebbe contenere ogni variazione dell'intento di ricerca per il tuo cluster. Il clustering si basa su tre tipi di somiglianza:
- Somiglianza lessicale.
- Somiglianza semantica.
- Fare clic su somiglianza.
Copertura dell'argomento
Che cos'è –> Elenco degli attributi –> Sezione dedicata a ciascun attributo –> Ogni sezione si collega a un articolo completamente dedicato a quell'argomento –> Dovrebbe essere specificato il pubblico e dovrebbero essere specificate le definizioni per la sottosezione –> Cosa dovrebbe essere considerato ? –> Quali sono i vantaggi? –> Vantaggi del modificatore –> Cos'è ___ –> Cosa fa? –> Come ottenerlo –> Come farlo –> Chi può farlo –> Link a tutte le categorie

Google offre uno strumento che fornisce un punteggio di salienza (simile a come usiamo la parola "forza" o "fiducia") che ti dice come Google vede il contenuto.

L'esempio sopra viene da un articolo di Search Engine Land sulle entità del 2018.
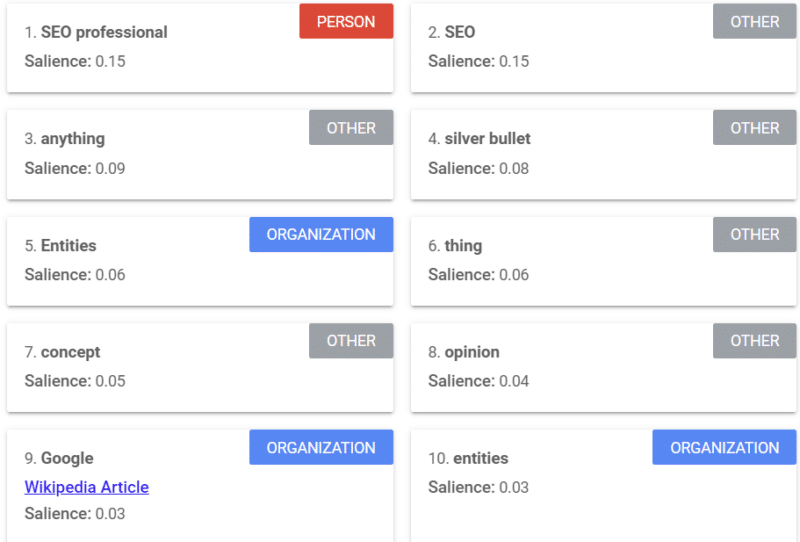
Puoi vedere persona, altro e organizzazioni dall'esempio. Lo strumento è l'API Natural Language di Google Cloud.
Ogni parola, frase e paragrafo è importante quando si parla di un'entità. Il modo in cui organizzi i tuoi pensieri può cambiare la comprensione dei tuoi contenuti da parte di Google.
Puoi includere una parola chiave sulla SEO, ma Google capisce quella parola chiave nel modo in cui vuoi che sia compresa?
Prova a inserire uno o due paragrafi nello strumento e a riorganizzare e modificare l'esempio per vedere come aumenta o diminuisce la rilevanza.
Questo esercizio, chiamato "disambiguazione", è incredibilmente importante per le entità. La lingua è ambigua, quindi dobbiamo rendere le nostre parole meno ambigue per Google.
I moderni approcci di disambiguazione considerano tre tipi di prove:
Importanza prioritaria di entità e menzioni.
Somiglianza contestuale tra il testo che circonda la menzione e l'entità candidata e coerenza tra tutte le decisioni di collegamento di entità nel documento.
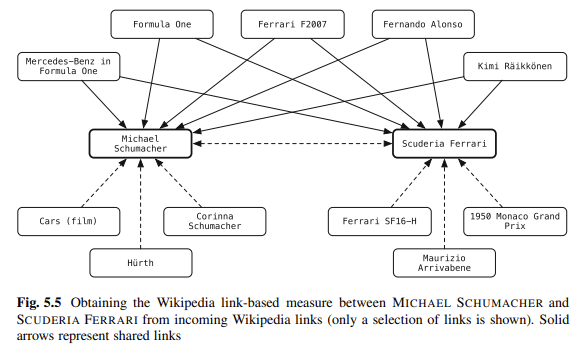
Lo schema è uno dei miei modi preferiti per disambiguare i contenuti. Stai collegando le entità nel tuo blog ai repository di conoscenza. Balog dice:
"[L]inking entità in testo non strutturato in un repository di conoscenza strutturato può potenziare notevolmente gli utenti nelle loro attività di consumo di informazioni."
Ad esempio, i lettori di un documento possono acquisire informazioni contestuali o di background con un solo clic e possono accedere facilmente alle entità correlate.
Le annotazioni di entità possono essere utilizzate anche nell'elaborazione a valle per migliorare le prestazioni di recupero o per facilitare una migliore interazione dell'utente con i risultati della ricerca.
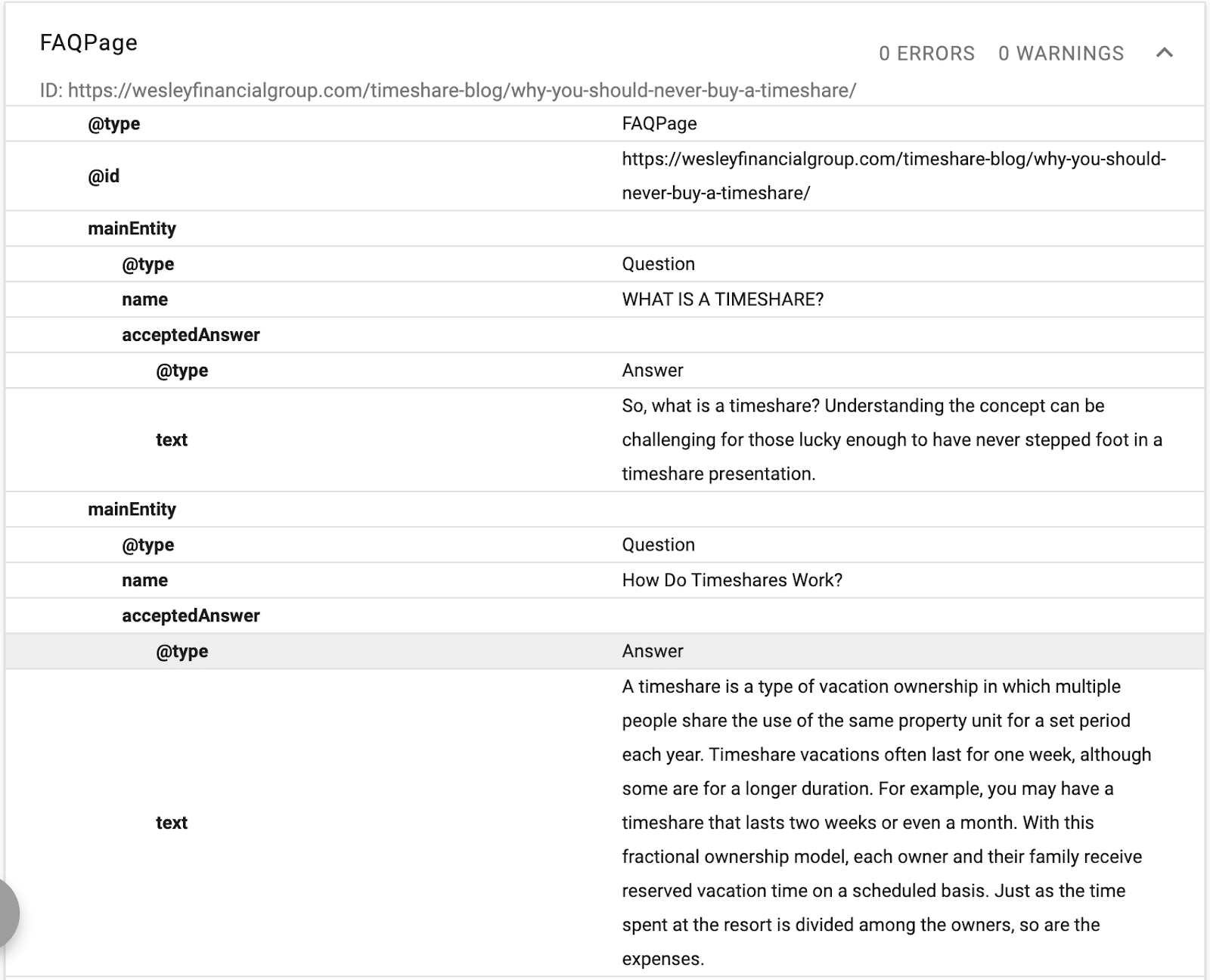
Qui puoi vedere che il contenuto delle FAQ è strutturato per Google utilizzando lo schema delle FAQ.
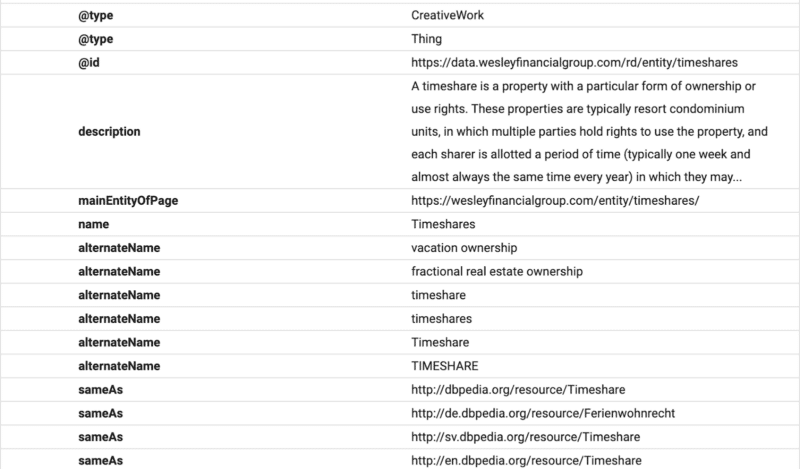
In questo esempio, puoi vedere lo schema che fornisce una descrizione del testo, un ID e una dichiarazione dell'entità principale della pagina.
(Ricorda, Google vuole capire la gerarchia del contenuto, motivo per cui H1-H6 è importante.)
Vedrai nomi alternativi e lo stesso delle dichiarazioni. Ora, quando Google leggerà il contenuto, saprà quale database strutturato associare al testo, e avrà sinonimi e versioni alternative di una parola legata all'entità.
Quando ottimizzi con lo schema, ottimizzi per NER (riconoscimento di entità denominate), noto anche come identificazione di entità, estrazione di entità e suddivisione in blocchi di entità.
L'idea è di impegnarsi in Named Entity Disambiguation > Wikiification > Entity Linking.
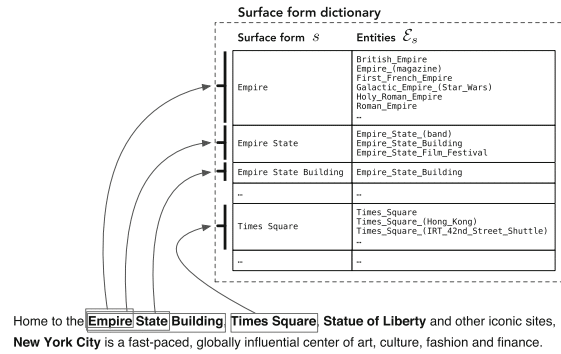
"L'avvento di Wikipedia ha facilitato il riconoscimento e la disambiguazione di entità su larga scala fornendo un catalogo completo di entità insieme ad altre risorse inestimabili (in particolare, collegamenti ipertestuali, categorie e pagine di reindirizzamento e disambiguazione".
– Ricerca orientata all'entità
Come andare oltre i suggerimenti degli strumenti SEO
La maggior parte dei SEO utilizza uno strumento on-page per ottimizzare i propri contenuti. Ogni strumento è limitato nella sua capacità di identificare opportunità di contenuto uniche e suggerimenti di profondità del contenuto.
Per la maggior parte, gli strumenti on-page si limitano ad aggregare i migliori risultati SERP e creare una media da emulare.
I SEO devono ricordare che Google non sta cercando le stesse informazioni rimaneggiate. Puoi copiare ciò che fanno gli altri, ma le informazioni uniche sono la chiave per diventare un sito seme/sito di autorità.
Ecco una descrizione semplificata di come Google gestisce i nuovi contenuti:
Una volta trovato un documento che menziona una data entità, quel documento può essere controllato per eventualmente scoprire nuovi fatti con i quali la voce della base di conoscenza di quell'entità può essere aggiornata.
Balog scrive:
"Desideriamo aiutare gli editori a rimanere aggiornati sui cambiamenti identificando automaticamente i contenuti (articoli di notizie, post di blog, ecc.) che potrebbero implicare modifiche alle voci KB di un determinato insieme di entità di interesse (ovvero entità che un determinato editor è responsabile di)."
Chiunque migliori le basi di conoscenza, il riconoscimento delle entità e la possibilità di scansione delle informazioni otterrà l'amore di Google.
Le modifiche apportate all'archivio delle conoscenze possono essere ricondotte al documento come fonte originale.
Se fornisci contenuti che trattano l'argomento e aggiungi un livello di approfondimento raro o nuovo, Google può identificare se il tuo documento ha aggiunto informazioni univoche.
Alla fine, queste nuove informazioni sostenute per un periodo di tempo potrebbero portare il tuo sito web a diventare un'autorità.
Questa non è un'autorevolezza basata sulla valutazione del dominio, ma sulla copertura dell'attualità, che credo sia molto più preziosa.
Con l'approccio dell'entità alla SEO, non sei limitato a indirizzare le parole chiave con il volume di ricerca.
Tutto quello che devi fare è convalidare il termine principale ("canne da pesca a mosca", ad esempio), quindi puoi concentrarti sul targeting delle variazioni dell'intento di ricerca basate sul buon pensiero umano di vecchia moda.
Cominciamo da Wikipedia. Per l'esempio della pesca a mosca, possiamo vedere che, come minimo, i seguenti concetti dovrebbero essere coperti su un sito web di pesca:
- Specie ittiche, storia, origini, sviluppo, miglioramenti tecnologici, espansione, metodi di pesca a mosca, casting, spey casting, pesca a mosca alla trota, tecniche per la pesca a mosca, pesca in acqua fredda, pesca alla trota a mosca secca, ninfa alla trota, acqua ferma pesca alla trota, riproduzione di trote, rilascio di trote, pesca a mosca in acqua salata, attrezzatura, mosche artificiali e nodi.
Gli argomenti di cui sopra provengono dalla pagina di Wikipedia sulla pesca a mosca. Sebbene questa pagina fornisca un'ottima panoramica degli argomenti, mi piace aggiungere ulteriori idee per argomenti che provengono da argomenti semanticamente correlati.
Per l'argomento "pesce", possiamo aggiungere diversi argomenti aggiuntivi, tra cui etimologia, evoluzione, anatomia e fisiologia, comunicazione dei pesci, malattie dei pesci, conservazione e importanza per l'uomo.
Qualcuno ha collegato l'anatomia della trota all'efficacia di certe tecniche di pesca?
Un unico sito Web di pesca ha coperto tutte le varietà di pesci collegando i tipi di tecniche di pesca, canne ed esche a ciascun pesce?
Ormai dovresti essere in grado di vedere come può crescere l'espansione dell'argomento. Tienilo a mente quando pianifichi una campagna di contenuti.
Non limitarti a ripassare. Aggiungere valore. Essere unico. Usa gli algoritmi menzionati in questo articolo come guida.
Conclusione
Questo articolo fa parte di una serie di articoli incentrati sulle entità. Nel prossimo articolo, approfondirò gli sforzi di ottimizzazione relativi alle entità e ad alcuni strumenti incentrati sulle entità sul mercato.
Voglio concludere questo articolo ringraziando due persone che mi hanno spiegato molti di questi concetti.
Bill Slawski di SEO by the Sea e Koray Tugbert di Holistic SEO. Anche se Slawski non è più con noi, i suoi contributi continuano ad avere un effetto a catena nel settore SEO.
Faccio molto affidamento sulle seguenti fonti per il contenuto dell'articolo, poiché queste fonti sono le migliori risorse esistenti sull'argomento:
- Gerarchia estesa delle entità nominate di Satoshi Ketine, Kiyoshi Sudo e Chikashi Nobata
- Ricerca orientata all'entità di Krisztian Balog , Information Retrieval Series (INRE, volume 39)
- Riscrittura delle query con rilevamento delle entità , brevetto di Google
- Perfezionamento delle query di ricerca , Brevetto di Google
- Associazione di un'entità a una query di ricerca , brevetto di Google
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.