
In che modo Apache Spark può dare le ali all'analisi delle compagnie aeree?
Pubblicato: 2015-10-30L'industria aerea globale continua a crescere rapidamente, ma una redditività solida e costante deve ancora essere vista. Secondo l'International Air Transport Association (IATA), l'industria ha raddoppiato le sue entrate negli ultimi dieci anni, da 369 miliardi di dollari nel 2005 a 727 miliardi di dollari previsti nel 2015.

Nel settore dell'aviazione commerciale, ogni attore della catena del valore: aeroporti, produttori di aeroplani, produttori di motori a reazione, agenti di viaggio e società di servizi realizza un discreto profitto.
Tutti questi giocatori generano individualmente volumi estremamente elevati di dati a causa della maggiore abbandono delle transazioni di volo. Identificare e catturare la domanda è la chiave qui che offre opportunità molto maggiori per le compagnie aeree di differenziarsi. Pertanto, le industrie aeronautiche possono utilizzare le informazioni sui big data per aumentare le vendite e migliorare il margine di profitto.
Big data è un termine per la raccolta di insiemi di dati così grandi e complessi che la loro elaborazione non può essere gestita dai tradizionali sistemi di elaborazione dati o dagli strumenti DBMS disponibili.
Apache Spark è un framework di cluster computing distribuito open source progettato specificamente per query interattive e algoritmi iterativi.
L'astrazione Spark DataFrame è un oggetto dati tabulare simile al frame di dati nativo di R o al pacchetto panda Pythons, ma archiviato nell'ambiente del cluster.
Secondo l'ultimo sondaggio di Fortunes, Apache Spark è la tecnologia più popolare del 2015.
Il più grande fornitore di Hadoop, Cloudera, sta anche dicendo addio a Hadoops MapReduce e Hello to Spark.
Ciò che dà a Spark un vantaggio su Hadoop è la velocità . Spark gestisce la maggior parte delle sue operazioni in memoria , copiandole dall'archiviazione fisica distribuita in una memoria RAM logica molto più veloce. Ciò riduce la quantità di tempo impiegato per la scrittura e la lettura da e verso dischi rigidi meccanici lenti e goffi che devono essere eseguiti con il sistema Hadoops MapReduce.
Inoltre, Spark include strumenti (elaborazione in tempo reale, apprendimento automatico e SQL interattivo) che sono ben realizzati per potenziare obiettivi aziendali come l'analisi dei dati in tempo reale combinando i dati storici dei dispositivi connessi, noti anche come Internet delle cose .
Oggi, raccogliamo alcune informazioni dettagliate sui dati aeroportuali di esempio utilizzando Apache Spark .
Nel blog precedente abbiamo visto come gestire i dati strutturati e semi-strutturati in Spark utilizzando la nuova API Dataframes e abbiamo anche spiegato come elaborare i dati JSON in modo efficiente.
In questo blog capiremo come interrogare i dati in DataFrames usando SQL e come salvare l'output nel filesystem in formato CSV.
Utilizzo della libreria di analisi CSV di Databricks
Per questo utilizzerò una libreria di analisi CSV fornita da Databricks , una società fondata dai creatori di Apache Spark e che attualmente gestisce lo sviluppo e le distribuzioni di Spark.
La comunità Spark è composta da circa 600 contributori che lo rendono il progetto più attivo dell'intera Apache Software Foundation, un importante organo di governo del software open source, in termini di numero di contributori.
La libreria Spark-csv ci aiuta ad analizzare e interrogare i dati CSV nella scintilla. Possiamo usare questa libreria sia per leggere che per scrivere dati CSV da e verso qualsiasi filesystem compatibile con Hadoop.
Caricamento dei dati in Spark DataFrames
Consente di caricare i nostri file di input in Spark DataFrames usando la libreria di analisi spark-csv di Databricks.
Puoi usare questa libreria nella shell Spark specificando –packages com.databricks: spark-csv_2.10:1.0.3
Durante l'avvio della shell come mostrato di seguito:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
Ricorda che dovresti essere connesso a Internet, perché il pacchetto spark-csv verrà scaricato automaticamente quando dai questo comando. Sto usando la versione Spark 1.4.0
Creiamo sqlContext con l'oggetto SparkContext(sc) già creato
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Ora carichiamo i nostri dati csv dal file airports.csv (airport csv github) il cui schema è il seguente
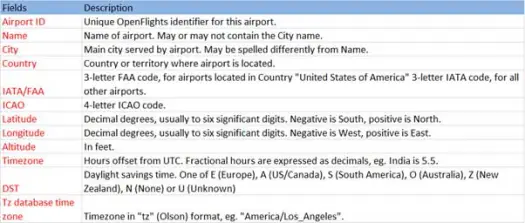
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))L'operazione di caricamento analizzerà il file *.csv utilizzando la libreria spark-csv di Databricks e restituirà un frame di dati con nomi di colonna uguali a quelli della prima riga di intestazione nel file.
Di seguito sono riportati i parametri passati al metodo di caricamento.
- Fonte : "com.databricks.spark.csv" dice a Spark che vogliamo caricare come file CSV.
- Opzioni:
- percorso – percorso del file, dove si trova.
- Header : "header" -> "true" dice a Spark di mappare la prima riga del file sui nomi delle colonne per il dataframe risultante.
Vediamo qual è lo schema del nostro Dataframe
Dai un'occhiata ai dati di esempio nel nostro dataframe
scala> airportDF.show


Interrogazione di dati CSV utilizzando tabelle temporanee:
Per eseguire una query su una tabella, chiamiamo il metodo sql() su SQLContext.
Abbiamo creato il DataFrame degli aeroporti e caricato i dati CSV, per interrogare questi dati DF dobbiamo registrarli come tabella temporanea chiamata aeroporti.
>
scala> airportDF.registerTempTable("airports")
Scopriamo quanti aeroporti ci sono nella parte sud-est nel nostro set di dati
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Possiamo fare aggregazioni in query sql su Spark
Scopriremo quante città uniche hanno aeroporti in ogni paese
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Qual è l'altitudine media (in piedi) degli aeroporti in ciascun Paese?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Ora per scoprire in ogni fuso orario quanti aeroporti operano?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Possiamo anche calcolare la latitudine e la longitudine medie per questi aeroporti in ogni paese
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Contiamo quanti diversi DST ci sono
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Salvataggio dei dati in formato CSV
Finora abbiamo caricato e interrogato i dati CSV. Ora vedremo come salvare i risultati in formato CSV sul filesystem.
Supponiamo di voler inviare un rapporto al cliente su tutti gli aeroporti nella parte nord-occidentale di tutti i paesi.
Calcoliamolo prima.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
E salvalo in un file CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Di seguito sono riportati i parametri passati per salvare il metodo.
- Fonte : è lo stesso del metodo di caricamento com.databricks.spark.csv che dice a Spark di salvare i dati come csv.
- SaveMode : consente all'utente di specificare in anticipo cosa deve essere fatto se il percorso di output specificato esiste già. In modo che i dati esistenti non vengano persi/sovrascritti per errore. Puoi lanciare un errore, aggiungere o sovrascrivere. Qui, abbiamo generato un errore ErrorIfExists poiché non vogliamo sovrascrivere alcun file esistente.
- Opzioni : queste opzioni sono le stesse che abbiamo passato al metodo di caricamento . Opzioni:
- percorso – percorso del file, dove dovrebbe essere archiviato.
- Header : "header" -> "true" dice a Spark di mappare i nomi delle colonne del frame di dati sulla prima riga del file di output risultante.
Conversione di altri formati di dati in CSV
Possiamo anche convertire qualsiasi altro formato di dati come JSON, parquet, testo in CSV utilizzando questa libreria.
Nel blog precedente avevamo creato dati json. lo trovi su github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
salvalo semplicemente come CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Conclusione:
In questo post abbiamo raccolto alcune informazioni sui dati degli aeroporti utilizzando le query interattive SparkSQL
ed esplorato la libreria di analisi CSV da Spark
Il prossimo blog esploreremo componenti molto importanti di Spark, ovvero Spark Streaming.
Spark Streaming consente agli utenti di raccogliere dati in tempo reale in Spark ed elaborarli in tempo reale e fornire risultati all'istante.