
Google utilizza un sistema simile a ChatGPT per il rilevamento di spam e contenuti AI e per il posizionamento dei siti Web?
Pubblicato: 2023-02-01Il titolo è intenzionalmente fuorviante, ma solo per quanto riguarda l'uso del termine "ChatGPT".
"ChatGPT-like" consente immediatamente a te, lettore, di conoscere il tipo di tecnologia a cui mi riferisco, invece di descrivere il sistema come "un modello di generazione di testo come GPT-2 o GPT-3". (Inoltre, quest'ultimo in realtà non sarebbe così cliccabile...)
Quello che esamineremo in questo articolo è un vecchio documento di Google, ma molto pertinente, del 2020, "I modelli generativi sono predittori non supervisionati della qualità della pagina: uno studio su scala colossale".
Di cosa parla il giornale?
Iniziamo con la descrizione degli autori. Introducono l'argomento così:
“Molti hanno sollevato preoccupazioni sui potenziali pericoli dei generatori di testo neurale in natura, in gran parte a causa della loro capacità di produrre testo dall'aspetto umano su larga scala.
Classificatori addestrati a discriminare tra testo umano e testo generato dalla macchina sono stati recentemente impiegati per monitorare la presenza di testo generato dalla macchina sul web [29]. Poco lavoro, tuttavia, è stato fatto nell'applicare questi classificatori per altri usi, nonostante la loro attraente proprietà di non richiedere etichette: solo un corpus di testo umano e un modello generativo. In questo lavoro, mostriamo attraverso una rigorosa valutazione umana che i discriminatori umani vs. macchina standard servono come potenti classificatori della qualità della pagina . Cioè, i testi che appaiono generati dalla macchina tendono ad essere incoerenti o incomprensibili. Per comprendere la presenza di una bassa qualità delle pagine in natura, applichiamo i classificatori a un campione di mezzo miliardo di pagine web in inglese".
Quello che stanno essenzialmente dicendo è che hanno scoperto che gli stessi classificatori sviluppati per rilevare la copia basata sull'intelligenza artificiale, utilizzando gli stessi modelli per generarla, possono essere utilizzati con successo per rilevare contenuti di bassa qualità.
Naturalmente, questo ci lascia con una domanda importante:
Si tratta di causalità (ovvero, il sistema lo rileva perché è veramente bravo a farlo) o di correlazione (ovvero, gran parte dello spam attuale è creato in un modo che è facile aggirare con strumenti migliori)?
Prima di esplorarlo, tuttavia, diamo un'occhiata ad alcuni dei lavori degli autori e alle loro scoperte.
Il set up
Per riferimento, hanno usato quanto segue nel loro esperimento:
- Due modelli di generazione di testo , il rilevatore GPT-2 basato su RoBERTa di OpenAI (un rilevatore che utilizza il modello RoBERTa con output GPT-2 e prevede se è probabile che sia generato dall'IA o meno) e il modello GLTR, che ha anche accesso alla parte superiore Uscita GPT-2 e funziona in modo simile.
Possiamo vedere un esempio dell'output di questo modello sul contenuto che ho copiato dal documento sopra:
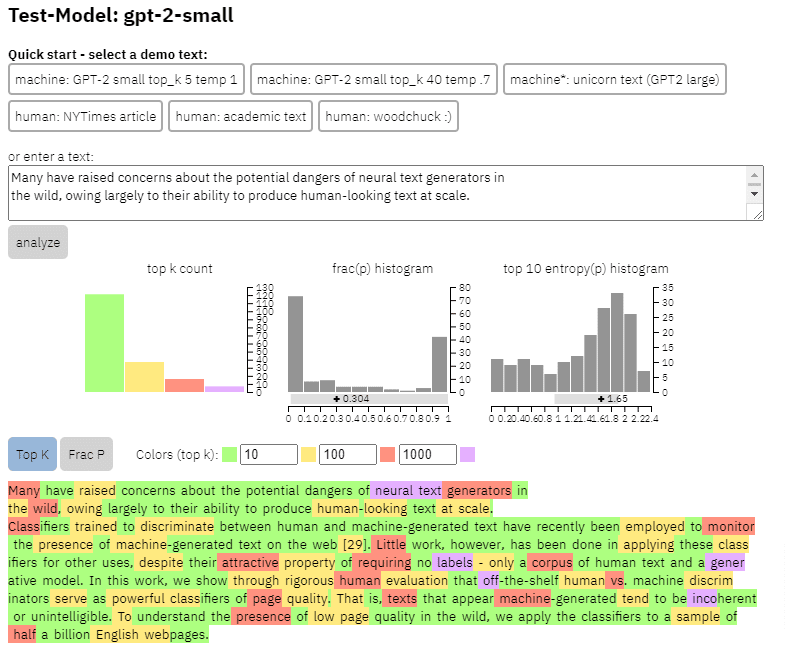
- Tre set di dati Web500M (un campionamento casuale di 500 milioni di pagine Web in inglese), GPT-2 Output (250.000 generazioni di testo GPT-2) e Grover-Output (hanno generato internamente 1,2 milioni di articoli utilizzando il modello Grover-Base pre-addestrato, progettato rilevare notizie false).
- The Spam Baseline , un classificatore addestrato sul set di dati Enron Spam Email. Hanno utilizzato questo classificatore per stabilire il numero di qualità della lingua che avrebbero assegnato, quindi se il modello ha stabilito che un documento non è spam con una probabilità di 0,2, il punteggio di qualità della lingua (LQ) assegnato era 0,2.
Ottieni la newsletter quotidiana su cui si affidano i marketer di ricerca.
Vedi termini.
Una parentesi sulla prevalenza dello spam
Volevo fare una breve digressione per discutere alcune scoperte interessanti in cui si sono imbattuti gli autori. Uno è illustrato nella figura seguente (Figura 3 dal documento):
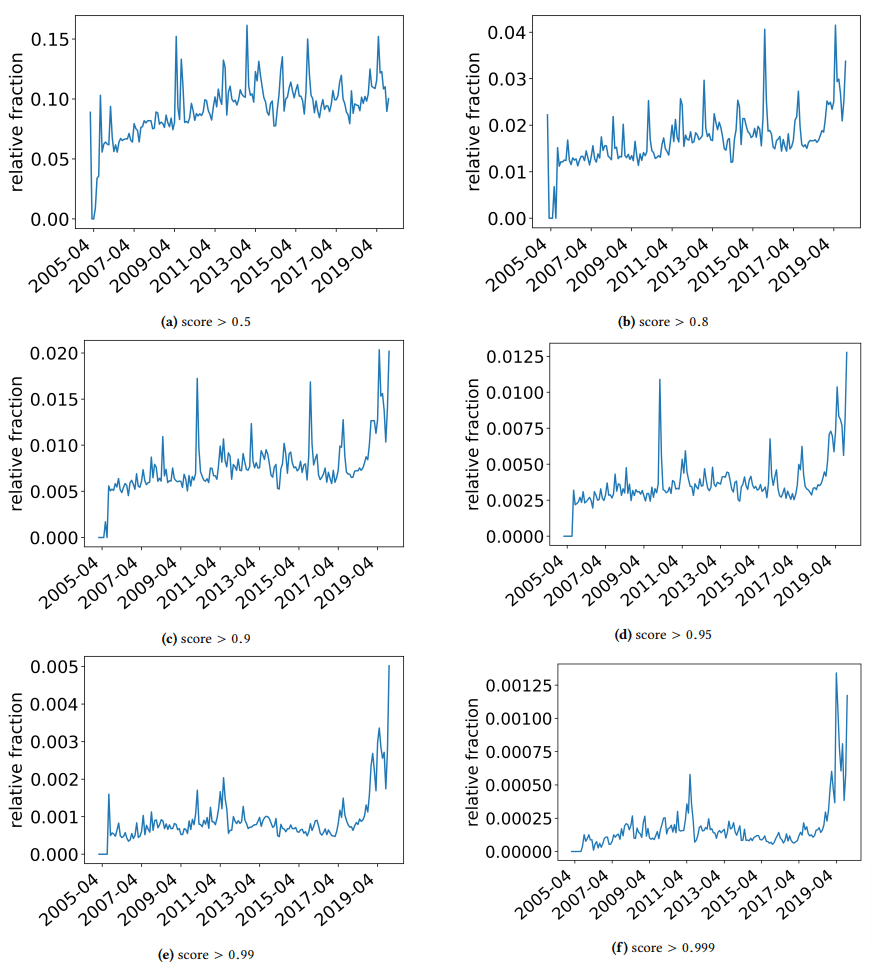
È importante notare il punteggio sotto ogni grafico. Un numero verso 1,0 si sta muovendo verso la certezza che il contenuto sia spam. Quello che stiamo vedendo quindi è che dal 2017 in poi - e con un picco nel 2019 - c'è stata una prevalenza di documenti di bassa qualità.
Inoltre, hanno scoperto che l'impatto dei contenuti di bassa qualità era maggiore in alcuni settori rispetto ad altri (ricordando che un punteggio più alto riflette una maggiore probabilità di spam).
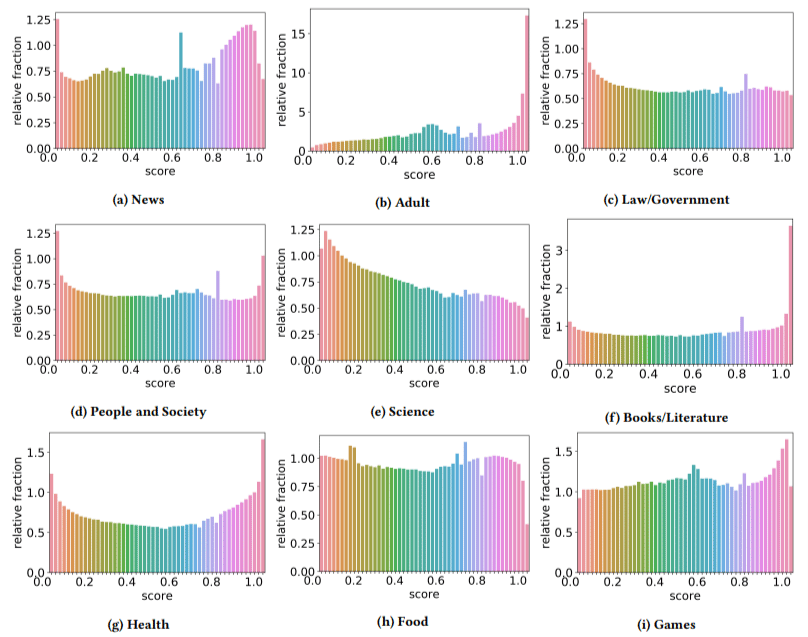
Mi sono grattato la testa su un paio di questi. L'adulto aveva senso, ovviamente.
Ma i libri e la letteratura sono stati un po' una sorpresa. E così era la salute - fino a quando gli autori non hanno citato il Viagra e altri siti di "prodotti per la salute degli adulti" come "salute" e le fattorie di saggi come "letteratura" - cioè.
Le loro scoperte
A parte ciò che abbiamo discusso sui settori e il picco nel 2019, gli autori hanno anche scoperto una serie di cose interessanti da cui i SEO possono imparare e che devono tenere a mente, soprattutto quando iniziamo ad appoggiarci a strumenti come ChatGPT.
- I contenuti di bassa qualità tendono ad essere di lunghezza inferiore (con un picco di 3.000 caratteri).
- I sistemi di rilevamento addestrati per determinare se il testo è stato scritto da una macchina o meno sono anche bravi a classificare contenuti di basso e alto livello.
- Chiamano il nostro contenuto progettato per le classifiche come un colpevole specifico, anche se sospetto che si riferiscano alla spazzatura che tutti sappiamo non dovrebbe essere lì.
Gli autori non affermano che questa sia una soluzione definitiva, ma piuttosto un punto di partenza e sono sicuro che negli ultimi due anni hanno spostato l'asticella in avanti.
Una nota sui contenuti generati dall'intelligenza artificiale
Anche i modelli linguistici si sono sviluppati nel corso degli anni. Mentre GPT-3 esisteva quando questo documento è stato scritto, i rilevatori che stavano usando erano basati su GPT-2 che è un modello significativamente inferiore.
GPT-4 è probabilmente dietro l'angolo e Google's Sparrow uscirà entro la fine dell'anno. Ciò significa che non solo la tecnologia sta migliorando su entrambi i lati del campo di battaglia (generatori di contenuti contro motori di ricerca), ma le combinazioni saranno più facili da mettere in gioco.
Google può rilevare i contenuti creati da Sparrow o GPT-4? Forse.
Ma che ne dici se è stato generato con Sparrow e poi inviato a GPT-4 con un prompt di riscrittura?
Un altro fattore da ricordare è che le tecniche utilizzate in questo documento si basano su modelli autoregressivi. In poche parole, prevedono un punteggio per una parola in base a ciò che prevederebbero che quella parola sarebbe stata assegnata a coloro che l'hanno preceduta.
Man mano che i modelli sviluppano un grado più elevato di sofisticazione e iniziano a creare idee complete alla volta piuttosto che una parola seguita da un'altra, il rilevamento dell'IA potrebbe fallire.
D'altra parte, il rilevamento di contenuti semplicemente scadenti dovrebbe intensificarsi, il che potrebbe significare che l'unico contenuto di "bassa qualità" che vincerà sarà generato dall'intelligenza artificiale.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.