
Ecosistema Hadoop e suoi componenti
Pubblicato: 2015-04-23Big Data è la parola d'ordine che circola nel settore IT dal 2008. La quantità di dati generata dai settori dei social network, della produzione, della vendita al dettaglio, delle azioni, delle telecomunicazioni, delle assicurazioni, delle banche e della sanità è ben oltre la nostra immaginazione.
Prima dell'avvento di Hadoop, l'archiviazione e l'elaborazione dei big data erano una grande sfida. Ma ora che Hadoop è disponibile, le aziende si sono rese conto dell'impatto sul business dei Big Data e di come la comprensione di questi dati guiderà la crescita. Per esempio:
• I settori bancari hanno maggiori possibilità di comprendere i clienti fedeli, gli inadempienti sui prestiti e le transazioni fraudolente.
• I settori del commercio al dettaglio ora dispongono di dati sufficienti per prevedere la domanda.
• I settori manifatturieri non devono necessariamente dipendere dai costosi meccanismi per i test di qualità. Catturare i dati dei sensori e analizzarli rivelerebbe molti modelli.
• E-Commerce, i social network possono personalizzare le pagine in base agli interessi dei clienti.
• I mercati azionari generano un'enorme quantità di dati, la correlazione di volta in volta rivelerà bellissime intuizioni.
I Big Data hanno molte applicazioni utili e approfondite.
Hadoop è la risposta diretta per l'elaborazione dei Big Data. L'ecosistema Hadoop è una combinazione di tecnologie che hanno un vantaggio abile nella risoluzione dei problemi aziendali.
Cerchiamo di comprendere i componenti di Hadoop Ecosytem per creare soluzioni giuste per un determinato problema aziendale.
Ecosistema Hadoop:
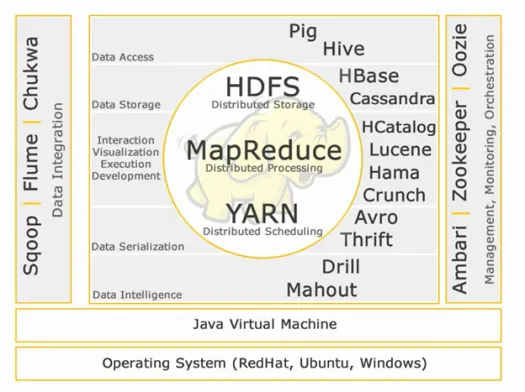

Core Hadoop:
HDFS:
HDFS è l'acronimo di Hadoop Distributed File System per la gestione di grandi set di dati con volume elevato, velocità e varietà. HDFS implementa l'architettura master slave. Il master è il nodo Nome e lo slave è il nodo dati.
Caratteristiche:
• Scalabile
• Affidabile
• Hardware di base
HDFS è noto per l'archiviazione di Big Data.
Riduci mappa:
Map Reduce è un modello di programmazione progettato per elaborare dati distribuiti ad alto volume. La piattaforma è costruita utilizzando Java per una migliore gestione delle eccezioni. Map Reduce include due demoni, Job tracker e Task Tracker.
Caratteristiche:
• Programmazione funzionale.
• Funziona molto bene sui Big Data.
• Può elaborare set di dati di grandi dimensioni.
Map Reduce è il componente principale noto per l'elaborazione di big data.
FILATO:
YARN sta per Yet Another Resource Negotiator. Viene anche chiamato MapReduce 2(MRv2). Le due principali funzionalità di Job Tracker in MRv1, la gestione delle risorse e la pianificazione/monitoraggio dei lavori, sono suddivise in demoni separati che sono ResourceManager, NodeManager e ApplicationMaster.
Caratteristiche:
• Migliore gestione delle risorse.
• Scalabilità
• Allocazione dinamica delle risorse del cluster.
Accesso ai dati:
Maiale:
Apache Pig è un linguaggio di alto livello basato su MapReduce per l'analisi di grandi set di dati con semplici programmi di analisi dei dati ad hoc. Pig è anche noto come linguaggio del flusso di dati. È molto ben integrato con Python. Inizialmente è sviluppato da yahoo.
Caratteristiche salienti del maiale:
• Facilità di programmazione
• Opportunità di ottimizzazione
• Estensibilità.
Gli script Pig internamente verranno convertiti per mappare i programmi di riduzione.

Alveare:
Apache Hive è un altro linguaggio di query di alto livello e un'infrastruttura di data warehouse costruita su Hadoop per fornire riepilogo, query e analisi dei dati. Inizialmente è sviluppato da yahoo e reso open source.
Caratteristiche salienti dell'alveare:
• Linguaggio di query simile a SQL chiamato HQL.
• Partizionamento e bucket per un'elaborazione più rapida dei dati.
• Integrazione con strumenti di visualizzazione come Tableau.
Le query Hive internamente verranno convertite per mappare i programmi di riduzione.
Se vuoi diventare un analista di big data, questi due linguaggi di alto livello sono assolutamente da conoscere!!

Archivio dati:
Base H:
Apache HBase è un database NoSQL creato per ospitare grandi tabelle con miliardi di righe e milioni di colonne su macchine hardware Hadoop. Usa Apache Hbase quando hai bisogno di un accesso in lettura/scrittura casuale e in tempo reale ai tuoi Big Data.
Caratteristiche:
• Letture e scritture rigorosamente coerenti. Nelle operazioni di memoria.
• API Java facile da usare per l'accesso client.
• Ben integrato con maiale, alveare e scoop.
• È un sistema consistente e tollerante alla partizione nel teorema CAP.

Cassandra:
Cassandra è un database NoSQL progettato per la scalabilità lineare e l'elevata disponibilità. Cassandra si basa sul modello chiave-valore. Sviluppato da Facebook e noto per una risposta più rapida alle domande.
Caratteristiche:
• Indici di colonna
• Supporto per la denormalizzazione
• Viste materializzate
• Potente memorizzazione nella cache integrata.


Interazione -Visualizzazione-esecuzione-sviluppo:
Catalogo:
HCatalog è un livello di gestione delle tabelle che fornisce l'integrazione dei metadati dell'hive per altre applicazioni Hadoop. Consente agli utenti con diversi strumenti di elaborazione dati come Apache pig, Apache MapReduce e Apache Hive di leggere e scrivere dati più facilmente.
Caratteristiche:
• Vista tabellare per diversi formati.
• Notifiche di disponibilità dei dati.
• API REST per sistemi esterni per l'accesso ai metadati.
Luceno:
Apache LuceneTM è una libreria di motori di ricerca di testo completa e ad alte prestazioni scritta interamente in Java. È una tecnologia adatta a quasi tutte le applicazioni che richiedono la ricerca full-text, in particolare multipiattaforma.
Caratteristiche:
• Indicizzazione scalabile, ad alte prestazioni.
• Algoritmi di ricerca potenti, accurati ed efficienti.
• Soluzione multipiattaforma.
Hama:
Apache Hama è un framework distribuito basato sul calcolo Bulk Synchronous Parallel (BSP). Capace e ben noto per enormi calcoli scientifici come algoritmi di matrici, grafici e reti.
Caratteristiche:
• Modello di programmazione semplice
• Adatto per algoritmi iterativi
• FILATO supportato
• Apprendimento automatico non supervisionato con filtraggio collaborativo.
• Raggruppamento K-Means.
scricchiolio:
Apache crunch è creato per la pipeline di programmi MapReduce che sono semplici ed efficienti. Questo framework viene utilizzato per scrivere, testare ed eseguire pipeline MapReduce.
Caratteristiche:
• Incentrato sullo sviluppatore.
• Minime astrazioni
• Modello dati flessibile.
Serializzazione dei dati:
Avro:
Apache Avro è un framework di serializzazione dei dati che è neutrale dal punto di vista della lingua. Progettato per la portabilità della lingua, consentendo ai dati di sopravvivere potenzialmente alla lingua per leggerli e scriverli.

parsimonia:
Thrift è un linguaggio sviluppato per costruire interfacce per interagire con le tecnologie basate su Hadoop. Viene utilizzato per definire e creare servizi per numerose lingue.
Intelligenza dati:
Trapano:
Apache Drill è un motore di query SQL a bassa latenza per Hadoop e NoSQL.
Caratteristiche:
• Agilità
• Flessibilità
• Familiarità.

Mahout:
Apache Mahout è una libreria di machine learning scalabile progettata per creare analisi predittive su Big Data. Mahout ora ha implementazioni Apache Spark per velocizzare il calcolo della memoria.
Caratteristiche:
• Filtraggio collaborativo.
• Classificazione
• Raggruppamento
• Riduzione della dimensionalità

Integrazione dei dati:
Apache Sqoop:

Apache Sqoop è uno strumento progettato per il trasferimento di dati in blocco tra database relazionali e Hadoop.
Caratteristiche:
• Importazione ed esportazione da e verso HDFS.
• Importa ed esporta da e verso Hive.
• Importa ed esporta in HBase.
Canale Apache:
Flume è un servizio distribuito, affidabile e disponibile per raccogliere, aggregare e spostare in modo efficiente grandi quantità di dati di registro.
Caratteristiche:
• Robusto
• Tollerante agli errori
• Architettura semplice e flessibile basata su flussi di dati in streaming.

Apache Chukwa:
Raccoglitore di log scalabile utilizzato per il monitoraggio di file system distribuiti di grandi dimensioni.
Caratteristiche:
• Scala a migliaia di nodi.
• Consegna affidabile.
• Dovrebbe essere in grado di memorizzare i dati a tempo indeterminato.

Gestione, monitoraggio e orchestrazione:
Apache Ambari:
Ambari è progettato per semplificare la gestione di hadoop fornendo un'interfaccia per il provisioning, la gestione e il monitoraggio dei cluster Apache Hadoop.
Caratteristiche:
• Fornire un cluster Hadoop.
• Gestire un cluster Hadoop.
• Monitorare un cluster Hadoop.

Guardiano dello zoo di Apache:
Zookeeper è un servizio centralizzato progettato per il mantenimento delle informazioni di configurazione, la denominazione, la sincronizzazione distribuita e la fornitura di servizi di gruppo.
Caratteristiche:
• Serializzazione
• Atomicita
• Affidabilità
• API semplice

Apache Oozie:
Oozie è un sistema di pianificazione del flusso di lavoro per gestire i lavori Apache Hadoop.
Caratteristiche:
• Sistema scalabile, affidabile ed estensibile.
• Supporta diversi tipi di lavori Hadoop come Map-Reduce, Hive, Pig e Sqoop.
• Semplice e facile da usare.

Parleremo dei componenti in dettaglio nei prossimi articoli. Rimani sintonizzato.