
Installazione di Hadoop tramite Ambari
Pubblicato: 2015-12-11Tutto quello che vuoi sapere sull'installazione di Hadoop tramite Ambari
Apache Hadoop è diventato un framework software de facto per l'elaborazione affidabile, scalabile, distribuita e su larga scala. A differenza di altri sistemi informatici, porta il calcolo ai dati anziché inviarli al calcolo. Hadoop è stato creato nel 2006 su Yahoo da Doug Cutting sulla base di un documento pubblicato da Google. Con la maturazione di Hadoop, nel corso degli anni molti nuovi componenti e strumenti sono stati aggiunti al suo ecosistema per migliorarne l'usabilità e la funzionalità. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop ecc. solo per citarne alcuni.
Perché Ambari?
Con la crescente popolarità di Hadoop, molti sviluppatori si lanciano in questa tecnologia per averne un assaggio. Ma come si suol dire, Hadoop non è per i deboli di cuore, molti sviluppatori non sono nemmeno riusciti a superare la barriera dell'installazione di Hadoop. Molte distribuzioni offrono sandbox preinstallato di VM per provare le cose, ma non ti dà la sensazione di elaborazione distribuita. Tuttavia, l'installazione di un multinodo non è un compito facile e con un numero crescente di componenti, è molto complicato gestire così tanti parametri di configurazione. Per fortuna Apache Ambari viene qui in nostro soccorso!
Cos'è Ambari?
Apache Ambari è uno strumento basato sul Web per il provisioning, la gestione e il monitoraggio dei cluster Apache Hadoop. Ambari fornisce un dashboard per la visualizzazione dello stato del cluster come mappe di calore e la possibilità di visualizzare visivamente le applicazioni MapReduce, Pig e Hive insieme a funzionalità per diagnosticare le loro caratteristiche prestazionali in modo intuitivo. Ha un'interfaccia utente molto semplice e interattiva per installare vari strumenti ed eseguire varie attività di gestione, configurazione e monitoraggio. Di seguito ti guideremo attraverso vari passaggi per l'installazione di Hadoop e dei suoi vari componenti dell'ecosistema su cluster multinodo.
L'architettura di Ambari è mostrata di seguito
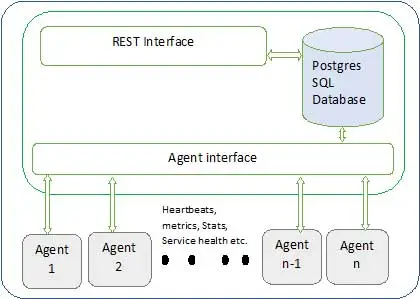
Gli Ambari hanno due componenti
- Server Ambari – Questo è il processo master che comunica con gli agenti Ambari installati su ciascun nodo che partecipa al cluster. Questo ha un'istanza del database postgres che viene utilizzata per mantenere tutti i metadati relativi al cluster.
- Agente Ambari – Questi sono agenti in qualità di Ambari su ogni nodo. Ogni agente invia periodicamente il proprio stato di salute insieme a diverse metriche, stato dei servizi installati e molte altre cose. Secondo il maestro decide l'azione successiva e rimanda all'agente per agire.
Come installare Ambari?
L'installazione di Ambari è un compito facile di pochi comandi.
Tratteremo l'installazione di Ambari e la configurazione del cluster. Si presume che abbiamo 4 nodi. Nodo1, Nodo2, Nodo3 e Nodo4. E stiamo selezionando Node1 come nostro server Ambari.
Questi sono passaggi di installazione sul sistema basato su RHEL, per Debian e altri passaggi i passaggi variano leggermente.
- Installazione di Ambari: –
Dal nodo del server Ambari (nodo 1 come abbiamo deciso)
io. Scarica il repository pubblico Ambari

Questo comando aggiungerà il repository Hortonworks Ambari in yum, che è un gestore di pacchetti predefinito per i sistemi RHEL.
ii.Installa Ambari RPMS

Ci vorrà del tempo e installerà Ambari su questo sistema.

iii. Configurazione del server Ambari
La prossima cosa da fare dopo l'installazione di Ambari è configurare Ambari e configurarlo per il provisioning del cluster.
Il passaggio successivo si occuperà di questo


IV. Avvia il server e accedi all'interfaccia utente web
Avvia il server con

Ora possiamo accedere all'interfaccia utente web di Ambari (ospitata sulla porta 8080).
Accedi ad Ambari con nome utente predefinito "admin" e password predefinita "admin"
Configurazione del cluster Hadoop
1. Pagina di destinazione
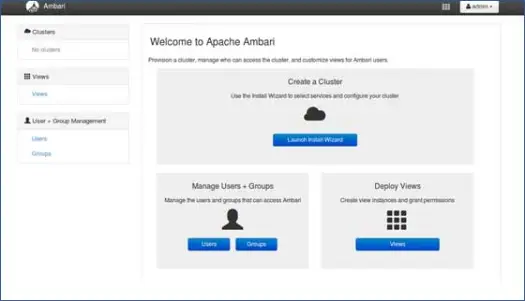
Fare clic su "Avvia installazione guidata" per avviare la configurazione del cluster
2. Nome del cluster
Darti un buon nome al gruppo.
Nota: questo è solo un semplice nome per il cluster, non è così significativo, quindi non preoccuparti e scegli un nome per esso.
3. Selezione della pila
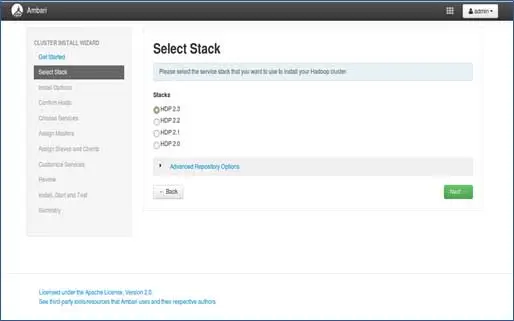
Questa pagina elencherà gli stack disponibili per l'installazione. Ogni stack è preconfezionato con il componente dell'ecosistema Hadoop. Queste pile sono di Hortonworks. (Possiamo installare anche Hadoop semplice. Di cui parleremo nei post successivi).
4.Inserimento host e inserimento chiave SSH
Prima di procedere ulteriormente in questo passaggio, dovremmo avere una configurazione SSH senza password per tutti i nodi partecipanti.

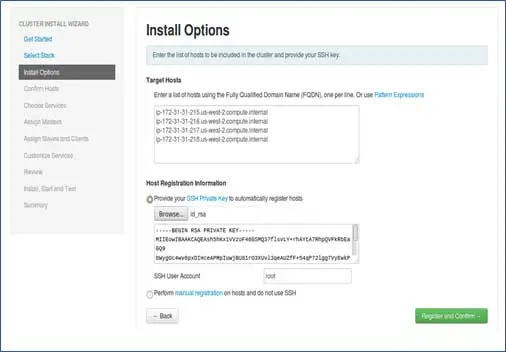
Aggiungi i nomi host dei nodi, voce singola su ogni riga. [Aggiungi FQDN che può essere ottenuto tramite il comando hostname –f]. Seleziona la chiave privata utilizzata durante l'impostazione della password meno SSH e nome utente utilizzando la chiave privata creata.
5. Stato di registrazione degli host
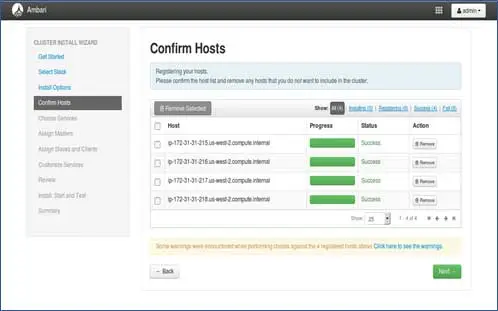
Puoi vedere alcune operazioni eseguite, queste operazioni includono l'impostazione di Ambari-agent su ciascun nodo, la creazione di configurazioni di base su ciascun nodo. Quando vedremo TUTTO VERDE siamo pronti per andare avanti. A volte questo può richiedere del tempo poiché installa pochi pacchetti.

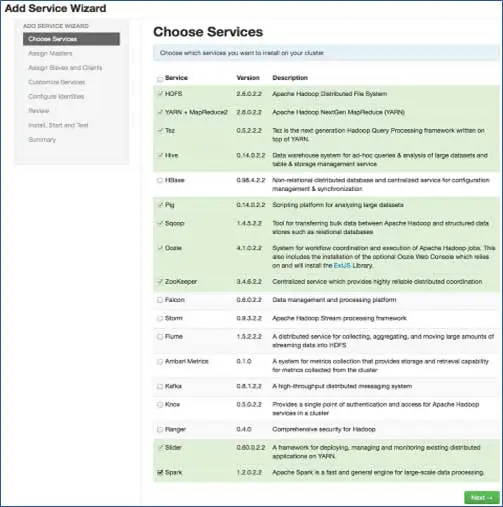
6. Scegli i servizi che desideri installare
In base agli stack selezionati nel passaggio 3, abbiamo il numero di servizi che possiamo installare nel cluster. Puoi scegliere quello che vuoi. Ambari seleziona in modo intelligente i servizi dipendenti se non li hai selezionati. Ad esempio, hai selezionato HBase ma non Zookeeper, verrà visualizzato lo stesso messaggio e aggiungerà Zookeeper anche al cluster.
7. Mappatura servizi master con Nodi
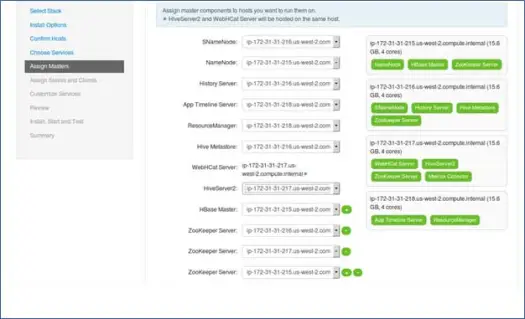
Come saprai, l'ecosistema Hadoop ha strumenti basati sull'architettura master-slave. In questo passaggio, assoceremo i processi master al nodo. Qui assicurati di bilanciare correttamente il tuo cluster. Inoltre, tieni presente che i servizi primari e secondari come Namenode e Namenode secondario non si trovano sulla stessa macchina.

8. Mappatura degli slave con i nodi
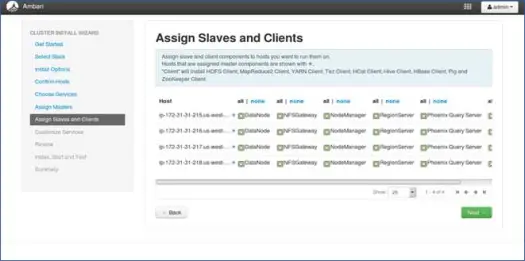
Simile ai master, mappa i servizi slave sui nodi. In generale, tutti i nodi avranno un processo slave in esecuzione almeno per Datanodes e Nodemanager.
9. Personalizza i servizi
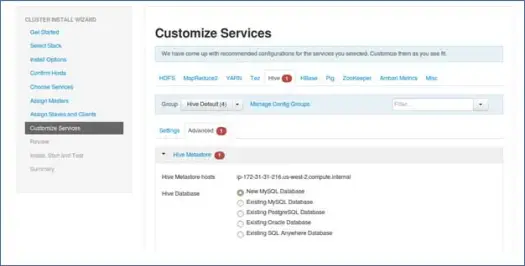
Questa è una pagina molto importante per gli amministratori.
Qui puoi configurare le proprietà per il tuo cluster per renderlo più adatto ai tuoi casi d'uso.
Inoltre avrà alcune proprietà richieste come la password del metastore Hive (se hive è selezionato) ecc. Queste verranno indicate con un errore rosso come simboli.
10. Rivedere e avviare il provisioning
Assicurati di rivedere la configurazione del cluster prima dell'avvio in quanto ciò salverà da configurazioni errate impostate inconsapevolmente.
11. Avviare e rimanere indietro fino a quando lo stato diventa VERDE.
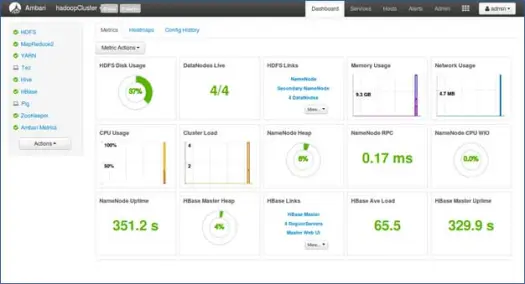
Prossimi passi
Sì! Abbiamo installato con successo Hadoop e tutti i componenti su tutti i nodi del cluster. Ora possiamo iniziare a giocare con Hadoop.
Ambari esegue un processo di conteggio parole MapReduce per verificare se tutto funziona correttamente. Controlliamo il registro del lavoro eseguito dall'utente ambari-qa.
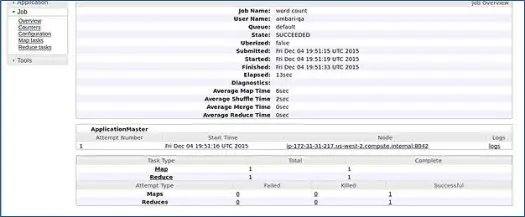
Come puoi vedere nello screenshot sopra, il lavoro di WordCount è stato completato con successo. Ciò conferma che il nostro cluster funziona correttamente.
Conclusione
Ecco fatto, ora abbiamo imparato come installare Hadoop e i suoi componenti sul cluster multinodo utilizzando un semplice strumento basato sul web chiamato Apache Ambari. Apache Ambari ci fornisce un'interfaccia più semplice e risparmia molti dei nostri sforzi per l'installazione, il monitoraggio e la gestione che sarebbero stati molto noiosi con così tanti componenti e le loro diverse fasi di installazione e controlli di monitoraggio.
Lascia che ti lasci con un trucco

Il programma di installazione di Ambari controlla /etc/lsb-release per ottenere i dettagli del sistema operativo. In Linux Mint, lo stesso file per la versione di Ubuntu si trova in /etc/upstream-release/lsb-release. Per ingannare l'installatore, basta sostituire il primo con il secondo (dovresti prima eseguire il backup del file).

Ad un certo punto al termine dell'installazione, puoi ripristinare l'originale con:

PS Questo è un hack senza alcuna garanzia, ha funzionato per me, quindi ho pensato di condividerlo con te.
Sei uno sviluppatore/dev-op e devi installare Hadoop rapidamente. Abbiamo una buona notizia per te, Ambari fornisce un modo in cui puoi saltare il processo completo della procedura guidata e il processo di installazione completato con un singolo script, e lo porterò nel prossimo post, quindi resta sintonizzato e fino ad allora Happy Hadooping!