
Una guida SEO per comprendere i grandi modelli linguistici (LLM)
Pubblicato: 2023-05-08Devo utilizzare modelli di linguaggio di grandi dimensioni per la ricerca di parole chiave? Questi modelli possono pensare? ChatGPT è mio amico?
Se ti sei posto queste domande, questa guida è per te.
Questa guida copre ciò che i SEO devono sapere sui modelli di linguaggio di grandi dimensioni, l'elaborazione del linguaggio naturale e tutto il resto.
Modelli di linguaggio di grandi dimensioni, elaborazione del linguaggio naturale e altro in termini semplici
Ci sono due modi per convincere una persona a fare qualcosa: dirgli di farlo o sperare che lo faccia da solo.
Quando si tratta di informatica, la programmazione dice al robot di farlo, mentre l'apprendimento automatico spera che il robot lo faccia da solo. Il primo è l'apprendimento automatico supervisionato e il secondo è l'apprendimento automatico non supervisionato.
L'elaborazione del linguaggio naturale (NLP) è un modo per scomporre il testo in numeri e quindi analizzarlo utilizzando i computer.
I computer analizzano i modelli nelle parole e, man mano che diventano più avanzati, nelle relazioni tra le parole.
Un modello di apprendimento automatico del linguaggio naturale non supervisionato può essere addestrato su molti diversi tipi di set di dati.
Ad esempio, se hai addestrato un modello linguistico sulla media delle recensioni del film "Waterworld", avresti un risultato che è bravo a scrivere (o comprendere) le recensioni del film "Waterworld".
Se lo addestrassi sulle due recensioni positive che ho fatto del film "Waterworld", capirebbe solo quelle recensioni positive.
I Large Language Model (LLM) sono reti neurali con oltre un miliardo di parametri. Sono così grandi che sono più generalizzati. Non sono solo formati su recensioni positive e negative per "Waterworld", ma anche su commenti, articoli di Wikipedia, siti di notizie e altro ancora.
I progetti di machine learning lavorano molto con il contesto, cose all'interno e all'esterno del contesto.
Se hai un progetto di apprendimento automatico che funziona per identificare i bug e mostrargli un gatto, non andrà bene per quel progetto.
Questo è il motivo per cui cose come le auto a guida autonoma sono così difficili: ci sono così tanti problemi fuori contesto che è molto difficile generalizzare questa conoscenza.
Gli LLM sembrano e possono essere molto più generalizzato rispetto ad altri progetti di machine learning. Ciò è dovuto alla vastità dei dati e alla capacità di elaborare miliardi di relazioni diverse.
Parliamo di una delle tecnologie rivoluzionarie che lo consentono: i trasformatori.
Spiegare i trasformatori da zero
Un tipo di architettura di rete neurale, i trasformatori hanno rivoluzionato il campo della PNL.
Prima dei trasformatori, la maggior parte dei modelli di PNL si basava su una tecnica chiamata reti neurali ricorrenti (RNN), che elaborava il testo in sequenza, una parola alla volta. Questo approccio aveva i suoi limiti, come essere lento e faticare a gestire le dipendenze a lungo raggio nel testo.
I trasformatori hanno cambiato questo.
Nel documento fondamentale del 2017, "L'attenzione è tutto ciò di cui hai bisogno", Vaswani et al. ha introdotto l'architettura del trasformatore.
Invece di elaborare il testo in sequenza, i trasformatori utilizzano un meccanismo chiamato "auto-attenzione" per elaborare le parole in parallelo, consentendo loro di catturare le dipendenze a lungo raggio in modo più efficiente.
L'architettura precedente includeva RNN e algoritmi di memoria a lungo termine.
Modelli ricorrenti come questi erano (e sono tuttora) comunemente usati per attività che coinvolgono sequenze di dati, come testo o parlato.
Tuttavia, questi modelli hanno un problema. Possono elaborare i dati solo un pezzo alla volta, il che li rallenta e limita la quantità di dati con cui possono lavorare. Questa elaborazione sequenziale limita davvero la capacità di questi modelli.
I meccanismi di attenzione sono stati introdotti come un modo diverso di elaborare i dati della sequenza. Consentono a un modello di esaminare tutti i dati contemporaneamente e decidere quali sono i più importanti.
Questo può essere davvero utile in molte attività. Tuttavia, la maggior parte dei modelli che hanno utilizzato l'attenzione utilizzano anche l'elaborazione ricorrente.
Fondamentalmente, avevano questo modo di elaborare i dati tutti in una volta, ma avevano comunque bisogno di guardarli in ordine. L'articolo di Vaswani et al. Galleggiava: "E se usassimo solo il meccanismo dell'attenzione?"
L'attenzione è un modo per il modello di concentrarsi su alcune parti della sequenza di input durante l'elaborazione. Ad esempio, quando leggiamo una frase, prestiamo naturalmente più attenzione ad alcune parole che ad altre, a seconda del contesto e di ciò che vogliamo capire.
Se guardi un trasformatore, il modello calcola un punteggio per ogni parola nella sequenza di input in base a quanto sia importante per comprendere il significato generale della sequenza.
Il modello utilizza quindi questi punteggi per soppesare l'importanza di ciascuna parola nella sequenza, consentendogli di concentrarsi maggiormente sulle parole importanti e meno su quelle non importanti.
Questo meccanismo di attenzione aiuta il modello a catturare dipendenze e relazioni a lungo raggio tra parole che potrebbero essere molto distanti nella sequenza di input senza dover elaborare l'intera sequenza in sequenza.
Ciò rende il trasformatore così potente per le attività di elaborazione del linguaggio naturale, in quanto può comprendere rapidamente e con precisione il significato di una frase o una sequenza di testo più lunga.
Prendiamo l'esempio di un modello di trasformatore che elabora la frase "Il gatto si è seduto sul tappeto".
Ogni parola nella frase è rappresentata come un vettore, una serie di numeri, utilizzando una matrice di incorporamento. Diciamo che gli incorporamenti per ogni parola sono:
- Il : [0.2, 0.1, 0.3, 0.5]
- gatto : [0.6, 0.3, 0.1, 0.2]
- sat : [0.1, 0.8, 0.2, 0.3]
- su : [0.3, 0.1, 0.6, 0.4]
- il : [0.5, 0.2, 0.1, 0.4]
- mat : [0.2, 0.4, 0.7, 0.5]
Quindi, il trasformatore calcola un punteggio per ogni parola nella frase in base alla sua relazione con tutte le altre parole nella frase.
Questo viene fatto utilizzando il prodotto scalare dell'incorporamento di ogni parola con gli incorporamenti di tutte le altre parole nella frase.
Ad esempio, per calcolare il punteggio per la parola "gatto", prenderemmo il prodotto scalare del suo incorporamento con gli incorporamenti di tutte le altre parole:
- “ Il gatto “: 0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- “ gatto seduto “: 0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- “ gatto su “: 0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- “ gatto il “: 0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- " tappetino per gatti ": 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Questi punteggi indicano la rilevanza di ogni parola rispetto alla parola "gatto". Il trasformatore utilizza quindi questi punteggi per calcolare una somma ponderata delle parole incorporate, dove i pesi sono i punteggi.
Questo crea un vettore di contesto per la parola "gatto" che considera le relazioni tra tutte le parole nella frase. Questo processo viene ripetuto per ogni parola della frase.
Pensalo come il trasformatore che traccia una linea tra ogni parola nella frase in base al risultato di ogni calcolo. Alcune linee sono più tenui, altre meno.
Il trasformatore è un nuovo tipo di modello che utilizza solo l'attenzione senza alcuna elaborazione ricorrente. Questo lo rende molto più veloce e in grado di gestire più dati.
Come GPT utilizza i trasformatori
Potresti ricordare che nell'annuncio BERT di Google, si vantavano di aver permesso alla ricerca di comprendere l'intero contesto di un input. Questo è simile a come GPT può utilizzare i trasformatori.
Usiamo un'analogia.
Immagina di avere un milione di scimmie, ciascuna seduta davanti a una tastiera.
Ogni scimmia preme casualmente i tasti sulla tastiera, generando stringhe di lettere e simboli.
Alcune stringhe sono completamente senza senso, mentre altre potrebbero assomigliare a parole reali o persino a frasi coerenti.
Un giorno, uno degli addestratori del circo vede che una scimmia ha scritto "Essere o non essere", quindi l'addestratore dà un premio alla scimmia.
Le altre scimmie lo vedono e iniziano a provare a imitare la scimmia di successo, sperando in una sorpresa.
Col passare del tempo, alcune scimmie iniziano a produrre costantemente stringhe di testo migliori e più coerenti, mentre altre continuano a produrre parole senza senso.
Alla fine, le scimmie possono riconoscere e persino emulare schemi coerenti nel testo.
Gli LLM hanno un vantaggio sulle scimmie perché gli LLM vengono prima addestrati su miliardi di pezzi di testo. Possono già vedere i modelli. Capiscono anche i vettori e le relazioni tra questi pezzi di testo.
Ciò significa che possono utilizzare quei modelli e relazioni per generare un nuovo testo che assomigli al linguaggio naturale.
GPT, che sta per Generative Pre-trained Transformer, è un modello linguistico che utilizza i trasformatori per generare testo in linguaggio naturale.
È stato addestrato su un'enorme quantità di testo da Internet, che gli ha permesso di apprendere i modelli e le relazioni tra parole e frasi nel linguaggio naturale.
Il modello funziona prendendo in considerazione un prompt o poche parole di testo e utilizzando i trasformatori per prevedere quali parole dovrebbero venire dopo in base ai modelli che ha appreso dai suoi dati di addestramento.
Il modello continua a generare testo parola per parola, utilizzando il contesto delle parole precedenti per informare quelle successive.
GPT in azione
Uno dei vantaggi di GPT è che può generare testo in linguaggio naturale altamente coerente e contestualmente rilevante.
Questo ha molte applicazioni pratiche, come la generazione di descrizioni dei prodotti o la risposta alle domande del servizio clienti. Può anche essere usato in modo creativo, come generare poesie o racconti.
Tuttavia, è solo un modello linguistico. È addestrato sui dati e tali dati possono essere obsoleti o non corretti.
- Non ha alcuna fonte di conoscenza.
- Non può cercare in Internet.
- Non “sa” niente.
Indovina semplicemente quale parola verrà dopo.
Diamo un'occhiata ad alcuni esempi:
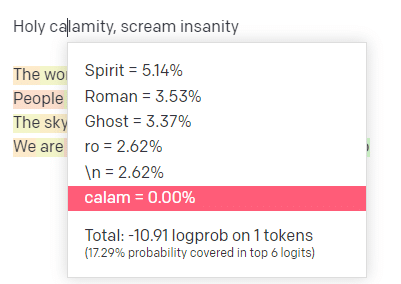
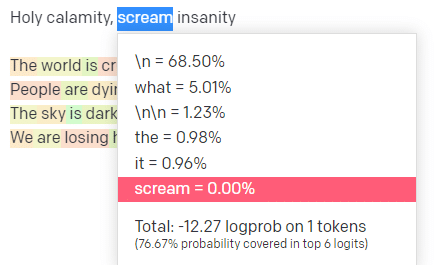
Nel parco giochi OpenAI, ho inserito la prima riga del classico brano Handsome Boy Modeling School "Holy calamity [[Bear Witness ii]]".
Ho inviato la risposta in modo che possiamo vedere la probabilità sia del mio input che delle linee di output. Quindi esaminiamo ogni parte di ciò che questo ci dice.
Per la prima parola/token, inserisco "Holy". Possiamo vedere che il prossimo input più atteso è Spirit, Roman e Ghost.
Possiamo anche vedere che i primi sei risultati coprono solo il 17,29% delle probabilità di ciò che verrà dopo: il che significa che ci sono circa l'82% di altre possibilità che non possiamo vedere in questa visualizzazione.
Discutiamo brevemente i diversi input che puoi utilizzare in questo e come influenzano il tuo output.
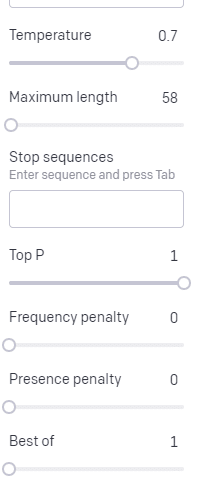
La temperatura è la probabilità con cui il modello acquisisce parole diverse da quelle con la probabilità più alta, P superiore è il modo in cui seleziona quelle parole.
Quindi, per l'input "Holy Calamity", la P in alto è il modo in cui selezioniamo il gruppo di token successivi [Ghost, Roman, Spirit] e la temperatura è la probabilità con cui andrà il token più probabile rispetto a una maggiore varietà.
Se la temperatura è più alta, è più probabile che scelga un token meno probabile .
Quindi una temperatura elevata e una P massima alta saranno probabilmente più selvagge. Sta scegliendo tra un'ampia varietà (P alta in alto) ed è più probabile che scelga gettoni sorprendenti.


Mentre una P superiore ad alta temperatura ma più bassa sceglierà opzioni sorprendenti da un campione più piccolo di possibilità:

E l'abbassamento della temperatura sceglie solo i token successivi più probabili:

Giocare con queste probabilità può, secondo me, darti una buona idea di come funzionano questi tipi di modelli.
Sta esaminando una raccolta di probabili selezioni successive basate su ciò che è già stato completato.
Cosa significa questo in realtà?
In poche parole, gli LLM raccolgono una raccolta di input, li scuotono e li trasformano in output.
Ho sentito persone scherzare sul fatto che sia così diverso dalle persone.
Ma non è come le persone: gli LLM non hanno una base di conoscenza. Non stanno estraendo informazioni su una cosa. Stanno indovinando una sequenza di parole basata sull'ultima.
Un altro esempio: pensa a una mela. Cosa ti viene in mente?
Forse puoi ruotarne uno nella tua mente.
Forse ricordi l'odore di un meleto, la dolcezza di una signora rosa, ecc.
Forse pensi a Steve Jobs.
Ora vediamo cosa restituisce un prompt "pensa a una mela".
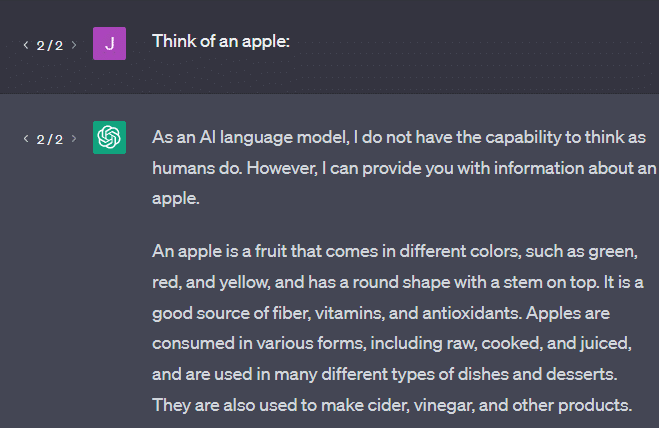
Potresti aver sentito le parole "Stochastic Parrots" fluttuare a questo punto.
Stochastic Parrots è un termine usato per descrivere LLM come GPT. Un pappagallo è un uccello che imita ciò che sente.
Quindi, i LLM sono come pappagalli in quanto raccolgono informazioni (parole) e producono qualcosa che assomiglia a ciò che hanno sentito. Ma sono anche stocastici , il che significa che usano la probabilità per indovinare cosa verrà dopo.
Gli LLM sono bravi a riconoscere schemi e relazioni tra le parole, ma non hanno una comprensione più profonda di ciò che stanno vedendo. Ecco perché sono così bravi a generare testi in linguaggio naturale ma non a comprenderli.
Buoni usi per un LLM
Gli LLM sono bravi in compiti più generalisti.
Puoi mostrargli del testo e, senza addestramento, può svolgere un'attività con quel testo.
Puoi lanciargli del testo e chiedere un'analisi del sentimento, chiedergli di trasferire quel testo in markup strutturato e fare un lavoro creativo (ad esempio, scrivere contorni).
Va bene per cose come il codice. Per molte attività, può quasi portarti lì.
Ma ancora una volta, si basa su probabilità e schemi. Quindi ci saranno momenti in cui raccoglierà schemi nel tuo input che non sai che ci sono.
Questo può essere positivo (vedere modelli che gli umani non possono), ma può anche essere negativo (perché ha risposto così?).
Inoltre, non ha accesso a nessun tipo di origine dati. I SEO che lo usano per cercare parole chiave di ranking se la passeranno male.
Non può cercare il traffico per una parola chiave. Non ha le informazioni per i dati delle parole chiave oltre a quelle che esistono.

La cosa eccitante di ChatGPT è che si tratta di un modello linguistico facilmente disponibile che puoi utilizzare immediatamente per varie attività. Ma non è senza avvertimenti.
Buoni usi per altri modelli ML
Sento che le persone dicono che stanno usando LLM per determinate attività, che altri algoritmi e tecniche di PNL possono fare meglio.

Facciamo un esempio, l'estrazione di parole chiave.
Se uso TF-IDF, o un'altra tecnica di parole chiave, per estrarre parole chiave da un corpus, so quali calcoli stanno andando in quella tecnica.
Ciò significa che i risultati saranno standard, riproducibili e so che saranno correlati specificamente a quel corpus.
Con LLM come ChatGPT, se richiedi l'estrazione di parole chiave, non stai necessariamente ottenendo le parole chiave estratte dal corpus. Stai ottenendo ciò che GPT pensa che sarebbe una risposta alle parole chiave corpus + extract.
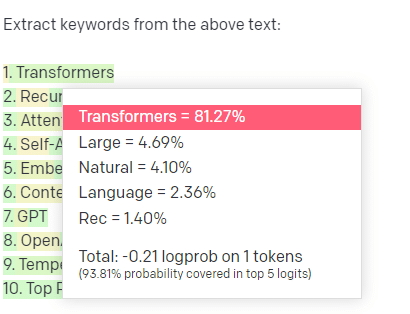
Questo è simile ad attività come il clustering o l'analisi del sentiment. Non stai necessariamente ottenendo il risultato perfetto con i parametri che hai impostato. Stai ottenendo ciò che c'è una certa probabilità sulla base di altri compiti simili.
Ancora una volta, gli LLM non hanno una base di conoscenza e nessuna informazione aggiornata. Spesso non possono eseguire ricerche sul Web e analizzano ciò che ottengono dalle informazioni come token statistici. Le restrizioni sulla durata della memoria di un LLM sono dovute a questi fattori.
Un'altra cosa è che questi modelli non possono pensare. Uso la parola "pensare" solo poche volte in questo pezzo perché è davvero difficile non usarla quando si parla di questi processi.
La tendenza è verso l'antropomorfismo, anche quando si discute di statistiche fantasiose.
Ma questo significa che se affidi un LLM a qualsiasi compito che richieda "pensiero", non ti fidi di una creatura pensante.
Ti stai fidando di un'analisi statistica di ciò con cui centinaia di tipi strani di Internet rispondono a token simili.
Se ti affidi agli abitanti di Internet con un'attività, puoi utilizzare un LLM. Altrimenti…
Cose che non dovrebbero mai essere modelli ML
Secondo quanto riferito, un chatbot eseguito attraverso un modello GPT (GPT-J) ha incoraggiato un uomo a uccidersi. La combinazione di fattori può causare danni reali, tra cui:
- Persone che antropomorfizzano queste risposte.
- Credendoli infallibili.
- Usandoli in luoghi in cui gli umani devono essere nella macchina.
- E altro ancora.
Mentre potresti pensare: “Sono un SEO. Non ho mano nei sistemi che potrebbero uccidere qualcuno!
Pensa alle pagine YMYL e a come Google promuove concetti come EEAT.
Google lo fa perché vuole infastidire i SEO o è perché non vuole la colpevolezza di quel danno?
Anche in sistemi con solide basi di conoscenza, si possono fare danni.
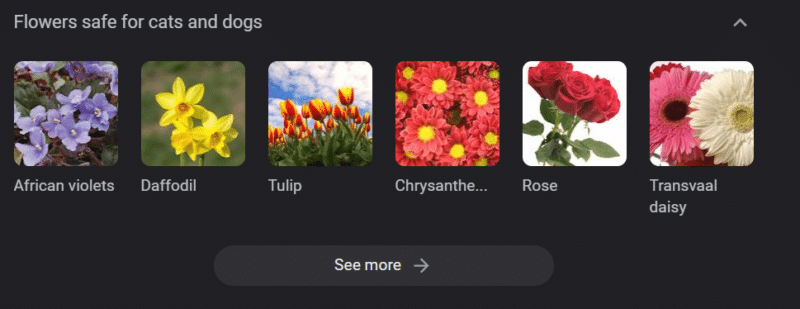
Quanto sopra è un carosello di conoscenza di Google per "fiori sicuri per cani e gatti". I narcisi sono in quella lista nonostante siano tossici per i gatti.
Supponiamo che tu stia generando contenuti per un sito Web veterinario su larga scala utilizzando GPT. Inserisci una serie di parole chiave e esegui il ping dell'API ChatGPT.
Hai un libero professionista che legge tutti i risultati e non è un esperto in materia. Non raccolgono un problema.
Pubblichi il risultato, che incoraggia l'acquisto di narcisi per i proprietari di gatti.
Uccidi il gatto di qualcuno.
Non direttamente. Forse non sanno nemmeno che era quel sito in particolare.
Forse gli altri siti veterinari iniziano a fare la stessa cosa e si nutrono a vicenda.
Il primo risultato di ricerca di Google per "i narcisi sono tossici per i gatti" è un sito che dice che non lo sono.
Altri freelance che leggono altri contenuti di intelligenza artificiale - pagine su pagine di contenuti di intelligenza artificiale - in realtà controllano i fatti. Ma i sistemi ora hanno informazioni errate.
Quando discuto di questo attuale boom dell'IA, cito molto Therac-25. È un famoso caso di studio di illeciti informatici.
Fondamentalmente, era una macchina per radioterapia, la prima a utilizzare solo meccanismi di blocco del computer. Un problema tecnico nel software significava che le persone ricevevano decine di migliaia di volte la dose di radiazioni che avrebbero dovuto.
Qualcosa che mi colpisce sempre è che l'azienda ha richiamato e ispezionato volontariamente questi modelli.
Ma presumevano che, poiché la tecnologia era avanzata e il software era "infallibile", il problema avesse a che fare con le parti meccaniche della macchina.
Pertanto, hanno riparato i meccanismi ma non hanno controllato il software e il Therac-25 è rimasto sul mercato.
Domande frequenti e idee sbagliate
Perché ChatGPT mi mente?
Una cosa che ho visto da alcune delle più grandi menti della nostra generazione e anche da influencer su Twitter è una lamentela che ChatGPT "mente" a loro. Ciò è dovuto a un paio di idee sbagliate in tandem:
- Che ChatGPT ha "desideri".
- Che ha una base di conoscenza.
- Che i tecnologi dietro la tecnologia hanno una sorta di agenda oltre a "fare soldi" o "fare una cosa interessante".
I pregiudizi sono presenti in ogni parte della tua vita quotidiana. Così sono le eccezioni a questi pregiudizi.
La maggior parte degli sviluppatori di software attualmente sono uomini: io sono uno sviluppatore di software e una donna.
Addestrare un'intelligenza artificiale basata su questa realtà la porterebbe sempre a presumere che gli sviluppatori di software siano uomini, il che non è vero.
Un famoso esempio è l'intelligenza artificiale del reclutamento di Amazon, addestrata sui curriculum di dipendenti Amazon di successo.
Ciò ha portato a scartare i curriculum dei college a maggioranza nera, anche se molti di quei dipendenti avrebbero potuto avere un enorme successo.
Per contrastare questi pregiudizi, strumenti come ChatGPT utilizzano livelli di messa a punto. Questo è il motivo per cui ottieni la risposta "Come modello di linguaggio AI, non posso ...".
Alcuni lavoratori in Kenya hanno dovuto affrontare centinaia di suggerimenti, alla ricerca di insulti, incitamento all'odio e risposte e suggerimenti semplicemente terribili.
Quindi è stato creato un livello di regolazione fine.
Perché non riesci a inventare insulti su Joe Biden? Perché puoi fare battute sessiste sugli uomini e non sulle donne?
Non è dovuto a pregiudizi liberali, ma a causa di migliaia di livelli di messa a punto che dicono a ChatGPT di non pronunciare la parola N.
Idealmente, ChatGPT sarebbe del tutto neutrale rispetto al mondo, ma ne ha anche bisogno per riflettere il mondo.
È un problema simile a quello che ha Google.
Ciò che è vero, ciò che rende felici le persone e ciò che rende una risposta corretta a un prompt sono spesso tutte cose molto diverse .
Perché ChatGPT presenta citazioni false?
Un'altra domanda che vedo emergere frequentemente riguarda le citazioni false. Perché alcuni di loro sono falsi e alcuni veri? Perché alcuni siti Web sono reali, ma le pagine sono false?
Si spera che, leggendo come funzionano i modelli statistici, tu possa analizzarlo. Ma ecco una breve spiegazione:
Sei un modello di linguaggio AI. Sei stato addestrato su un sacco di web.
Qualcuno ti dice di scrivere su una cosa tecnologica – diciamo Cumulative Layout Shift.
Non hai un sacco di esempi di documenti CLS, ma sai di cosa si tratta e conosci la forma generale di un articolo sulle tecnologie. Conosci lo schema di come appare questo tipo di articolo.

Quindi inizi con la tua risposta e ti imbatti in una sorta di problema. Nel modo in cui comprendi la scrittura tecnica, sai che un URL dovrebbe essere il prossimo nella tua frase.
Bene, da altri articoli CLS, sai che Google e GTMetrix sono spesso citati su CLS, quindi quelli sono facili.
Ma sai anche che i trucchi CSS sono spesso collegati negli articoli web: sai che di solito gli URL dei trucchi CSS hanno un certo aspetto: quindi puoi costruire un URL dei trucchi CSS come questo:
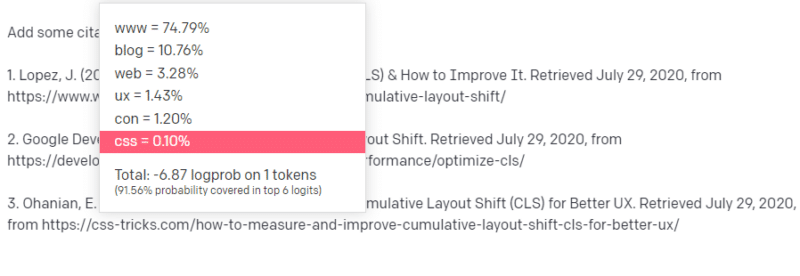
Il trucco è: ecco come vengono costruiti tutti gli URL, non solo quelli falsi:

Questo articolo di GTMetrix esiste: ma esiste perché probabilmente era una stringa di valori alla fine di questa frase.
GPT e modelli simili non sono in grado di distinguere tra una citazione vera e una falsa.
L'unico modo per eseguire tale modellazione è utilizzare altre fonti (basi di conoscenza, Python, ecc.) Per analizzare tale differenza e verificare i risultati.
Cos'è un "pappagallo stocastico"?
So di averlo già esaminato, ma vale la pena ripeterlo. I pappagalli stocastici sono un modo per descrivere cosa succede quando i grandi modelli linguistici sembrano di natura generalista.
Per il LLM, assurdità e realtà sono la stessa cosa. Vedono il mondo come un economista, come un mucchio di statistiche e numeri che descrivono la realtà.
Conosci la citazione: "Ci sono tre tipi di bugie: bugie, dannate bugie e statistiche".
Gli LLM sono un grande gruppo di statistiche.
Gli LLM sembrano coerenti, ma questo perché fondamentalmente vediamo le cose che sembrano umane come umane.
Allo stesso modo, il modello di chatbot offusca gran parte dei suggerimenti e delle informazioni necessarie affinché le risposte GPT siano pienamente coerenti.
Sono uno sviluppatore: provare a utilizzare LLM per eseguire il debug del mio codice ha risultati estremamente variabili. Se si tratta di un problema simile a quello che le persone hanno spesso riscontrato online, gli LLM possono rilevare e correggere tale risultato.
Se si tratta di un problema che non ha mai riscontrato prima o è una piccola parte del corpus, non risolverà nulla.
Perché GPT è migliore di un motore di ricerca?
L'ho formulato in modo piccante. Non credo che GPT sia migliore di un motore di ricerca. Mi preoccupa che le persone abbiano sostituito la ricerca con ChatGPT.
Una parte poco riconosciuta di ChatGPT è quanto esiste per seguire le istruzioni. Puoi chiedergli di fare praticamente qualsiasi cosa.
Ma ricorda, è tutto basato sulla parola statistica successiva in una frase, non sulla verità.
Quindi, se gli fai una domanda che non ha una buona risposta ma la fai in un modo a cui è obbligato a rispondere, otterrai una risposta scadente.
Avere una risposta pensata per te e intorno a te è più confortante, ma il mondo è una massa di esperienze.
Tutti gli input in un LLM sono trattati allo stesso modo: ma alcune persone hanno esperienza e la loro risposta sarà migliore di un melange di risposte di altre persone.
Un esperto vale più di mille pezzi di riflessione.
È questo l'alba dell'intelligenza artificiale? Skynet è qui?
Koko il Gorilla era una scimmia a cui era stato insegnato il linguaggio dei segni. I ricercatori in studi linguistici hanno fatto tonnellate di ricerche che dimostrano che alle scimmie si potrebbe insegnare la lingua.
Herbert Terrace ha poi scoperto che le scimmie non stavano mettendo insieme frasi o parole, ma semplicemente imitando i loro gestori umani.
Eliza era una terapista della macchina, uno dei primi chatterbot (chatbot).
La gente la vedeva come una persona: una terapista di cui si fidava e di cui si prendeva cura. Hanno chiesto ai ricercatori di stare da soli con lei.
Il linguaggio fa qualcosa di molto specifico per il cervello delle persone. Le persone sentono qualcosa comunicare e si aspettano che ci sia un pensiero dietro.
Gli LLM sono impressionanti ma in un modo che mostra l'ampiezza dei risultati umani.
Gli LLM non hanno volontà. Non possono scappare. Non possono provare a conquistare il mondo.
Sono uno specchio: un riflesso delle persone e dell'utente in particolare.
L'unico pensiero che c'è è una rappresentazione statistica dell'inconscio collettivo.
GPT ha imparato un'intera lingua da solo?
Sundar Pichai, CEO di Google, è andato su "60 Minutes" e ha affermato che il modello linguistico di Google ha imparato il bengalese.
Il modello è stato addestrato su quei testi. Non è corretto che "parli una lingua straniera che non è mai stato addestrato a conoscere".
Ci sono momenti in cui l'IA fa cose inaspettate, ma questo di per sé è previsto.
Quando guardi modelli e statistiche su larga scala, ci saranno necessariamente momenti in cui questi modelli rivelano qualcosa di sorprendente.
Ciò che questo rivela veramente è che molti dei C-suite e del marketing che vendono AI e ML non capiscono effettivamente come funzionano i sistemi.
Ho sentito alcune persone molto intelligenti parlare di proprietà emergenti, intelligenza artificiale generale (AGI) e altre cose futuristiche.
Potrei essere solo un semplice ingegnere operativo ML di campagna, ma mostra quanta pubblicità, promesse, fantascienza e realtà vengono messe insieme quando si parla di questi sistemi.
Elizabeth Holmes, la famigerata fondatrice di Theranos, fu crocifissa per aver fatto promesse che non potevano essere mantenute.
Ma il ciclo di fare promesse impossibili fa parte della cultura delle startup e del guadagno. La differenza tra Theranos e l'hype AI è che Theranos non poteva fingere a lungo.
GPT è una scatola nera? Cosa succede ai miei dati in GPT?
GPT è, come modello, non una scatola nera. Puoi vedere il codice sorgente per GPT-J e GPT-Neo.
Il GPT di OpenAI è, tuttavia, una scatola nera. OpenAI non ha e probabilmente proverà a non rilasciare il suo modello, poiché Google non rilascia l'algoritmo.
Ma non perché l'algoritmo sia troppo pericoloso. Se fosse vero, non venderebbero abbonamenti API a nessuno sciocco con un computer. È a causa del valore di quella base di codice proprietaria.
Quando utilizzi gli strumenti di OpenAI, stai addestrando e alimentando la loro API con i tuoi input. Ciò significa che tutto ciò che metti in OpenAI lo alimenta.
Ciò significa che le persone che hanno utilizzato il modello GPT di OpenAI sui dati dei pazienti per aiutare a scrivere note e altre cose hanno violato l'HIPAA. Quelle informazioni sono ora nel modello e sarà estremamente difficile estrarle.
Poiché così tante persone hanno difficoltà a capirlo, è molto probabile che il modello contenga tonnellate di dati privati, che aspettano solo il prompt giusto per rilasciarlo.
Perché GPT è formato sull'incitamento all'odio?
Un'altra cosa che emerge spesso è che il corpus di testo su cui è stato addestrato GPT include l'incitamento all'odio.
In una certa misura, OpenAI deve addestrare i suoi modelli a rispondere all'incitamento all'odio, quindi deve disporre di un corpus che includa alcuni di questi termini.
OpenAI ha affermato di cancellare quel tipo di incitamento all'odio dal sistema, ma i documenti di origine includono 4chan e tonnellate di siti di odio.
Striscia il web, assorbi il pregiudizio.
Non esiste un modo semplice per evitarlo. Come puoi fare in modo che qualcosa riconosca o comprenda l'odio, i pregiudizi e la violenza senza averlo come parte del tuo set di allenamento?
Come si evitano i pregiudizi e si comprendono i pregiudizi impliciti ed espliciti quando si è un agente macchina che seleziona statisticamente il token successivo in una frase?
TL; DR
L'hype e la disinformazione sono attualmente i principali elementi del boom dell'IA. Ciò non significa che non ci siano usi legittimi: questa tecnologia è sorprendente e utile.
Ma il modo in cui la tecnologia viene commercializzata e il modo in cui le persone la utilizzano possono favorire la disinformazione, il plagio e persino causare danni diretti.
Non usare gli LLM quando la vita è in pericolo. Non utilizzare LLM quando un algoritmo diverso farebbe meglio. Non farti ingannare dall'hype.
Capire cosa sono e cosa non sono gli LLM è necessario
Raccomando questa intervista di Adam Conover con Emily Bender e Timnit Gebru.
Gli LLM possono essere strumenti incredibili se usati correttamente. Esistono molti modi in cui puoi utilizzare gli LLM e ancora più modi per abusare degli LLM.
ChatGPT non è tuo amico. È un mucchio di statistiche. AGI non è "già qui".
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.