
Spark vs Hadoop: quale framework per i big data migliorerà il tuo business?
Pubblicato: 2019-09-24“I dati sono il carburante dell'economia digitale”
Con le aziende moderne che fanno affidamento su un mucchio di dati per comprendere meglio i propri consumatori e il mercato, le tecnologie come i Big Data stanno guadagnando un enorme slancio.
I Big Data, proprio come l'IA, non solo sono entrati nell'elenco delle principali tendenze tecnologiche per il 2020 , ma dovrebbero essere abbracciati sia dalle startup che dalle aziende Fortune 500 per godere di una crescita esponenziale del business e garantire una maggiore fidelizzazione dei clienti. Una chiara indicazione di ciò è che si prevede che il mercato dei Big Data raggiungerà i 103 miliardi di dollari entro il 2027.
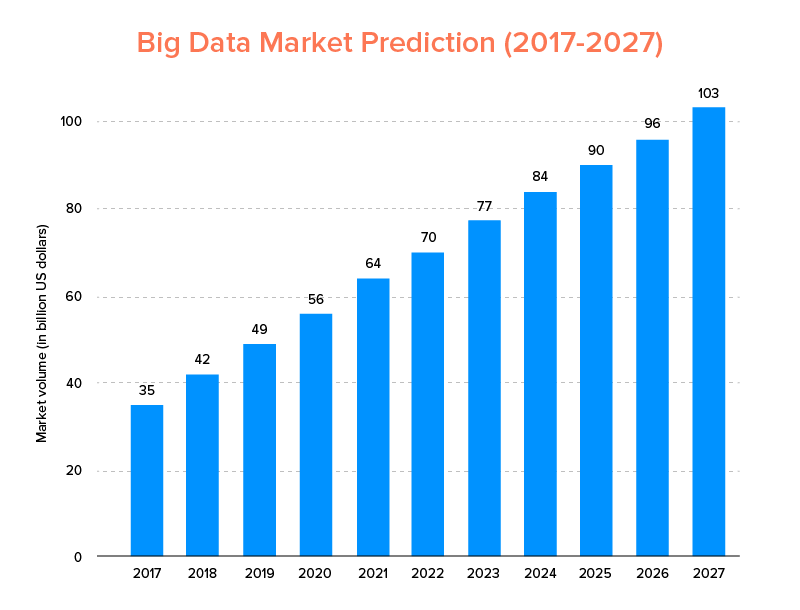
Ora, mentre questo da un lato tutti sono fortemente motivati a sostituire i loro tradizionali strumenti di analisi dei dati con i Big Data, quelli che preparano il terreno per il progresso di Blockchain e AI, sono anche confusi sulla scelta dello strumento Big Data giusto. Stanno affrontando il dilemma di scegliere tra Apache Hadoop e Spark, i due titani del mondo dei Big Data.
Quindi, considerando questo pensiero, oggi tratteremo un articolo su Apache Spark vs Hadoop e ti aiuteremo a determinare quale è l'opzione giusta per le tue esigenze.
Ma, in primo luogo, facciamo una breve introduzione di ciò che è Hadoop e Spark.
Apache Hadoop è un framework open source, distribuito e basato su Java che consente agli utenti di archiviare ed elaborare big data su più cluster di computer utilizzando semplici costrutti di programmazione. Comprende vari moduli che lavorano insieme per offrire un'esperienza migliorata, che sono: -
- Hadoop comune
- File system distribuito Hadoop (HDFS)
- FILATO Hadoop
- Hadoop MapReduce
Considerando che Apache Spark è un framework di big data distribuito open source per il calcolo dei cluster che è "facile da usare" e offre servizi più veloci.
I due framework di big data sono supportati da numerose grandi aziende per l'insieme di opportunità che offrono.
Vantaggi di Hadoop Big Data Framework
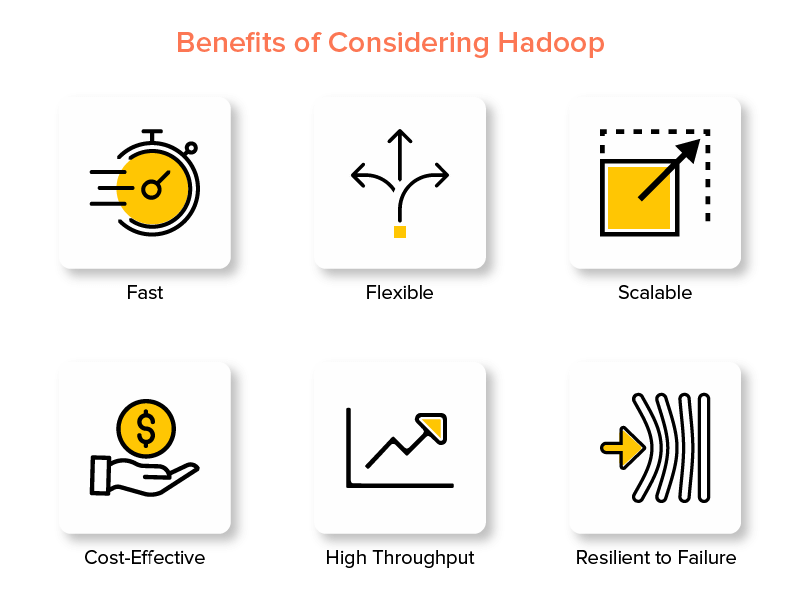
1. Veloce
Una delle caratteristiche di Hadoop che lo rende popolare nel mondo dei big data è che è veloce.
Il suo metodo di archiviazione si basa su un file system distribuito che 'mappa' principalmente i dati ovunque si trovino su un cluster. Inoltre, i dati e gli strumenti utilizzati per l'elaborazione dei dati sono generalmente disponibili sullo stesso server, il che rende l'elaborazione dei dati un'attività semplice e veloce.
In effetti, è stato riscontrato che Hadoop può elaborare terabyte di dati non strutturati in pochi minuti, mentre petabyte in poche ore.
2. Flessibile
Hadoop, a differenza dei tradizionali strumenti di elaborazione dati, offre flessibilità di fascia alta.
Consente alle aziende di raccogliere dati da diverse fonti (come social media, e-mail, ecc.), lavorare con diversi tipi di dati (sia strutturati che non strutturati) e ottenere informazioni preziose da utilizzare ulteriormente per vari scopi (come elaborazione di registri, analisi di campagne di mercato, rilevamento delle frodi, ecc.).
3. Scalabile
Un altro vantaggio di Hadoop è che è altamente scalabile. La piattaforma, a differenza dei tradizionali sistemi di database relazionali (RDBMS) , consente alle aziende di archiviare e distribuire grandi set di dati da centinaia di server che operano in parallelo.
4. Conveniente
Apache Hadoop, rispetto ad altri strumenti di analisi dei big data, è molto economico. Questo perché non richiede alcuna macchina specializzata; funziona su un gruppo di hardware di base. Inoltre, è più facile aggiungere più nodi a lungo termine.
Ciò significa che un caso aumenta facilmente i nodi senza subire tempi di inattività dei requisiti di pre-pianificazione.
5. Alta produttività
Nel caso del framework Hadoop, i dati vengono archiviati in modo distribuito in modo tale che un piccolo lavoro venga suddiviso in più blocchi di dati in parallelo. Ciò rende più facile per le aziende svolgere più lavori in meno tempo, il che alla fine si traduce in una maggiore produttività.
6. Resiliente al fallimento
Ultimo ma non meno importante, Hadoop offre opzioni di elevata tolleranza ai guasti che aiutano a mitigare le conseguenze del guasto. Memorizza una replica di ogni blocco che consente di recuperare i dati ogni volta che un nodo si interrompe.
Svantaggi di Hadoop Framework
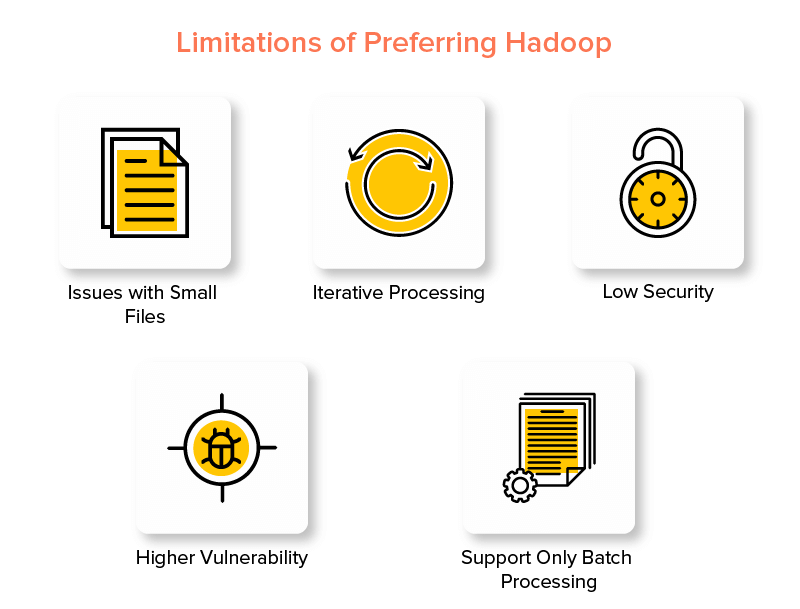
1. Problemi con i file di piccole dimensioni
Il più grande svantaggio di considerare Hadoop per l'analisi dei big data è che non ha il potenziale per supportare la lettura casuale di piccoli file in modo efficiente ed efficace.
Il motivo alla base di ciò è che un file di piccole dimensioni ha dimensioni di memoria relativamente inferiori rispetto alle dimensioni del blocco HDFS. In uno scenario del genere, se si archivia un gran numero di piccoli file, ci sono maggiori possibilità di sovraccarico di NameNode che memorizza lo spazio dei nomi di HDFS, il che praticamente non è una buona idea.
2. Elaborazione iterativa
Il flusso di dati nel framework Hadoop dei big data ha la forma di una catena, in modo tale che l'output di uno diventi l'input di un altro stadio. Considerando che il flusso di dati nell'elaborazione iterativa è di natura ciclica.
Per questo motivo, Hadoop è una scelta inadatta per le soluzioni basate sull'apprendimento automatico o sull'elaborazione iterativa.
3. Bassa sicurezza
Un altro svantaggio dell'utilizzo del framework Hadoop è che offre funzionalità di sicurezza inferiori.
Il framework, ad esempio, ha il modello di sicurezza disabilitato per impostazione predefinita. Se qualcuno che utilizza questo strumento per big data non sa come abilitarlo, i suoi dati potrebbero essere maggiormente a rischio di essere rubati/utilizzati in modo improprio. Inoltre, Hadoop non fornisce la funzionalità di crittografia a livello di archiviazione e rete, il che aumenta ancora una volta le possibilità di minaccia di violazione dei dati.
4. Maggiore vulnerabilità
Il framework Hadoop è scritto in Java, il linguaggio di programmazione più popolare ma ampiamente sfruttato. Ciò semplifica l'accesso dei criminali informatici alle soluzioni basate su Hadoop e l'uso improprio dei dati sensibili.
5. Supporto solo per l'elaborazione in batch
A differenza di vari altri framework di big data, Hadoop non elabora i dati in streaming. Supporta solo l'elaborazione batch e il motivo è che MapReduce non riesce a sfruttare al massimo la memoria del cluster Hadoop.
Anche se questo riguarda Hadoop, le sue caratteristiche e i suoi svantaggi, diamo un'occhiata ai pro e ai contro di Spark per trovare facilmente la differenza tra i due.
Vantaggi di Apache Spark Framework
1. Dinamico in natura
Poiché Apache Spark offre circa 80 operatori di alto livello, può essere utilizzato per elaborare i dati in modo dinamico. Può essere considerato il giusto strumento per i big data per sviluppare e gestire app parallele.
2. Potente
Grazie alla sua capacità di elaborazione dei dati in memoria a bassa latenza e alla disponibilità di varie librerie integrate per algoritmi di machine learning e analisi dei grafi, può gestire varie sfide di analisi. Questo lo rende una potente opzione per i big data sul mercato con cui andare.
3. Analisi avanzate
Un'altra caratteristica distintiva di Spark è che non solo incoraggia "MAP" e "riduce", ma supporta anche Machine Learning (ML), query SQL, algoritmi Graph e Streaming di dati. Questo lo rende adatto per godere di analisi avanzate.
4. Riutilizzabilità
A differenza di Hadoop, il codice Spark può essere riutilizzato per l'elaborazione in batch, eseguire query ad hoc sullo stato del flusso, unire il flusso rispetto ai dati storici e altro ancora.
5. Elaborazione del flusso in tempo reale
Un altro vantaggio dell'utilizzo di Apache Spark è che consente la gestione e l'elaborazione dei dati in tempo reale.
6. Supporto multilingue
Ultimo ma non meno importante, questo strumento di analisi dei big data supporta più linguaggi per la codifica, inclusi Java, Python e Scala.
Limitazioni dello strumento Spark Big Data

1. Nessun processo di gestione dei file
Il principale svantaggio di utilizzare Apache Spark è che non dispone di un proprio sistema di gestione dei file. Si basa su altre piattaforme come Hadoop per soddisfare questo requisito.
2. Pochi algoritmi
Apache Spark è anche in ritardo rispetto ad altri framework di big data se si considera la disponibilità di algoritmi come la distanza di Tanimoto.
3. Problema con i file di piccole dimensioni
Un altro svantaggio dell'utilizzo di Spark è che non gestisce i file di piccole dimensioni in modo efficiente.
Questo perché funziona con Hadoop Distributed File System (HDFS) che trova più facile gestire un numero limitato di file di grandi dimensioni su molti file piccoli.
4. Nessun processo di ottimizzazione automatico
A differenza di vari altri big data e piattaforme basate su cloud, Spark non ha alcun processo di ottimizzazione del codice automatico. Si deve ottimizzare il codice solo manualmente.
5. Non adatto per ambienti multiutente
Poiché Apache Spark non può gestire più utenti contemporaneamente, non funziona in modo efficiente in un ambiente multiutente. Qualcosa che di nuovo si aggiunge ai suoi limiti.
Con le basi di entrambi i framework di big data coperti, è probabile che tu speri di familiarizzare con le differenze tra Spark e Hadoop.
Quindi, non aspettiamo oltre e dirigiamoci verso il loro confronto per vedere quale guida la battaglia "Spark vs Hadoop".
Spark vs Hadoop: come i due strumenti per i big data si accumulano l'uno contro l'altro
[ID tabella=38 /]
1. Architettura
Quando si tratta di architettura Spark e Hadoop, quest'ultima è in testa anche quando entrambe operano in ambienti di calcolo distribuito.
Questo perché l'architettura di Hadoop, a differenza di Spark, ha due elementi principali: HDFS (Hadoop Distributed File System) e YARN (Yet Another Resource Negotiator). Qui, HDFS gestisce l'archiviazione di big data su vari nodi, mentre YARN si occupa dell'elaborazione delle attività tramite l'allocazione delle risorse e i meccanismi di pianificazione dei lavori. Questi componenti vengono quindi ulteriormente suddivisi in più componenti per fornire soluzioni migliori con servizi come la tolleranza ai guasti.
2. Facilità d'uso
Apache Spark consente agli sviluppatori di introdurre varie API intuitive come quella per Scala, Python, R, Java e Spark SQL nel loro ambiente di sviluppo. Inoltre, viene caricato con una modalità interattiva che supporta utenti e sviluppatori. Questo lo rende facile da usare e con una curva di apprendimento bassa.
Considerando che, quando si parla di Hadoop, offre componenti aggiuntivi per supportare gli utenti, ma non una modalità interattiva. Questo fa sì che Spark vinca su Hadoop in questa battaglia sui "big data".
3. Tolleranza ai guasti e sicurezza
Mentre sia Apache Spark che Hadoop MapReduce offrono funzionalità di tolleranza agli errori, quest'ultimo vince la battaglia.
Questo perché è necessario ricominciare da zero nel caso in cui un processo si arresti in modo anomalo durante l'operazione nell'ambiente Spark. Ma, quando si tratta di Hadoop, possono continuare dal punto dell'incidente stesso.
4. Prestazioni
Quando si tratta di considerare le prestazioni di Spark vs MapReduce, il primo vince sul secondo.
Il framework Spark è in grado di funzionare 10 volte più velocemente su disco e 100 volte in memoria. Ciò consente di gestire 100 TB di dati 3 volte più velocemente di Hadoop MapReduce.
5. Trattamento dei dati
Un altro fattore da considerare durante il confronto tra Apache Spark e Hadoop è l'elaborazione dei dati.
Mentre Apache Hadoop offre un'opportunità solo per l'elaborazione in batch, l'altro framework per big data consente di lavorare con l'elaborazione interattiva, iterativa, di flusso, grafica e batch. Qualcosa che dimostri che Spark è un'opzione migliore per usufruire di migliori servizi di elaborazione dati.
6. Compatibilità
La compatibilità di Spark e Hadoop MapReduce è in qualche modo la stessa.
Sebbene a volte entrambi i framework di big data agiscano come applicazioni autonome, possono anche lavorare insieme. Spark può funzionare in modo efficiente su Hadoop YARN, mentre Hadoop può integrarsi facilmente con Sqoop e Flume. Per questo motivo, entrambi supportano le origini dati e i formati file degli altri.
7. Sicurezza
L'ambiente Spark è caricato con diverse funzionalità di sicurezza come la registrazione degli eventi e l'uso di filtri servlet javax per la salvaguardia delle UI web. Inoltre, incoraggia l'autenticazione tramite segreto condiviso e può sfruttare il potenziale dei permessi dei file HDFS, della crittografia tra modalità e Kerberos se integrato con YARN e HDFS.
Considerando che Hadoop supporta l'autenticazione Kerberos , l' autenticazione di terze parti, i permessi dei file convenzionali e gli elenchi di controllo degli accessi e altro, il che alla fine offre risultati di sicurezza migliori.
Quindi, quando si considera il confronto tra Spark e Hadoop in termini di sicurezza, quest'ultimo è in testa.
8. Rapporto costo-efficacia
Quando si confronta Hadoop e Spark, il primo ha bisogno di più memoria su disco mentre il secondo richiede più RAM. Inoltre, poiché Spark è piuttosto nuovo rispetto ad Apache Hadoop, gli sviluppatori che lavorano con Spark sono più rari.
Questo rende il lavoro con Spark un affare costoso. Ciò significa che Hadoop offre soluzioni convenienti quando ci si concentra sui costi Hadoop vs Spark.
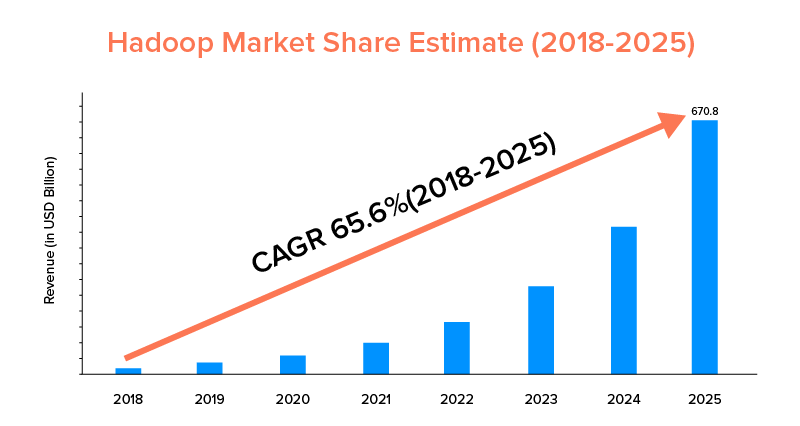
9. Ambito di mercato
Sebbene sia Apache Spark che Hadoop siano supportati da grandi aziende e siano stati utilizzati per scopi diversi, quest'ultimo è in testa in termini di portata del mercato.
Secondo le statistiche di mercato, si prevede che il mercato Apache Hadoop crescerà con un CAGR del 65,6% nel periodo dal 2018 al 2025, rispetto a Spark con un CAGR del solo 33,9%.
Sebbene questi fattori aiuteranno a determinare lo strumento per big data giusto per la tua azienda, è redditizio familiarizzare con i loro casi d'uso. Quindi, copriamo qui.
Casi d'uso di Apache Spark Framework
Questo strumento per i big data è adottato dalle aziende quando desiderano:
- Trasmetti e analizza i dati in tempo reale.
- Assapora la potenza dell'apprendimento automatico.
- Lavora con l'analisi interattiva.
- Introduci Fog ed Edge Computing nel loro modello di business.
Casi d'uso di Apache Hadoop Framework
Hadoop è preferito dalle startup e dalle imprese quando vogliono: -
- Analizza i dati di archivio.
- Goditi migliori opzioni di trading e previsione finanziaria.
- Eseguire operazioni che comprendono hardware Commodity.
- Considera l'elaborazione dei dati lineare.
Con questo, speriamo che tu abbia deciso quale sia il vincitore della battaglia "Spark vs Hadoop" per quanto riguarda la tua attività. In caso contrario, sentiti libero di connetterti con i nostri esperti di Big Data per chiarire tutti i dubbi e ottenere servizi esemplari con una percentuale di successo più elevata.
DOMANDE FREQUENTI
1. Quale Big Data Framework scegliere?
La scelta dipende completamente dalle tue esigenze aziendali. Se ti stai concentrando su prestazioni, compatibilità dei dati e facilità d'uso, Spark è meglio di Hadoop. Considerando che, il framework per big data Hadoop è migliore quando ti concentri su architettura, sicurezza e rapporto costo-efficacia.
2. Qual è la differenza tra Hadoop e Spark?
Ci sono varie differenze tra Spark e Hadoop. Per esempio:-
- Spark è un fattore 100 volte superiore a quello di Hadoop MapReduce.
- Mentre Hadoop è impiegato per l'elaborazione in batch, Spark è pensato per l'elaborazione in batch, grafica, machine learning ed iterativa.
- Spark è compatto e più semplice del framework dei big data Hadoop.
- A differenza di Spark, Hadoop non supporta la memorizzazione nella cache dei dati.
3. Spark è meglio di Hadoop?
Spark è migliore di Hadoop quando il tuo obiettivo principale è la velocità e la sicurezza. Tuttavia, in altri casi, questo strumento di analisi dei big data è in ritardo rispetto ad Apache Hadoop.
4. Perché Spark è più veloce di Hadoop?
Spark è più veloce di Hadoop a causa del minor numero di cicli di lettura/scrittura su disco e della memorizzazione di dati intermedi in memoria.
5. A cosa serve Apache Spark?
Apache Spark viene utilizzato per l'analisi dei dati quando si desidera-
- Analizza i dati in tempo reale.
- Introduci ML e Fog Computing nel tuo modello di business.
- Lavora con l'analisi interattiva.