
TW-BERT: ponderazione dei termini delle query end-to-end e il futuro della Ricerca Google
Pubblicato: 2023-09-14La ricerca è difficile, come scrisse Seth Godin nel 2005.
Voglio dire, se pensiamo che la SEO sia difficile (e lo è), immagina se stessi cercando di costruire un motore di ricerca in un mondo in cui:
- Gli utenti variano notevolmente e cambiano le loro preferenze nel tempo.
- La tecnologia a cui accedono per la ricerca avanza ogni giorno.
- I concorrenti ti stanno costantemente alle calcagna.
Oltre a ciò, hai anche a che fare con fastidiosi SEO che cercano di ingannare il tuo algoritmo per ottenere informazioni su come ottimizzare al meglio per i tuoi visitatori.
Questo renderà le cose molto più difficili.
Ora immagina se le principali tecnologie a cui devi fare affidamento per avanzare presentassero i propri limiti e, forse peggio, costi enormi.
Bene, se sei uno degli autori dell'articolo recentemente pubblicato, "Ponderazione dei termini delle query end-to-end", vedi questa come un'opportunità per brillare.
Che cos'è la ponderazione dei termini della query end-to-end?
La ponderazione dei termini della query end-to-end si riferisce a un metodo in cui il peso di ciascun termine in una query viene determinato come parte del modello complessivo, senza fare affidamento su schemi di ponderazione dei termini tradizionali o programmati manualmente o su altri modelli indipendenti.
Che aspetto ha?
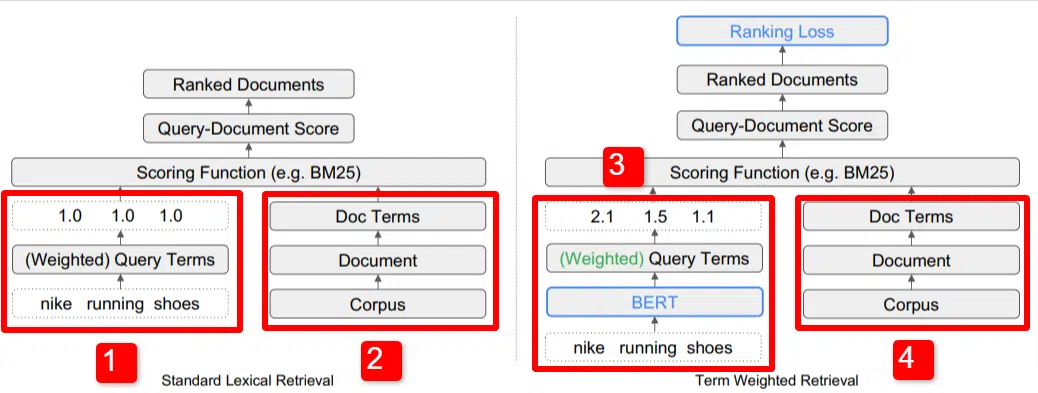
Qui vediamo un'illustrazione di uno dei principali differenziatori del modello delineato nel documento (Figura 1, in particolare).
Sul lato destro del modello standard (2) vediamo la stessa cosa che facciamo con il modello proposto (4), che è il corpus (insieme completo di documenti nell'indice), che porta ai documenti, che porta ai termini.
Questo illustra l'effettiva gerarchia del sistema, ma puoi immaginarla casualmente al contrario, dall'alto verso il basso. Abbiamo dei termini. Cerchiamo documenti con questi termini. Quei documenti sono nel corpus di tutti i documenti di cui siamo a conoscenza.
In basso a sinistra (1) nell'architettura IR (Information Retrieval) standard, noterai che non esiste un livello BERT. La query utilizzata nella loro illustrazione (scarpe da corsa nike) entra nel sistema e i pesi vengono calcolati indipendentemente dal modello e ad esso passati.
Nell'illustrazione qui, i pesi passano equamente tra le tre parole nella query. Tuttavia, non deve essere necessariamente così. È semplicemente un'illustrazione predefinita e buona.
Ciò che è importante capire è che i pesi vengono assegnati dall'esterno del modello e inseriti con la query. Tra poco spiegheremo perché questo è importante.
Se osserviamo la versione del peso del termine sul lato destro, vedrai che la query "scarpe da corsa nike" inserisce BERT (Term Weighting BERT, o TW-BERT, per essere precisi) che viene utilizzato per assegnare i pesi che sarebbe meglio applicarlo a quella query.
Da lì le cose seguono un percorso simile per entrambi, viene applicata una funzione di punteggio e i documenti vengono classificati. Ma c’è un passaggio finale fondamentale con il nuovo modello, che è davvero il punto di tutto, il calcolo della perdita in classifica.
Questo calcolo, a cui mi riferivo sopra, rende così importante la determinazione dei pesi all'interno del modello. Per capirlo meglio, facciamo una breve digressione per discutere le funzioni di perdita, che è importante per capire veramente cosa sta succedendo qui.
Cos'è una funzione di perdita?
Nell'apprendimento automatico, una funzione di perdita è fondamentalmente un calcolo di quanto sia sbagliato un sistema che cerca di imparare ad avvicinarsi il più possibile a una perdita zero.
Prendiamo ad esempio un modello progettato per determinare i prezzi delle case. Se inserisci tutte le statistiche della tua casa e ottieni un valore di $ 250.000, ma la tua casa viene venduta per $ 260.000, la differenza verrebbe considerata la perdita (che è un valore assoluto).
Attraverso un gran numero di esempi, al modello viene insegnato a minimizzare la perdita assegnando pesi diversi ai parametri forniti finché non ottiene il risultato migliore. Un parametro, in questo caso, può includere cose come metri quadrati, camere da letto, dimensioni del cortile, vicinanza a una scuola, ecc.
Ora torniamo alla ponderazione dei termini della query
Ripensando ai due esempi precedenti, ciò su cui dobbiamo concentrarci è la presenza di un modello BERT per fornire la ponderazione dei termini down-funnel del calcolo della perdita di ranking.
In altre parole, nei modelli tradizionali, la ponderazione dei termini veniva effettuata indipendentemente dal modello stesso e, pertanto, non poteva rispondere alla performance del modello complessivo. Non è riuscito a imparare come migliorare le ponderazioni.

Nel sistema proposto, questo cambia. La ponderazione viene effettuata all'interno del modello stesso e quindi, poiché il modello cerca di migliorare le proprie prestazioni e ridurre la funzione di perdita, ha questi quadranti aggiuntivi da girare per introdurre la ponderazione dei termini nell'equazione. Letteralmente.
ngrammi
TW-BERT non è progettato per funzionare in termini di parole, ma piuttosto di ngrammi.
Gli autori dell'articolo illustrano bene il motivo per cui usano gli ngrammi invece delle parole quando sottolineano che nella query "scarpe da corsa nike" se si pesano semplicemente le parole, una pagina con menzioni delle parole nike, running e scarpe potrebbe posizionarsi bene anche se si tratta di “calzini da corsa Nike” e “scarpe da skate”.
I metodi IR tradizionali utilizzano statistiche sulle query e statistiche sui documenti e potrebbero far emergere pagine con questo o problemi simili. I tentativi passati di affrontare questo problema si sono concentrati sulla co-occorrenza e sull’ordinamento.
In questo modello, gli ngrammi sono pesati come lo erano le parole nel nostro esempio precedente, quindi otteniamo qualcosa del tipo:
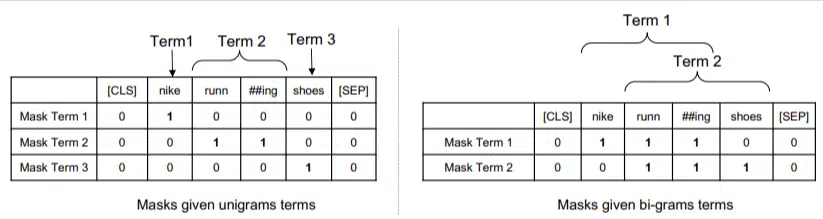
A sinistra vediamo come la query verrebbe pesata come unigrammi (ngrammi di 1 parola) e a destra, bi-grammi (ngrammi di 2 parole).
Il sistema, poiché la ponderazione è incorporata, può allenarsi su tutte le permutazioni per determinare i migliori ngrammi e anche il peso appropriato per ciascuno, invece di fare affidamento solo su statistiche come la frequenza.
Tiro zero
Una caratteristica importante di questo modello è la sua prestazione in compiti zero-short. Gli autori hanno testato su:
- Dataset MS MARCO – Dataset Microsoft per la classificazione di documenti e passaggi
- Set di dati TREC-COVID: articoli e studi sul COVID
- Robust04 – Articoli di notizie
- Nucleo comune: articoli didattici e post di blog
Avevano solo un numero limitato di query di valutazione e non ne usavano nessuna per la messa a punto, rendendolo un test zero-shot in quanto il modello non era addestrato a classificare i documenti in questi domini in modo specifico. I risultati sono stati:
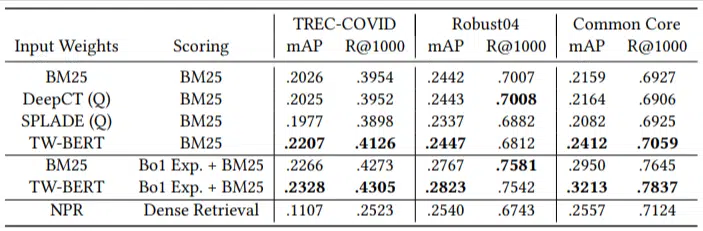
Ha sovraperformato nella maggior parte delle attività e ha funzionato meglio con query più brevi (da 1 a 10 parole).
Ed è plug-and-play!
OK, potrebbe essere eccessivamente semplificativo, ma gli autori scrivono:
“L’allineamento di TW-BERT con i punteggi dei motori di ricerca riduce al minimo le modifiche necessarie per integrarlo nelle applicazioni di produzione esistenti , mentre i metodi di ricerca esistenti basati sul deep learning richiederebbero un’ulteriore ottimizzazione dell’infrastruttura e dei requisiti hardware. I pesi appresi possono essere facilmente utilizzati dai lessical retriever standard e da altre tecniche di recupero come l’espansione delle query”.
Poiché TW-BERT è progettato per integrarsi nel sistema attuale, l’integrazione è molto più semplice ed economica rispetto ad altre opzioni.
Cosa significa tutto questo per te
Con i modelli di machine learning, è difficile prevedere ad esempio cosa puoi fare tu come SEO (a parte implementazioni visibili come Bard o ChatGPT).
Una permutazione di questo modello verrà senza dubbio implementata grazie ai suoi miglioramenti e alla facilità di implementazione (supponendo che le dichiarazioni siano accurate).
Detto questo, si tratta di un miglioramento della qualità della vita di Google, che migliorerà il posizionamento e i risultati zero-shot a un costo contenuto.
Tutto ciò su cui possiamo veramente contare è che, se implementato, i risultati migliori emergeranno in modo più affidabile. E questa è una buona notizia per i professionisti SEO.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.