
Cos’è l’intelligenza artificiale generativa e come funziona?
Pubblicato: 2023-09-26L’intelligenza artificiale generativa, un sottoinsieme dell’intelligenza artificiale, è emersa come una forza rivoluzionaria nel mondo della tecnologia. Ma cos'è esattamente? E perché sta guadagnando così tanta attenzione?
Questa guida approfondita approfondirà il funzionamento dei modelli di intelligenza artificiale generativa, cosa possono e non possono fare e le implicazioni di tutti questi elementi.
Cos’è l’IA generativa?
L’intelligenza artificiale generativa, o genAI, si riferisce a sistemi in grado di generare nuovi contenuti, siano essi testo, immagini, musica o persino video. Tradizionalmente, AI/ML significava tre cose: apprendimento supervisionato, non supervisionato e per rinforzo. Ciascuno fornisce approfondimenti basati sull'output del clustering.
I modelli di intelligenza artificiale non generativa effettuano calcoli in base all'input (come classificare un'immagine o tradurre una frase). Al contrario, i modelli generativi producono risultati “nuovi” come scrivere saggi, comporre musica, progettare grafica e persino creare volti umani realistici che non esistono nel mondo reale.
Le implicazioni dell’intelligenza artificiale generativa
L’ascesa dell’IA generativa ha implicazioni significative. Grazie alla capacità di generare contenuti, settori come l’intrattenimento, il design e il giornalismo stanno assistendo a un cambiamento di paradigma.
Ad esempio, le agenzie di stampa possono utilizzare l’intelligenza artificiale per redigere rapporti, mentre i designer possono ottenere suggerimenti per la grafica assistiti dall’intelligenza artificiale. L’intelligenza artificiale può generare centinaia di slogan pubblicitari in pochi secondi, indipendentemente dal fatto che tali opzioni siano valide o meno o no è un'altra questione.
L’intelligenza artificiale generativa può produrre contenuti su misura per i singoli utenti. Pensa a qualcosa come un'app musicale che compone una canzone unica in base al tuo umore o un'app di notizie che redige articoli su argomenti che ti interessano.
Il problema è che, poiché l’intelligenza artificiale svolge un ruolo sempre più importante nella creazione di contenuti, le domande sull’autenticità, sul diritto d’autore e sul valore della creatività umana diventano più prevalenti.
Come funziona l’intelligenza artificiale generativa?
L'intelligenza artificiale generativa, nella sua essenza, consiste nel prevedere il successivo dato in una sequenza, sia che si tratti della parola successiva in una frase o del pixel successivo in un'immagine. Analizziamo come si ottiene questo risultato.
Modelli statistici
I modelli statistici sono la spina dorsale della maggior parte dei sistemi di intelligenza artificiale. Usano equazioni matematiche per rappresentare la relazione tra diverse variabili.
Per l’intelligenza artificiale generativa, i modelli vengono addestrati a riconoscere modelli nei dati e quindi utilizzare questi modelli per generare dati nuovi e simili.
Se un modello viene addestrato su frasi inglesi, apprende la probabilità statistica che una parola segua un’altra, consentendogli di generare frasi coerenti.
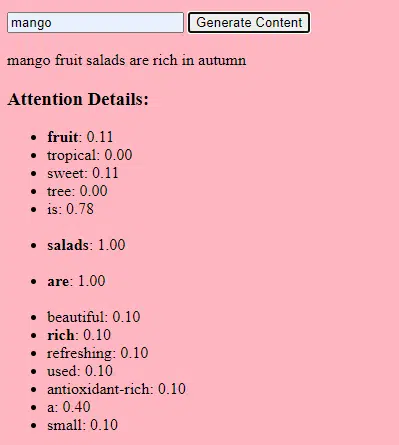
Raccolta di dati
Sia la qualità che la quantità dei dati sono cruciali. I modelli generativi vengono addestrati su vasti set di dati per comprendere i modelli.
Per un modello linguistico, ciò potrebbe significare l’acquisizione di miliardi di parole da libri, siti Web e altri testi.
Per un modello di immagine, ciò potrebbe significare analizzare milioni di immagini. Più diversificati e completi sono i dati di addestramento, migliore sarà la capacità del modello di generare risultati diversificati.
Come funzionano i trasformatori e l'attenzione
I trasformatori sono un tipo di architettura di rete neurale introdotta in un articolo del 2017 intitolato "L'attenzione è tutto ciò di cui hai bisogno" di Vaswani et al. Da allora sono diventati la base per la maggior parte dei modelli linguistici all'avanguardia. ChatGPT non funzionerebbe senza trasformatori.
Il meccanismo di “attenzione” consente al modello di concentrarsi su diverse parti dei dati di input, proprio come gli esseri umani prestano attenzione a parole specifiche quando comprendono una frase.
Questo meccanismo consente al modello di decidere quali parti dell'input sono rilevanti per un determinato compito, rendendolo altamente flessibile e potente.
Il codice seguente è una ripartizione fondamentale dei meccanismi del trasformatore, spiegando ogni pezzo in un inglese semplice.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)Nel codice, potresti avere una classe Transformer e una singola classe TransformerLayer. È come avere un progetto per un piano invece che per un intero edificio.
Questo pezzo di codice TransformerLayer mostra come funzionano componenti specifici, come l'attenzione multi-testa e disposizioni specifiche.
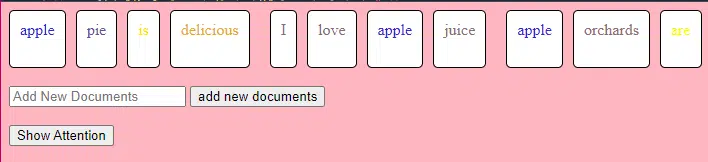
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Una rete neurale feed-forward è uno dei tipi più semplici di reti neurali artificiali. È costituito da un livello di input, uno o più livelli nascosti e un livello di output.
I dati fluiscono in una direzione: dallo strato di input, attraverso gli strati nascosti e allo strato di output. Non ci sono loop o cicli nella rete.
Nel contesto dell'architettura del trasformatore, la rete neurale feed-forward viene utilizzata dopo il meccanismo di attenzione in ogni strato. È una semplice trasformazione lineare a due livelli con un'attivazione ReLU nel mezzo.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Come funziona l'intelligenza artificiale generativa: in termini semplici
Pensa all’intelligenza artificiale generativa come al lancio di un dado ponderato. I dati di addestramento determinano i pesi (o probabilità).
Se il dado rappresenta la parola successiva in una frase, una parola che spesso segue la parola corrente nei dati di addestramento avrà un peso maggiore. Quindi, “cielo” potrebbe seguire “blu” più spesso di “banana”. Quando l'IA “lancia i dadi” per generare contenuti, è più probabile che scelga sequenze statisticamente più probabili in base al suo addestramento.
Quindi, come possono i LLM generare contenuti che “sembrano” originali?
Prendiamo un elenco falso - i "migliori regali Eid al-Fitr per i professionisti del content marketing" - e analizziamo come un LLM può generare questo elenco combinando spunti testuali da documenti su regali, Eid e contenuti di marketing.
Prima dell’elaborazione, il testo viene suddiviso in parti più piccole chiamate “token”. Questi token possono essere corti quanto un carattere o lunghi quanto una parola.
Esempio: “Eid al-Fitr è una celebrazione” diventa [“Eid”, “al-Fitr”, “è”, “a”, “celebrazione”].
Ciò consente al modello di lavorare con porzioni di testo gestibili e di comprendere la struttura delle frasi.
Ogni token viene quindi convertito in un vettore (un elenco di numeri) utilizzando gli incorporamenti. Questi vettori catturano il significato e il contesto di ogni parola.
La codifica posizionale aggiunge informazioni a ciascun vettore di parole sulla sua posizione nella frase, garantendo che il modello non perda queste informazioni sull'ordine.
Quindi utilizziamo un meccanismo di attenzione : questo consente al modello di concentrarsi su diverse parti del testo di input quando genera un output. Se ricordi BERT, questo è ciò che è stato così entusiasmante per i Googler di BERT.
Se il nostro modello ha visto testi sui “ doni ” e sa che le persone fanno regali durante le celebrazioni , e ha anche visto testi sull’“ Eid al-Fitr ” come una celebrazione significativa, presterà “ attenzione ” a queste connessioni.
Allo stesso modo, se ha visto testi sui “ content marketer ” che necessitano di strumenti o risorse specifici, può collegare l’idea di “ regali ” a “content marketer ”.

Ora possiamo combinare i contesti: mentre il modello elabora il testo di input attraverso più livelli Transformer, combina i contesti appresi.
Quindi, anche se i testi originali non menzionavano mai “regali Eid al-Fitr per i marketer di contenuti”, il modello può riunire i concetti di “Eid al-Fitr”, “regali” e “marketing di contenuti” per generare questo contenuto.
Questo perché ha appreso i contesti più ampi attorno a ciascuno di questi termini.
Dopo aver elaborato l'input attraverso il meccanismo di attenzione e le reti feed-forward in ogni strato Transformer, il modello produce una distribuzione di probabilità sul suo vocabolario per la parola successiva nella sequenza.
Si potrebbe pensare che dopo parole come “migliore” e “Eid al-Fitr”, la parola “regali” abbia un’alta probabilità di venire dopo. Allo stesso modo, potrebbe associare i “regali” a potenziali destinatari come “operatori di marketing di contenuti”.
Ottieni la ricerca quotidiana di newsletter su cui fanno affidamento gli esperti di marketing.
Vedi i termini.
Come vengono costruiti i modelli linguistici di grandi dimensioni
Il viaggio da un modello di trasformatore di base a un sofisticato modello di linguaggio di grandi dimensioni (LLM) come GPT-3 o BERT comporta l’ampliamento e il perfezionamento di vari componenti.
Ecco una ripartizione passo passo:
Gli LLM sono addestrati su grandi quantità di dati di testo. È difficile spiegare quanto siano vasti questi dati.
Il set di dati C4, punto di partenza per molti LLM, è composto da 750 GB di dati di testo. Sono 805.306.368.000 byte: un sacco di informazioni. Questi dati possono includere libri, articoli, siti Web, forum, sezioni di commenti e altre fonti.
Quanto più vari e completi sono i dati, tanto migliori saranno le capacità di comprensione e generalizzazione del modello.
Mentre l’architettura di base del trasformatore rimane la base, gli LLM hanno un numero significativamente maggiore di parametri. GPT-3, ad esempio, ha 175 miliardi di parametri. In questo caso, i parametri si riferiscono ai pesi e ai pregiudizi nella rete neurale appresi durante il processo di addestramento.
Nel deep learning, un modello viene addestrato a fare previsioni regolando questi parametri per ridurre la differenza tra le sue previsioni e i risultati effettivi.

Il processo di regolazione di questi parametri è chiamato ottimizzazione, che utilizza algoritmi come la discesa del gradiente.
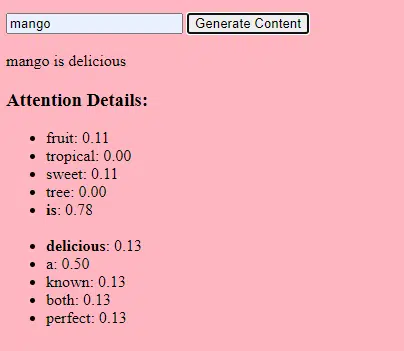
- Pesi: questi sono valori nella rete neurale che trasformano i dati di input all'interno degli strati della rete. Vengono adattati durante l'addestramento per ottimizzare l'output del modello. Ad ogni connessione tra neuroni di strati adiacenti è associato un peso.
- Bias: questi sono anche valori nella rete neurale che vengono aggiunti all'output della trasformazione di un livello. Forniscono un ulteriore grado di libertà al modello, consentendogli di adattarsi meglio ai dati di addestramento. Ogni neurone in uno strato ha un bias associato.
Questo ridimensionamento consente al modello di archiviare ed elaborare modelli e relazioni più complessi nei dati.
L'elevato numero di parametri significa anche che il modello richiede una notevole potenza di calcolo e memoria per l'addestramento e l'inferenza. Questo è il motivo per cui l'addestramento di tali modelli richiede molte risorse e in genere utilizza hardware specializzato come GPU o TPU.
Il modello è addestrato a prevedere la parola successiva in una sequenza utilizzando potenti risorse computazionali. Adatta i suoi parametri interni in base agli errori che commette, migliorando continuamente le sue previsioni.
Meccanismi di attenzione come quelli di cui abbiamo discusso sono fondamentali per i LLM. Consentono al modello di concentrarsi su diverse parti dell'input durante la generazione dell'output.
Valutando l'importanza delle diverse parole in un contesto, i meccanismi di attenzione consentono al modello di generare testo coerente e contestualmente rilevante. Farlo su questa scala su vasta scala consente ai LLM di lavorare come fanno.
In che modo un trasformatore prevede il testo?
I trasformatori prevedono il testo elaborando i token di input attraverso più livelli, ciascuno dotato di meccanismi di attenzione e reti di feed-forward.
Dopo l'elaborazione, il modello produce una distribuzione di probabilità sul suo vocabolario per la parola successiva nella sequenza. La parola con la probabilità più alta viene generalmente selezionata come previsione.
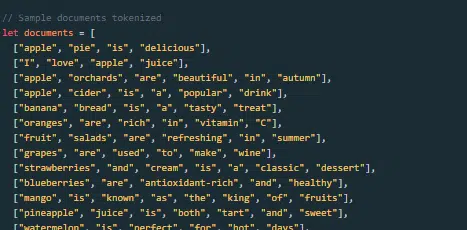
Come viene costruito e addestrato un grande modello linguistico?
Costruire un LLM comporta la raccolta di dati, la loro pulizia, l'addestramento del modello, la messa a punto del modello e test vigorosi e continui.
Il modello viene inizialmente addestrato su un vasto corpus per prevedere la parola successiva in una sequenza. Questa fase consente al modello di apprendere connessioni tra parole che riprendono schemi grammaticali, relazioni che possono rappresentare fatti sul mondo e connessioni che sembrano ragionamenti logici. Queste connessioni consentono inoltre di rilevare i pregiudizi presenti nei dati di addestramento.
Dopo la formazione preliminare, il modello viene perfezionato su un set di dati più ristretto, spesso con revisori umani che seguono le linee guida.
La messa a punto è un passaggio cruciale nella creazione di LLM. Implica l'addestramento del modello preaddestrato su un set di dati o un'attività più specifica. Prendiamo come esempio ChatGPT.
Se hai giocato con i modelli GPT, sai che il suggerimento è meno "scrivi questa cosa" e più simile
- Suggerimento: C'era una volta
- Continuazione: C'era un mago malvagio in cima a una torre.
- Continuazione: C'era un mago malvagio in cima a una torre.
- Suggerimento : Perché il pollo si è unito a una band?
- Continuazione : Perché aveva le bacchette!
Per accedere a ChatGPT da quel momento è necessario molto lavoro a bassa retribuzione. Queste persone creano immensi corpora per valutare il peso delle risposte GPT e dei comportamenti attesi. Questi lavoratori creano tonnellate di testi di suggerimento/continuazione che sono come:
- Suggerimento : termina questa storia: "C'era una volta..."
- Continuazione : Certo! C'era una volta, in una terra molto, molto lontana, un piccolo villaggio incastonato tra due maestose montagne.
- Continuazione : Certo! C'era una volta, in una terra molto, molto lontana, un piccolo villaggio incastonato tra due maestose montagne.
- Suggerimento : Raccontami una barzelletta su un pollo.
- Continuazione : Perchè il pollo si è unito ad una band? Perché aveva le bacchette!
Questo processo di messa a punto è essenziale per diversi motivi:
- Specificità: mentre la formazione preliminare fornisce al modello un'ampia comprensione del linguaggio, la messa a punto ne restringe la conoscenza e il comportamento per allinearlo maggiormente a compiti o domini specifici. Ad esempio, un modello messo a punto sui dati medici risponderà meglio alle domande mediche.
- Controllo: la regolazione fine offre agli sviluppatori un maggiore controllo sugli output del modello. Gli sviluppatori possono utilizzare un set di dati curato per guidare il modello a produrre le risposte desiderate ed evitare comportamenti indesiderati.
- Sicurezza: aiuta a ridurre i risultati dannosi o distorti. Utilizzando le linee guida durante il processo di messa a punto, i revisori umani possono garantire che il modello non produca contenuti inappropriati.
- Prestazioni: la messa a punto può migliorare significativamente le prestazioni del modello su attività specifiche. Ad esempio, un modello ottimizzato per l'assistenza clienti sarà molto migliore rispetto a un modello generico.
Puoi dire che ChatGPT è stato ottimizzato in particolare in alcuni modi.
Ad esempio, il "ragionamento logico" è qualcosa con cui gli LLM tendono a lottare. Il miglior modello di ragionamento logico di ChatGPT – GPT-4 – è stato addestrato intensamente per riconoscere esplicitamente i modelli nei numeri.
Invece di qualcosa del genere:
- Suggerimento : quanto fa 2+2?
- Procedimento : Spesso nei libri di matematica per bambini 2+2 =4. Occasionalmente ci sono riferimenti a "2+2=5", ma di solito c'è più contesto a che fare con George Orwell o Star Trek quando è il caso. Se ciò accadesse in quel contesto il peso sarebbe più a favore di 2+2=5. Ma quel contesto non esiste, quindi in questo caso il token successivo sarà probabilmente 4.
- Risposta : 2+2=4
La formazione fa qualcosa del genere:
- formazione: 2+2=4
- formazione: 4/2=2
- formazione: metà di 4 è 2
- formazione: 2 su 2 fa quattro
…e così via.
Ciò significa che per i modelli più "logici", il processo di formazione è più rigoroso e mirato a garantire che il modello comprenda e applichi correttamente i principi logici e matematici.
Il modello è esposto a vari problemi matematici e alle relative soluzioni, garantendo che possa generalizzare e applicare questi principi a problemi nuovi e invisibili.
L’importanza di questo processo di messa a punto, soprattutto per il ragionamento logico, non può essere sopravvalutata. Senza di esso, il modello potrebbe fornire risposte errate o prive di senso a semplici domande logiche o matematiche.
Modelli di immagine e modelli linguistici
Sebbene sia i modelli di immagini che quelli di linguaggio possano utilizzare architetture simili come i trasformatori, i dati che elaborano sono fondamentalmente diversi:
Modelli di immagine
Questi modelli si occupano di pixel e spesso funzionano in modo gerarchico, analizzando prima piccoli motivi (come i bordi), quindi combinandoli per riconoscere strutture più grandi (come le forme) e così via fino a comprendere l'intera immagine.
Modelli linguistici
Questi modelli elaborano sequenze di parole o caratteri. Devono comprendere il contesto, la grammatica e la semantica per generare testo coerente e contestualmente rilevante.
Come funzionano le principali interfacce di intelligenza artificiale generativa
Dall-E + metà viaggio
Dall-E è una variante del modello GPT-3 adattato per la generazione di immagini. È addestrato su un vasto set di dati di coppie testo-immagine. Midjourney è un altro software di generazione di immagini basato su un modello proprietario.
- Input: fornisci una descrizione testuale, come "un fenicottero a due teste".
- Elaborazione: questi modelli codificano questo testo in una serie di numeri e quindi decodificano questi vettori, trovando relazioni con i pixel, per produrre un'immagine. Il modello ha appreso le relazioni tra descrizioni testuali e rappresentazioni visive dai suoi dati di training.
- Output: un'immagine che corrisponde o si riferisce alla descrizione fornita.
Dita, schemi, problemi
Perché questi strumenti non riescono a generare costantemente mani che sembrino normali? Questi strumenti funzionano osservando i pixel uno accanto all'altro.
Puoi vedere come funziona confrontando immagini generate in precedenza o più primitive con quelle più recenti: i modelli precedenti sembrano molto confusi. Al contrario, i modelli più recenti sono molto più nitidi.
Questi modelli generano immagini prevedendo il pixel successivo in base ai pixel che ha già generato. Questo processo viene ripetuto milioni di volte per produrre un'immagine completa.
Le mani, in particolare le dita, sono complesse e contengono molti dettagli che devono essere catturati con precisione.
Il posizionamento, la lunghezza e l'orientamento di ciascun dito possono variare notevolmente nelle diverse immagini.
Quando si genera un'immagine da una descrizione testuale, il modello deve fare molte ipotesi sull'esatta posa e struttura della mano, il che può portare ad anomalie.
ChatGPT
ChatGPT si basa sull'architettura GPT-3.5, un modello basato su trasformatore progettato per attività di elaborazione del linguaggio naturale.
- Input: un messaggio o una serie di messaggi per simulare una conversazione.
- Elaborazione: ChatGPT utilizza la sua vasta conoscenza di diversi testi Internet per generare risposte. Considera il contesto fornito nella conversazione e cerca di produrre la risposta più pertinente e coerente.
- Output: una risposta testuale che continua o risponde alla conversazione.
Specialità
La forza di ChatGPT risiede nella sua capacità di gestire vari argomenti e simulare conversazioni umane, rendendolo ideale per chatbot e assistenti virtuali.
Bard + Search Generative Experience (SGE)
Sebbene i dettagli specifici possano essere proprietari, Bard si basa su tecniche di intelligenza artificiale trasformatrice, simili ad altri modelli linguistici all'avanguardia. SGE si basa su modelli simili ma si intreccia con altri algoritmi ML utilizzati da Google.
SGE probabilmente genera contenuti utilizzando un modello generativo basato su trasformatore e quindi estrae fuzzy le risposte dalle pagine di classificazione nella ricerca. (Questo potrebbe non essere vero. Solo un'ipotesi basata su come sembra funzionare giocandoci. Per favore, non farmi causa!)
- Input: un prompt/comando/ricerca
- Elaborazione: Bard elabora l'input e funziona come fanno gli altri LLM. SGE utilizza un'architettura simile ma aggiunge un livello in cui ricerca la propria conoscenza interna (ottenuta dai dati di addestramento) per generare una risposta adeguata. Considera la struttura, il contesto e l'intento del prompt per produrre contenuto pertinente.
- Output: contenuto generato che può essere una storia, una risposta o qualsiasi altro tipo di testo.
Applicazioni dell’IA generativa (e loro controversie)
Arte e design
L’intelligenza artificiale generativa ora può creare opere d’arte, musica e persino progetti di prodotti. Ciò ha aperto nuove strade alla creatività e all’innovazione.
Controversia
L’ascesa dell’intelligenza artificiale nell’arte ha acceso dibattiti sulla perdita di posti di lavoro nei campi creativi.
Inoltre, ci sono preoccupazioni riguardo a:
- Violazioni del lavoro, soprattutto quando i contenuti generati dall’intelligenza artificiale vengono utilizzati senza un’adeguata attribuzione o compenso.
- I dirigenti che minacciano gli scrittori di sostituirli con l'intelligenza artificiale sono una delle questioni che hanno stimolato lo sciopero degli scrittori.
Elaborazione del linguaggio naturale (PNL)
I modelli di intelligenza artificiale sono ora ampiamente utilizzati per chatbot, traduzione linguistica e altre attività di PNL.
Al di fuori del sogno dell’intelligenza generale artificiale (AGI), questo è l’uso migliore per gli LLM poiché sono vicini a un modello PNL “generalista”.
Controversia
Molti utenti trovano i chatbot impersonali e talvolta fastidiosi.
Inoltre, sebbene l’intelligenza artificiale abbia fatto passi da gigante nella traduzione linguistica, spesso manca delle sfumature e della comprensione culturale che i traduttori umani apportano, portando a traduzioni impressionanti e imperfette.
Medicina e scoperta di farmaci
L’intelligenza artificiale può analizzare rapidamente grandi quantità di dati medici e generare potenziali composti farmaceutici, accelerando il processo di scoperta dei farmaci. Molti medici utilizzano già i LLM per scrivere appunti e comunicazioni con i pazienti
Controversia
Affidarsi agli LLM per scopi medici può essere problematico. La medicina richiede precisione e qualsiasi errore o svista da parte dell’intelligenza artificiale può avere gravi conseguenze.
Anche la medicina ha già pregiudizi che diventano ancora più concreti nell’uso dei LLM. Esistono anche questioni simili, come discusso di seguito, relative alla privacy, all’efficacia e all’etica.
Gioco
Molti appassionati di intelligenza artificiale sono entusiasti dell'utilizzo dell'intelligenza artificiale nei giochi: affermano che l'intelligenza artificiale può generare ambienti di gioco, personaggi e persino intere trame di gioco realistiche, migliorando l'esperienza di gioco. Il dialogo degli NPC può essere migliorato utilizzando questi strumenti.
Controversia
C'è un dibattito sull'intenzionalità nel game design.
Sebbene l’intelligenza artificiale possa generare grandi quantità di contenuti, alcuni sostengono che manchi del design deliberato e della coesione narrativa che i designer umani apportano.
Watchdogs 2 aveva NPC programmatici, che contribuivano ben poco alla coesione narrativa del gioco nel suo insieme.
Marketing e pubblicità
L’intelligenza artificiale può analizzare il comportamento dei consumatori e generare pubblicità personalizzate e contenuti promozionali, rendendo le campagne di marketing più efficaci.
I LLM ricavano il contesto dalla scrittura di altre persone, rendendoli utili per generare storie di utenti o idee programmatiche più sfumate. Invece di consigliare televisori a qualcuno che ha appena acquistato un televisore, gli LLM possono consigliare accessori che qualcuno potrebbe desiderare.
Controversy
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.