
Mentre concludiamo il 2016, parliamo di conclusione dei test CRO
Pubblicato: 2021-10-23Mentre ci avviciniamo alla chiusura di un altro anno, e mentre la domanda "Quando può concludersi questo test?" compare ancora nelle mie conversazioni almeno una volta alla settimana, mi sentivo come se fosse il momento di sedermi e scrivere il mio processo di conclusione del test e tutte le variabili che influiscono su questa decisione.
Oggi ti scalderò con due suggerimenti da tenere a mente quando ti avvicini alla decisione di conclusione e poi passerò alle quattro variabili che guardo quando mi avvicino a questa decisione. Soffia via la polvere da quel manuale di statistica che hai seppellito molto tempo fa e cominciamo.
Prefazione Suggerimento n. 1: assicurati che i tuoi dati siano belli e robusti
Prima di impostare il test, dovresti già sapere quali sono i tuoi obiettivi. Nota come ho detto "obiettivi" lì. Sì, sappiamo tutti che dovresti avere una conversione centralizzata; l'unica cosa importante verso cui stai indirizzando i tuoi utenti. Ma ci sono molte altre interazioni con qualsiasi sito che possiamo monitorare per osservare se la nostra alterazione ha influenzato o meno anche quelle interazioni. Vedere l'immagine qui sotto per alcuni esempi.

Prima di analizzare i dati dei test, ricontrolla che i tuoi dati siano tutti su un piano di parità. Assicurati di aver estratto i dati per ogni obiettivo per lo stesso intervallo di date esatto in modo da poter confrontare in modo appropriato i punti dati senza distorcere una stringa di dati. Mentre sei qui, assicurati anche che tutti i dati dei tuoi obiettivi appaiano "normali" e che non sospetti alcun obiettivo fallito o obiettivo morto che non ha mai visto alcuna azione.
Prefazione Suggerimento n. 2: Non concludere mai su una singola variabile
Prendere una decisione conclusiva non può fare affidamento su nessuna variabile. Prendi in considerazione ciascuna di queste quattro variabili e se la maggior parte delle variabili si completa a vicenda, puoi concludere con sicurezza.
Se tutte le variabili si contraddicono a vicenda, potresti vedere una moltitudine di scenari diversi. Ma a quel punto, se concludi, potresti prendere una decisione illogica con conseguenze costose.
Ognuna di queste variabili è influenzata o influenza almeno una delle altre variabili. Pertanto, i dati complementari si sostengono mentre i dati contraddittori ti costringono a collegare i punti con reti di bugie. Non farlo!
Variabile n. 1: dimensione del campione
La dimensione del campione conta gente. La dimensione del campione ci consente di generalizzare con sicurezza un comportamento basato sulla nostra popolazione (utenti totali) e sul nostro margine di errore accettabile (significatività statistica di 100 goal).
Riguarda davvero le proporzioni, ma se guardi costantemente lo stesso sito con fluttuazioni di traffico molto ridotte, puoi impostare un obiettivo di fondo da cui lavorare.
Cento utenti per ogni segmento di un test sono il minimo indispensabile. Anche su siti a basso traffico è molto difficile generalizzare i comportamenti basandosi sui dati di pochi utenti. Quindi, più siamo meglio è. Una dimensione del campione più elevata aiuta anche ad annullare eventuali distorsioni che potremmo vedere da valori anomali.
Tuttavia, su un sito di e-commerce piuttosto grande che porta almeno 1.000 utenti al giorno, non c'è modo di considerare 100 e un campione appropriato di utenti. Si tratta di proporzioni e di qual è il volume di utenti tipico per il tuo sito su base regolare.
Questa variabile include le conversioni e gli utenti per gli obiettivi che prenderai in considerazione. Anche se hai un sito a bassa conversione, se confronti 0 conversioni con 2 conversioni, la variante con 2 conversioni vincerà sicuramente solo perché era l'unica variante tecnicamente convertibile.
Assicurati che le tue conversioni siano almeno a doppia cifra; e se questo è il tuo minimo indispensabile (doppie cifre), assicurati di avere una forte azione di complimento nelle altre tre variabili.
Oppure, se non hai molta esperienza con la dimensione del campione in un ambiente statistico, puoi utilizzare questo pratico calcolatore della dimensione del campione per determinare una dimensione del campione appropriata per te.
Variabile n. 2: Durata del test
Idealmente, eseguo test ovunque da 2-6 settimane.
Due settimane sono un minimo solido perché stai annullando la possibilità che qualsiasi variabile abbia una settimana "buona" o "cattiva" e che sia trascinata nel traffico felice o allontanando il traffico poco motivato. Sei settimane sono un bel massimo perché è una rete temporale abbastanza ampia da catturare qualsiasi fluttuazione che potresti vedere.
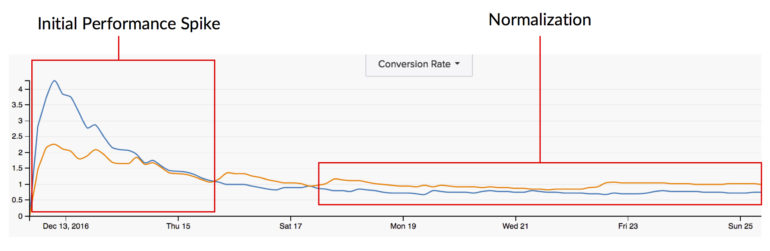
Tuttavia, tieni presente che eseguire un test per sempre può anche essere dannoso per il tuo test. Un fattore importante nei risultati dei test è la risposta dell'utente a nuovi stimoli. Pertanto, quando lanciamo per la prima volta un test, tendiamo a vedere enormi balzi fuori dal cancello in cui una variazione sta perdendo drammaticamente mentre l'altra costeggia la sua serie vincente. Nel tempo questo enorme divario tra le variazioni tende a normalizzarsi e chiudersi perché il "nuovo" è svanito e gli utenti di ritorno non sono così colpiti dalla nuova alterazione come una volta. Pertanto, più a lungo dura il test, meno nuova diventa l'alterazione e meno influenza i comportamenti per quegli utenti di ritorno.
Variabile n. 3: significatività statistica
Sebbene la significatività statistica sia fondamentale nel dichiarare la "fiducia" nella tua conclusione, può anche essere molto fuorviante.
La significatività statistica determina se una variazione in due tassi è dovuta alla varianza normale oa un fattore esterno. Quindi, in teoria, quando raggiungiamo una forte significatività statistica, sappiamo che la nostra alterazione ha avuto un effetto sugli utenti.
Idealmente, vuoi puntare a una significatività statistica il più vicino possibile al 100%. Più ti avvicini al 100%, più piccolo è il tuo margine di errore. Ciò significa che i risultati possono essere riprodotti su una base più coerente. Maggiore è la tua significatività statistica, maggiori sono le tue possibilità di mantenere l'aumento del tasso di conversione se implementi la variante vincente. Il 95% è un buon obiettivo alto a cui puntare. Il 90% è un buon posto dove stabilirsi. Qualsiasi inferiore al 90% e stai diventando rischioso di essere effettivamente in grado di concludere "con fiducia".
La minaccia qui è che la dimensione del campione conta davvero. Potresti raggiungere una significatività statistica del 98% in pochi giorni e letteralmente guardare solo un totale di 16 utenti, il che ovviamente non è una dimensione del campione affidabile.
La significatività statistica può anche catturare quell'enorme picco di prestazioni a cui ho fatto riferimento in precedenza quando un test è stato avviato per la prima volta. I test hanno tutte le capacità di ribaltamento e sappiamo anche che nel tempo i dati si normalizzano. Pertanto, misurare la significatività statistica troppo presto potrebbe darci un'immagine completamente errata di come tale alterazione molto probabilmente influenzerà i nostri utenti su una base più a lungo termine.
Inoltre, non tutti i test acquisiranno una significatività statistica. Alcune modifiche apportate potrebbero non influenzare il comportamento dell'utente abbastanza fortemente da essere viste come una variazione più che normale. E va bene! Ciò significa semplicemente che devi testare modifiche più grandi per catturare un po' di più l'attenzione dell'utente.
Variabile n. 4: coerenza dei dati
Questo va a tutti quei test flip-flop là fuori. Ci sono alcuni test che si rifiutano di normalizzarsi e si rifiutano di presentarti un chiaro vincitore. Passeranno ogni giorno a presentarti una variante diversa come vincitore e ti faranno impazzire.
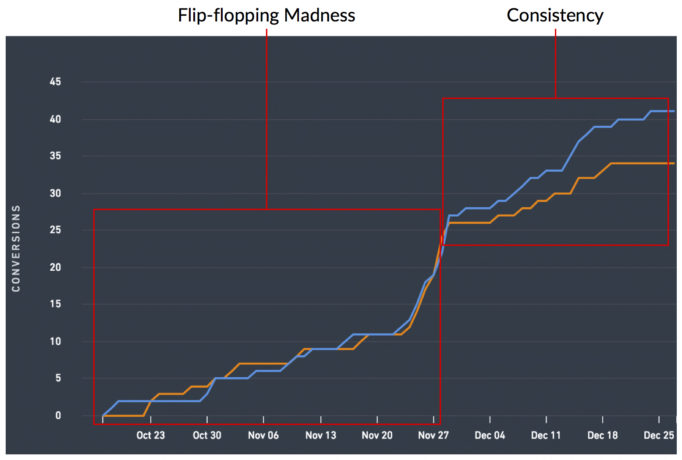
Ma esistono e sono esattamente il motivo per cui la ricerca di una direzionalità dei dati coerente è così cruciale. La variazione che stai dichiarando vincente è sempre stata vincente? Se no, perché non è sempre stato un vincitore? Se non puoi rispondere con sicurezza al "perché?" quindi implementare il vincitore potrebbe danneggiare la tua linea di fondo se implementi la variazione che sfila come un vincitore.
Misuro anche la differenza tra il tasso di conversione del controllo e il tasso di conversione della variazione (noto anche come "lift" o "drop"). Cerco che anche questa metrica sia coerente in modo da poter garantire che il test sia fuori dalla fase di picco iniziale.
È anche utile calcolare periodicamente la significatività statistica per vedere quanto sia coerente anche questa metrica.
Pensieri finali
Concludere qualsiasi tipo di test non è uno scherzo ed è pieno di pressione. Se fai la chiamata sbagliata e implementi qualcosa che "ritenevi" fosse il vincitore mentre i dati illustravano il contrario, i tuoi profitti e i tuoi utenti ne soffriranno.
Avvicinati a una conclusione da ogni angolazione praticabile in modo da poterti assicurare di avere una conclusione veramente sicura alimentata dai dati!