
Caso di studio SEO lungo un anno: cosa devi sapere su Googlebot
Pubblicato: 2019-08-30Nota del redattore: il CEO del crawler JetOctopus Serge Bezborodov fornisce consigli esperti su come rendere il tuo sito web attraente per Googlebot. I dati in questo articolo si basano su una ricerca durata un anno e su 300 milioni di pagine sottoposte a scansione.
Alcuni anni fa, stavo cercando di aumentare il traffico sul nostro sito Web di aggregazione di lavoro con 5 milioni di pagine. Ho deciso di utilizzare i servizi dell'agenzia SEO, aspettandomi che il traffico sarebbe andato alle stelle. Ma mi sbagliavo. Invece di un controllo completo, ho letto i tarocchi. Ecco perché sono tornato al punto di partenza e ho creato un web crawler per un'analisi SEO on-page completa.
Spio Googlebot da più di un anno e ora sono pronto a condividere informazioni sul suo comportamento. Mi aspetto che le mie osservazioni chiariscano almeno come funzionano i web crawler e al massimo ti aiuteranno a condurre l'ottimizzazione on-page in modo efficiente. Ho raccolto i dati più significativi utili per un nuovo sito web o per uno con migliaia di pagine.
Le tue pagine compaiono nelle SERP?
Per sapere con certezza quali pagine sono nei risultati di ricerca, dovresti controllare l'indicizzazione dell'intero sito web. Tuttavia, l'analisi di ogni URL su un sito Web di oltre 10 milioni di pagine costa una fortuna, più o meno quanto un'auto nuova.
Usiamo invece l'analisi dei file di registro. Lavoriamo con i siti Web nel modo seguente: eseguiamo la scansione delle pagine Web come fa il bot di ricerca, quindi analizziamo i file di registro raccolti per metà dell'anno. I registri mostrano se i bot visitano il sito Web, quali pagine sono state sottoposte a scansione e quando e con quale frequenza i bot hanno visitato le pagine.
La scansione è il processo in cui i robot di ricerca visitano il tuo sito Web, elaborano tutti i collegamenti sulle pagine Web e posizionano questi collegamenti in linea per l'indicizzazione. Durante la scansione, i bot confrontano gli URL appena elaborati con quelli già presenti nell'indice. Pertanto, i robot aggiornano i dati e aggiungono/eliminano alcuni URL dal database del motore di ricerca per fornire i risultati più pertinenti e aggiornati per gli utenti.
Ora, possiamo facilmente trarre queste conclusioni:
- A meno che il bot di ricerca non fosse sull'URL, questo URL probabilmente non sarà nell'indice.
- Se Googlebot visita l'URL più volte al giorno, quell'URL è ad alta priorità e richiede pertanto la tua particolare attenzione.
Complessivamente, queste informazioni rivelano ciò che impedisce la crescita organica e lo sviluppo del tuo sito web. Ora, invece di operare alla cieca, il tuo team può saggiamente ottimizzare un sito web.
Lavoriamo principalmente con grandi siti Web perché se il tuo sito Web è piccolo, prima o poi Googlebot eseguirà la scansione di tutte le tue pagine Web.
Al contrario, i siti Web con più di 100.000 pagine incontrano un problema quando il crawler visita pagine invisibili ai webmaster. Il prezioso crawl budget può essere sprecato su queste pagine inutili o addirittura dannose. Allo stesso tempo, il bot potrebbe non trovare mai le tue pagine redditizie perché c'è un pasticcio nella struttura di un sito web.
Il crawl budget rappresenta le risorse limitate che Googlebot è pronto a spendere sul tuo sito web. È stato creato per dare la priorità a cosa analizzare e quando. La dimensione del crawl budget dipende da molti fattori, come la dimensione del tuo sito web, la sua struttura, il volume e la frequenza delle query degli utenti, ecc.
Tieni presente che il bot di ricerca non è interessato a eseguire la scansione completa del tuo sito web.
Lo scopo principale del bot del motore di ricerca è fornire agli utenti le risposte più pertinenti con perdite minime di risorse.Il bot esegue la scansione di tutti i dati di cui ha bisogno per lo scopo principale. Quindi, è TUO compito aiutare il bot a raccogliere i contenuti più utili e redditizi.
Spiare Googlebot
Nell'ultimo anno abbiamo scansionato più di 300 milioni di URL e 6 miliardi di righe di log su grandi siti web. Sulla base di questi dati, abbiamo tracciato il comportamento di Googlebot per contribuire a rispondere alle seguenti domande:
- Quali tipi di pagine vengono ignorati?
- Quali pagine vengono visitate di frequente?
- Cosa merita attenzione per il bot?
- Cosa non ha valore?
Di seguito sono riportate le nostre analisi e risultati, e non una riscrittura delle Linee guida per i webmaster di Google. In effetti, non diamo raccomandazioni non provate e ingiustificate. Ogni punto si basa su statistiche e grafici fattuali per tua comodità.
Andiamo al sodo e scopriamo:
- Cosa conta davvero per Googlebot?
- Cosa determina se il bot visita o meno la pagina?
Abbiamo identificato i seguenti fattori:
Distanza dall'indice
DFI è l'acronimo di Distance From Index ed è quanto è lontano il tuo URL per l'URL principale/root/index in clic. È uno dei criteri più cruciali che influisce sulla frequenza delle visite di Googlebot. Ecco un video educativo per saperne di più su DFI .
Si noti che DFI non è il numero di barre nella directory dell'URL come, ad esempio:
site.com/negozio/iphone/iphoneX.html – DFI– 3__ _
Quindi, DFI viene conteggiato esattamente per CLIC dalla pagina principale
https://site.com/shop/iphone/iphoneX.html
https://site.com Catalogo iPhone → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
Di seguito puoi vedere come l'interesse di Googlebot per l'URL con il suo DFI si è ridotto gradualmente durante l'ultimo mese e negli ultimi sei mesi.
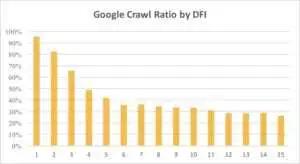
Come puoi vedere, se DFI è 5 t0 6, Googlebot esegue la scansione solo della metà delle pagine web. E la percentuale di pagine elaborate si riduce se DFI è più grande. Gli indicatori nella tabella sono stati unificati per 18 milioni di pagine. Si noti che i dati possono variare a seconda della nicchia del sito Web specifico.
Cosa fare?
È ovvio che la migliore strategia in questo caso è evitare DFI più lunghi di 5, creare una struttura del sito web facile da navigare, prestare particolare attenzione ai collegamenti, ecc.
La verità è che queste misure richiedono molto tempo per i siti Web di oltre 100.000 pagine. Di solito i grandi siti Web hanno una lunga storia di riprogettazioni e migrazioni. Ecco perché i webmaster non dovrebbero semplicemente eliminare le pagine con DFI di 10, 12 o anche 30. Inoltre, l'inserimento di un collegamento dalle pagine visitate di frequente non risolverà il problema.
Il modo ottimale per far fronte a lunghi DFI è verificare e stimare se questi URL sono pertinenti, redditizi e quali posizioni hanno nelle SERP.
Le pagine con un DFI lungo ma con buone posizioni nelle SERP hanno un alto potenziale. Per aumentare il traffico su pagine di alta qualità, i webmaster dovrebbero inserire collegamenti dalle pagine successive. Uno o due collegamenti non sono sufficienti per un progresso tangibile.
Puoi vedere dal grafico sottostante che Googlebot visita gli URL più frequentemente se ci sono più di 10 link sulla pagina.
Collegamenti
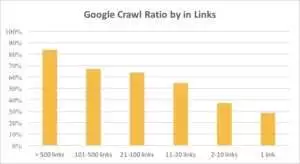
Infatti, più grande è un sito web, più significativo è il numero di collegamenti nelle pagine web. Questi dati provengono in realtà da siti Web di oltre 1 milione di pagine.

Se hai scoperto che ci sono meno di 10 link nelle tue pagine redditizie, niente panico. Innanzitutto, controlla se queste pagine sono di alta qualità e redditizie. Quando lo fai, inserisci collegamenti su pagine di alta qualità senza fretta e con brevi iterazioni, analizzando i log dopo ogni passaggio.
Dimensione del contenuto
Il contenuto è uno degli aspetti più popolari dell'analisi SEO. Naturalmente, maggiore è il contenuto pertinente sul tuo sito Web, migliore è il tuo Crawl Ratio. Di seguito puoi vedere come diminuisce drasticamente l'interesse di Googlebot per le pagine con meno di 500 parole.
Cosa fare?
Sulla base della mia esperienza, quasi la metà di tutte le pagine con meno di 500 parole sono pagine spazzatura. Abbiamo visto un caso in cui un sito web conteneva 70.000 pagine con solo la taglia dei vestiti elencata, quindi solo una parte di queste pagine era nell'indice.
Pertanto, prima controlla se hai davvero bisogno di quelle pagine. Se questi URL sono importanti, dovresti aggiungere alcuni contenuti pertinenti su di essi. Se non hai nulla da aggiungere, rilassati e lascia questi URL così come sono. A volte è meglio non fare nulla invece di pubblicare contenuti inutili.
Altri fattori
I seguenti fattori possono avere un impatto significativo sul Crawl Ratio:
Tempo di caricamento
La velocità della pagina Web è fondamentale per la scansione e il posizionamento. Il bot è come un essere umano: odia aspettare troppo a lungo per il caricamento di una pagina web. Se ci sono più di 1 milione di pagine sul tuo sito web, il bot di ricerca scaricherà probabilmente cinque pagine con un tempo di caricamento di 1 secondo invece di attendere una pagina che si carica in 5 secondi.
Cosa fare?
In realtà, si tratta di un compito tecnico e non esiste una soluzione "un metodo valido per tutti", come l'utilizzo di un server più grande. L'idea principale è trovare il collo di bottiglia del problema. Dovresti capire perché le pagine web si caricano lentamente. Solo dopo che il motivo è stato rivelato, puoi agire.
Rapporto tra contenuto unico e basato su modelli
L'equilibrio tra dati univoci e basati su modelli è importante. Ad esempio, hai un sito Web con variazioni di nomi di animali domestici. Quanti contenuti pertinenti e unici puoi davvero raccogliere su questo argomento?
Luna era il nome di cane "celebrità" più popolare, seguito da Stella, Jack, Milo e Leo.
Ai robot di ricerca non piace spendere le proprie risorse su questo tipo di pagine.
Cosa fare?
Mantenere l'equilibrio. A utenti e bot non piace visitare pagine con modelli complicati, un mucchio di link in uscita e poco contenuto.
Pagine orfane
Le pagine orfane sono URL che non sono nella struttura del sito web e non conosci queste pagine, ma queste pagine orfane potrebbero essere scansionate dai bot. Per chiarire, guarda il cerchio di Eulero nell'immagine qui sotto:

Potete vedere la situazione normale per il giovane sito web, la cui struttura non è cambiata da tempo. Ci sono 900.000 pagine che tu e il crawler potete analizzare. Circa 500.000 pagine vengono elaborate dal crawler ma sono sconosciute a Google. Se rendi indicizzabili questi 500.000 URL, il tuo traffico aumenterà sicuramente.
Attenzione: Anche un sito giovane contiene alcune pagine (la parte blu nella foto) che non sono nella struttura del sito ma sono regolarmente visitate da bot.
E queste pagine potrebbero contenere contenuti spazzatura, come inutili query dei visitatori generate automaticamente.
Ma i grandi siti Web raramente sono così accurati. Molto spesso i siti Web con la cronologia hanno questo aspetto:

Ecco l'altro problema: Google sa più cose sul tuo sito web di te. Possono esserci pagine cancellate, pagine su JavaScript o Ajax, reindirizzamenti interrotti e così via. Una volta ci siamo trovati di fronte a una situazione in cui nella mappa del sito è apparso un elenco di 500.000 collegamenti interrotti a causa di un errore di un programmatore. Dopo tre giorni, il bug è stato trovato e risolto, ma Googlebot visitava questi collegamenti interrotti da sei mesi!
Molto spesso, il tuo Crawl Budget viene spesso sprecato su queste pagine orfane.
Cosa fare?
Esistono due modi per risolvere questo potenziale problema: il primo è canonico: ripulire il casino. Organizza la struttura del sito web, inserisci correttamente i link interni, aggiungi pagine orfane al DFI aggiungendo link da pagine indicizzate, imposta il compito per i programmatori e attendi la prossima visita di Googlebot.
Il secondo modo è rapido: raccogliere l'elenco delle pagine orfane e verificare se sono pertinenti. Se la risposta è "sì", crea la mappa del sito con questi URL e inviala a Google. In questo modo è più facile e veloce, ma solo la metà delle pagine orfane sarà nell'indice.
Il livello successivo
Gli algoritmi dei motori di ricerca sono migliorati da due decenni ed è ingenuo pensare che la ricerca per indicizzazione possa essere spiegata con pochi grafici.
Raccogliamo più di 200 parametri diversi per ogni pagina e prevediamo che questo numero aumenterà entro la fine dell'anno. Immagina che il tuo sito web sia la tabella con 1 milione di righe (pagine) e moltiplica queste righe per 200 colonne, il semplice campione non è sufficiente per un audit tecnico completo. Sei d'accordo?
Abbiamo deciso di approfondire e utilizzare l'apprendimento automatico per scoprire cosa influenza la scansione di Googlebot in ciascun caso.

Per uno, i collegamenti ai siti Web sono cruciali mentre il contenuto è il fattore chiave per l'altro.
Il punto principale di questo compito era ottenere risposte facili da dati complessi e massicci: cosa sul tuo sito web influisce maggiormente sull'indicizzazione? Quali cluster di URL sono collegati con gli stessi fattori? In modo che tu possa lavorare con loro in modo completo.
Prima di scaricare e analizzare i log sul nostro sito Web aggregatore HotWork, la storia delle pagine orfane visibili ai bot ma non a noi mi sembrava irrealistica. Ma la situazione reale mi ha sorpreso ancora di più: Crawl ha mostrato 500 pagine con reindirizzamento 301, ma Yandex ha trovato 700.000 pagine con lo stesso codice di stato.
Di solito, ai fanatici della tecnologia non piace archiviare i file di registro perché questi dati "sovraccaricano" i dischi. Ma oggettivamente, sulla maggior parte dei siti Web con un massimo di 10 milioni di visite al mese, l'impostazione di base dell'archiviazione dei registri funziona perfettamente.
Parlando del volume di log, la soluzione migliore è creare un archivio e scaricarlo su Amazon S3-Glacier (puoi archiviare 250 GB di dati a solo $ 1). Per gli amministratori di sistema, questo compito è facile come preparare una tazza di caffè. In futuro, i registri storici aiuteranno a rivelare bug tecnici e stimare l'influenza degli aggiornamenti di Google sul tuo sito web.