
クロールの有効性: クロールの最適化をレベルアップする方法
公開: 2022-10-27サイトでアクセスできるすべての URL を Googlebot がクロールするとは限りません。 それどころか、大多数のサイトではかなりの量のページが欠落しています。
現実には、Google には、見つけたすべてのページをクロールするためのリソースがありません。 Googlebot が検出したものの、まだクロールしていないすべての URL と、再クロールしようとしている URL は、クロール キューで優先されます。
つまり、Googlebot は十分に高い優先度が割り当てられたものだけをクロールします。 また、クロール キューは動的であるため、Google が新しい URL を処理するたびに継続的に変化します。 また、すべての URL がキューの最後に参加するわけではありません。
では、サイトの URL が VIP であることを確認し、一線を越えるにはどうすればよいでしょうか?
クロールはSEOにとって非常に重要です

コンテンツを可視化するには、まず Googlebot がコンテンツをクロールする必要があります。
ただし、次のような場合にページが高速にクロールされるため、利点はそれよりも微妙です。
- 作成済み 、新しいコンテンツが Google に表示されるのが早くなります。 これは、期間限定または市場初のコンテンツ戦略にとって特に重要です。
- 更新された 、更新されたコンテンツがランキングに影響を与え始めるのが早くなります。 これは、コンテンツの再公開戦略と技術的な SEO 戦術の両方にとって特に重要です。
そのため、クロールはすべてのオーガニック トラフィックに不可欠です。 しかし、クロールの最適化は大規模な Web サイトにのみ有益であるとよく言われます。
ただし、ウェブサイトのサイズ、コンテンツの更新頻度、または Google Search Console で「発見 - 現在はインデックスに登録されていません」除外を設定しているかどうかは問題ではありません。
クロールの最適化は、すべての Web サイトにとって有益です。 その価値の誤解は、無意味な測定値、特にクロール バジェットに拍車をかけているようです。
クロールの予算は関係ありません

多くの場合、クロールはクロール バジェットに基づいて評価されます。 これは、Googlebot が特定のウェブサイトで一定時間内にクロールする URL の数です。
Google は、次の 2 つの要因によって決定されると述べています。
- クロール レート制限(または Googlebot がクロールできるもの): Googlebot がサイトのパフォーマンスに影響を与えずにウェブサイトのリソースを取得できる速度。 基本的に、レスポンシブ サーバーはより高いクロール レートにつながります。
- クロールの需要(または Googlebot がクロールしたいもの): 1 回のクロール中に Googlebot が (再) インデックス作成の需要に基づいてアクセスする URL の数。サイトのコンテンツの人気と古さの影響を受けます。
Googlebot は、クロール バジェットを「消費」すると、サイトのクロールを停止します。
Google はクロール バジェットの数値を提供していません。 最も近いのは、Google Search Console のクロール統計レポートにクロール リクエストの合計を表示することです。
過去に私を含む非常に多くの SEO が、クロール バジェットを推測するために多大な労力を費やしてきました。
よく提示される手順は、次のようなものです。
- サイトにクロール可能なページがいくつあるかを判断します。多くの場合、XML サイトマップの URL の数を確認するか、無制限のクローラーを実行することをお勧めします。
- Google Search Console のクロール統計レポートをエクスポートするか、ログ ファイル内の Googlebot リクエストに基づいて、1 日あたりの平均クロールを計算します。
- ページ数を 1 日あたりの平均クロール数で割ります。 結果が 10 を超える場合は、クロール バジェットの最適化に注力するとよく言われます。
ただし、このプロセスには問題があります。
すべての URL が 1 回クロールされると想定しているだけでなく、実際には複数回クロールされるものもあれば、まったくクロールされないものもあります。
1 回のクロールが 1 ページに等しいと想定しているからだけではありません。 実際には、1 つのページをロードするために必要なリソース (JS、CSS など) を取得するために、多くの URL クロールが必要になる場合があります。
しかし、最も重要なことは、1 日あたりの平均クロール数などの計算された指標にまで絞り込むと、クロール バジェットは虚栄心の指標にすぎないためです。
「クロール バジェットの最適化」 (つまり、クロールの総量を継続的に増やすことを目的とする) を目的とした戦術は、愚かな用事です。
値のない URL や前回のクロールから変更されていないページで使用されている場合、クロールの総数を増やすことに注意する必要があるのはなぜですか? このようなクロールは、SEO のパフォーマンスには役立ちません。
さらに、クロールの統計を見たことがある人なら誰でも知っていることですが、多くの場合、さまざまな要因によって日ごとに非常に激しく変動します。 これらの変動は、SEO 関連ページの高速 (再) インデックス作成と相関する場合と相関しない場合があります。
クロールされる URL の数の増減は、本質的に良いことでも悪いことでもありません。
クロール効率はSEO KPI

インデックスを作成したいページについては、クロールされたかどうかではなく、公開後または大幅に変更された後にクロールされた速さに焦点を当てる必要があります。
基本的に、目標は、SEO 関連のページが作成または更新されてから、次の Googlebot クロールまでの時間を最小限に抑えることです。 この時間遅延をクロールの有効性と呼んでいます。
クロールの有効性を測定する理想的な方法は、データベースの作成または更新日時と、サーバー ログ ファイルからの URL の次の Googlebot クロールとの差を計算することです。
これらのデータ ポイントにアクセスするのが難しい場合は、Google Search Console URL Inspection API で XML サイトマップ lastmod 日付とクエリ URL をプロキシとして使用して、最後のクロール ステータスを取得することもできます (1 日あたり 2,000 クエリの制限まで)。
さらに、URL Inspection API を使用すると、インデックス作成ステータスがいつ変化したかを追跡して、新しく作成された URL のインデックス作成の有効性を計算することもできます。これは、公開と成功したインデックス作成の違いです。
インデックス作成のステータスに影響を与えたり、ページ コンテンツの更新を処理したりせずにクロールするのは無駄です。
クロールの有効性は実用的な指標です。これが低下するにつれて、SEO にとってより重要なコンテンツが Google 全体でオーディエンスに表示されるようになるためです。
また、SEO の問題を診断するためにも使用できます。 URL パターンをドリルダウンして、サイトのさまざまなセクションのコンテンツがクロールされる速度と、それがオーガニック パフォーマンスを妨げている原因であるかどうかを理解します。
Googlebot がクロールして新しく作成したコンテンツや最近更新したコンテンツをインデックスに登録するのに数時間、数日、または数週間かかっていることがわかった場合は、どうすればよいでしょうか?
検索マーケティング担当者が頼りにしている毎日のニュースレターを入手してください。
条件を参照してください。
クロールを最適化するための 7 つのステップ
クロールの最適化とは、重要な URL をクロールするように Googlebot を誘導することです それらが(再)公開されるときは高速です。 以下の 7 つの手順に従ってください。
1. 高速で健全なサーバー応答を確保する
高性能サーバーは非常に重要です。 Googlebot は、次の場合にクロールを遅くするか停止します。
- サイトのクロールはパフォーマンスに影響します。 たとえば、クロールが多いほど、サーバーの応答時間が遅くなります。
- サーバーは、顕著な数のエラーまたは接続タイムアウトで応答します。
反対に、ページの読み込み速度を改善してより多くのページを提供できるようにすると、Googlebot が同じ時間内により多くの URL をクロールするようになる可能性があります。 これは、ユーザー エクスペリエンスとランキング要因であるページ速度に加えて、追加の利点です。

まだお持ちでない場合は、HTTP/2 のサポートを検討してください。これにより、サーバーに同様の負荷をかけてより多くの URL を要求できるようになります。
ただし、パフォーマンスとクロール ボリュームの相関関係は、ある程度までしかありません。 サイトごとに異なるそのしきい値を超えると、サーバー パフォーマンスの追加の向上がクロールの増加と相関する可能性は低くなります。
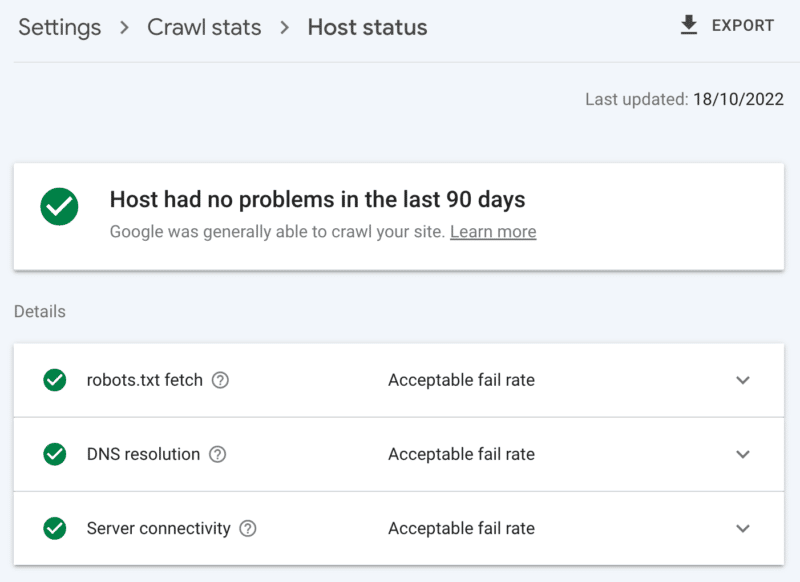
サーバーの状態を確認する方法
Google Search Console のクロール統計レポート:
- ホストのステータス: 緑色の目盛りが表示されます。
- 5xx エラー: 1% 未満を構成します。
- サーバー応答時間グラフ: 300 ミリ秒未満の傾向。
2.価値の低いコンテンツをクリーンアップする
かなりの量のサイト コンテンツが古い、重複している、または品質が低い場合、クロール アクティビティの競合が発生し、新しいコンテンツのインデックス作成または更新されたコンテンツの再インデックス作成が遅れる可能性があります。
さらに、価値の低いコンテンツを定期的にクリーニングすることで、インデックスの肥大化とキーワードの共食いが減り、ユーザー エクスペリエンスにメリットがあります。これは非常に簡単な SEO です。
明確な代替と見なされる別のページがある場合は、コンテンツを 301 リダイレクトとマージします。 これを理解すると、クロールの処理に 2 倍のコストがかかりますが、リンク エクイティを犠牲にする価値はあります。
同等のコンテンツがない場合、301 を使用してもソフト 404 になります。そのようなコンテンツを削除するには、410 (最高) または 404 (2 番目に近い) ステータス コードを使用して、URL を再度クロールしないように強いシグナルを発します。
価値の低いコンテンツを確認する方法
Google Search Console ページの URL の数は、「クロール済み – 現在インデックスに登録されていません」除外を報告しています。 これが高い場合は、フォルダー パターンまたはその他の問題の指標について提供されているサンプルを確認してください。
3. インデックス管理の見直し
Rel=正規リンク は、インデックス作成の問題を回避するための強力なヒントですが、多くの場合、過度に依存し、最終的にクロールの問題を引き起こします。これは、すべての正規化された URL が少なくとも 2 回のクロール (1 回はそれ自体、もう 1 回はそのパートナー) にかかるためです。
同様に、noindex robots ディレクティブはインデックスの肥大化を抑えるのに役立ちますが、数が多いとクロールに悪影響を与える可能性があるため、必要な場合にのみ使用してください。
どちらの場合も、次のように自問してください。
- これらのインデックス作成ディレクティブは、SEO の課題を処理するための最適な方法ですか?
- 一部の URL ルートは、robots.txt で統合、削除、またはブロックできますか?
AMP を使用している場合は、AMP を長期的な技術ソリューションとして真剣に考え直してください。
コア Web バイタルに焦点を当てたページ エクスペリエンスの更新と、サイトの速度要件を満たしている限り、すべての Google エクスペリエンスに非 AMP ページを含めることで、AMP がダブル クロールの価値があるかどうかをよく調べてください。
インデックス作成コントロールへの過度の依存をチェックする方法
明確な理由なしに除外対象に分類された、Google Search Console カバレッジ レポート内の URL の数:
- 適切な canonical タグを持つ代替ページ。
- noindex タグによる除外。
- 重複、Google はユーザーとは異なる標準を選択しました。
- 重複して送信された URL が正規として選択されていません。
4. 検索エンジンのスパイダーに何をいつクロールするかを伝える
Googlebot が重要なサイト URL に優先順位を付け、そのようなページが更新されたときに通信するために不可欠なツールは、XML サイトマップです。
効果的なクローラー ガイダンスのために、次のことを確認してください。
- インデックス可能で SEO にとって価値のある URL のみを含めます。通常は、SERP での可視性を気にする「index,follow」ロボット タグを含む 200 のステータス コード、正規のオリジナル コンテンツ ページを含めます。
- 個々の URL とサイトマップ自体に正確な <lastmod> タイムスタンプ タグをできるだけリアルタイムに近づけます。
Google は、サイトがクロールされるたびにサイトマップをチェックするわけではありません。 そのため、更新されるたびに、Google の注意を喚起することをお勧めします。 これを行うには、ブラウザーまたはコマンド ラインで GET 要求を次の場所に送信します。
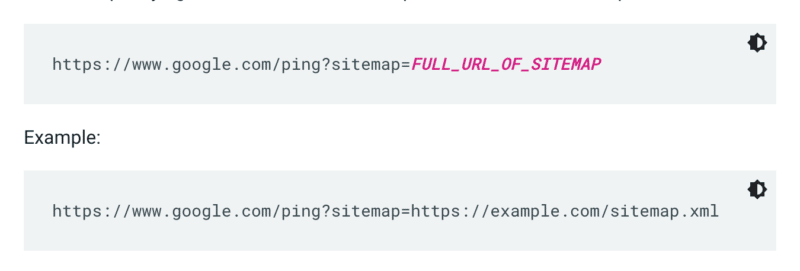
さらに、robots.txt ファイルでサイトマップへのパスを指定し、サイトマップ レポートを使用して Google Search Console に送信します。
原則として、Google はサイトマップ内の URL を他のサイトより頻繁にクロールします。 ただし、サイトマップ内のごく一部の URL が低品質であっても、Googlebot がその URL を提案のクロールに使用するのを思いとどまらせる可能性があります。
XML サイトマップとリンクは、通常のクロール キューに URL を追加します。 優先クロール キューもあり、2 つのエントリ方法があります。
まず、求人情報やライブ ビデオがある場合は、URL を Google の Indexing API に送信できます。
または、Microsoft Bing や Yandex の注目を集めたい場合は、任意の URL に IndexNow API を使用できます。 ただし、私自身のテストでは、URL のクロールへの影響は限定的でした。 そのため、IndexNow を使用する場合は、Bingbot のクロールの有効性を監視してください。
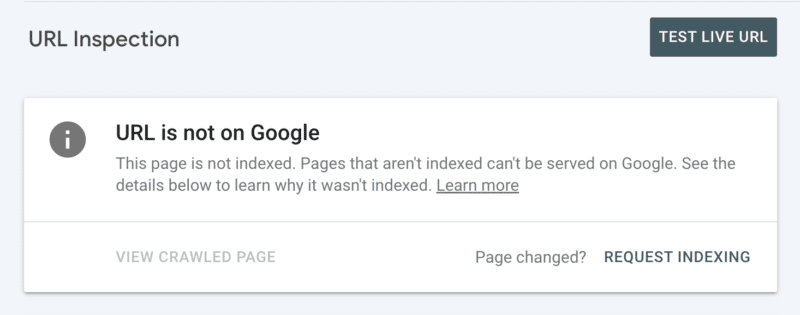
次に、Search Console で URL を調べた後、手動でインデックス登録をリクエストできます。 ただし、毎日 10 個の URL の割り当てがあり、クロールにはかなりの時間がかかる場合があることに注意してください。 クロールの問題の原因を突き止めるために掘り下げている間は、これを一時的なパッチと見なすことをお勧めします。
Googlebot のクロールに関する重要なガイダンスを確認する方法
Google Search Console では、XML サイトマップに「成功」というステータスが表示され、最近読み込まれました。
5. クロールしないものを検索エンジンのスパイダーに伝える
一部のページは、ユーザーやサイトの機能にとって重要かもしれませんが、検索結果に表示したくない場合があります。 robots.txt の disallow を使用して、このような URL ルートがクローラーの注意をそらさないようにします。 これには次のものが含まれます。
- API と CDN 。 たとえば、Cloudflare の顧客である場合は、サイトに追加された /cdn-cgi/ フォルダーを許可しないようにしてください。
- 重要でない画像、スクリプト、またはスタイル ファイル。これらのリソースなしで読み込まれたページが損失の影響を大きく受けていない場合。
- ショッピング カートなどの機能的なページ。
- カレンダー ページによって作成されるような無限のスペース。
- パラメータページ。 特に、すべての組み合わせがクローラーによって個別のページとしてカウントされるため、フィルタリング (例: ?price-range=20-50)、並べ替え (例: ?sort=)、または検索 (例: ?q=) のファセット ナビゲーションからのもの。
ページネーション パラメータを完全にブロックしないように注意してください。 Googlebot がコンテンツを発見し、内部リンク エクイティを処理するには、ある程度までクロール可能なページネーションが不可欠であることがよくあります。 (理由の詳細については、ページネーションに関するこの Semrush ウェビナーをご覧ください。)
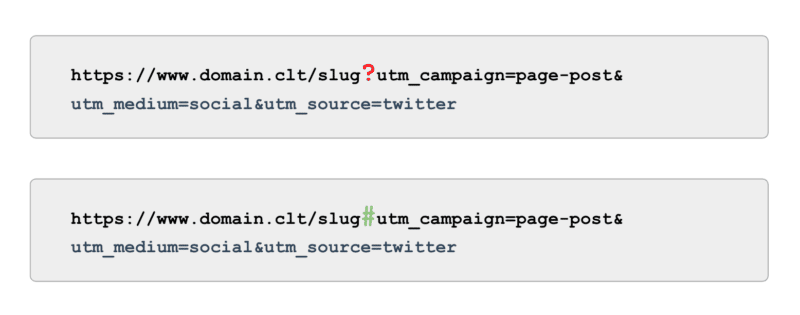
また、追跡に関しては、パラメーター (別名「?」) を使用する UTM タグを使用するのではなく、アンカー (別名「#」) を使用します。 クロール可能でなくても、Google アナリティクスと同じレポート機能を提供します。
Googlebot がクロールしないガイダンスを確認する方法
Google Search Console で「インデックス登録済み、サイトマップに送信されていない」URL のサンプルを確認します。 ページネーションの最初の数ページを無視して、他にどのような道筋を見つけることができますか? それらを XML サイトマップに含めるか、クロールをブロックするか、許可するか。
また、「検出済み - 現在はインデックスに登録されていません」のリストを確認し、robots.txt で、Google にとって価値の低い、またはまったく価値のない URL パスをブロックします。
これを次のレベルに進めるには、サーバー ログ ファイルですべての Googlebot スマートフォン クロールを確認して、値のないパスを探します。
6. 関連リンクをキュレートする
ページへのバックリンクは SEO の多くの側面で価値があり、クロールも例外ではありません。 ただし、ページの種類によっては、外部リンクを取得するのが難しい場合があります。 たとえば、製品、サイト アーキテクチャの下位レベルのカテゴリ、さらには記事などのディープ ページです。
一方、関連する内部リンクは次のとおりです。
- 技術的にスケーラブル。
- クロール対象のページに優先順位を付けるための Googlebot への強力な信号。
- ページの深いクロールに特に影響を与えます。
ブレッドクラム、関連するコンテンツ ブロック、クイック フィルター、厳選されたタグの使用はすべて、クロールの有効性に大きなメリットがあります。 それらは SEO にとって重要なコンテンツであるため、そのような内部リンクが JavaScript に依存していないことを確認し、標準のクロール可能な <a> リンクを使用してください。
このような内部リンクも、ユーザーにとって実際の価値を追加する必要があることを念頭に置いてください。
関連リンクの確認方法
ScreamingFrog の SEO スパイダーなどのツールを使用して、サイト全体の手動クロールを実行し、以下を探します。
- 孤立した URL。
- robots.txt によってブロックされた内部リンク。
- 200 以外のステータス コードへの内部リンク。
- 内部的にリンクされた、インデックスに登録できない URL の割合。
7.残りのクロールの問題を監査する
上記の最適化がすべて完了しても、クロールの有効性が最適ではない場合は、詳細な監査を実施してください。
クロールの問題を特定するために、残りの Google Search Console 除外のサンプルを確認することから始めます。
それらに対処したら、手動クロール ツールを使用して、Googlebot のようにサイト構造内のすべてのページをクロールして、さらに深く掘り下げます。 これを Googlebot の IP に絞り込んだログ ファイルと相互参照して、クロールされているページとクロールされていないページを把握します。
最後に、ログ ファイル分析を開始し、少なくとも 4 週間、理想的にはそれ以上のデータについて、Googlebot IP に絞り込みました。
ログ ファイルの形式に慣れていない場合は、ログ アナライザー ツールを活用してください。 最終的に、これは、Google がサイトをどのようにクロールするかを理解するための最良の情報源です。
監査が完了し、特定されたクロールの問題のリストができたら、予想される作業レベルとパフォーマンスへの影響によって各問題をランク付けします。
注: 他の SEO 専門家は、SERP からのクリックがランディング ページ URL のクロールを増加させると述べています。 ただし、これをテストで確認することはまだできていません。
クロールの予算よりもクロールの有効性を優先する
クロールの目的は、最大限のクロールを獲得することでも、Web サイトのすべてのページを繰り返しクロールすることでもありません。ページが作成または更新されるときに、SEO 関連のコンテンツのクロールをできる限り近づけることです。
全体として、予算は問題ではありません。 何に投資するかが重要です。
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。