
カノニカルタグSEOについて知っておくべきこと
公開: 2022-02-22あなたが技術に精通していない場合、正規タグSEOは複雑で風変わりに聞こえるかもしれません。 ただし、これは検索エンジン最適化の武器として重要なツールであり、重複するコンテンツを管理する場合にはかけがえのないものです。 カノニカルがどのような目的を果たし、それらを適切に使用するかを理解することで、ページをより適切に最適化し、リンクの公平性を維持できます。
SEOの他の側面と同様に、カノニカルが実行できることと実行できないこと、およびそれらをどのように使用するかについては、多くの推測があります。 これらのタイプのタグは10年以上前から存在しているため、インターネット上には古くて誤解を招く情報がたくさん出回っています。
したがって、この記事では、2022年の正規タグSEOについて知っておく必要のあるすべてのことについて説明します。読んでメモを取りましょう。
カノニカルタグとは何ですか?
正規タグは、ページのHTMLのヘッドセクションに配置できるコードの一部です。 これらは、Webサイトに同一、類似、または密接に関連するコンテンツのURLがある場合に使用され、検索エンジンに最も重要なものを通知するのに役立ちます。
標準リンクタグは次のようになります。
<link rel =” canonical” href =” https://example.com/text/text-text” />
タグ内のリンクはメインページのURLであり、Googleの規制に従い、相対URLではなく絶対URLである必要があります。 これは、プロトコル、ドメイン、およびWebサイト内のコンテンツの場所を含むページの完全なアドレスを使用する必要があることを意味します。
<link rel =” canonical” href =” https://example.com/text/text-text” />
それ以外の
<link rel =” canonical” href =” text / text-text” />

ソース
どのタイプのページに正規タグが必要ですか?
ページの繰り返しなど、明らかに重複するコンテンツがない場合でも、URLが重複している可能性があり、ボットを混乱させ、インデックス作成の挫折を招く可能性があります。 これらは、パスウェイの使用方法の不一致やプロトコルの問題などが原因で、コンテンツ管理システム(CMS)によって作成される可能性があります。
それでは、正規タグSEOの恩恵を受けることができるページの種類と、それぞれの場合の進め方を見てみましょう。
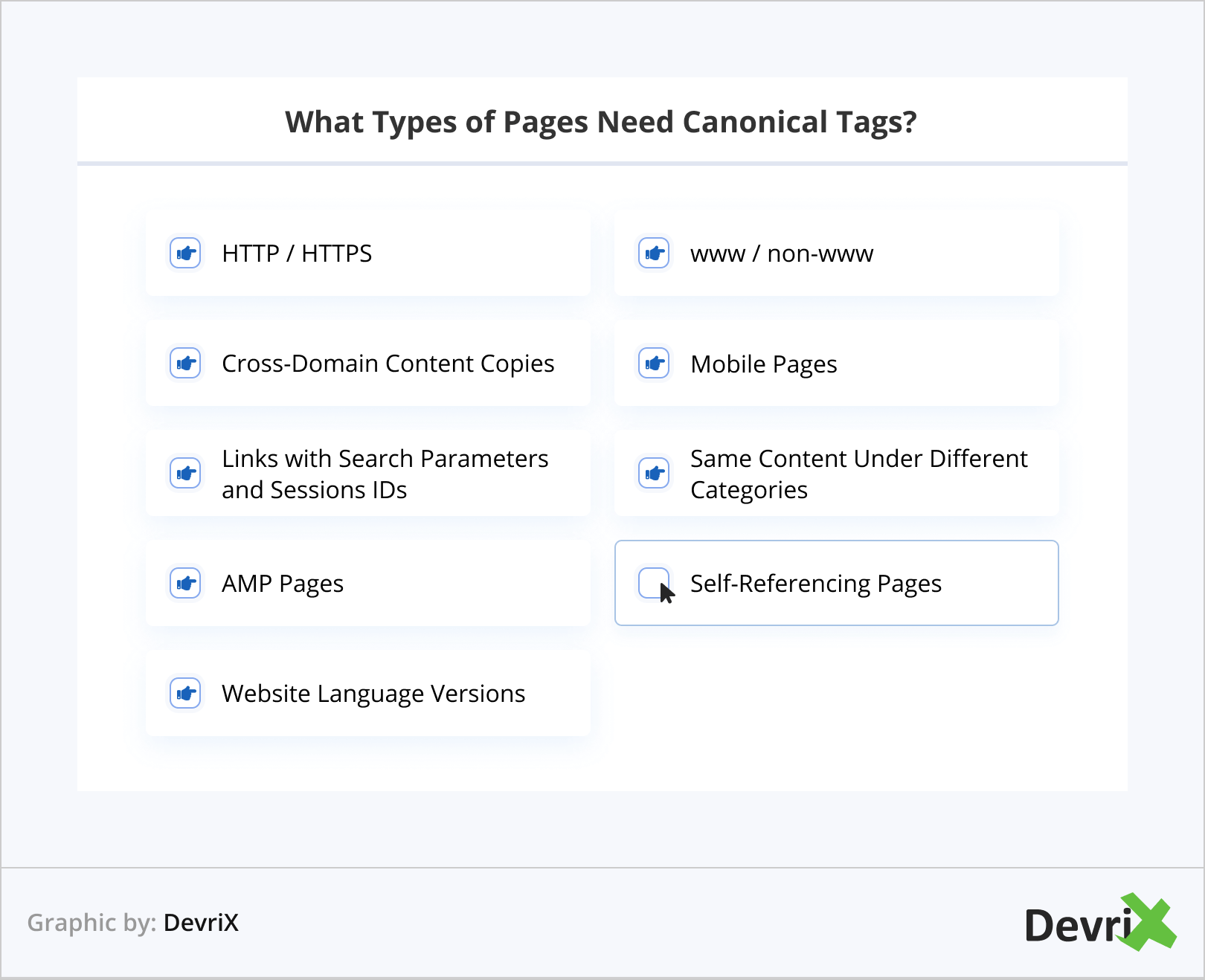
HTTP / HTTPS
GoogleはHTTPSプロトコルを優先するため、デフォルトでは、HTTPバージョンとHTTPSバージョンの両方を含むページがあり、前者から後者へのリダイレクトがない場合、ボットはHTTPSバージョンを正規として表示します。 301リダイレクトを使用してHTTPバージョンを完全に破棄したくない場合は、HTTPSに正規タグを追加する必要があります。
ただし、何らかの理由でHTTPバージョンをより重要なバージョンとしてマークしたい場合は、正規タグを追加できます。 ただし、推奨事項にかかわらず、Googleが安全なバージョンを表示することを選択する場合があることに注意してください。
www/非www
ボットの場合、 https://www.example.com/textとhttps://example.com/textは同じものではありません。 理想的には、リンクのwwwバージョンまたはwww以外のバージョンを一貫して使用する必要があります。
ただし、訪問者が検索エンジンやブラウザに何を入力できるか、そして訪問者が何をブックマークしているのかを確認することはできません。 バージョンの1つを正規化すると、ボットはどちらが好きかを確実に認識し、それに集中することができます。
クロスドメインコンテンツコピー
デジタル出版社がよく行うようにコンテンツをシンジケート化する場合、または複数のドメインで作品を公開したい場合は、元のページ(自分のWebサイトにあるページ)を正規化する必要があります。
これは、ページにrel =” canonical”タグを追加し、サイト運営者に元のタグへのリンクを使用してページのコードに追加するように依頼することで実行できます。 このように、すべてのリンクジュースとエクイティはあなたのウェブサイトに向けられます。
さらに、ボットは複数の場所で同じコンテンツに遭遇するため、どのリンクを上位にランク付けするかについて混乱することはありません。
モバイルページ
ウェブサイトがレスポンシブでなく、スタンドアロンのモバイルバージョンを使用している場合、GoogleはデスクトップとモバイルのURLを別々のページとして表示します。
https://m.example.com/text≠https://example.com/text
混乱を避け、2つの間で権限が分散されるのを防ぐために、そのうちの1つだけを正規として設定する必要があります。 モバイルファーストのインデックス作成を実施している場合は、モバイルページを正規化するのが最適です。
ただし、心配する必要はありません。ユーザーがデスクトップでクエリを入力すると、タグに関係なくボットに適切なバージョンが表示されます。
AMPページ
コンテンツのAMPバージョンを使用している場合、ベストプラクティスは、AMPページを元のアドレスと同様のアドレスでホストすることです。
https://example.com/news
https://amp.example.com/news
この場合、メインページを正規化し、元のリンクを含む正規タグをAMPバージョンのコードに追加する必要があります。 このようにして、ボットはどちらがメインページであるかをより簡単に識別します。
検索パラメータとセッションIDとのリンク
セッションIDとURLパラメータはボットを混乱させることが多く、その結果、ボットがページのインデックスを適切に作成できなくなる可能性があります。 これらの使用を避けられない場合は、メインページを正規化する必要があります。これにより、ボットは、リンクアドレスの拡張子が単にそれであり、新しいページではないことを認識します。
パラメータは、eコマースWebサイトのコンテンツをより適切に整理するために最も一般的に使用されます。 URLに値を追加して、色、サイズ、タイプなどの商品のバリエーションを示し、さまざまな検索フィルターやキャンペーン追跡情報などを適用するために使用できます。
パラメータを含むページは次のようになります。
https // www.example.com / page?key1 = value1&key2 = value2
それ以外の
https // www.example.com / page
セッションIDは、Webサイトでの個々のユーザーの行動を追跡するために使用できます。 たとえば、eコマースストアでは、IDは、ユーザーがアクセスしたページをWebサイトに表示するCookieの代わりに使用できます。 この情報を使用して、ユーザーのカートと最後にアクセスしたアイテムがWebサイトを離れるまで保存されます。
セッションIDを持つページは次のようになります。
https://example.com/index.jsp;jsessionid=07D3CCD4D9A6A9F3CF9CAD4F9A728F44
それ以外の
https // www.example.com / page
理想的には、ボットはパラメーターとセッションIDの両方を認識するのに十分スマートである必要があります。 ただし、場合によっては混乱することがあります。そのため、正規タグを設定すると、ページを配布するのではなく、ページのランキングを統合するのに役立ちます。
異なるカテゴリの同じコンテンツ
Webサイトの複数のカテゴリに同じコンテンツがある場合、同じページにつながるほぼ同じコンテンツを持つ複数のURLがあります。
https://example.com/category1/text-text/
https://example.com/category2/text-text/
内部リンク構築戦略でページの1つを正規としてマークアップせず、一貫してそのページにリンクしていない場合、ボットはこれらを重複と見なします。 どちらをユーザーに表示するかを決定するのに時間(およびクロール予算)が無駄になるだけでなく、2つを別々にランク付けすることもできます。
自己参照ページ
冗長に聞こえるかもしれませんが、自己参照は重要であり、GoogleのJohn Muellerによって、Redditでのユーザーの質問への回答にSEO値があることが確認されています。

<link rel =” canonical” href =” b.html” />これがa.htmlにある場合は、通常の正規(技術的には正規のリンク要素)であり、b.htmlにある場合は、自己参照です。一。
人々があなたのページにどのようにリンクしているかわからないので、自己参照的なものは小さな間違いを片付けるのに役立ちます。 たとえば、リンクがb.html?utm = cheeseに移動する場合、通常、サーバーはb.htmlのみを表示し、そこにある自己参照の正規リンク要素は、検索エンジンが代わりに「b.html」を使用するように促します。 「b.html?utm=cheese」。
一言で言えば、元のページはrel = canonicalでタグ付けすることができ、またタグ付けする必要があります。これにより、ボットにとって、実際に元のページであることが明確になります。
ウェブサイトの言語バージョン
Webサイトの言語バージョンが異なる場合は、そのうちの1つだけを正規として定義することをお勧めします。 この場合、自己参照rel = canonicalタグを、メインのタグと見なすコードに追加し、他のタグをそのコードにポイントすることができます。

2つのページのコンテンツが類似または同じであるが重複していない理由をGoogleが理解しやすくするために、hreflangタグ属性を使用する必要があります。 たとえば、Webサイトに英国英語、米国英語、スペイン語のバージョンがある場合、それぞれのバージョンに次のスニペットを追加できます。
link rel =” alternate” href =” http://example.com” hreflang =” en-us” />
link rel =” alternate” href =” http://example.com” hreflang =” en-uk” />
link rel =” alternate” href =” http://example.com” hreflang =” en-es” />
米国英語版を正規版としてマークアップします。
ただし、ユーザーの場所に基づいて、Googleはユーザーを表示するページの最後の単語を取得し、提案を無視する場合があることに注意してください。
カノニカルタグSEOは何に使用されますか?
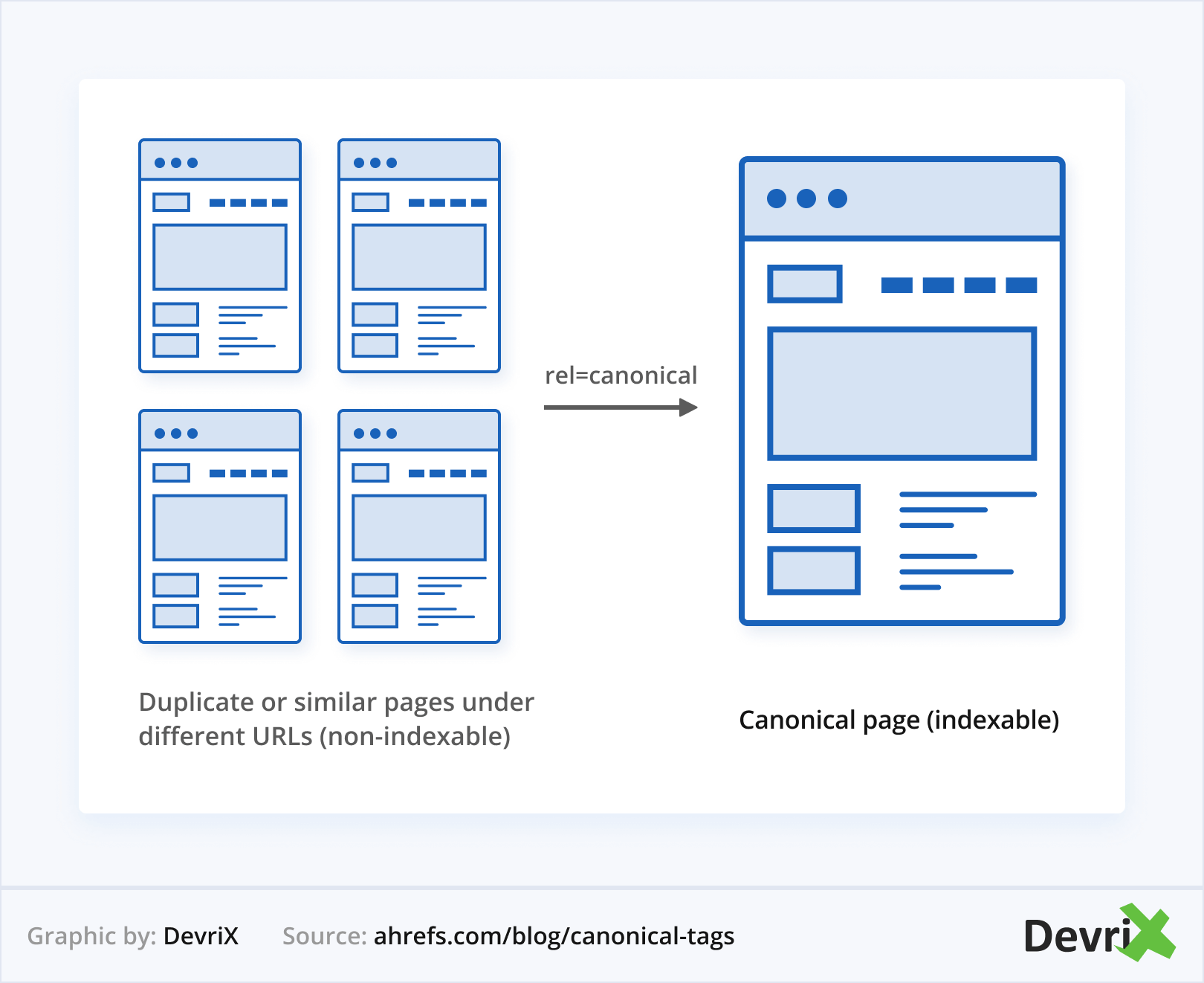
一言で言えば、正規タグSEOの主な目的は、重複を管理し、リンクの公平性を維持することです。 何らかの理由で、同じページにつながる複数のURLがある場合、ボットはどのURLをランク付けするかについて混乱する可能性があります。
人間として、あなたはリンクを実際には同じものとして見ます。 ただし、ボットの場合、各URLには意味があります。 どちらがより重要であると考えるかを指定しない場合、Googleがこの選択を行います。 ただし、あなたとGoogleは、リンクの重要性について異なる優先順位と異なる理解を持っている場合があります。
さらに、どちらが正規パスであるかを指定しない場合、それぞれの個別のリンクが、異なる装いで検索結果のユーザーに提供されます。 これは、すべての権限とリンクジュースが、ページの1つだけに蓄積されるのではなく、ページ間でリークされることを意味します。
繰り返しになりますが、Googleはページの1つを正規のものとして受け入れることを決定しますが、参照するための指示がない場合、理論的には、毎回異なる決定を下す可能性があります。
なぜカノニカルタグを誤用してはいけないのですか?
人々は正規タグSEOで注意深くスレッド化する必要があります。 別の理由でボットを操作したり、タグを誤用したりすると(例を示します)、クローラーを混乱させ、リンクのインデックス作成をあきらめる可能性があります。
さらに、大規模なWebサイトでカノニカルを置き忘れると、クロールの予算が無駄になる可能性があります。 ボットはあなたのページで何が起こっているのかわからない場合、あなたが公開した新しいコンテンツをクロールする代わりに、それを理解しようとし続けます。 これにより、彼らの仕事は遅れ、Googleの検索ランキングでのあなたのウェブサイトのパフォーマンスに影響を及ぼします。
つまり、カノニカルを間違った方法で使用すると、誰もいなくなった場所で問題が発生するリスクがあります。
カノニカルタグSEOに関する一般的な誤解
SEOの正規タグに関する最も一般的な誤解は次のとおりです。 わかりやすくするために、ここに要約しました。
- Googleはそれらを遵守する義務があります。 誤り。 カノニカルは推奨事項であり、ルールではありません。 それらは、あなたが最も重要であると考える重複ページをグーグルに提案する方法として役立ちます。 ただし、これらのタグを使用しても、ボットは別のページがより適切であると判断し、必要なページよりも選択する可能性があります。
- これらは、トピックごとにコンテンツをグループ化するために使用されます。 カノニカルの唯一の目的は、ボットが重複するURLを分類できるようにすることです。 つまり、類似したトピックに関するページがあり、ターゲットが異なり、コンテンツが異なる場合、正規タグはリンクの公平性を統合するための適切なツールではありません。 2つのページが大きく異なるが、rel = canonicalで接続されている場合、ボットはタグが存在する理由を理解しようとしてそれらをクロールし続けます。これにより、クロールの予算が無駄になります。
- 正規タグはリダイレクトを置き換えることができます。 正規化は、リダイレクトと同じ重みを持ちません。これは、前述のように、これはディレクティブではなく、提案であるためです。 したがって、ページにアクセスしたり優先順位を付けたりしたくない場合は、タグは役に立ちません
- 常にCanonicalsを使用する必要があります。 必ずしも。 ここでの目標は、そもそも存在してはならない技術的な問題を回避することです。 URLがWebサイト全体で一貫していて、前に説明した問題がない場合は、正規のタグは必要ない可能性があります。 とはいえ、よくわからない場合は、万が一の場合に備えて、rel=canonicalタグを使用して最も重要なページのみを自己参照することができます。
ページを正規として統合する方法
グーグルは常にそれが標準的であると考えるページの最後の言葉を持っていますが、あなたが好むものを強く推薦する方法があります。
SEOを扱ったことがある人が知っているように、Googleはさまざまなシグナルを使用して、Webのクロール、理解、およびインデックス作成の方法を決定します。 適切なものを使用すると、耳を傾ける可能性が高くなります。
カノニカルの場合、GoogleのJohn Muellerは、ボットは実際、Webサイトが望んでいることを読み込もうとしていると述べています。
では、HTMLヘッダーにrel =” canonical”リンクタグを追加する以外に、必要なものをGoogleに伝えるにはどうすればよいでしょうか。
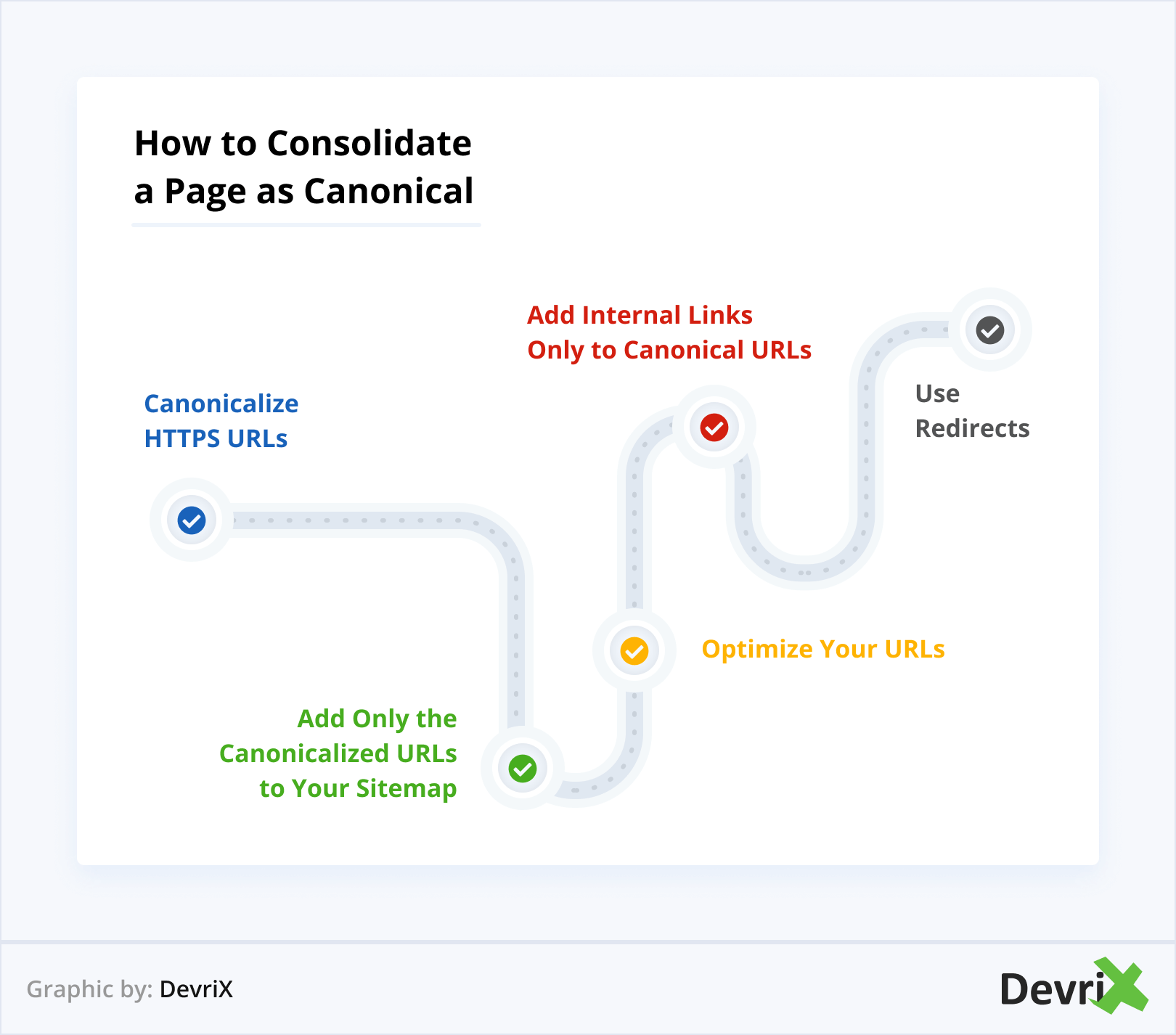
HTTPSURLを正規化する
GoogleはHTTPパスよりもHTTPSパスを強く推奨しています。これは、HTTPSパスがSSL(またはTLS)証明書を持ち、より安全な情報転送を提供するためです。 したがって、リンクが両方のタイプを使用している場合、GoogleはHTTPSタイプによって描画されます。
ボットを混乱させて、ボットが正しいことを知っていることと、ボットに強制しているように見えることのどちらかを選択させることを避けるために、HTTPSリンクを常に正規化するのが最善です。
正規化されたURLのみをサイトマップに追加します
XMLサイトマップはSEO戦略の重要なツールであり、ボットがコンテンツに優先順位を付けてインデックスを作成するのに役立ちます。 Googleは、マップ内のすべてのURLをデフォルトで正規と見なします。これは、これらが最も重要なページ、つまりインデックスに登録するように指示したページであると想定されているためです。
したがって、マップを作成するときは、マスターコピーと見なすページのみを追加するようにしてください。
URLを最適化する
ボットは、URLの外観にも関心があります。 これは、ユーザーがそれらを簡単に理解できるかどうかを意味します。 GoogleはSERPに表示されるものを選択する傾向があるため、混乱を招くパラメータを持つリンクは回避される可能性が高くなります。 そのようなリンクがユーザーのクエリに完全に一致する場合はランク付けすることは可能ですが、申し訳ありませんが安全である方がよいでしょう。
標準URLにのみ内部リンクを追加する
内部リンクは、どのリンクが他のリンクよりも重要であるかをGoogleに示すための優れた方法です。 記事にリンクを追加するときは、それらが常に正規化されており、メインURLを指していることを確認してください。 このようにして、ボットはどのページがより重要であるかを認識し、それらをより関連性があると見なします。
リダイレクトを使用する
重複するページの1つが使用できなくなった場合、そのページをクロールしてインデックスに登録したくないことをGoogleに伝える最良の方法は、301サーバーリダイレクトを作成することです。 このように、両方のページにアクセスして選択する代わりに、ボットは古いページを完全にスキップして新しいページを優先します。
これは、WebサイトにSSLまたはTLSをインストールしていて、すべてのHTTPリンクがHTTPSになる場合に特に推奨されます。 リダイレクトを作成すると、古いリンクをブックマークまたはバックリンクした人は誰でも、新しい安全なアドレスに自動的にリダイレクトされます。 これにより、ボットが自分で決定する必要がなくなります。
ただし、リダイレクトを使用すると、Googleとユーザーの両方が古いページに完全にアクセスできなくなることに注意してください。 これは抜本的な対策であり、ページが本当に必要なくなったが、公平性を維持したい場合にのみ使用する必要があります。 また、リダイレクトが多すぎると、Webサイトの速度が低下する可能性があります。
結論
カノニカルタグSEOは、それを理解し、適切なタグの使用方法を知っていれば複雑ではありません。
覚えておくべき重要なことは、rel = canonical属性の主な目的は、URLの重複を管理し、さまざまなURLが類似したコンテンツを指している理由をボットが理解できるようにすることです。
あなたが技術に精通しておらず、あなたのウェブサイトの標準的なSEOを管理する助けが必要な場合は、遠慮なく私たちに電話してください!