
Google エンティティと GPT-4 を使用して記事のアウトラインを作成する方法
公開: 2023-06-06この記事では、スクレイピングと Google のナレッジ グラフを使用して、記事の概要と要約を生成する自動プロンプト エンジニアリングを実行する方法を学びます。記事がうまく書かれていれば、上位にランクされるための多くの重要な要素が含まれます。
根本的に、私たちは GPT-4 に対し、キーワードと、ユーザーが選択した高ランキング ページで見つかった上位のエンティティに基づいて記事の概要を作成するように指示しています。
エンティティは、顕著性スコアによって順序付けされます。
「なぜ顕著性スコアなのか?」 と尋ねるかもしれません。
Google は API ドキュメントの中で顕著性を次のように説明しています。
「エンティティの顕著性スコアは、ドキュメント テキスト全体に対するそのエンティティの重要性または中心性に関する情報を提供します。 0 に近いスコアは顕著性が低く、1.0 に近いスコアは顕著性が高くなります。」
これは、作成するコンテンツにどのエンティティが存在する必要があるかを決定するために使用するのに非常に優れた指標だと思いませんか?
入門
これには 2 つの方法があります。
- 約 5 分 (コンピューターをセットアップする必要がある場合は 10 分ほど) かけて、マシンからスクリプトを実行します。または…
- 私が作成した Colab にジャンプして、すぐに遊んでみてください。
私は最初のものに興味がありますが、1 日に 1 つか 2 つの Colab に飛びついたこともあります。 😀
まだここにいて、自分のマシンでこのセットアップを行いたいが、まだ Python または IDE (統合開発環境) がインストールされていないと仮定して、最初に、使用するためのマシンのセットアップについて簡単に読んでいただくよう案内します。ジュピターノート。 約 5 分もかからないはずです。
さあ、出発です!
Google エンティティと GPT-4 を使用して記事のアウトラインを作成する
わかりやすくするために、手順を次のようにフォーマットします。
- Step : 現在進行中のステップの簡単な説明。
- コード: そのステップを完了するためのコード。
- 説明: コードの動作についての簡単な説明。
ステップ 1: 欲しいものを教えてください
アウトラインの作成に入る前に、必要なものを定義する必要があります。
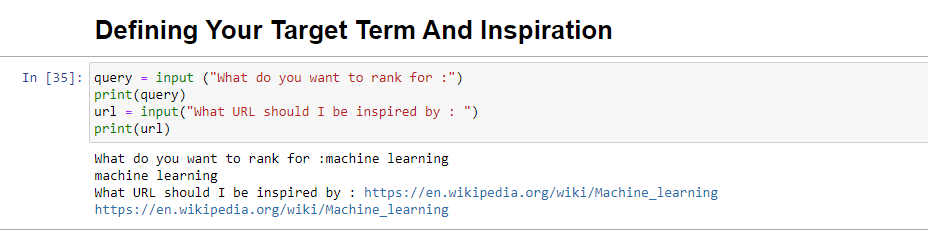
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)このブロックを実行すると、ユーザー (おそらくあなた) に、記事をランク付けしたい/掲載したいクエリを入力するよう求められ、また、ランク付けしたい記事の URL を入力する場所も表示されます。インスピレーションを受ける作品。
上位にランクされ、あなたのサイトに適した形式になっており、サイトの強さだけでなく記事の価値だけでランキングに値すると思われる記事をお勧めします。
実行すると、次のようになります。
ステップ 2: 必要なライブラリをインストールする
次に、魔法を実現するために使用するすべてのライブラリをインストールする必要があります。
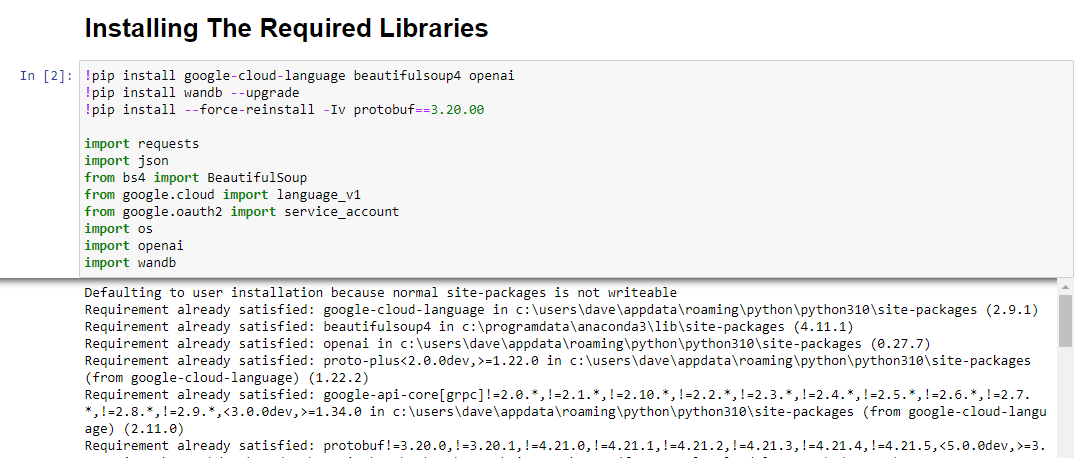
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandb次のライブラリをインストールしています。
- リクエスト: このライブラリを使用すると、Web サイトまたは Web API からコンテンツを取得するための HTTP リクエストを作成できます。
- JSON : JSON 文字列を Python オブジェクトに解析したり、Python オブジェクトを JSON 文字列にシリアル化したりするなど、JSON データを操作する関数を提供します。
- BeautifulSoup : このライブラリは Web スクレイピングの目的で使用されます。 これは、HTML または XML ドキュメントを解析してナビゲートし、そこから関連情報を抽出するのに役立ちます。
- Google.cloud. language_v1 : 自然言語処理機能を提供する Google Cloud のライブラリです。 これにより、感情分析、エンティティ認識、テキスト データの構文分析などのさまざまなタスクを実行できます。
- Google.oauth2.service_account : このライブラリは、Google OAuth2 Python パッケージの一部です。 サービス アカウントを使用した Google API での認証のサポートを提供します。これは、Google Cloud プロジェクトのリソースへの限定的なアクセスを許可する方法です。
- OS : このライブラリは、オペレーティング システムと対話する方法を提供します。 ファイル操作、環境変数、プロセス管理などのさまざまな機能にアクセスできます。
- OpenAI : このライブラリは OpenAI Python パッケージです。 GPT-4 (および 3) を含む OpenAI の言語モデルと対話するためのインターフェイスを提供します。 これにより、開発者はテキストを生成したり、テキスト補完を実行したりすることができます。
- Pandas : データ操作と分析のための強力なライブラリです。 テーブルや CSV ファイルなどの構造化データを効率的に処理および分析するためのデータ構造と関数を提供します。
- WandB : このライブラリは「Weights & Biases」の略で、実験の追跡と視覚化のためのツールです。 これは、メトリクス、ハイパーパラメータ、および機械学習実験のその他の重要な側面をログに記録して視覚化するのに役立ちます。
実行すると次のようになります。
マーケティング担当者が頼りにする毎日のニュースレター検索を入手します。
規約を参照してください。
ステップ 3: 認証
認証を取得するために、少し脇道にそれる必要があります。 OpenAI API キーと Google Knowledge Graph Search の認証情報が必要になります。
これには数分しかかかりません。
OpenAI API の取得
現時点では、待機リストに参加する必要がある可能性があります。 幸運にも API に早期にアクセスできたので、入手したらすぐにセットアップできるようにこれを書いています。
サインアップ イメージは GPT-3 のもので、フローがすべての人に利用可能になると GPT-4 用に更新されます。
GPT-4 を使用するには、それにアクセスするための API キーが必要です。
これを入手するには、OpenAI の製品ページに移動し、 [開始する]をクリックします。
サインアップ方法を選択し (私は Google を選択しました)、確認プロセスを実行します。 この手順では、テキストを受信できる電話にアクセスする必要があります。
それが完了したら、API キーを作成します。 これは、OpenAI がスクリプトをアカウントに接続できるようにするためです。
彼らは誰が何をしているのかを把握し、あなたがしていることに料金を請求するかどうか、またその料金をいくら請求するかを判断する必要があります。
OpenAIの価格設定
サインアップすると、5 ドルのクレジットが付与されます。これは、試しているだけであれば、驚くほど遠くまで到達できるでしょう。
この記事の執筆時点では、それ以降の価格は次のとおりです。

OpenAI キーの作成
キーを作成するには、右上のプロフィールをクリックし、 [API キーの表示]を選択します。
...そしてキーを作成します。
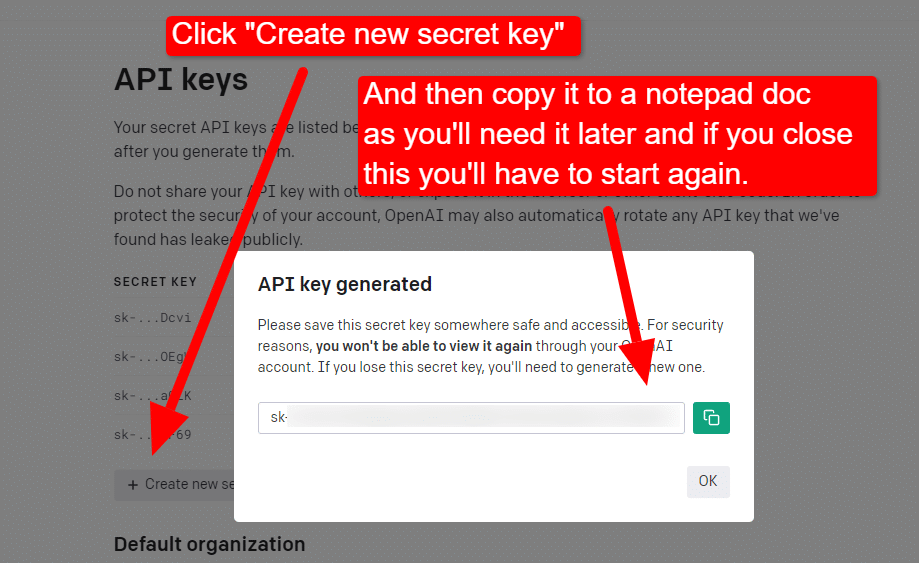
ライトボックスを閉じるとキーを表示できなくなり、キーを再作成する必要があるため、このプロジェクトではキーをメモ帳ドキュメントにコピーするだけですぐに使用できます。
注:キーを保存しないでください (デスクトップ上のメモ帳ドキュメントの安全性は高くありません)。 一時的に使用したら、保存せずにメモ帳ドキュメントを閉じます。
Google Cloud 認証の取得
まず、Google アカウントにログインする必要があります。 (あなたは SEO サイトにアクセスしているので、SEO サイトを持っていると思います。 🙂)
それが完了したら、必要に応じてナレッジ グラフ API 情報を確認することも、API コンソールに直接ジャンプして作業を開始することもできます。
コンソールにアクセスしたら、次のようにします。
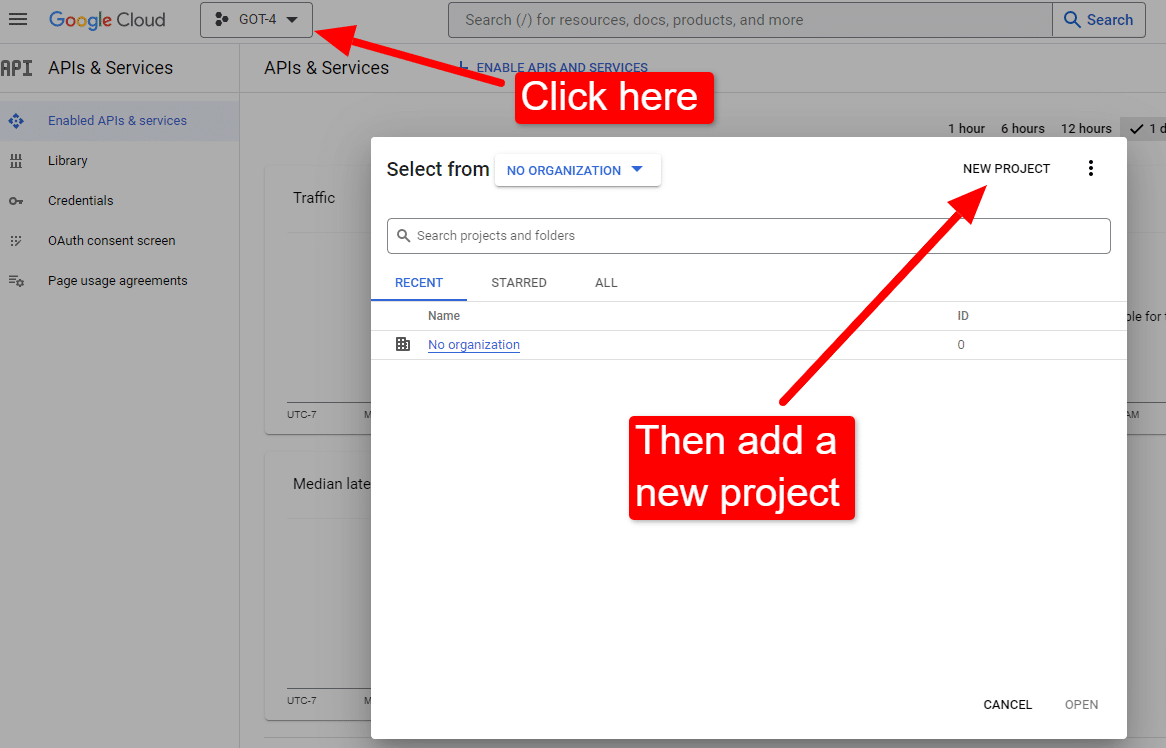
「Dave's Awesome Articles」などの名前を付けます。 ご存知のように…覚えやすいです。
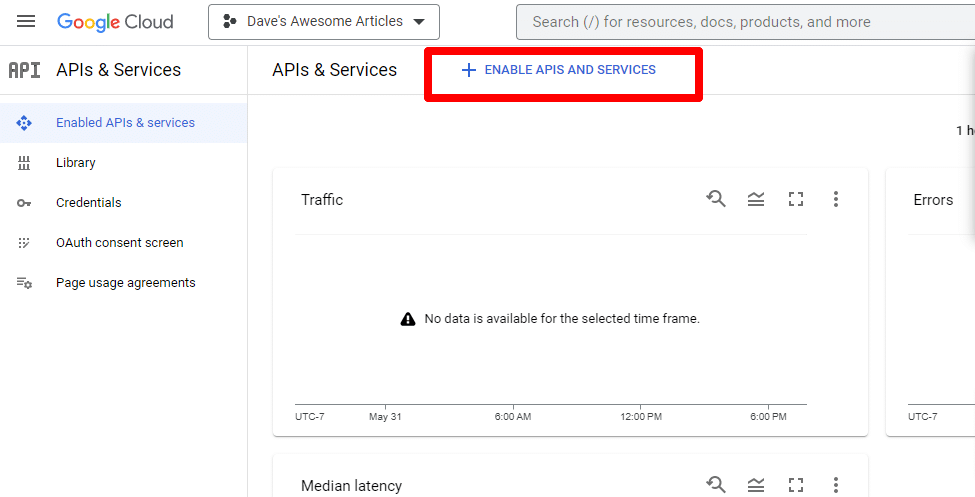
次に、 [API とサービスを有効にする] をクリックして API を有効にします。
Knowledge Graph Search API を見つけて有効にします。
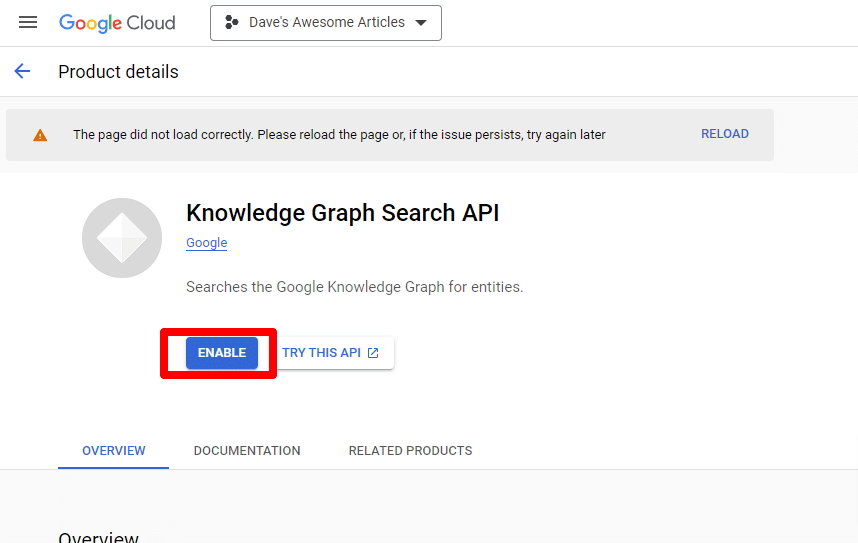
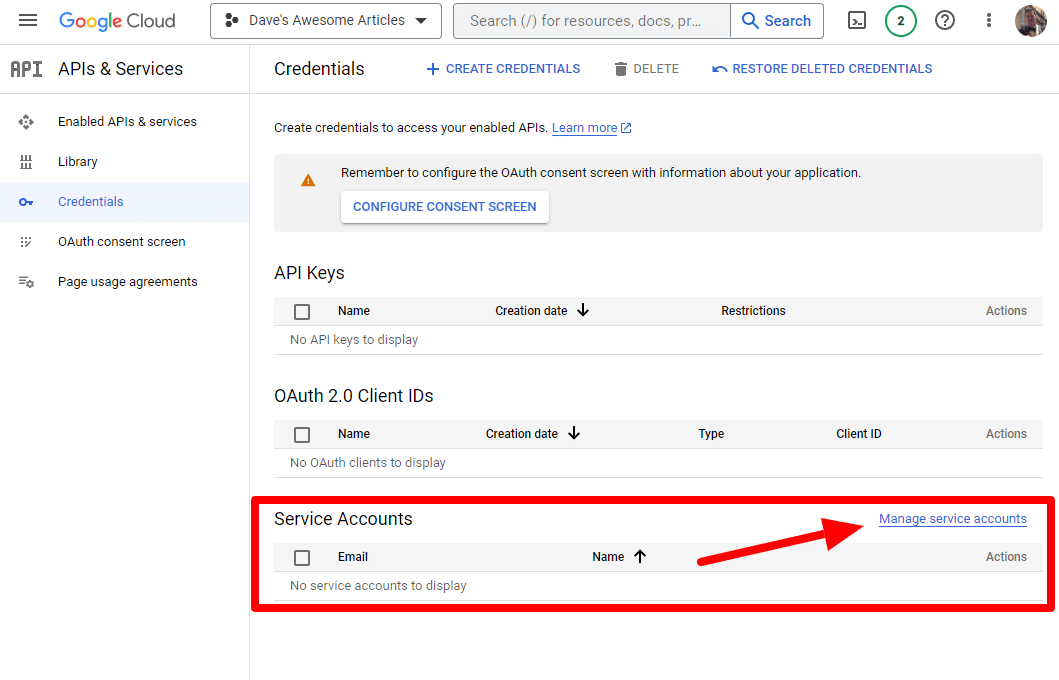
その後、メイン API ページに戻り、認証情報を作成できます。
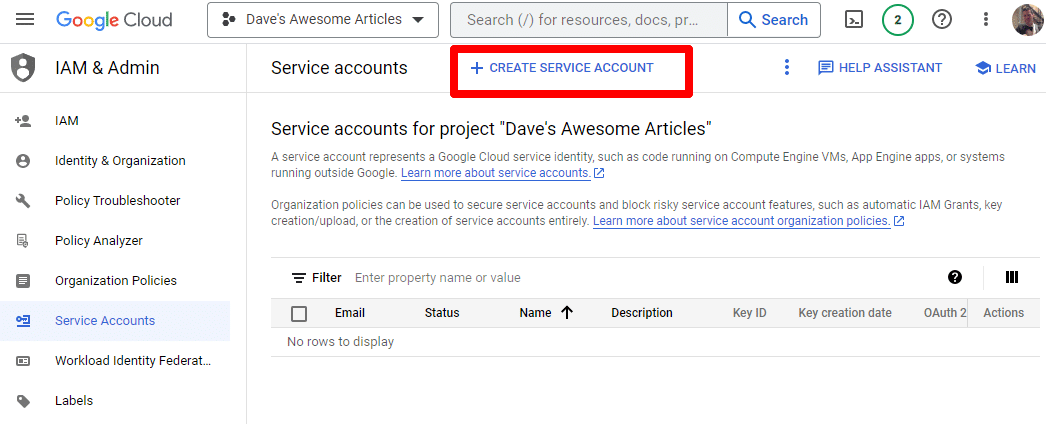
そしてサービスアカウントを作成していきます。

サービス アカウントを作成するだけです。
必要な情報を入力します。
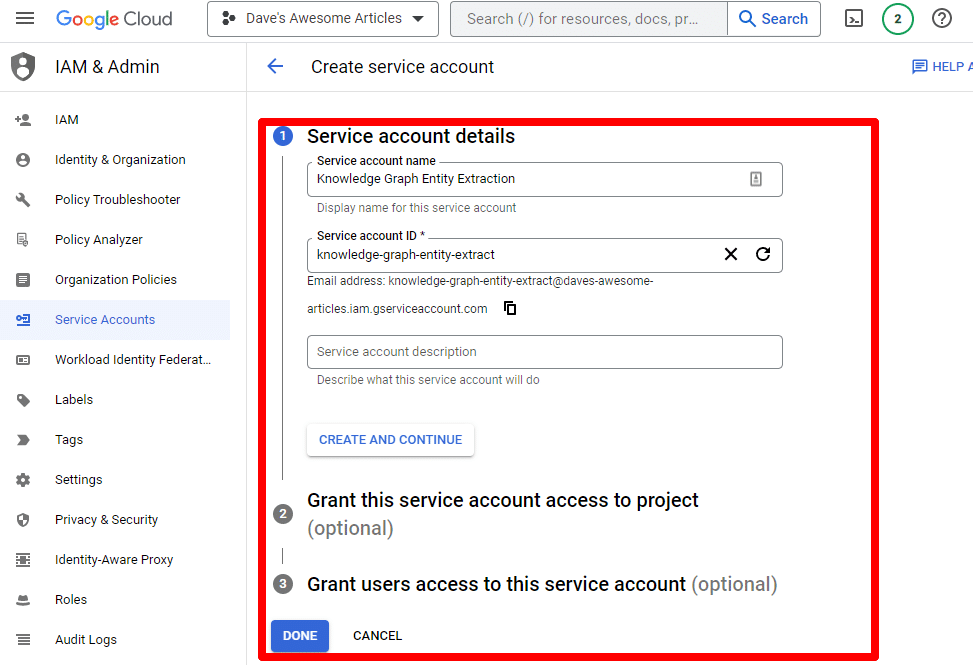
(名前を付けて所有者権限を付与する必要があります。)
これでサービスアカウントが完成しました。 残っているのはキーを作成することだけです。
[アクション]の下にある 3 つの点をクリックし、 [キーの管理]をクリックします。
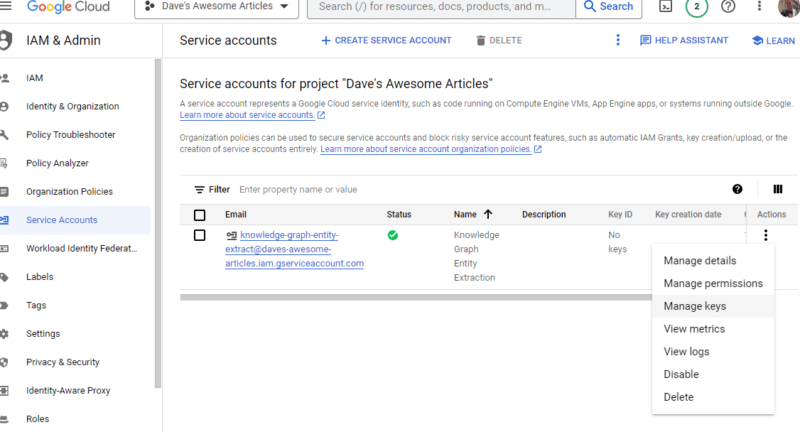
「キーの追加」をクリックし、 「新しいキーの作成」をクリックします。
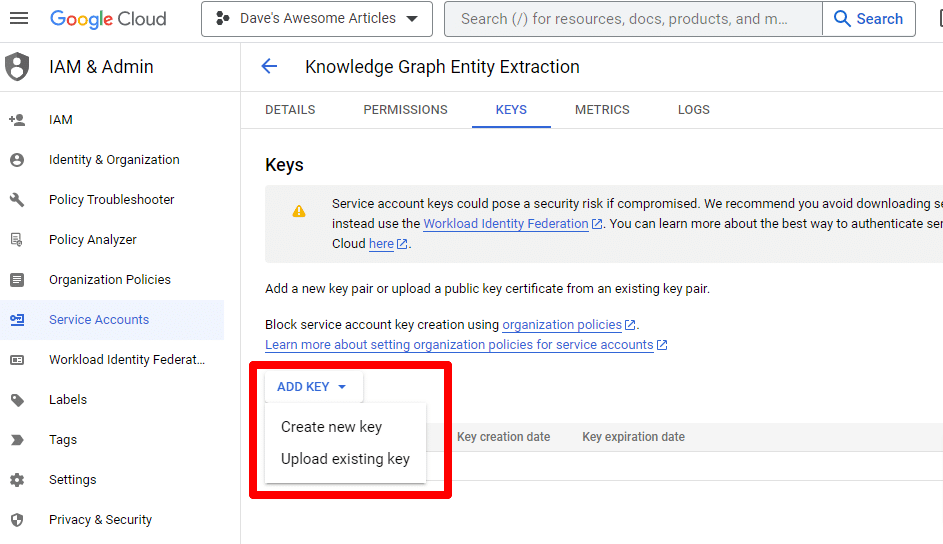
キーの種類は JSON になります。
すぐに、デフォルトのダウンロード場所にダウンロードされることがわかります。
このキーは API へのアクセスを許可するため、OpenAI API と同様に安全に保管してください。
さて…戻ってきました。 スクリプトを続行する準備はできていますか?
これらを取得したので、API キーとダウンロードしたファイルへのパスを定義する必要があります。 これを行うコードは次のとおりです。
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") YOUR_OPENAI_API_KEY独自のキーに置き換えます。
また、 /PATH-TO-FILE/FILENAME.JSON FILENAME.JSON を、ダウンロードしたサービス アカウント キーへのパス (ファイル名を含む) に置き換えます。
セルを実行すれば、次に進む準備は完了です。
ステップ 4: 関数を作成する
次に、次のことを行う関数を作成します。
- 上で入力した Web ページをスクレイピングします。
- コンテンツを分析してエンティティを抽出します。
- GPT-4 を使用して記事を生成します。
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()これはコメントで説明されているとおりです。 上記の目的のために 3 つの関数を作成しています。
鋭い目を持つ人は次のことに気づくでしょう。
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, コンテンツを編集し ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. )、ChatGPT に求める役割を説明できます。 口調を追加することもできます (例: 「あなたはフレンドリーな作家ですね…」)。
ステップ 5: URL をスクレイピングしてエンティティを出力する
今、私たちは手を汚しています。 それは時間です:
- 上で入力した URL をスクレイピングします。
- 段落タグ内にあるすべてのコンテンツを取得します。
- Google Knowledge Graph APIを通じて実行します。
- エンティティを出力して簡単にプレビューします。
基本的に、この段階では何でも確認する必要があります。 何も表示されない場合は、別のサイトを確認してください。
content = scrape_url(url) entities = analyze_content(content)1 行目は、最初に入力した URL をスクレイピングする関数を呼び出していることがわかります。 2 行目では、コンテンツを分析してエンティティと主要なメトリクスを抽出します。
また、analyze_content 関数の一部では、クイック参照と検証のために見つかったエンティティのリストも出力します。
ステップ 6: エンティティを分析する
最初にスクリプトをいじり始めたとき、20 個のエンティティから始めましたが、これは通常多すぎることがすぐにわかりました。 しかし、デフォルト (10) は正しいのでしょうか?
これを確認するには、簡単に評価できるようにデータを W&B テーブルに書き込みます。 将来の評価のためにデータが無期限に保存されます。
まず、サインアップには 30 秒ほどかかります。 (この種のことは無料ですので、ご安心ください。) https://wandb.ai/site で行うことができます。
それが完了したら、これを行うコードは次のとおりです。
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()実行すると、出力は次のようになります。
リンクをクリックして実行結果を表示すると、次の内容が表示されます。
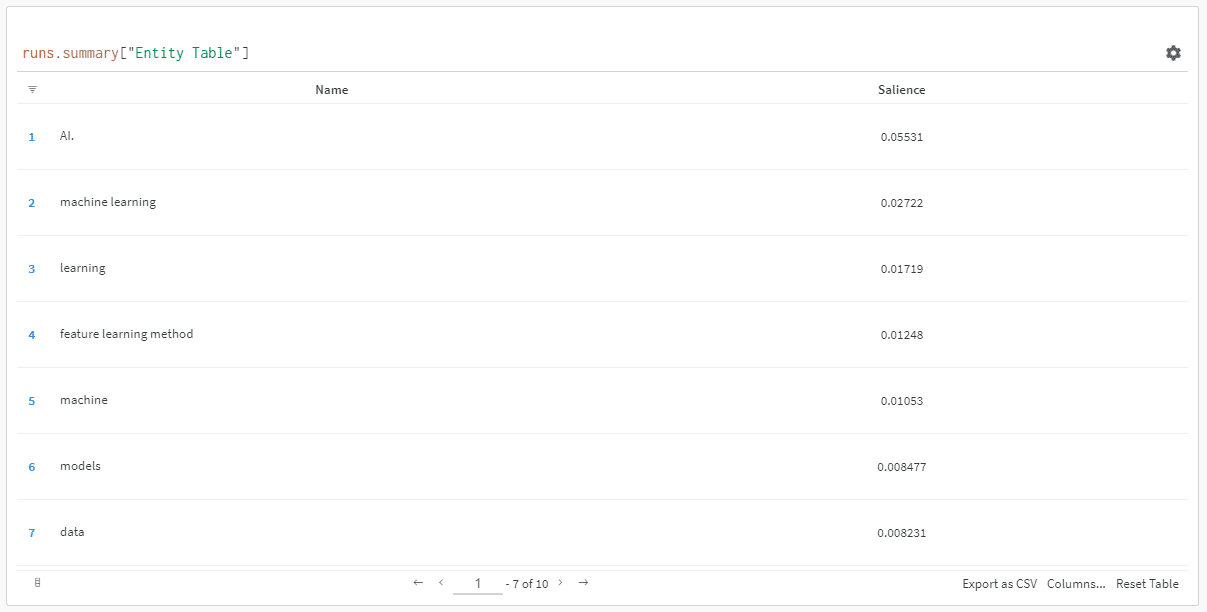
顕著性スコアの低下が見られます。 このスコアは、クエリではなく、その用語がページにとってどれだけ重要かを計算するものであることに注意してください。
このデータを確認するときは、顕著性に基づいてエンティティの数を調整するか、無関係な用語がポップアップしたときにのみエンティティの数を調整するかを選択できます。
エンティティの数を調整するには、関数セルに移動して次を編集します。
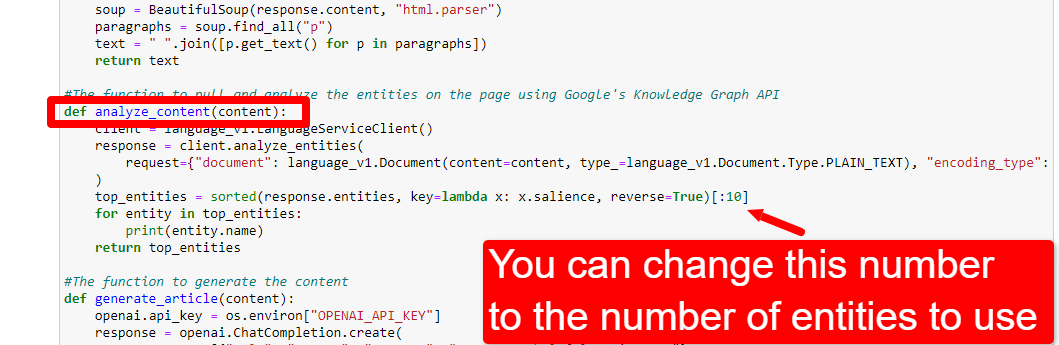
その後、セルを再度実行し、新しいエンティティ数を使用するためにコンテンツを収集して分析するために実行したセルを実行する必要があります。
ステップ 7: 記事のアウトラインを作成する
皆さんが待っていた瞬間、記事のアウトラインを生成する時が来ました。
これは 2 つの部分で行われます。 まず、セルを追加してプロンプトを生成する必要があります。
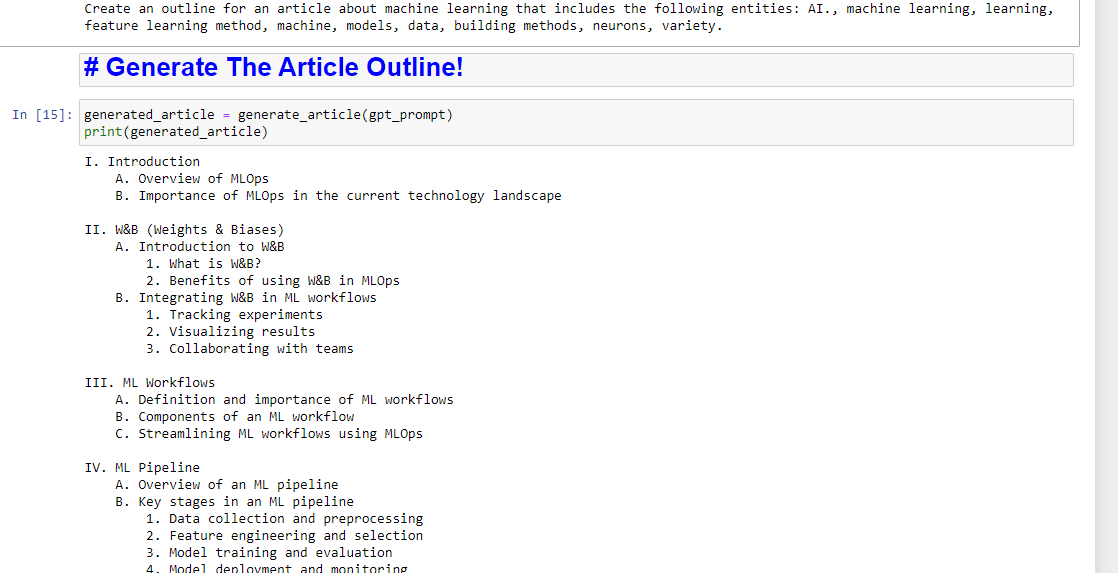
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)これにより、基本的に記事を生成するためのプロンプトが作成されます。

あとは、次のコマンドを使用して記事のアウトラインを生成するだけです。
generated_article = generate_article(gpt_prompt) print(generated_article)これは次のようなものを生成します:
要約も書きたい場合は、次のように追加できます。
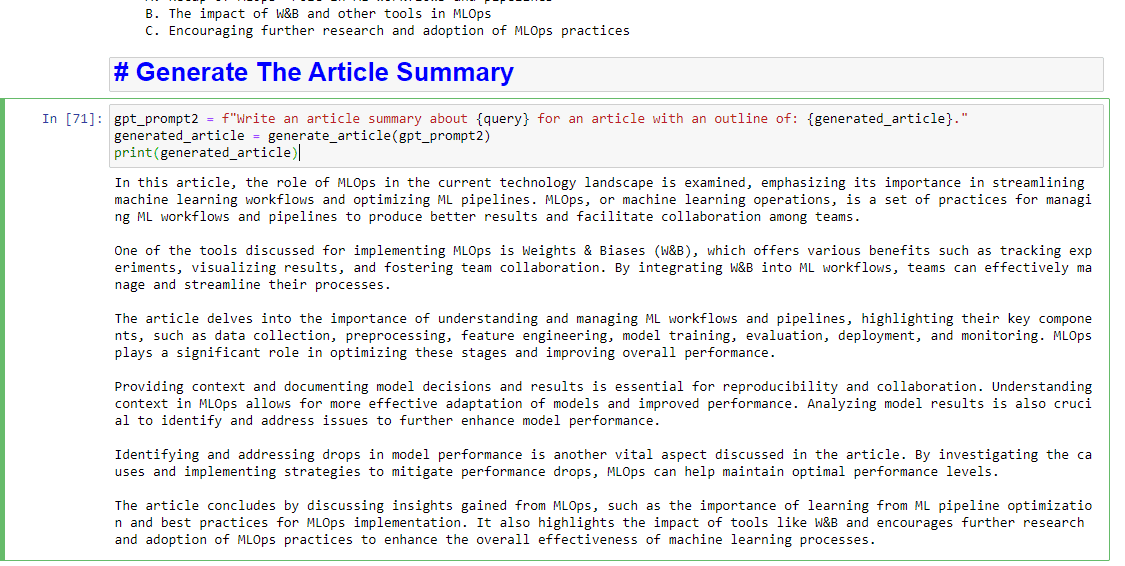
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)これは次のようなものを生成します:
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。