
Google は ChatGPT のようなシステムを使用して、スパムや AI コンテンツの検出や Web サイトのランク付けを行っていますか?
公開: 2023-02-01見出しは意図的に誤解を招くものですが、「ChatGPT」という用語の使用に関する限りです。
システムを「GPT-2 や GPT-3 のようなテキスト生成モデル」と説明する代わりに、「ChatGPT のような」という言葉を使用すると、読者は私が言及している技術の種類をすぐに知ることができます。 (また、後者は実際にはクリック可能ではありません…)
この記事で取り上げるのは、2020 年の古いものの関連性の高い Google の論文「Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study」です。
論文の内容は?
著者の説明から始めましょう。 彼らはこのようにトピックを紹介します:
「多くの人が、人間のようなテキストを大規模に生成する能力が主な理由で、野生のニューラル テキスト ジェネレーターの潜在的な危険性について懸念を表明しています。
人間と機械で生成されたテキストを区別するように訓練された分類子は、最近、ウェブ上の機械で生成されたテキストの存在を監視するために採用されています[29]。 しかし、ラベルを必要とせず、人間のテキストのコーパスと生成モデルのみを必要とするという魅力的な特性にもかかわらず、これらの分類器を他の用途に適用する作業はほとんど行われていません。 この作業では、市販の人間と機械の識別器がページ品質の強力な分類器として機能することを、厳密な人間による評価を通じて示します。 つまり、機械で生成されたように見えるテキストは、一貫性がなく、理解できない傾向があります。 実際に低品質のページが存在することを理解するために、5 億の英語の Web ページのサンプルに分類子を適用します。」
彼らが本質的に言っているのは、AIベースのコピーを検出するために開発された同じ分類器が、それを生成するために同じモデルを使用して、低品質のコンテンツを検出するためにうまく使用できることを発見したということです.
もちろん、これは私たちに重要な質問を残します:
これは因果関係(つまり、システムが真に優れているためシステムが検出したのか) なのか、それとも相関関係(つまり、現在の多くのスパムが、より優れたツールを使用して簡単に回避できる方法で作成されているのか) なのか?
ただし、それを検討する前に、著者の仕事とその発見のいくつかを見てみましょう.
セットアップ
参考までに、彼らは実験で以下を使用しました。
- 2 つのテキスト生成モデル、OpenAI の RoBERTa ベースの GPT-2 検出器 (GPT-2 出力を備えた RoBERTa モデルを使用し、AI によって生成された可能性が高いかどうかを予測する検出器) と、トップへのアクセスもある GLTR モデルGPT-2 は出力し、同様に動作します。
上記の論文からコピーしたコンテンツで、このモデルの出力の例を確認できます。
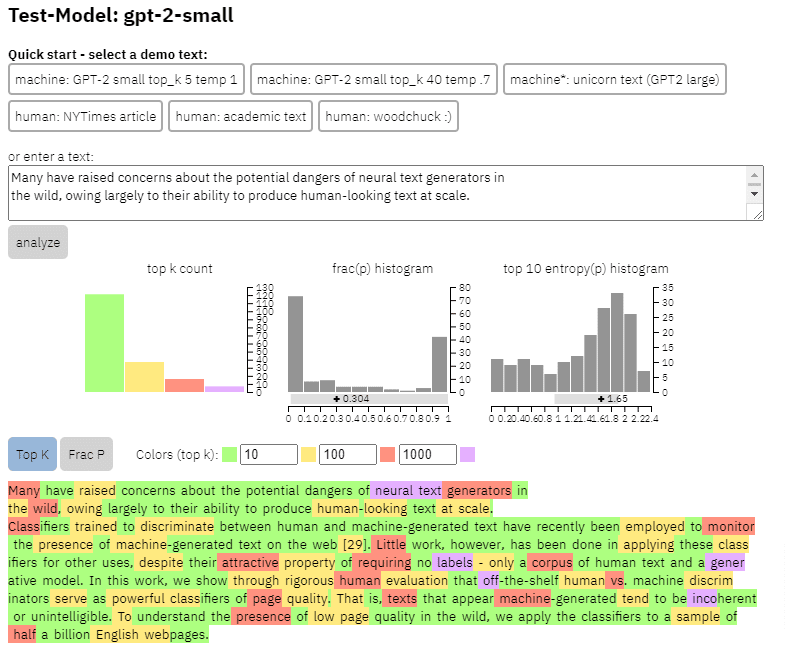
- 3 つのデータセットWeb500M (5 億の英語の Web ページのランダム サンプリング)、GPT-2 出力 (250k GPT-2 テキスト生成)、Grover-Output (設計された事前トレーニング済みの Grover-Base モデルを使用して 120 万件の記事を内部生成)フェイクニュースを検出します)。
- Enron Spam Email Dataset でトレーニングされた分類子であるSpam Baseline 。 この分類子を使用して、割り当てる言語品質番号を確立したため、ドキュメントが 0.2 の確率でスパムではないとモデルが判断した場合、割り当てられた言語品質 (LQ) スコアは 0.2 でした。
検索マーケティング担当者が頼りにしている毎日のニュースレターを入手してください。
条件を参照してください。
スパムの蔓延についての余談
著者が偶然見つけたいくつかの興味深い発見について議論するために、ちょっと脇に置いておきたいと思います。 その 1 つを次の図に示します (論文の図 3)。
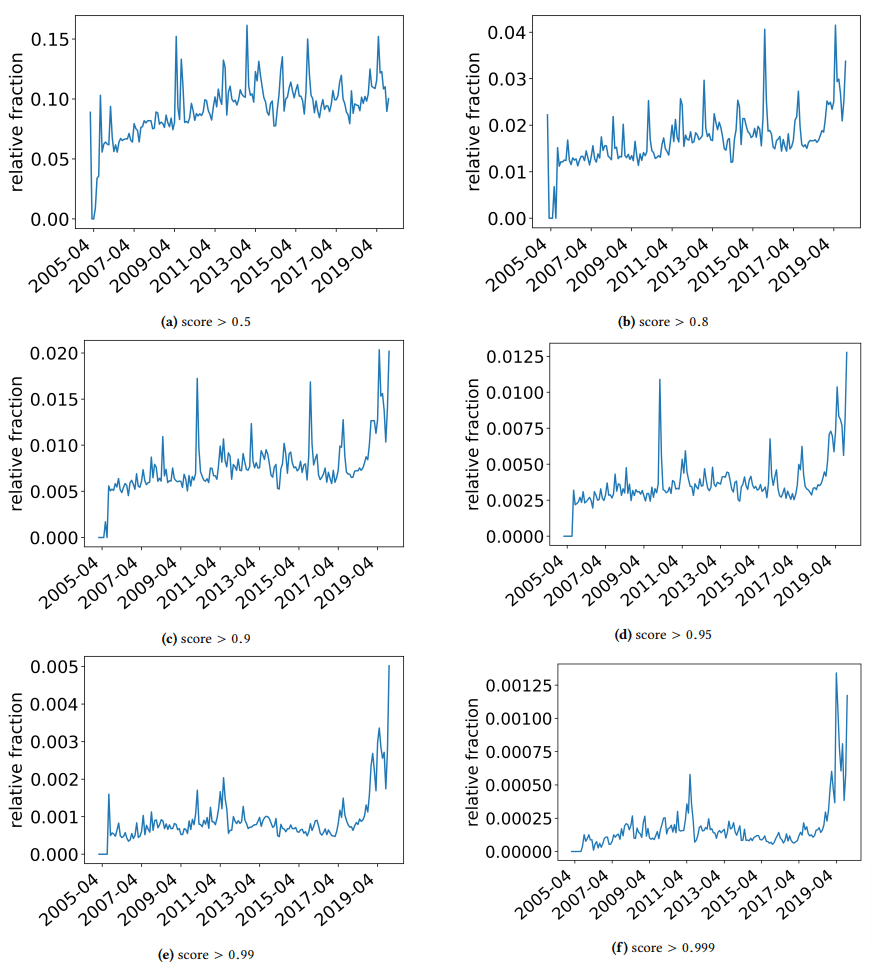
各グラフの下にあるスコアに注意することが重要です。 数値が 1.0 に近づくほど、コンテンツがスパムであるという確信が持てるようになります。 2017 年以降、そして 2019 年に急増し、低品質のドキュメントが蔓延していることがわかります。
さらに、低品質のコンテンツの影響は、一部のセクターで他のセクターよりも高いことがわかりました (スコアが高いほど、スパムの可能性が高いことを反映していることを思い出してください)。
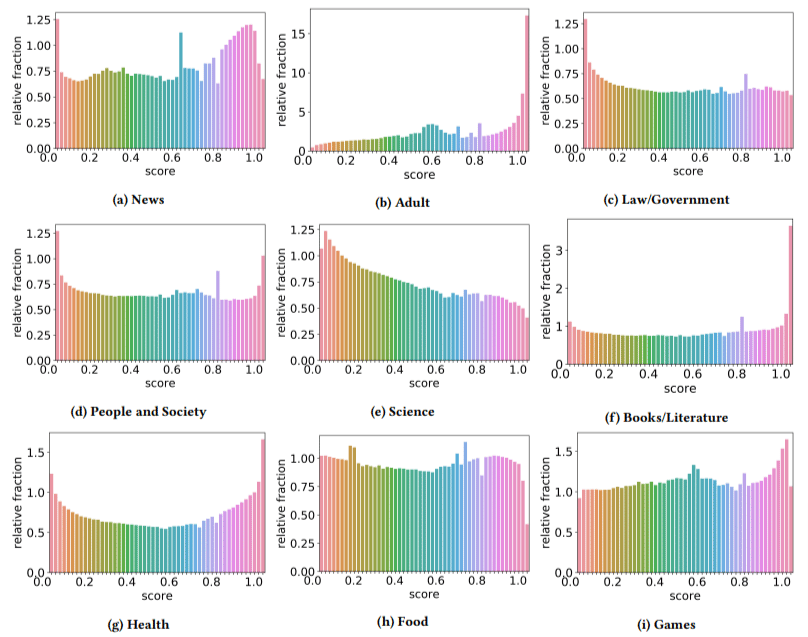
私はこれらのいくつかに頭を悩ませました。 明らかに、大人は理にかなっています。
しかし、本と文学はちょっとした驚きでした。 著者がバイアグラやその他の「成人向け健康製品」サイトを「健康」、エッセイ ファームを「文献」として取り上げるまでは、健康も同様でした。
彼らの調査結果
セクターと 2019 年の急増について議論したこととは別に、執筆者は、特に ChatGPT のようなツールに依存し始めたときに、SEO が学ぶことができ、心に留めておくべき多くの興味深いことも発見しました。
- 低品質のコンテンツは、長さが短くなる傾向があります (3,000 文字がピーク)。
- テキストが機械によって書かれたかどうかを判断するように訓練された検出システムは、低レベルのコンテンツと高レベルのコンテンツの分類にも優れています。
- 彼らは、ランキングのために設計されたコンテンツを特定の犯人と呼んでいますが、そこにあってはならないことを誰もが知っているゴミについて言及しているのではないかと思います.
著者は、これが最終的な解決策であるとは主張していませんが、むしろ出発点であり、過去数年間でバーを前進させたと確信しています.
AI 生成コンテンツに関する注意事項
言語モデルも同様に長年にわたって開発されてきました。 この論文が書かれた時点で GPT-3 は存在していましたが、彼らが使用していた検出器は GPT-2 に基づいていましたが、これはかなり劣ったモデルです。
GPT-4 はもうすぐ実現する可能性が高く、Google の Sparrow は今年後半にリリースされる予定です。 これは、技術が戦場の両側 (コンテンツ ジェネレーターと検索エンジン) で改善されているだけでなく、組み合わせを活用しやすくなることを意味します。
Google は、Sparrow または GPT-4 によって作成されたコンテンツを検出できますか? 多分。
しかし、Sparrow で生成され、書き換えプロンプトで GPT-4 に送信された場合はどうでしょうか?
覚えておく必要があるもう 1 つの要因は、このホワイト ペーパーで使用されている手法が自己回帰モデルに基づいていることです。 簡単に言えば、その単語に先行する単語が与えられると予測するものに基づいて、単語のスコアを予測します。
モデルがより高度に洗練され、単語の後に別の単語が続くのではなく、一度に完全なアイデアを作成し始めると、AI の検出が失敗する可能性があります。
一方で、ただのくだらないコンテンツの検出はエスカレートする必要があります。これは、AI によって生成された「低品質」のコンテンツだけが勝つことを意味する可能性があります。
この記事で表明された意見はゲスト著者のものであり、必ずしも Search Engine Land ではありません。 スタッフの著者はここにリストされています。