
Hadoopエコシステムとそのコンポーネント
公開: 2015-04-23ビッグデータは、2008年からIT業界で流行語です。ソーシャルネットワーク、製造、小売、株式、通信、保険、銀行、ヘルスケア業界で生成されるデータの量は、私たちの想像をはるかに超えています。
Hadoopが登場する前は、ビッグデータの保存と処理は大きな課題でした。 しかし、Hadoopが利用可能になった今、企業はビッグデータのビジネスへの影響と、このデータを理解することが成長を促進する方法を認識しています。 例えば:
•銀行セクターは、忠実な顧客、ローンの不履行者、および詐欺取引を理解するためのより良い機会があります。
•小売部門は現在、需要を予測するのに十分なデータを持っています。
•製造部門は、品質テストのために費用のかかるメカニズムに依存する必要はありません。 センサーデータをキャプチャして分析すると、多くのパターンが明らかになります。
•Eコマースのソーシャルネットワークは、顧客の関心に基づいてページをパーソナライズできます。
•株式市場は膨大な量のデータを生成し、時々相関することで美しい洞察が明らかになります。
ビッグデータには、多くの有用で洞察に満ちたアプリケーションがあります。
Hadoopは、ビッグデータを処理するための正解です。 Hadoopエコシステムは、ビジネス上の問題を解決するのに十分な利点があるテクノロジーの組み合わせです。
特定のビジネス問題に適切なソリューションを構築するために、HadoopEcosytemのコンポーネントを理解しましょう。
Hadoopエコシステム:
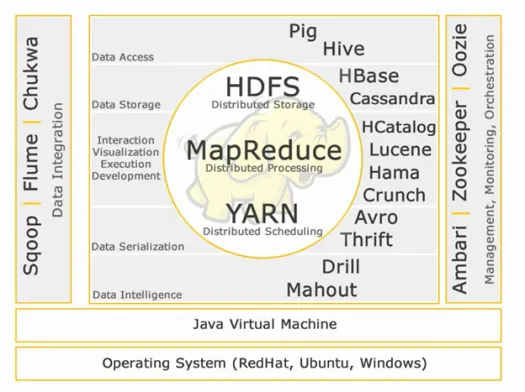

コアHadoop:
HDFS:
HDFSは、Hadoop Distributed File Systemの略で、大量、高速、多様性のあるビッグデータセットを管理します。 HDFSはマスタースレーブアーキテクチャを実装しています。 マスターは名前ノードであり、スレーブはデータノードです。
特徴:
•スケーラブル
• 信頼性のある
•コモディティハードウェア
HDFSはビッグデータストレージでよく知られています。
MapReduce:
Map Reduceは、大量の分散データを処理するために設計されたプログラミングモデルです。 プラットフォームは、例外処理を改善するためにJavaを使用して構築されています。 Map Reduceには、ジョブトラッカーとタスクトラッカーの2つのデーモンが含まれています。
特徴:
•関数型プログラミング。
•ビッグデータで非常にうまく機能します。
•大規模なデータセットを処理できます。
Map Reduceは、ビッグデータの処理で知られる主要なコンポーネントです。
糸:
YARNはYetAnotherResourceNegotiatorの略です。 MapReduce 2(MRv2)とも呼ばれます。 MRv1のJobTrackerの2つの主要な機能、リソース管理とジョブのスケジューリング/監視は、ResourceManager、NodeManager、ApplicationMasterという別々のデーモンに分割されています。
特徴:
•より良いリソース管理。
•スケーラビリティ
•クラスターリソースの動的割り当て。
データアクセス:
豚:
Apache Pigは、MapReduce上に構築された高級言語であり、単純なアドホックデータ分析プログラムを使用して大規模なデータセットを分析します。 Pigはデータフロー言語としても知られています。 Pythonと非常によく統合されています。 当初はyahooによって開発されました。
豚の顕著な特徴:
•プログラミングのしやすさ
•最適化の機会
•拡張性。
Pigスクリプトは、内部でマップリデュースプログラムに変換されます。

ハイブ:
Apache Hiveは、データの要約、クエリ、分析を提供するためにHadoop上に構築されたもう1つの高レベルのクエリ言語およびデータウェアハウスインフラストラクチャです。 当初はyahooによって開発され、オープンソースになりました。
ハイブの顕著な特徴:
•HQLと呼ばれるSQLのようなクエリ言語。
•データ処理を高速化するためのパーティショニングとバケット化。
•Tableauなどの視覚化ツールとの統合。
内部でHiveクエリは、マップリデュースプログラムに変換されます。
ビッグデータアナリストになりたいのなら、この2つの高級言語は必見です!!

データストレージ:
Hbase:
Apache HBaseは、Hadoopコモディティハードウェアマシン上に数十億行と数百万列の大きなテーブルをホストするために構築されたNoSQLデータベースです。 ビッグデータへのランダムなリアルタイムの読み取り/書き込みアクセスが必要な場合は、ApacheHbaseを使用してください。
特徴:
•厳密に一貫した読み取りと書き込み。 メモリ内の操作。
•クライアントアクセス用の使いやすいJavaAPI。
•豚、ハイブ、スクープとうまく統合されています。
•CAP定理における一貫性のあるパーティショントレラントシステムです。

カサンドラ:
Cassandraは、線形スケーラビリティと高可用性のために設計されたNoSQLデータベースです。 CassandraはKey-Valueモデルに基づいています。 Facebookによって開発され、クエリへの応答が速いことで知られています。
特徴:
•列インデックス
•非正規化のサポート
•マテリアライズドビュー
•強力な組み込みキャッシュ。

相互作用-視覚化-実行-開発:
Hカタログ:
HCatalogは、他のHadoopアプリケーションのハイブメタデータの統合を提供するテーブル管理レイヤーです。 これにより、Apache pig、Apache MapReduce、Apache Hiveなどのさまざまなデータ処理ツールを使用するユーザーが、より簡単にデータを読み書きできるようになります。
特徴:
•さまざまな形式の表形式のビュー。

•データの可用性の通知。
•外部システムがメタデータにアクセスするためのRESTAPI。
Lucene:
Apache LuceneTMは、完全にJavaで記述された高性能のフル機能のテキスト検索エンジンライブラリです。 これは、全文検索を必要とするほぼすべてのアプリケーション、特にクロスプラットフォームに適したテクノロジーです。
特徴:
•スケーラブルで高性能–パフォーマンスのインデックス付け。
•強力で正確かつ効率的な検索アルゴリズム。
•クロスプラットフォームソリューション。
ハマ:
Apache Hamaは、Bulk Synchronous Parallel(BSP)コンピューティングに基づく分散フレームワークです。 マトリックス、グラフ、ネットワークアルゴリズムなどの大規模な科学計算に対応し、よく知られています。
特徴:
•シンプルなプログラミングモデル
•反復アルゴリズムに最適
•YARNがサポートされています
•協調フィルタリングの教師なし機械学習。
•K-Meansクラスタリング。
噛み砕く:
Apacheクランチは、シンプルで効率的なMapReduceプログラムをパイプライン化するために構築されています。 このフレームワークは、MapReduceパイプラインの作成、テスト、実行に使用されます。
特徴:
•開発者に焦点を当てています。
•最小限の抽象化
•柔軟なデータモデル。
データのシリアル化:
アブロ:
Apache Avroは、言語に依存しないデータシリアル化フレームワークです。 言語の移植性を考慮して設計されており、データが言語よりも長持ちして読み書きできるようになります。

倹約:
Thriftは、Hadoop上に構築されたテクノロジーと対話するためのインターフェースを構築するために開発された言語です。 これは、多数の言語のサービスを定義および作成するために使用されます。
データインテリジェンス:
ドリル:
Apache Drillは、HadoopおよびNoSQL用の低レイテンシSQLクエリエンジンです。
特徴:
• 機敏
•柔軟性
•ファミリアリティ。

マハウト:
Apache Mahoutは、ビッグデータの予測分析を構築するために設計されたスケーラブルな機械学習ライブラリです。 Mahoutには、メモリコンピューティングを高速化するためのapachesparkの実装があります。
特徴:
•協調フィルタリング。
•分類
•クラスタリング
•次元削減

データ統合:
Apache Sqoop:

Apache Sqoopは、リレーショナルデータベースとHadoop間のバルクデータ転送用に設計されたツールです。
特徴:
•HDFSとの間でインポートおよびエクスポートします。
•Hiveとの間でインポートおよびエクスポートします。
•HBaseにインポートおよびエクスポートします。
Apache Flume:
Flumeは、大量のログデータを効率的に収集、集約、および移動するための、分散された信頼性の高い利用可能なサービスです。
特徴:
• 壮健
• 耐障害性
•ストリーミングデータフローに基づくシンプルで柔軟なアーキテクチャ。

Apache Chukwa:
大規模な分散ファイルシステムの監視に使用されるスケーラブルなログコレクター。
特徴:
•数千のノードに拡張できます。
•信頼性の高い配信。
•データを無期限に保存できる必要があります。

管理、監視、オーケストレーション:
Apache Ambari:
Ambariは、Apache Hadoopクラスターをプロビジョニング、管理、および監視するためのインターフェースを提供することにより、Hadoop管理を簡素化するように設計されています。
特徴:
•Hadoopクラスターをプロビジョニングします。
•Hadoopクラスターを管理します。
•Hadoopクラスターを監視します。

Apache Zookeeper:
Zookeeperは、構成情報の保守、命名、分散同期の提供、およびグループサービスの提供のために設計された一元化されたサービスです。
特徴:
•シリアル化
•アトミシティ
• 信頼性
•シンプルなAPI

Apache Oozie:
Oozieは、ApacheHadoopジョブを管理するためのワークフロースケジューラシステムです。
特徴:
•スケーラブルで信頼性が高く、拡張可能なシステム。
•Map-Reduce、Hive、Pig、SqoopなどのいくつかのタイプのHadoopジョブをサポートします。
•シンプルで使いやすい。

コンポーネントについては、今後の記事で詳しく説明します。 乞うご期待。