
Ambariを使用したHadoopのインストール
公開: 2015-12-11Ambariを使用したHadoopのインストールについて知りたいことすべて
Apache Hadoopは、信頼性が高く、スケーラブルで、分散型の大規模コンピューティングのための事実上のソフトウェアフレームワークになりました。 他のコンピューティングシステムとは異なり、データを計算に送信するのではなく、データに計算をもたらします。 Hadoopは、Googleが発行した論文に基づいて、2006年にYahooでDougCuttingによって作成されました。 Hadoopが成熟するにつれ、使いやすさと機能を強化するために、何年にもわたって多くの新しいコンポーネントとツールがエコシステムに追加されました。 いくつか例を挙げると、Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig、Sqoopなどがあります。
なぜアンバリ?
Hadoopの人気が高まるにつれ、多くの開発者がこのテクノロジーに飛び込んで味わうようになっています。 しかし、彼らが言うように、Hadoopは気弱な人向けではなく、多くの開発者はHadoopのインストールの障壁を越えることさえできませんでした。 多くのディストリビューションでは、VMのサンドボックスがプリインストールされて試してみることができますが、分散コンピューティングの感覚は得られません。 ただし、マルチノードのインストールは簡単な作業ではなく、コンポーネントの数が増えるにつれて、非常に多くの構成パラメーターを処理するのは非常に困難です。 ありがたいことに、Apache Ambariが私たちの救助のためにここに来ました!
アンバリとは?
Apache Ambariは、Apache Hadoopクラスターをプロビジョニング、管理、および監視するためのWebベースのツールです。 Ambariは、ヒートマップなどのクラスターヘルスを表示するためのダッシュボードと、MapReduce、Pig、およびHiveアプリケーションを視覚的に表示する機能と、ユーザーフレンドリーな方法でパフォーマンス特性を診断する機能を提供します。 さまざまなツールをインストールし、さまざまな管理、構成、および監視タスクを実行するための非常にシンプルでインタラクティブなUIを備えています。 以下では、Hadoopとそのさまざまなエコシステムコンポーネントをマルチノードクラスターにインストールするためのさまざまな手順を説明します。
Ambariアーキテクチャを以下に示します
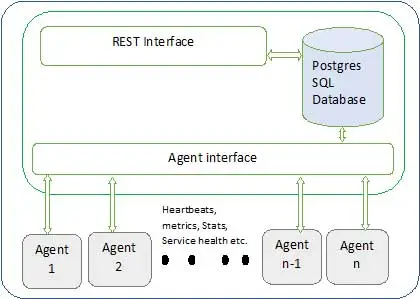
アンバリには2つの要素があります
- Ambariサーバー–これは、クラスターに参加している各ノードにインストールされているAmbariエージェントと通信するマスタープロセスです。 これには、すべてのクラスター関連のメタデータを維持するために使用されるpostgresデータベースインスタンスがあります。
- Ambariエージェント–これらは各ノードのAmbariの代理エージェントです。 各エージェントは、さまざまなメトリック、インストールされているサービスのステータスなど、さまざまなものとともに、自分のヘルスステータスを定期的に送信します。 マスターによると、次の行動を決定し、行動するためにエージェントに伝えます。
Ambariのインストール方法は?
Ambariのインストールは、いくつかのコマンドで簡単に実行できます。
Ambariのインストールとクラスターのセットアップについて説明します。 4つのノードがあると想定しています。 Node1、Node2、Node3およびNode4。 そして、AmbariサーバーとしてNode1を選択しています。
これらはRHELベースのシステムへのインストール手順です。Debianやその他のシステムの手順はほとんど変わりません。
- Ambariのインストール:–
Ambariサーバーノードから(決定したノード1)
私。 Ambariパブリックリポジトリをダウンロード

このコマンドは、RHELシステムのデフォルトのパッケージマネージャーであるyumにHortonworksAmbariリポジトリーを追加します。
ii。AmbariRPMSをインストールします

これには時間がかかり、このシステムにAmbariがインストールされます。

iii。 Ambariサーバーの構成
Ambariのインストール後に次に行うことは、Ambariを構成し、クラスターをプロビジョニングするようにセットアップすることです。
次の手順でこれを処理します


iv。 サーバーを起動し、WebUIにログインします
サーバーを起動します

これで、Ambari Web UI(8080ポートでホストされている)にアクセスできます。
デフォルトのユーザー名「admin」とデフォルトのパスワード「admin」でAmbariにログインします。
Hadoopクラスターのセットアップ
1.ランディングページ
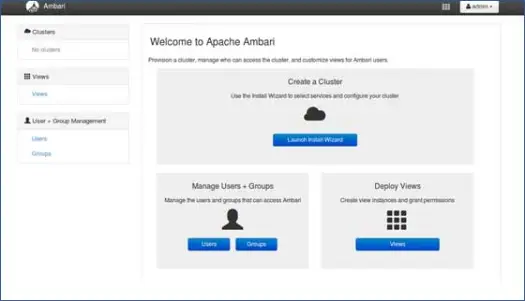
「LaunchInstallWizard」をクリックして、クラスターのセットアップを開始します
2.クラスター名
クラスターに適切な名前を付けます。
注:これはクラスターの単純な名前であり、それほど重要ではないため、心配する必要はなく、任意の名前を選択してください。
3.スタックの選択
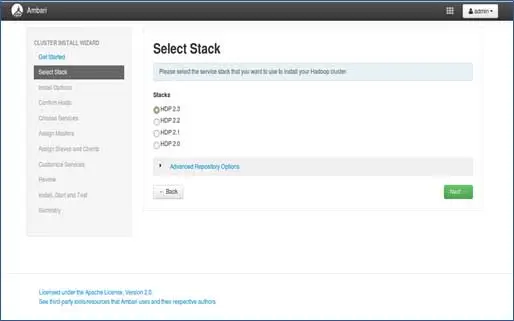
このページには、インストール可能なスタックが一覧表示されます。 各スタックには、Hadoopエコシステムコンポーネントが事前にパッケージ化されています。 これらのスタックはHortonworksからのものです。 (プレーンなHadoopもインストールできます。これについては後の投稿で説明します)。
4.ホストエントリとSSHキーエントリ
このステップをさらに進める前に、参加しているすべてのノードに対してパスワードなしのSSHセットアップを行う必要があります。

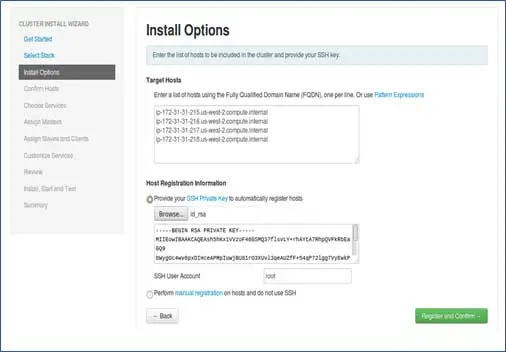
ノードのホスト名を追加します。各行に1つのエントリがあります。 [hostname –fコマンドで取得できるFQDNを追加]。 パスワードを設定するときに使用する秘密鍵を選択します。SSHと、秘密鍵が作成されたユーザー名を使用します。
5.ホストの登録ステータス
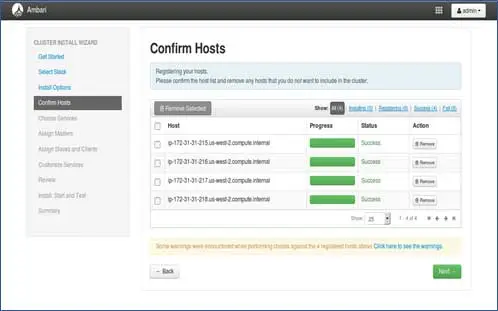
実行されているいくつかの操作を確認できます。これらの操作には、各ノードでのAmbari-agentの設定、各ノードでの基本的なセットアップの作成が含まれます。 ALL GREENが表示されたら、次に進む準備ができています。 いくつかのパッケージをインストールするため、これには時間がかかる場合があります。

6.インストールするサービスを選択します
手順3で選択したスタックに従って、クラスターにインストールできるサービスの数があります。 あなたが望むものを選ぶことができます。 依存サービスを選択していない場合、Ambariはインテリジェントに依存サービスを選択します。 たとえば、HBaseを選択しましたが、Zookeeperは選択していません。同じプロンプトが表示され、Zookeeperもクラスターに追加されます。
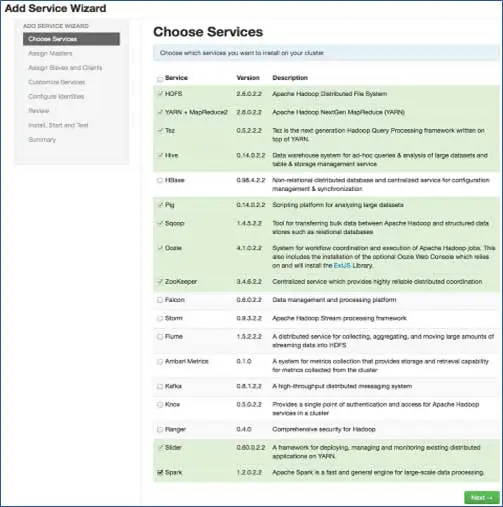
7.ノードを使用したマスターサービスのマッピング
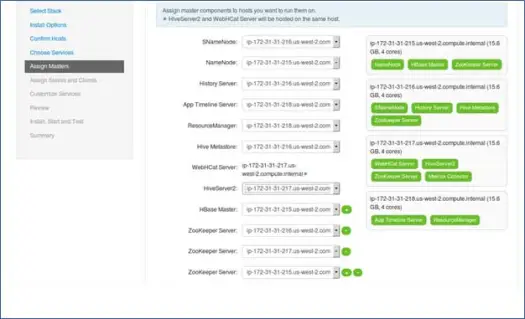
ご存知のとおり、Hadoopエコシステムには、マスタースレーブアーキテクチャに基づくツールがあります。 このステップでは、マスタープロセスをノードに関連付けます。 ここで、クラスターのバランスを適切に取っていることを確認してください。 また、NamenodeやセカンダリNamenodeなどのプライマリサービスとセカンダリサービスは同じマシン上にないことに注意してください。

8.ノードを使用したスレーブマッピング
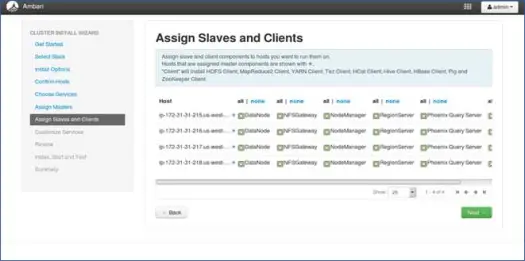
マスターと同様に、ノードにスレーブサービスをマップします。 一般に、すべてのノードには、少なくともデータノードとノードマネージャーに対して実行されるスレーブプロセスがあります。
9.サービスをカスタマイズする
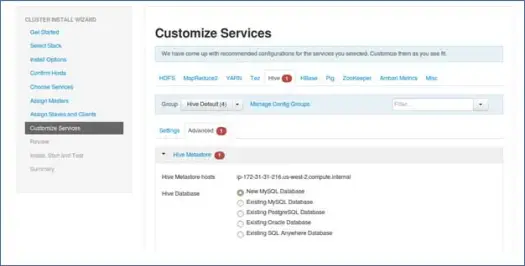
これは管理者にとって非常に重要なページです。
ここでは、クラスターのプロパティを構成して、ユースケースに最も適したものにすることができます。
また、Hiveメタストアパスワード(hiveが選択されている場合)などのいくつかの必須プロパティがあります。これらは、記号のような赤いエラーで示されます。
10.プロビジョニングを確認して開始します
起動する前にクラスター構成を確認してください。これにより、誤って誤った構成を設定することを防ぐことができます。
11.起動して、ステータスが緑になるまで戻ります。
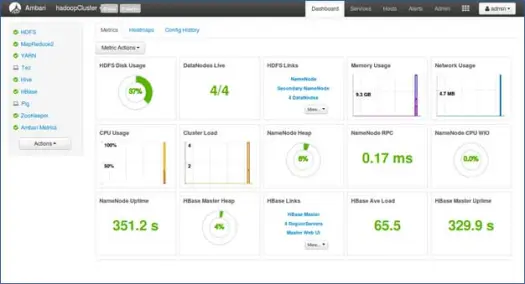
次のステップ
やぁ! これで、クラスターのすべてのノードにHadoopとすべてのコンポーネントが正常にインストールされました。 これで、Hadoopでのプレイを開始できます。
AmbariはMapReducewordcountジョブを実行して、すべてが正常に実行されているかどうかを確認します。 ambari-qaユーザーが実行したジョブのログを確認してみましょう。
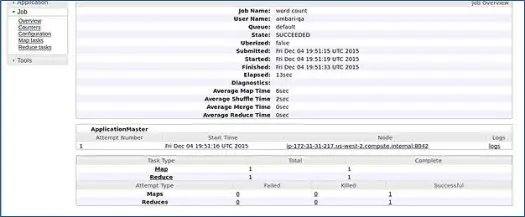
上のスクリーンショットでわかるように、WordCountジョブは正常に完了しました。 これにより、クラスターが正常に機能していることが確認されます。
結論
これで、ApacheAmbariと呼ばれる単純なWebベースのツールを使用してHadoopとそのコンポーネントをマルチノードクラスターにインストールする方法を学習しました。 Apache Ambariは、よりシンプルなインターフェイスを提供し、インストール、監視、および管理に関する多くの労力を節約します。これは、非常に多くのコンポーネントと、それらのさまざまなインストール手順および監視制御では非常に面倒でした。
ハックを残しておきましょう

Ambariインストーラーは/etc/lsb-releaseをチェックしてOSの詳細を取得します。 Linux Mintでは、Ubuntuバージョンの同じファイルが/ etc / upload-release/lsb-releaseの下にあります。 インストーラーをだますには、前者を後者に置き換えるだけです(最初にファイルをバックアップする必要があります)。

インストールが完了した後のある時点で、次の方法で元のファイルを復元できます。

PSこれは保証のないハックです、それは私のために働いたので、私はあなたとそれを共有することを考えました。
あなたは開発者/開発者であり、Hadoopをすばやくインストールする必要があります。 朗報です。Ambariは、ウィザードプロセス全体とインストールプロセス完了を1つのスクリプトでスキップできる方法を提供します。次の投稿で紹介しますので、しばらくお待ちください。それまではHappy Hadooping!