
SparkとHadoop:どのビッグデータフレームワークがあなたのビジネスを向上させますか?
公開: 2019-09-24「データはデジタルエコノミーの原動力です」
現代の企業は、消費者と市場をよりよく理解するために大量のデータに依存しているため、ビッグデータのようなテクノロジーは大きな勢いを増しています。
ビッグデータは、AIが2020年のトップテクノロジートレンドのリストに載っただけでなく、スタートアップとフォーチュン500企業の両方に受け入れられ、ビジネスの飛躍的な成長を享受し、顧客ロイヤルティを高めることが期待されています。 その明確な兆候は、ビッグデータ市場が2027年までに1,030億ドルに達すると予測されていることです。
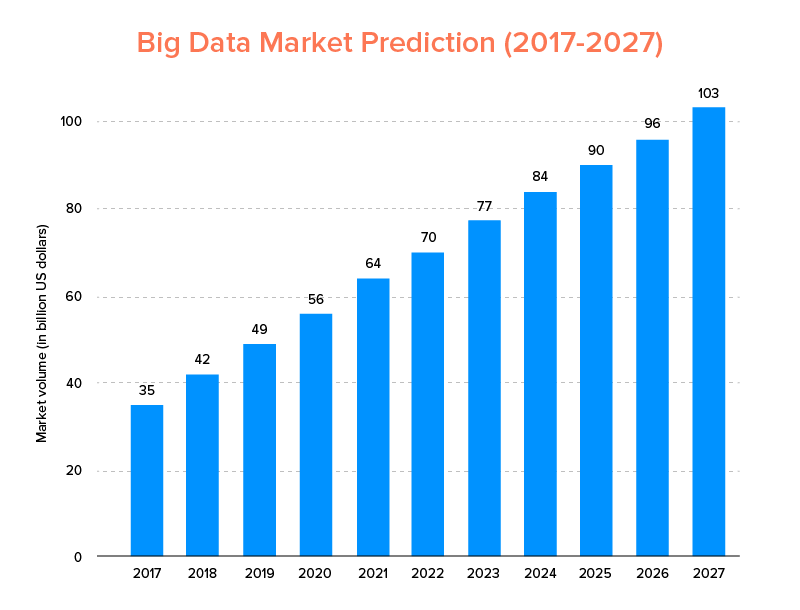
現在、これは一方で、従来のデータ分析ツールをビッグデータ(ブロックチェーンとAIの進歩の基盤を準備するもの)に置き換える意欲がありますが、適切なビッグデータツールの選択についても混乱しています。 彼らは、ビッグデータの世界の2つの巨人であるApacheHadoopとSparkの間で選択するというジレンマに直面しています。
したがって、この考えを考慮して、本日はApache SparkとHadoopに関する記事を取り上げ、どちらがニーズに適しているかを判断するのに役立ちます。
ただし、最初に、HadoopとSparkとは何かについて簡単に紹介します。
Apache Hadoopは、オープンソースの分散型Javaベースのフレームワークであり、ユーザーは、単純なプログラミング構造を使用して、コンピューターの複数のクラスターにわたってビッグデータを保存および処理できます。 これは、連携して強化されたエクスペリエンスを提供するさまざまなモジュールで構成されています。
- Hadoop Common
- Hadoop分散ファイルシステム(HDFS)
- Hadoop YARN
- Hadoop MapReduce
一方、Apache Sparkは、「使いやすく」、より高速なサービスを提供する、オープンソースの分散クラスターコンピューティングビッグデータフレームワークです。
2つのビッグデータフレームワークは、それらが提供する一連の機会のために、多数の大企業によって支えられています。
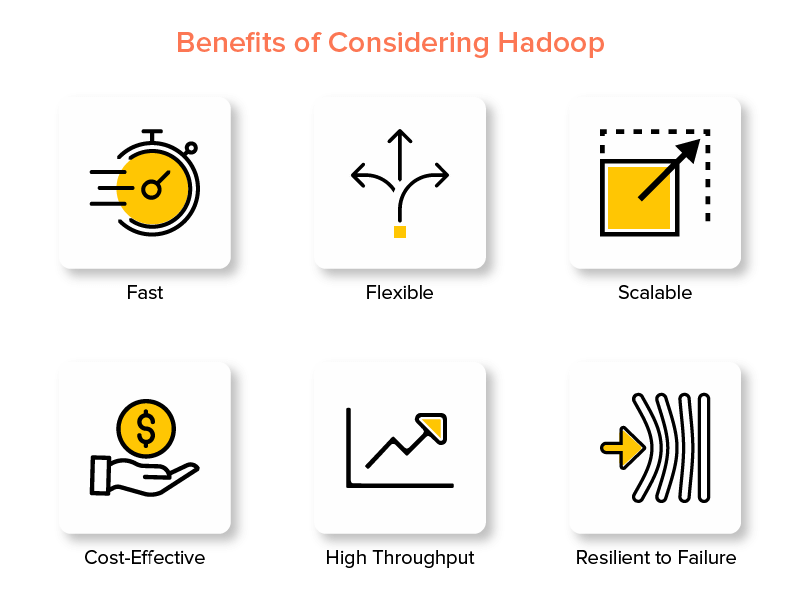
Hadoopビッグデータフレームワークの利点
1.速い
ビッグデータの世界で人気のあるHadoopの機能の1つは、高速であることです。
その保存方法は、主にクラスター上の任意の場所にデータを「マップ」する分散ファイルシステムに基づいています。 また、データ処理に使用されるデータとツールは通常、同じサーバー上で利用できるため、データ処理は手間がかからず、より高速なタスクになります。
実際、Hadoopは数テラバイトの非構造化データをわずか数分で処理でき、ペタバイトは数時間で処理できることがわかっています。
2.柔軟
Hadoopは、従来のデータ処理ツールとは異なり、ハイエンドの柔軟性を提供します。
これにより、企業はさまざまなソース(ソーシャルメディア、電子メールなど)からデータを収集し、さまざまなデータタイプ(構造化および非構造化の両方)で作業し、さまざまな目的(ログ処理、市場キャンペーン分析など)でさらに使用するための貴重な洞察を得ることができます。不正検出など)。
3.スケーラブル
Hadoopのもう1つの利点は、拡張性が高いことです。 このプラットフォームは、従来のリレーショナルデータベースシステム(RDBMS)とは異なり、並列で動作する数百台のサーバーから大規模なデータセットを保存および配布できるようにします。
4.費用対効果
Apache Hadoopは、他のビッグデータ分析ツールと比較すると、はるかに安価です。 これは、専用のマシンを必要としないためです。 コモディティハードウェアのグループで実行されます。 また、長期的にはノードを追加する方が簡単です。
つまり、1つのケースでは、事前計画要件のダウンタイムに悩まされることなく、ノードを簡単に増やすことができます。
5.高スループット
Hadoopフレームワークの場合、データは分散された方法で保存されるため、小さなジョブが複数のデータチャンクに並列に分割されます。 これにより、企業はより少ない時間でより多くの仕事をこなすことが容易になり、最終的にはスループットが向上します。
6.障害に対する回復力
最後になりましたが、Hadoopは、障害の結果を軽減するのに役立つ高いフォールトトレランスオプションを提供します。 すべてのブロックのレプリカを格納し、ノードがダウンしたときにデータを回復できるようにします。
Hadoopフレームワークのデメリット
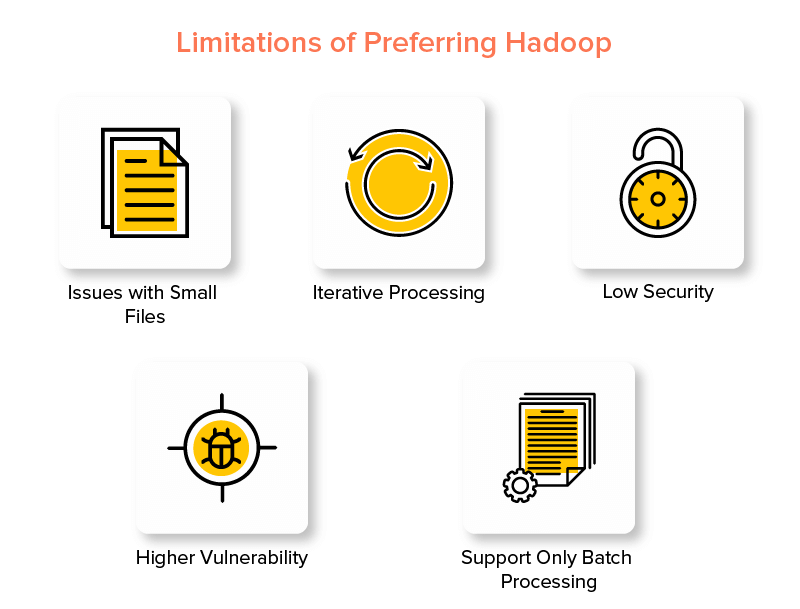
1.小さなファイルに関する問題
ビッグデータ分析にHadoopを検討することの最大の欠点は、小さなファイルのランダムな読み取りを効率的かつ効果的にサポートする可能性がないことです。
この背後にある理由は、小さなファイルのメモリサイズがHDFSブロックサイズよりも比較的小さいためです。 このようなシナリオでは、大量の小さなファイルを保存すると、HDFSの名前空間を保存するNameNodeがオーバーロードされる可能性が高くなりますが、これは実際には良い考えではありません。
2.反復処理
ビッグデータHadoopフレームワークのデータフローはチェーンの形式であるため、あるステージの出力が別のステージの入力になります。 一方、反復処理のデータフローは、本質的に循環的です。
このため、Hadoopは機械学習または反復処理ベースのソリューションには適していません。
3.低セキュリティ
Hadoopフレームワークを使用することのもう1つの欠点は、セキュリティ機能が低いことです。
たとえば、フレームワークでは、セキュリティモデルがデフォルトで無効になっています。 このビッグデータツールを使用している人がそれを有効にする方法を知らない場合、彼らのデータは盗まれたり誤用されたりするリスクが高くなる可能性があります。 また、Hadoopは、ストレージおよびネットワークレベルでの暗号化機能を提供していません。これにより、データ侵害の脅威が発生する可能性が高くなります。
4.より高い脆弱性
Hadoopフレームワークは、最も人気がありながら悪用されているプログラミング言語であるJavaで記述されています。 これにより、サイバー犯罪者がHadoopベースのソリューションに簡単にアクセスし、機密データを悪用することが容易になります。
5.バッチ処理のみのサポート
他のさまざまなビッグデータフレームワークとは異なり、Hadoopはストリーミングされたデータを処理しません。 バッチ処理のみをサポートしますが、その背後にある理由は、MapReduceがHadoopクラスターのメモリを最大限に活用できないためです。
これはすべてHadoop、その機能と欠点に関するものですが、Sparkの長所と短所を調べて、2つの違いを簡単に理解できるようにしましょう。
ApacheSparkフレームワークの利点
1.自然の中でダイナミック
Apache Sparkは約80の高レベルの演算子を提供するため、データを動的に処理するために使用できます。 これは、並列アプリを開発および管理するための適切なビッグデータツールと見なすことができます。
2.パワフル
低レイテンシのメモリ内データ処理機能と、機械学習およびグラフ分析アルゴリズム用のさまざまな組み込みライブラリの可用性により、さまざまな分析の課題に対処できます。 これにより、市場で強力なビッグデータオプションを利用できるようになります。
3.高度な分析
Sparkのもう1つの特徴的な機能は、「MAP」と「reduce」を促進するだけでなく、機械学習(ML)、SQLクエリ、グラフアルゴリズム、およびストリーミングデータもサポートすることです。 これにより、高度な分析を楽しむのに適しています。
4.再利用性
Hadoopとは異なり、Sparkコードはバッチ処理、ストリーム状態でのアドホッククエリの実行、履歴データに対するストリームの結合などに再利用できます。
5.リアルタイムストリーム処理
Apache Sparkを使用するもう1つの利点は、データをリアルタイムで処理および処理できることです。
6.多言語サポート
最後になりましたが、このビッグデータ分析ツールは、Java、Python、Scalaなどのコーディング用の複数の言語をサポートしています。
Sparkビッグデータツールの制限

1.ファイル管理プロセスなし
Apache Sparkを使用することの主な欠点は、独自のファイル管理システムがないことです。 この要件を満たすために、Hadoopなどの他のプラットフォームに依存しています。
2.いくつかのアルゴリズム
また、Apache Sparkは、谷本距離などのアルゴリズムの可用性を考慮すると、他のビッグデータフレームワークに遅れをとっています。
3.小さなファイルの問題
Sparkを使用するもう1つの欠点は、小さなファイルを効率的に処理できないことです。
これは、Hadoop分散ファイルシステム(HDFS)で動作するためです。これにより、多数の小さなファイルよりも限られた数の大きなファイルを管理しやすくなります。
4.自動最適化プロセスはありません
他のさまざまなビッグデータやクラウドベースのプラットフォームとは異なり、Sparkには自動コード最適化プロセスがありません。 コードを手動で最適化するだけです。
5.マルチユーザー環境には適していません
Apache Sparkは同時に複数のユーザーを処理できないため、マルチユーザー環境では効率的に動作しません。 再びその制限を追加する何か。
両方のビッグデータフレームワークの基本をカバーしているので、SparkとHadoopの違いに慣れることを望んでいる可能性があります。
それでは、これ以上待たずに、どちらが「SparkvsHadoop」の戦いをリードしているかを確認するために比較に向かいましょう。
SparkとHadoop:2つのビッグデータツールが互いにどのように積み重なるか
[テーブルID = 38 /]
1.アーキテクチャ
SparkとHadoopのアーキテクチャーに関しては、両方が分散コンピューティング環境で動作している場合でも、後者がリードします。
これは、Sparkとは異なり、Hadoopのアーキテクチャには、HDFS(Hadoop分散ファイルシステム)とYARN(Yet Another Resource Negotiator)という2つの主要な要素があるためです。 ここでは、HDFSがさまざまなノード間でビッグデータストレージを処理しますが、YARNはリソース割り当てとジョブスケジューリングメカニズムを介してタスクの処理を処理します。 次に、これらのコンポーネントはさらに多くのコンポーネントに分割され、フォールトトレランスなどのサービスを備えたより優れたソリューションを提供します。
2.使いやすさ
Apache Sparkを使用すると、開発者は、Scala、Python、R、Java、SparkSQLなどのさまざまなユーザーフレンドリーなAPIを開発環境に導入できます。 また、ユーザーと開発者の両方をサポートするインタラクティブモードが搭載されています。 これにより、使いやすく、学習曲線が短くなります。
一方、Hadoopについて話すときは、ユーザーをサポートするアドオンを提供しますが、インタラクティブモードは提供しません。 これにより、この「ビッグデータ」の戦いでSparkがHadoopに勝ちます。
3.フォールトトレランスとセキュリティ
ApacheSparkとHadoopMapReduceはどちらもフォールトトレランス機能を提供しますが、後者が戦いに勝ちます。
これは、Spark環境での操作の途中でプロセスがクラッシュした場合に備えて、最初からやり直す必要があるためです。 ただし、Hadoopに関しては、クラッシュ自体の時点から続行できます。
4.パフォーマンス
SparkとMapReduceのパフォーマンスを検討する場合、前者が後者に勝ちます。
Sparkフレームワークは、ディスク上で10倍、メモリ内で100倍高速に実行できます。 これにより、HadoopMapReduceの3倍の速度で100TBのデータを管理できます。
5.データ処理
Apache SparkとHadoopの比較中に考慮すべきもう1つの要素は、データ処理です。
Apache Hadoopはバッチ処理のみの機会を提供しますが、他のビッグデータフレームワークは、インタラクティブ、反復、ストリーム、グラフ、およびバッチ処理での作業を可能にします。 Sparkがより良いデータ処理サービスを楽しむためのより良いオプションであることを証明する何か。
6.互換性
SparkとHadoopMapReduceの互換性は多少同じです。
両方のビッグデータフレームワークがスタンドアロンアプリケーションとして機能することもありますが、連携して機能することもできます。 SparkはHadoopYARN上で効率的に実行できますが、HadoopはSqoopおよびFlumeと簡単に統合できます。 このため、どちらも互いのデータソースとファイル形式をサポートしています。
7.セキュリティ
Spark環境には、イベントログやWebUIを保護するためのjavaxサーブレットフィルターの使用などのさまざまなセキュリティ機能が搭載されています。 また、共有シークレットを介した認証を促進し、YARNおよびHDFSと統合すると、HDFSファイルのアクセス許可、モード間暗号化、およびKerberosの可能性を活用できます。
一方、Hadoopは、 Kerberos認証、サードパーティ認証、従来のファイルアクセス許可、アクセス制御リストなどをサポートしており、最終的にはより優れたセキュリティ結果を提供します。
したがって、セキュリティの観点からSparkとHadoopの比較を検討すると、後者がリードします。
8.費用対効果
HadoopとSparkを比較すると、前者はディスク上により多くのメモリを必要とし、後者はより多くのRAMを必要とします。 また、SparkはApache Hadoopと比較して非常に新しいため、Sparkを使用する開発者はほとんどいません。
これにより、Sparkでの作業は高額になります。 つまり、HadoopとSparkのコストに焦点を当てると、Hadoopは費用効果の高いソリューションを提供します。
9.市場範囲
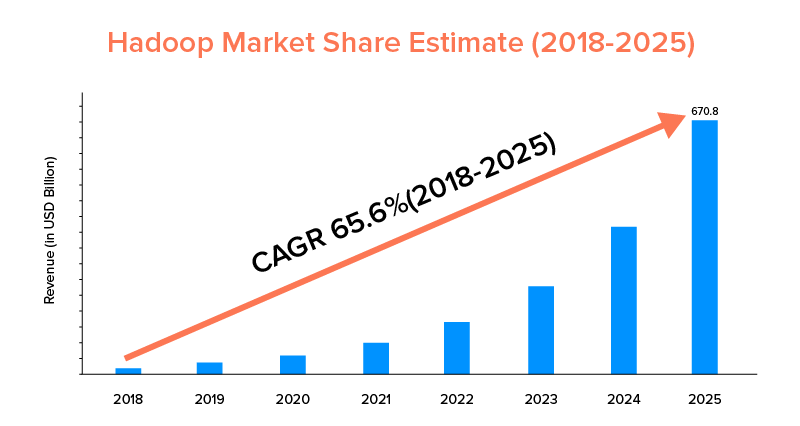
Apache SparkとHadoopはどちらも大企業に支えられており、さまざまな目的で使用されてきましたが、後者は市場範囲の点でリードしています。
市場統計によると、Apache Hadoop市場は、CAGRが33.9%のみのSparkと比較した場合、2018年から2025年の間に65.6%のCAGRで成長すると予測されています。
これらの要素は、ビジネスに適したビッグデータツールを決定するのに役立ちますが、それらのユースケースに精通することは有益です。 それでは、ここで取り上げましょう。
Apache SparkFrameworkのユースケース
このビッグデータツールは、企業が次のことを望むときに採用されます。
- データをリアルタイムでストリーミングおよび分析します。
- 機械学習の力を楽しんでください。
- インタラクティブな分析を行います。
- フォグとエッジコンピューティングをビジネスモデルに導入します。
ApacheHadoopフレームワークのユースケース
Hadoopは、スタートアップや企業が次のことを望むときに好まれます。-
- アーカイブデータを分析します。
- より良い金融取引と予測オプションをお楽しみください。
- コモディティハードウェアで構成される操作を実行します。
- 線形データ処理を検討してください。
これにより、ビジネスに関して「SparkvsHadoop」の戦いの勝者がどちらであるかを決定したことを願っています。 そうでない場合は、ビッグデータエキスパートに連絡して、すべての疑問を解消し、成功率の高い模範的なサービスを利用してください。
よくある質問
1.どのビッグデータフレームワークを選択しますか?
選択は完全にあなたのビジネスニーズに依存します。 パフォーマンス、データの互換性、使いやすさに重点を置いている場合、SparkはHadoopよりも優れています。 一方、アーキテクチャ、セキュリティ、費用対効果に重点を置く場合は、Hadoopビッグデータフレームワークの方が優れています。
2. HadoopとSparkの違いは何ですか?
SparkとHadoopにはさまざまな違いがあります。 例えば:-
- SparkはHadoopMapReduceの100倍の要素です。
- Hadoopはバッチ処理に使用されますが、Sparkはバッチ、グラフ、機械学習、および反復処理を目的としています。
- Sparkはコンパクトで、Hadoopビッグデータフレームワークよりも簡単です。
- Sparkとは異なり、Hadoopはデータのキャッシュをサポートしていません。
3. SparkはHadoopよりも優れていますか?
速度とセキュリティに重点を置いている場合、SparkはHadoopよりも優れています。 ただし、他の場合では、このビッグデータ分析ツールはApacheHadoopに遅れをとっています。
4. SparkがHadoopよりも速いのはなぜですか?
Sparkは、ディスクへの読み取り/書き込みサイクルの数が少なく、中間データをメモリに保存するため、Hadoopよりも高速です。
5. Apache Sparkは何に使用されますか?
Apache Sparkは、必要に応じてデータ分析に使用されます-
- リアルタイムでデータを分析します。
- MLとフォグコンピューティングをビジネスモデルに導入します。
- InteractiveAnalyticsを使用します。