
TW-BERT: エンドツーエンドのクエリ用語の重み付けと Google 検索の将来
公開: 2023-09-14セス・ゴーディンが 2005 年に書いたように、検索は困難です。
つまり、SEO が難しいと考えている場合 (そして実際にそうなのです)、次のような世界で検索エンジンを構築しようとしていると想像してみてください。
- ユーザーは大きく異なり、時間の経過とともに好みも変化します。
- ユーザーが検索にアクセスするテクノロジーは日々進歩しています。
- 競合他社が常にあなたの後を追いついてくるのです。
それに加えて、訪問者にとって最適な最適化方法についての洞察を得るためにアルゴリズムを操作しようとする厄介な SEO にも対処する必要があります。
それは非常に困難になります。
ここで、進歩するために頼る必要がある主要なテクノロジーに独自の限界があり、さらに悪いことに、莫大なコストがかかる場合を想像してみてください。
あなたが最近出版された論文「エンドツーエンドのクエリ用語の重み付け」の著者の一人であれば、これは輝ける機会であると考えているでしょう。
エンドツーエンドのクエリ用語の重み付けとは何ですか?
エンドツーエンドのクエリ用語の重み付けとは、手動でプログラムされた用語や従来の用語の重み付けスキームや他の独立したモデルに依存せず、クエリ内の各用語の重みがモデル全体の一部として決定される方法を指します。
それは何のように見えますか?
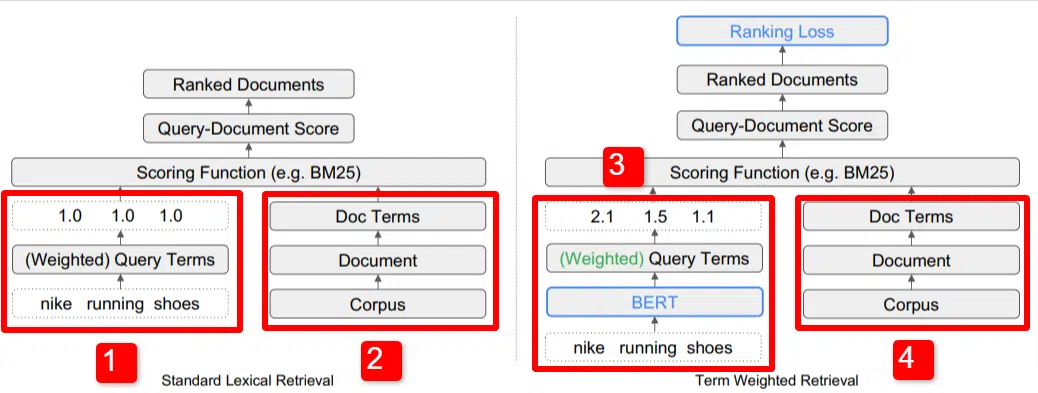
ここでは、論文で概説されているモデルの主要な差別化要因の1 つを図示しています (具体的には図 1)。
標準モデル (2) の右側には、提案されたモデル (4) と同じものがあります。これは、文書につながり、用語につながるコーパス (索引内の文書の完全なセット) です。
これはシステムの実際の階層を示していますが、逆にトップダウンで考えることもできます。 条件があります。 これらの用語を含む文書を探します。 これらの文書は、私たちが知っているすべての文書のコーパスに含まれています。
標準の情報取得 (IR) アーキテクチャの左下 (1) には、BERT 層がないことがわかります。 彼らのイラスト (ナイキ ランニング シューズ) で使用されているクエリがシステムに入力され、重みがモデルとは独立して計算されてモデルに渡されます。
この図では、クエリ内の 3 つの単語間で重みが均等に渡されています。 しかし、必ずしもそうである必要はありません。 これは単にデフォルトであり、優れたイラストです。
理解することが重要なのは、重みがモデルの外部から割り当てられ、クエリでモデルに入力されることです。 これがなぜ重要なのかについては、すぐに説明します。
右側の用語重みバージョンを見ると、クエリ「ナイキ ランニング シューズ」が BERT (具体的には用語重み付け BERT、または TW-BERT) に入り、重みを割り当てるために使用されていることがわかります。そのクエリに適用するのが最適です。
そこからは、両方とも同様のパスをたどり、スコアリング関数が適用され、ドキュメントがランク付けされます。 しかし、新しいモデルには重要な最終ステップがあります。それがすべての重要な点であり、順位の損失の計算です。
上で言及したこの計算により、モデル内で決定される重みが非常に重要になります。 これを最もよく理解するために、ここで何が起こっているのかを本当に理解するために重要である損失関数について少し脇に置いてみましょう。
損失関数とは何ですか?
機械学習における損失関数は、基本的に、システムが可能な限りゼロ損失に近づくように学習しようとする際に、システムがどの程度間違っているかを計算するものです。
たとえば、住宅価格を決定するために設計されたモデルを考えてみましょう。 あなたの家のすべての統計を入力し、その値が 250,000 ドルであると判明したが、あなたの家が 260,000 ドルで販売された場合、その差額は損失とみなされます (これは絶対値です)。
モデルは、多数の例にわたって、最良の結果が得られるまで、与えられたパラメーターに異なる重みを割り当てることで損失を最小限に抑えるように学習されます。 この場合のパラメーターには、平方フィート、寝室、庭の広さ、学校への近さなどが含まれる場合があります。
さて、クエリ用語の重み付けに戻ります
上記の 2 つの例を振り返ると、注目する必要があるのは、ランキング損失計算のダウンファネルの項に重み付けを提供する BERT モデルの存在です。
言い換えれば、従来のモデルでは、項の重み付けがモデル自体とは独立して行われていたため、モデル全体のパフォーマンスに応答できませんでした。 重み付けを改善する方法を学ぶことができませんでした。
提案されたシステムでは、これが変わります。 重み付けはモデル自体の内部で行われるため、モデルがパフォーマンスを向上させ、損失関数を削減しようとするときに、これらの追加のダイヤルを回して項の重み付けを方程式に組み込む必要があります。 文字通り。

ングラム
TW-BERT は、単語に関してではなく、ngram に関して動作するように設計されています。
この論文の著者は、「ナイキ ランニング シューズ」というクエリで単純に単語に重み付けをすれば、ナイキ、ランニング、シューズという単語が含まれるページが上位にランクされる可能性があることを指摘し、単語の代わりに ngram を使用する理由をよく説明しています。 「ナイキ ランニング ソックス」と「スケート シューズ」について話している場合。
従来の IR 方法では、クエリ統計とドキュメント統計を使用するため、この問題または同様の問題がページに現れる可能性があります。 これに対処するための過去の試みは、共起と順序に焦点を当てていました。
このモデルでは、ngram は前の例の単語と同様に重み付けされるため、次のような結果になります。
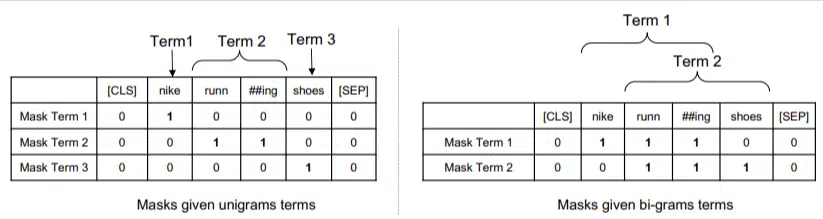
左側には、クエリがユニグラム (1 ワード ngram) としてどのように重み付けされるかを示し、右側にはバイグラム (2 ワード ngram) として重み付けされる方法が表示されます。
このシステムには重み付けが組み込まれているため、頻度などの統計だけに依存するのではなく、すべての順列をトレーニングして最適な ngram とそれぞれの適切な重みを決定できます。
ゼロショット
このモデルの重要な特徴は、ゼロショート タスクでのパフォーマンスです。 著者は以下についてテストしました。
- MS MARCO データセット – 文書およびパッセージのランキング用の Microsoft データセット
- TREC-COVID データセット – COVID の記事と研究
- Robust04 – ニュース記事
- Common Core – 教育記事とブログ投稿
少数の評価クエリのみがあり、微調整には何も使用されませんでした。モデルがこれらのドメイン上のドキュメントを特にランク付けするようにトレーニングされていないという点で、これはゼロショット テストになりました。 結果は次のとおりです。
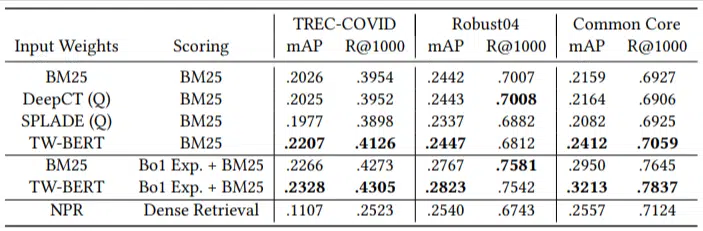
ほとんどのタスクで優れたパフォーマンスを発揮し、短いクエリ (1 ~ 10 ワード) で最高のパフォーマンスを発揮しました。
しかもプラグアンドプレイです!
OK、これは単純化しすぎかもしれませんが、著者は次のように書いています。
「TW-BERT を検索エンジン スコアラーと連携させることで、TW-BERTを既存の実稼働アプリケーションに統合するために必要な変更が最小限に抑えられますが、既存の深層学習ベースの検索方法ではさらなるインフラストラクチャの最適化とハードウェア要件が必要になります。 学習した重みは、標準の字句検索や、クエリ拡張などの他の検索手法で簡単に利用できます。」
TW-BERT は現在のシステムに統合するように設計されているため、統合は他のオプションよりもはるかに簡単で安価です。
これはあなたにとって何を意味しますか
機械学習モデルでは、SEO として何ができるかを予測するのは困難です (Bard や ChatGPT などの目に見える展開は別として)。
このモデルの順列は、その改善と導入の容易さにより、間違いなく導入されるでしょう (記述が正確であると仮定して)。
とはいえ、これは Google の生活の質の向上であり、低コストでランキングとゼロショットの結果を向上させることができます。
私たちが本当に信頼できるのは、実装されればより良い結果がより確実に現れるということだけです。 これは SEO 専門家にとって朗報です。
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。