
キーワード クラスタリングのウィッシュ リストに含めるべき 10 種類のデータ
公開: 2023-06-26
誰もがキーワード クラスターについて話しています。 基本的には非常にシンプルで、関連するキーワードをグループ化します。 簡単そうに思えますよね?
一部の無料ツールでは、キーワード間の重複を排除して意味上の類似性を見つけるのに役立つ、基本的な自然言語処理 (NLP) について説明します。 そこから始めることに何も問題はありませんが、必然的にそれらは制限されます。 一方、Google には、基本的なキーワード操作だけでなく、より多くのコンテキストを提供するためのページ上のデータやリンクなど、アルゴリズムに供給するデータが無限にあります。
Google が世界をどのように見ているかを真に理解するには、SERP データを収集して、どのページがどの用語でランク付けされているかを確認する必要があります。 大規模な場合、上位 10 件の結果で重複する URL の数を比較することで、どの SERP が関連しているかを非常に明確に把握できます。 この手法は最近、キーワード インサイトによって普及しており、これも Nozzle、Cluster AI などから利用できます。
手動でグループ化したはずのキーワードを見つけると、Google では重複する URL がまったく表示されず、その逆も同様です。 このような場合に Google が「正しい」かどうかは関係ありません。これは Google の世界であり、私たちはその中で生きているだけです。
これは、広告を削除して「SEO 代理店」と「SEO 会社」を並べて検索した結果です。上位 10 件中 8 件が同じであることがわかります。
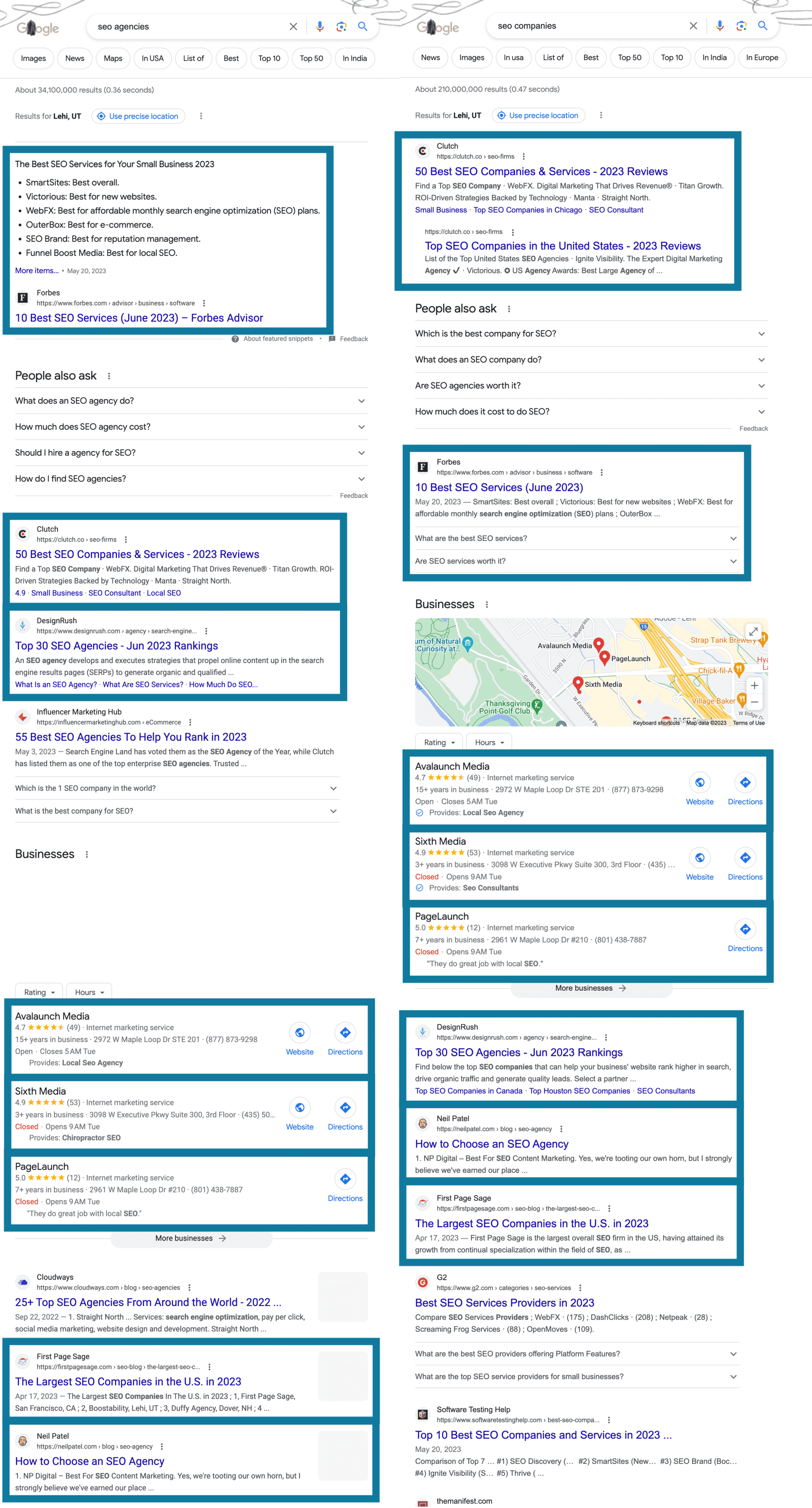
これらの重なり合うページを手動で見つけることは、大規模に行うことはほぼ不可能ですが、優れたツールを使用すれば簡単です。 ここ何年も、キーワード リストの厳選に役立つさまざまなツールが存在していましたが、深く掘り下げることはできませんでした。 基本的なクラスタリングを提供する大きな新製品もありますが、キーワードの 2,000 個の制限には残念です。
キーワードを自動的にクラスタリングするのは素晴らしいことですが、ほとんどのツールはここで終わります。キーワードのリスト、場合によっては検索ボリュームやランクです。 以下は、キーワード クラスターのコンテキストにおいて非常に貴重となる 10 種類のデータのウィッシュリストです。そのほとんどは現在まで入手できませんでした。
- URLのランキング
- 絞り込み条件
- PAA
- よくある質問
- SERPの特徴
- 検索意図
- ランキング順位
- 声のシェア
- エンティティ
- カテゴリー
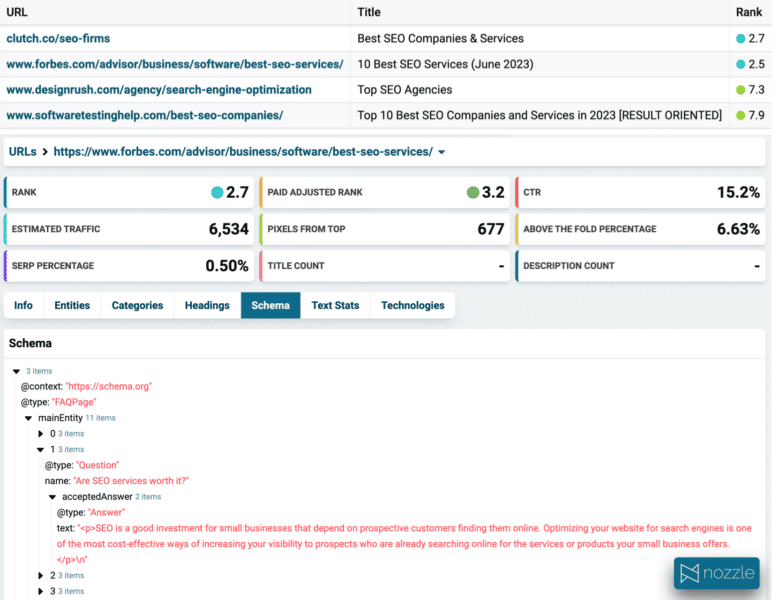
1. URL/ページのランキング
既存のツールでは、クラスター内のすべてのキーワード間でどのページが共有されているかを正確に表示できないため、Google が何に報酬を与えているかを知ることが非常に困難になっています。 さらに、URL の数を知ることで、クラスターの強度/緊密性についての重要な洞察が得られます。 上の例のように、10 個の URL のうち 8 個を共有することは非常にタイトなクラスターであり、適度にタイトな重複するページは 3 ~ 4 つだけです。
また、ほとんどのツールでは、開始する前に重複する URL の数をカウントするかどうかを決定する必要がありますが、これはデータを見る前に知るのは困難です。 探索中にこの値を動的に変更できるはずです。クラスタリング プロセスを再度実行するための料金を支払う必要はありません。
コンテンツ作成ツールの使用経験がある場合は、単一のキーワードで上位の結果を収集して表示できることがよくあります。 クラスター内のすべてのキーワードの URL ランキングを収集する方がはるかに効果的です。
見出し、スキーマ、単語数や学年レベルなどのテキスト統計に関する詳細情報を確認することは、役立つガイドとなります。
2. 絞り込み条件
関連トピック情報の犯罪的に見落とされているソースの 1 つが、すべての SERP の先頭に隠されており、「フィルターとトピック」という隠れた H1 タグが付いているのが便利です。
画像、ニュース、マップなどのいくつかの従来のタブ (検索から検索への変更) の後、Google は関連トピックへのリンクを表示し、通常はトピックを現在のキーワード フレーズの先頭または末尾に追加します。 これらは通常、手動で簡単に識別でき、HTML マークアップ/CSS クラスによって区別することもできます。
3 および 4. よくある質問 (PAA) およびよくある質問 (FAQ)
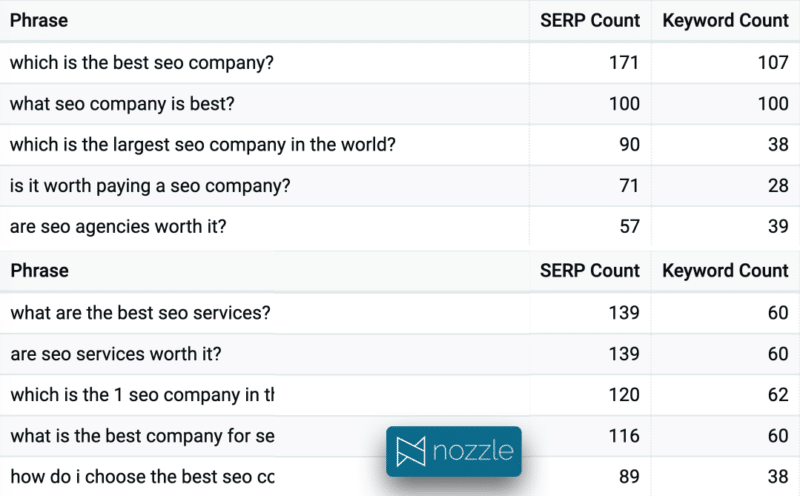
Google がコンテンツ内で何を答えるべきかについての青写真を提供してくれるため、People also Ask の質問はコンテンツ作成者にとって宝の山です。 また、PAA は従来の検索結果よりも不安定であるため、ほとんどのツールで使用される 1 回限りのスクレイピングではなく、時間をかけて集計することで、どの質問が最も頻繁に表示されるかを特定できます。 上記の例では、SERP がほぼ同一であったにもかかわらず、重複する質問はありませんでした。
まず、この特定のクラスターに関する過去 30 日間の上位 10 件の質問があります。 SERP 数は、検索結果が表示された SERP の合計数であり、キーワード数は、質問を表示した一意のキーワードの数です。
PAA と非常によく似ていますが、以下は、正しい schema.org マークアップを実装することで、サイトに大幅に多くの視覚的情報を提供するために、トピックに十分関連していると Google が判断した質問です。
5.SERPの特徴
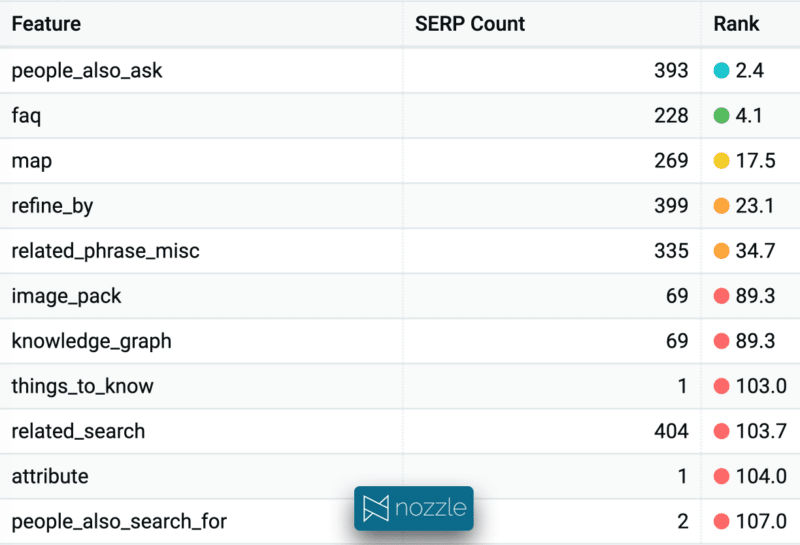
クラスターの特定の SERP 機能の有無は、コンテンツ戦略に影響します。 PAA と FAQ は通常、SERP 上で非常に高い可視性を持っています。このクラスターでは、それぞれ 2.5 位と 4.2 位にランクされています。そのため、適切なマークアップを追加し、適切な質問に答えることで、トラフィックをキャプチャできれば、大量のトラフィックを増加させることができます。 マップには 65% の確率で表示されますが、これは意図が一部分断されていることを示しています。 Things_to_know は 1 つの SERP でのみ表示されますが、最適化すると成長の機会を表す可能性があります。

6. 検索意図
検索意図は戦略全体に影響を与えるため、混合意図を含むクラスター全体の意図を知ることは、優れた戦略を立てる上で非常に重要です。 単一の SERP で複数のページをランク付けする機会を特定するのに役立つように、全体的な集計スコアに加えて、検索意図も結果ごとに利用できる必要があります。 Google 広告の指標など、その意図を伝えるデータがあることも役立ちます。
7. ランキング順位
現在のランキング順位を報告することが重要です。 現在まったくランク付けされていない場合でも、コンテンツにギャップがあるだけで、十分な話題性があれば、公開するだけでランク付けできる簡単な成果があるかもしれません。 同様に、ランクが 8 ~ 15 位の場合は、追加の最適化を行うだけでトラフィックを 10 倍にできる可能性があります。
ピクセル深度やスクロールせずに見える範囲の割合などの新しい指標を含め、ランクだけでなくそれ以上の指標を確認できればボーナス ポイント。
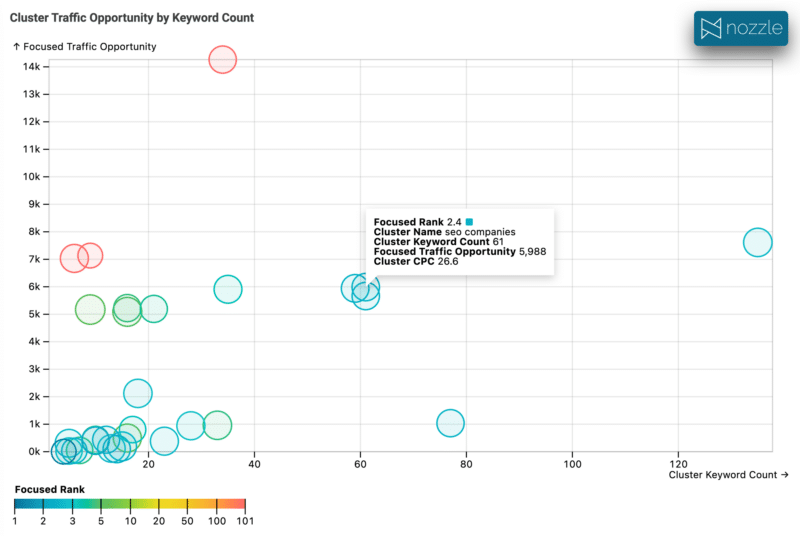
ランクを利用可能にしても、それを有意義に視覚化して機会を特定できなければ、あまり意味がありません。
これは、CPC をバブルの半径、ランクをバブルの色として、検索ボリュームに対するクラスター内のキーワードの数を示します。 条件に一致するクラスターを簡単に特定し、さらに詳細にドリルダウンすることができます。
8. 競合他社の概要/意見の共有
自分のランクを確認できるのは素晴らしいことですが、同じデータを使って競合他社を監視できればさらに良いでしょう。 ドメインを切り替えると、競合を圧倒する神のような力が得られます。
すべてのクラスターが異なるため、各クラスターに異なる競合他社が存在する可能性があるため、クラスターごとの音声のシェアをレポートできるようにしてください。
9. エンティティ
Google は、完全一致キーワードによるウェブの閲覧をやめて久しいです。 それは、自然言語処理 (NLP) を使用してページ コンテンツから抽出されたエンティティによって表現できる意味上の類似性に関するものです。
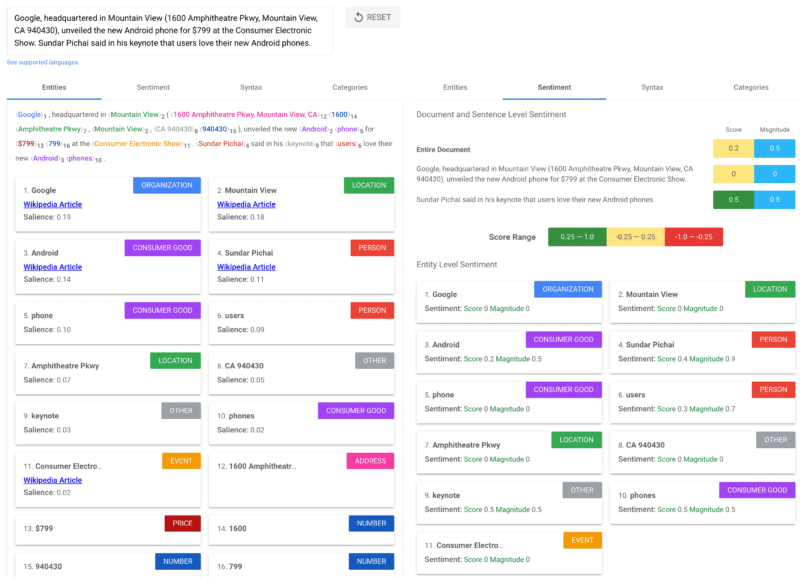
さらに詳しく知りたい場合は、SEL に関する Timothy Warren の記事「Entity SEO: The definitive guide」を読むことを強くお勧めします。 テキストからデータを抽出するための API や spaCy などのオープンソース ツールは数多くありますが、私は Google の API を使用することを好みます。Google には、以下に示すように、テキストの重要な部分を識別するデモがあります。
- 顕著性: テキストに対するエンティティの重要性。
- 感情スコア: -1 から 1 まで。-1 が最も否定的、0 が中立、1 が最も肯定的です。
- 感情の大きさ: 文書内に感情的な内容がどの程度含まれているかを示します。
キーワード クラスターをターゲットとするコンテンツ ライターとして、キーワード密度をさらに進化させていることを願っています。 ただし、Google が認識し、関心を持っているエンティティを正しくターゲットにすることが重要です。
ここで、私たちは Bruce Clay のために執筆しており、この「SEO 企業」クラスターの例をターゲットにすることに決めたとします。 通常、ワークフローでは、ライターがいくつかの重要なページをスキャンしてから、既存のページを更新する必要があります。 エンティティを使用すると、コンテンツの最適化にアプローチする新しい方法が得られます。 同じ NLP を使用して、マップされたページからエンティティを抽出し、それらをクラスター エンティティと比較できます。
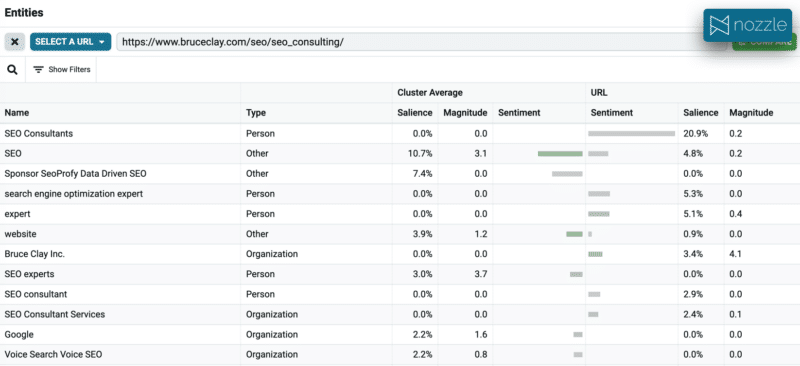
この場合、完全に不一致があることは明らかです。 比較しているページがすでに他のクラスターに対してランク付けされていると仮定すると、これは、このクラスターをターゲットとする新しいコンテンツを作成する必要があることを示す強いシグナルです。
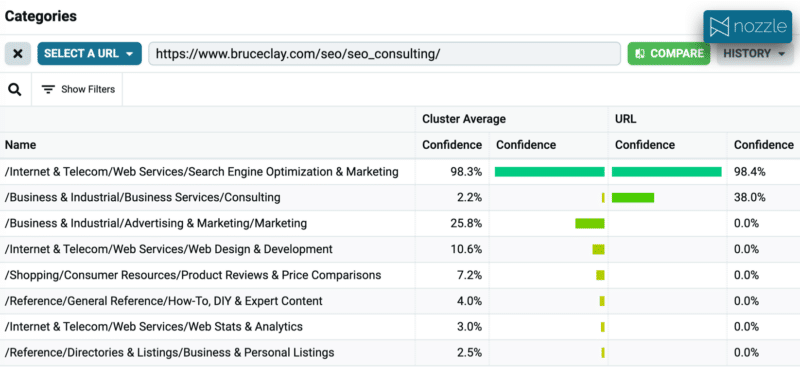
10. コンテンツの分類
エンティティへのアプローチと同様に、コンテンツを分類することもでき、それをクラスターと比較することで不一致を特定できます。
Google には、複数の言語で機能する約 1,100 のカテゴリを備えた分類 API があります。 当然のことながら、SEO はこのクラスターの一致 URL の主要なカテゴリですが、カテゴリ 4 は「製品レビューと価格比較」です。
その信頼レベルでは、比較表を実行してページに追加する必要があるという意味ではありませんが、それが視聴者にとって価値をもたらすかどうかを検討する価値はあります。
結論
これまでは、このデータの一部を表示するだけでも、さまざまなツールを組み合わせなければなりませんでした。 本日、Nozzle は、これらすべてのデータをすぐに利用できるキーワード クラスタリング ツールを Product Hunt で開始しました。 ぜひ無料で独自のキーワードを試してみてください。