
Excel回帰を使用してKPIをよりよく理解する
公開: 2021-10-23ここハナピンにいる私たちのグループは、最近、有名なマイクロソフトエクセルの専門家であるウェインウィンストン博士が監督する無料の21日間のエクセルコースに参加しました。 コース自体は最初は遅いと感じましたが、最終的には私が知らなかったいくつかのExcel機能が明らかになりました。 これらの中で最もエキサイティングなのは、高度な統計ソフトウェア(STATAなど)なしで複数の変数を回帰できることです。 この投稿では、Excelで回帰を設定して実行するためのステップバイステップと、このツールがPPC分析とアカウント管理にどのように役立つかを共有します。
すみません、私は後退します
技術的な実装を掘り下げる前に、「世界でリグレッションとは何ですか?」と疑問に思うかもしれません。 要するに、回帰は変数間の関係を調べます。 従属変数(「Y」)の場合、どの独立変数(「X」)のセットが変動Yに寄与し、回帰モデルはその動作のどの程度を説明しますか? (回帰分析の詳細なレビューについては、ここを参照してください)
線形回帰(または複数の線形回帰)が最も一般的であり、次の形式の合計方程式に適合します。
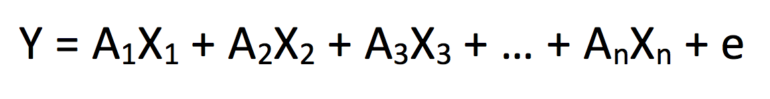
X nはnは独立変数とA 1のセットを表す- - A nはX 1に対応する係数の定数である-ここで、Yは従属変数、X 1 X N。 これは基本的な統計モデルの構築であるため、「y」回の反復ごとに予測結果と観測結果の間に矛盾があることを認識しています。 したがって、このような分散を説明するために、誤差項「+ e」が追加されます。
なぜPPCで回帰するのですか?
回帰は、任意の数の分析で使用できます。 たとえば、クリック単価の変更が平均にどのような影響を与えるかを検討することができます。 位置、失われたインプレッションシェア、または品質スコア。 アカウントレベル、キャンペーンレベル、またはキーワードレベルの品質スコアに最も強い影響を与える要素(期待されるクリック率、ランディングページのエクスペリエンス、または広告の関連性)を調べることができます。 おそらく、以下の例でわかるように、アカウントの全体的なCPAで検索と表示のCPCとコンバージョン率が果たしている役割を明らかにしたいとします。
最終目標が何であれ、回帰モデルの値を設定および決定するプロセスは同じです。
ステップ1:データを準備する
他の分析と同様に、良好な結果を得るには、正しく準備された高品質のデータが必要です。 良好な回帰結果を得るには、十分な量のデータが必要です(少なくとも独立変数の数と同じ数のデータポイントですが、利用できるデータが多いほど、回帰モデルはより正確になります)。 データポイントの数を増やすには、データを日、週、または月でセグメント化することを検討してください(調査する時間枠によって異なります)。
この例では、アドワーズ広告で過去24か月のデータを使用しています。 キャンペーンレポート(月ごとにセグメント化)をダウンロードした後、ピボットテーブルを作成して、月ごとのクリック数、費用、コンバージョン、およびキャンペーンタイプを調べます。
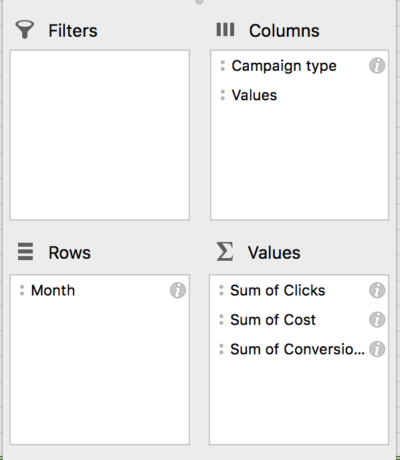
ここから、各ネットワークのCPA、CPC、CVR、および合計CPAを計算できます。 次に、データを1回コピーして新しいシートに貼り付けるだけで、回帰を開始する準備が整います。
ステップ2:モデルを構築する(変数を選択する)
モデル構築には、慎重な計画と柔軟な改訂という2つの主要なコンポーネントがあります。 慎重な計画とは、どの変数がモデルに論理的に最適であるか(およびどのデータを使用できるか)を検討することです。 計画段階で少し余分な時間を費やすと、後でモデルをテストして再テストするときに時間と正気を節約できます。 注意深く準備したとしても、回帰するときにモデルを柔軟に修正し、重要で重要ではない変数を特定する必要がある場合があります。
独立変数を選択する際の2つの重要な注意事項:
- 独立変数は、従属変数と考えられる論理的な関係を持っている必要があります(つまり、東京の平均降雨量とウィスコンシンの心臓発作の数は、調査する相関関係のリストでは低くなります)
- 独立変数は、相互に高度に相関してはなりません(つまり、同じ回帰内の独立変数がモデルで多重共線性エラーを引き起こすため、コスト、クリック数、およびCPCを含めます)
この例では、アカウントのCPAを推進している要因を確認します。 AdWordsで広告を掲載するネットワークには検索と表示の2つがあり、各ネットワークのCPA(コスト/コンバージョン)を促進する2つの主な変数は、CPC(コスト/クリック)とCVR(コンバージョン/クリック)です。 )。
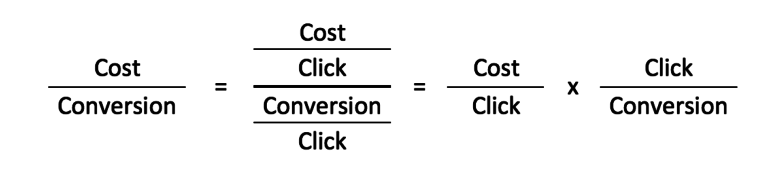
したがって、検索と表示のCPCとCVRでCPAを個別に回帰して、どの独立変数が重要であり、したがって最終モデルに含める必要があるかを判断することから始めます。
ステップ3:回帰と修正
Excelで回帰を実行するには:
1. Excelで回帰を開始する前に、まず独立変数(データ列)が互いに隣接していることを確認します。
2.次に、「Analysis ToolPak」アドオンがExcelで有効になっていることを確認します(有効にすると「データ」リボンに表示されます)。
3.データ分析ツールボックス内で、「回帰」を選択します。
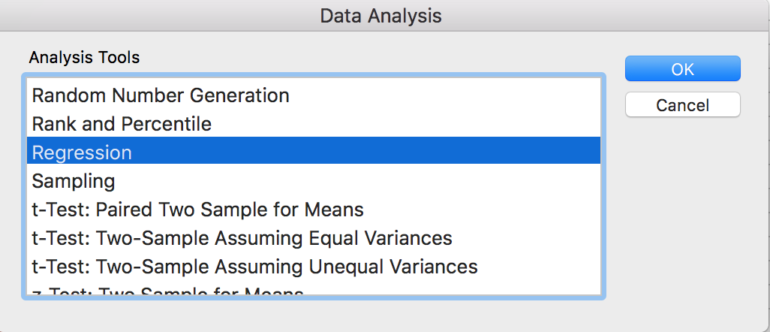
4.従属変数(Y)の範囲と独立変数(X)の範囲を入力し、列ヘッダーを含める場合は[ラベル]を選択します
5.回帰出力(新規または既存のワークシート)の配置を選択します
6.データの外れ値を確認して削除する場合は、「残差」を選択します
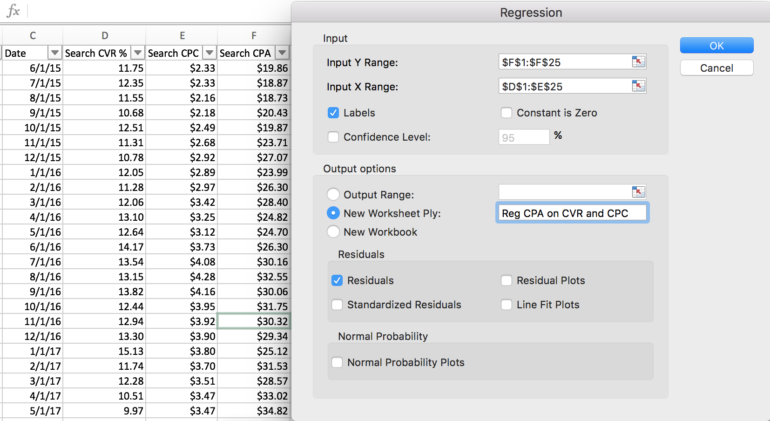
7.「OK」をクリックして回帰を実行します。 出力の概要と詳細を含むシートに自動的に移動します。
8.回帰出力を調べたところ、有意でない独立変数(通常、p値が.1より大きい)または予想よりも低い決定係数(以下の「A」を参照)が明らかになった場合は、必要に応じてこのプロセスを繰り返すことができます。モデルを改良します。
ステップ4:出力を理解する
サマリー出力を初めて見ると、威圧的で落胆する可能性があります。 簡単にするために、以下に強調表示されているのは、回帰で作成したばかりのモデルを評価するのに役立つ出力の主要なセクションです。

(A)R二乗および調整済みR二乗:これは、モデルがデータにどの程度「適合」しているかを示す尺度です。 要するに、決定係数は、従属変数の変動のどれだけが選択された独立変数によって説明されるかを示します。 調整済み決定係数は基本的に同じですが、含まれる独立変数の数も考慮して、わずかに正確な測定値を提供します。 (使用しているモデルとデータのタイプに依存するため、「良い」または「正しい」Rスクエアなどはありませんが、高いほど良いです)。
(B)標準誤差:予測結果と実際の結果の差の2乗の合計の平方根。 正規分布の場合、残差の約65%(以下の「E」を参照)は1標準誤差未満、95%は2未満になります。標準誤差の2倍を超える残差は、通常、データ内で外れ値としてラベル付けされます。
(C)独立変数の係数:係数は、回帰式の「A」項です。 したがって、この例では、CPCの1ユニットの増加は、CPAの8.4の増加に等しいはずです(CVRが一定のままであると仮定)。
(D)独立変数のP値:素人の用語では、P値は独立変数の重要性を示します。 低いP値は重要です(.1未満を目指します)が、高いP値は、知覚された相関が純粋なチャンスである可能性があることを示します。 P値が高い独立変数は、「柔軟な改訂」段階で除外する必要があります。
(E)残差:これは、各反復の従属変数の予測値と実際に記録された値の差を示します。 上記のように、ほとんどの残差は1標準誤差未満である必要があり、ほとんどすべてが2 *標準誤差の値未満である必要があります。 識別された外れ値(標準誤差の2倍を超える残差)をモデルに含めるか除外するかを決定できます。
ステップ5:まとめる(要点!)
3つの回帰を実行した後、検索と表示のCPCとCVRをネットワークと合計CPAに関連付ける次の3つの方程式が見つかりました。



これらの方程式は、検索と表示のCPCとCVRがすべて、合計CPAの動作に重要な役割を果たしていることを私たちがすでに知っている(または私たちが行ったと思った)ことを証明します。 ただし、それ以外にも、標準のヒートマップでは得られない3つのことが明らかになりました。
- 検索CPCの増加は、検索CVRの同等の増加よりも検索CPAに3.5倍の影響を及ぼします。
- ディスプレイCPCの変動は、ディスプレイCPRがディスプレイCPAに与える影響のほぼ5倍です。
- 全体として、ディスプレイネットワークのパフォーマンスの変化は、検索ネットワークのパフォーマンスの同様の大きさの変化よりも、合計CPAに劇的に影響します。
このことから、総CPAの削減を目指しているのであれば、ディスプレイCPCが最適化の最大のターゲットであることは明らかです。 次に、検索CPCとディスプレイCVRがありますが、検索CVRは私の優先事項の中で最も優先度が低くなっています。
リグレッションは強力なツールであり、PPCマネージャーのツールベルトへの優れた追加機能です。 この基本的な例は、回帰が最愛のKPI間の関係を理解するのに役立つ多くの方法の1つにすぎません。 Excelの回帰機能をテストするか、引き続き使用し、経験/考え/発見をTwitterで共有してください。