
生成 AI とは何ですか?また、どのように機能しますか?
公開: 2023-09-26人工知能のサブセットである生成 AI は、テクノロジーの世界で革命的な力として台頭しています。 しかし、それは一体何なのでしょうか? そしてなぜこれほど注目を集めているのでしょうか?
この詳細なガイドでは、生成 AI モデルがどのように機能するか、何ができるか、何ができないか、そしてこれらすべての要素の影響について詳しく説明します。
生成AIとは何ですか?
生成 AI (genAI) は、テキスト、画像、音楽、さらにはビデオなど、新しいコンテンツを生成できるシステムを指します。 従来、AI/ML は、教師あり学習、教師なし学習、強化学習という 3 つのことを意味していました。 それぞれがクラスタリング出力に基づいた洞察を提供します。
非生成 AI モデルは、入力 (画像の分類や文章の翻訳など) に基づいて計算を行います。 対照的に、生成モデルは、エッセイの執筆、音楽の作曲、グラフィックのデザイン、さらには現実世界には存在しないリアルな人間の顔の作成などの「新しい」出力を生成します。
生成型 AI の影響
生成型 AI の台頭は重大な影響を及ぼします。 コンテンツを生成できるようになったことで、エンターテインメント、デザイン、ジャーナリズムなどの業界はパラダイム シフトを目の当たりにしています。
たとえば、通信社は AI を使用してレポートの草稿を作成でき、デザイナーは AI を活用したグラフィックの提案を得ることができます。 AI は、そのオプションが良いかどうかに関係なく、数百の広告スローガンを数秒で生成できます かどうかは別の問題です。
生成 AI は、個々のユーザーに合わせたコンテンツを生成できます。 気分に合わせてユニークな曲を作成する音楽アプリや、興味のあるトピックに関する記事の下書きを作成するニュース アプリのようなものを考えてください。
問題は、コンテンツ作成において AI がより重要な役割を果たすにつれて、真正性、著作権、人間の創造性の価値に関する疑問がより一般的になっていることです。
生成 AI はどのように機能するのでしょうか?
生成 AI の核心は、シーケンス内の次のデータ部分 (それが文内の次の単語であれ、画像内の次のピクセルであれ) を予測することです。 これがどのように達成されるのかを詳しく見てみましょう。
統計モデル
統計モデルは、ほとんどの AI システムのバックボーンです。 彼らは数式を使用して、さまざまな変数間の関係を表します。
生成 AI の場合、モデルはデータ内のパターンを認識するようにトレーニングされ、これらのパターンを使用して生成 新しい同様のデータ。
モデルが英語の文章でトレーニングされる場合、ある単語が別の単語に続く統計的な可能性を学習し、一貫した文章を生成できるようになります。
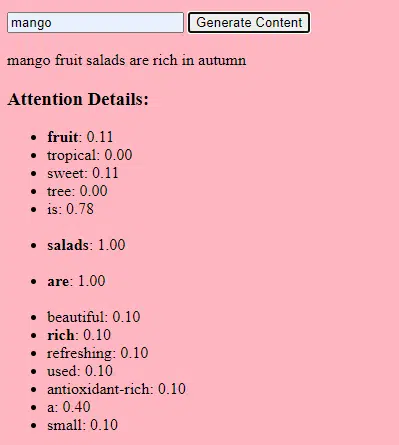
データ収集
データの質と量の両方が重要です。 生成モデルは、パターンを理解するために膨大なデータセットでトレーニングされます。
言語モデルの場合、これは書籍、Web サイト、その他のテキストから数十億の単語を取り込むことを意味する場合があります。
画像モデルの場合、何百万もの画像を分析することを意味する可能性があります。 トレーニング データがより多様で包括的であればあるほど、モデルが多様な出力を生成できるようになります。
変圧器と注意力の仕組み
トランスフォーマーは、Vaswani らによる 2017 年の論文「Attending Is All You Need」で導入されたニューラル ネットワーク アーキテクチャの一種です。 それ以来、これらはほとんどの最先端の言語モデルの基盤となっています。 ChatGPT はトランスフォーマーなしでは動作しません。
「注意」メカニズムにより、人間が文を理解するときに特定の単語に注意を払うのと同じように、モデルは入力データのさまざまな部分に焦点を当てることができます。
このメカニズムにより、モデルは入力のどの部分が特定のタスクに関連するかを決定できるため、モデルが非常に柔軟で強力になります。
以下のコードは、トランスのメカニズムの基本的な分解であり、各部分をわかりやすい英語で説明しています。
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)コードでは、Transformer クラスと 1 つの TransformerLayer クラスが存在する場合があります。 これは、フロアと建物全体の青写真を作成するようなものです。
この TransformerLayer コード部分は、マルチヘッド アテンションや特定の配置などの特定のコンポーネントがどのように機能するかを示しています。
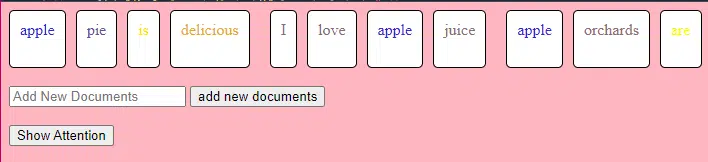
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)フィードフォワード ニューラル ネットワークは、最も単純なタイプの人工ニューラル ネットワークの 1 つです。 これは、入力層、1 つ以上の隠れ層、および出力層で構成されます。
データは一方向、つまり入力層から隠れ層を通って出力層に流れます。 ネットワークにはループやサイクルはありません。
トランスフォーマー アーキテクチャのコンテキストでは、フィードフォワード ニューラル ネットワークは、各層のアテンション メカニズムの後に使用されます。 これは、間に ReLU アクティベーションを挟んだ単純な 2 層の線形変換です。
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)生成 AI の仕組み - 簡単に言うと
生成 AI は重み付けされたサイコロを振るようなものだと考えてください。 トレーニング データによって重み (または確率) が決定されます。
サイコロが文内の次の単語を表す場合、トレーニング データ内の現在の単語に続く単語の重みが高くなります。 したがって、「空」は「バナナ」よりも「青」に続くことが多いかもしれません。 AI がコンテンツを生成するために「サイコロを振る」とき、トレーニングに基づいて統計的により可能性の高いシーケンスを選択する可能性が高くなります。
では、LLM はどのようにしてオリジナルと「見える」コンテンツを生成できるのでしょうか?
「コンテンツマーケティング担当者に最適なイード・アル・フィトルギフト」という偽のリストを取り上げ、LLM がどのように生成できるかを見てみましょう。 このリストは、ギフト、イード、コンテンツ マーケティング担当者に関する文書からのテキストのヒントを組み合わせて作成されます。
処理前に、テキストは「トークン」と呼ばれる小さな部分に分割されます。 これらのトークンは、1 文字ほど短くても、1 単語ほど長くても構いません。
例: 「イード・アル・フィトルはお祝いです」は、[「イード」、「アル・フィトル」、「は」、「a」、「お祝い」] になります。
これにより、モデルは扱いやすいテキストの塊を処理し、文の構造を理解できるようになります。
次に、各トークンは、埋め込みを使用してベクトル (数値のリスト) に変換されます。 これらのベクトルは、各単語の意味とコンテキストを捉えます。
位置エンコーディングは、文内の位置に関する情報を各単語ベクトルに追加し、モデルがこの順序情報を失わないようにします。
次に、アテンション メカニズムを使用します。これにより、モデルは出力を生成するときに入力テキストのさまざまな部分に焦点を当てることができます。 BERT を覚えている方はいると思いますが、これが Google 社員にとって BERT について非常に興奮した点です。
私たちのモデルが「贈り物」に関するテキストを見て、人々がお祝いのときに贈り物をすることを知っていて、「イード・アル・フィトル」が重要なお祝いであるというテキストも見た場合、モデルはこれらのつながりに「注意」を払います。
同様に、特定のツールやリソースを必要とする「コンテンツ マーケター」に関するテキストを見た場合、「ギフト」のアイデアを「コンテンツマーケター」に結び付けることができます。

コンテキストを結合できるようになりました。モデルは複数の Transformer レイヤーを通じて入力テキストを処理する際に、学習したコンテキストを結合します。
したがって、元のテキストに「コンテンツ マーケティング担当者へのイード アル フィトル ギフト」についてまったく言及されていない場合でも、モデルでは「イード アル フィトル」、「ギフト」、および「コンテンツ マーケティング担当者」の概念を組み合わせてこのコンテンツを生成できます。
これは、これらの各用語に関するより広範なコンテキストを学習しているためです。
各 Transformer レイヤーのアテンション メカニズムとフィードフォワード ネットワークを通じて入力を処理した後、モデルはシーケンス内の次の単語の語彙にわたる確率分布を生成します。
「最高」や「イード・アル・フィトル」などの言葉の次には「贈り物」という言葉が来る可能性が高いと考える人もいるかもしれません。 同様に、「ギフト」を「コンテンツ マーケティング担当者」などの潜在的な受取人に関連付けることもできます。
マーケティング担当者が頼りにする毎日のニュースレター検索を入手します。
規約を参照してください。
大規模な言語モデルがどのように構築されるか
基本的なトランスフォーマー モデルから GPT-3 や BERT などの洗練された大規模言語モデル (LLM) への移行には、さまざまなコンポーネントのスケール アップと改良が必要です。
段階的な内訳は次のとおりです。
LLM は、膨大な量のテキスト データでトレーニングされます。 このデータがどれほど膨大であるかを説明するのは困難です。
多くの LLM の開始点である C4 データセットは、750 GB のテキスト データです。 これは 805,306,368,000 バイトであり、多くの情報量になります。 このデータには、書籍、記事、Web サイト、フォーラム、コメント セクション、その他のソースが含まれる場合があります。
データが多様で包括的であればあるほど、モデルの理解と一般化の能力が向上します。
基本的なトランス アーキテクチャが基礎であることに変わりはありませんが、LLM には非常に多くのパラメータがあります。 たとえば、GPT-3 には 1,750 億個のパラメータがあります。 この場合、パラメーターは、トレーニング プロセス中に学習されるニューラル ネットワークの重みとバイアスを指します。
ディープ ラーニングでは、これらのパラメーターを調整して予測と実際の結果の差を減らすことで、モデルが予測を行うようにトレーニングされます。
これらのパラメーターを調整するプロセスは最適化と呼ばれ、勾配降下法などのアルゴリズムが使用されます。
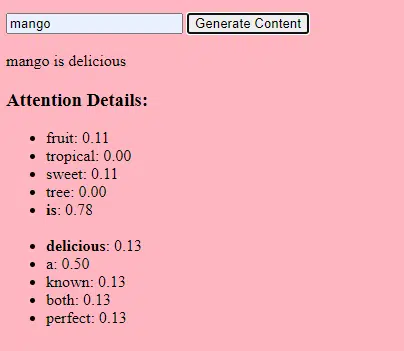
- 重み:これらは、ネットワークのレイヤー内で入力データを変換するニューラル ネットワークの値です。 これらは、モデルの出力を最適化するためにトレーニング中に調整されます。 隣接する層のニューロン間の各接続には、関連する重みがあります。
- バイアス:これらは、レイヤーの変換の出力に追加されるニューラル ネットワークの値でもあります。 これらにより、モデルにさらなる自由度が提供され、トレーニング データによりよく適合できるようになります。 層内の各ニューロンには関連するバイアスがあります。
このスケーリングにより、モデルはデータ内のより複雑なパターンと関係を保存および処理できるようになります。
パラメーターの数が多いということは、モデルがトレーニングと推論に大量の計算能力とメモリを必要とすることも意味します。 このようなモデルのトレーニングにはリソースが大量に消費され、通常は GPU や TPU などの特殊なハードウェアが使用されるのはこのためです。
このモデルは、強力な計算リソースを使用してシーケンス内の次の単語を予測するようにトレーニングされます。 エラーに基づいて内部パラメータを調整し、予測を継続的に改善します。
これまで説明してきたような注意メカニズムは、LLM にとって極めて重要です。 これらにより、モデルは出力を生成するときに入力のさまざまな部分に焦点を当てることができます。
アテンション メカニズムにより、コンテキスト内のさまざまな単語の重要性を評価することで、一貫性があり、コンテキストに関連したテキストをモデルが生成できるようになります。 これをこの大規模な規模で実行することで、LLM は通常どおりに動作できるようになります。
トランスフォーマーはどのようにしてテキストを予測するのでしょうか?
トランスフォーマーは、複数のレイヤーを通じて入力トークンを処理することによってテキストを予測します。各レイヤーにはアテンション メカニズムとフィードフォワード ネットワークが装備されています。
処理後、モデルはシーケンス内の次の単語の語彙にわたる確率分布を生成します。 通常、最も高い確率を持つ単語が予測として選択されます。
大規模な言語モデルはどのように構築され、トレーニングされるのでしょうか?
LLM の構築には、データの収集、データのクリーニング、モデルのトレーニング、モデルの微調整、および精力的な継続的なテストが含まれます。
モデルは最初に、シーケンス内の次の単語を予測するために膨大なコーパスでトレーニングされます。 このフェーズでは、モデルが文法のパターンを拾う単語間のつながり、世界に関する事実を表すことができる関係、論理的推論のように感じられるつながりを学習できます。 これらの接続により、トレーニング データに存在するバイアスも検出されます。
事前トレーニングの後、モデルはより狭いデータセットで洗練され、多くの場合、ガイドラインに従って人間のレビュー担当者が使用されます。
微調整は、LLM を構築する際の重要なステップです。 これには、より具体的なデータセットまたはタスクで事前トレーニングされたモデルをトレーニングすることが含まれます。 ChatGPT を例に挙げてみましょう。
GPT モデルを使ったことがある人なら、プロンプトは「これを書いてください」というよりも、むしろ「これを書いてください」に近いものであることがわかるでしょう。
- プロンプト:むかしむかし
- 続き:塔の頂上には邪悪な魔法使いがいました。
- 続き:塔の頂上には邪悪な魔法使いがいました。
- プロンプト: ニワトリはなぜバンドに参加したのですか?
- 続き:バチがあったから!
そこから ChatGPT に到達するには、多くの低賃金労働が必要になります。 これらの人々は、GPT 応答と予想される動作の重要性を把握するために膨大なコーパスを作成します。 これらの作業者は、次のような大量のプロンプト/継続テキストを作成します。
- プロンプト: このストーリーを終了します: 「むかしむかし…」
- 続き:確かに! むかしむかし、遠く離れた国に、雄大な 2 つの山の間に位置する小さな村がありました。
- 続き:確かに! むかしむかし、遠く離れた国に、雄大な 2 つの山の間に位置する小さな村がありました。
- プロンプト: ニワトリに関するジョークを教えてください。
- 続き:ニワトリはなぜバンドを組んだのか? ドラムスティックがあったからです!
この微調整プロセスは、次のような理由から不可欠です。
- 特異性:事前トレーニングによりモデルは言語を幅広く理解できるようになりますが、微調整によりモデルの知識と動作が絞り込まれ、特定のタスクやドメインに合わせて調整されます。 たとえば、医療データに基づいてモデルを微調整すると、医学的な質問に対する答えが向上します。
- 制御:微調整により、開発者はモデルの出力をより詳細に制御できるようになります。 開発者は、厳選されたデータセットを使用して、モデルが望ましい応答を生成し、望ましくない動作を回避できるようにガイドできます。
- 安全性:有害な出力や偏った出力を減らすのに役立ちます。 微調整プロセス中にガイドラインを使用することで、人間のレビュー担当者は、モデルが不適切なコンテンツを生成しないことを確認できます。
- パフォーマンス:微調整により、特定のタスクにおけるモデルのパフォーマンスを大幅に向上させることができます。 たとえば、顧客サポート用に微調整されたモデルは、汎用モデルよりもはるかに優れています。
ChatGPT は特にいくつかの点で微調整されていることがわかります。
たとえば、「論理的推論」は LLM が苦手とする傾向にあるものです。 ChatGPT の最高の論理推論モデル – GPT-4 – は、数値のパターンを明示的に認識するために徹底的にトレーニングされています。
このようなものの代わりに:
- プロンプト: 2+2 とは何ですか?
- プロセス: 子供向けの算数の教科書では、2+2 =4 がよく登場します。 時折、「2+2=5」への言及がありますが、その場合は通常、ジョージ・オーウェルやスタートレックと関係のある文脈がより多くあります。 これがそのような文脈であれば、重みは 2+2=5 の方が有利になるでしょう。 しかし、そのコンテキストは存在しないため、この例では次のトークンはおそらく 4 です。
- 応答: 2+2=4
トレーニングでは次のようなことを行います。
- トレーニング: 2+2=4
- トレーニング: 4/2=2
- トレーニング: 4 の半分は 2
- トレーニング: 2/2 は 4
…等々。
これは、より「論理的」なモデルの場合、トレーニング プロセスがより厳密になり、モデルが論理的および数学的原理を理解し、正しく適用できるようにすることに焦点を当てていることを意味します。
モデルはさまざまな数学的問題とその解決策にさらされており、これらの原則を一般化し、まだ見ぬ新しい問題に適用できることが保証されています。
この微調整プロセスの重要性、特に論理的推論の重要性は、どれだけ強調してもしすぎることはありません。 これがないと、モデルは単純な論理的または数学的な質問に対して、不正確または無意味な回答を提供する可能性があります。
画像モデルと言語モデルの比較
画像モデルと言語モデルはどちらもトランスフォーマーなどの同様のアーキテクチャを使用している可能性がありますが、処理されるデータは根本的に異なります。
画像モデル
これらのモデルはピクセルを扱い、多くの場合、最初に小さなパターン (エッジなど) を分析し、次にそれらを組み合わせてより大きな構造 (形状など) を認識するなど、画像全体を理解するまで階層的な方法で機能します。
言語モデル
これらのモデルは、単語または文字のシーケンスを処理します。 一貫した文脈に関連したテキストを生成するには、文脈、文法、意味論を理解する必要があります。
著名な生成 AI インターフェイスの仕組み
Dall-E + ミッドジャーニー
Dall-E は、画像生成に適応した GPT-3 モデルのバリアントです。 これは、テキストと画像のペアの膨大なデータセットでトレーニングされます。 Midjourney も、独自のモデルに基づいた画像生成ソフトウェアです。
- 入力: 「双頭のフラミンゴ」などのテキストによる説明を入力します。
- 処理:これらのモデルは、このテキストを一連の数値にエンコードし、次にこれらのベクトルをデコードして、ピクセルとの関係を見つけて画像を生成します。 モデルは、トレーニング データからテキストの説明と視覚的表現の間の関係を学習しました。
- 出力:指定された説明に一致する、またはそれに関連する画像。
指、パターン、問題
なぜこれらのツールは正常に見える手を一貫して生成できないのでしょうか? これらのツールは、隣り合うピクセルを調べることによって機能します。
以前に生成された、またはよりプリミティブなイメージと、より最近のイメージを比較すると、これがどのように機能するかがわかります。以前のモデルは非常に曖昧に見えます。 対照的に、最近のモデルはより鮮明です。
これらのモデルは、すでに生成されたピクセルに基づいて次のピクセルを予測することによって画像を生成します。 このプロセスは何百万回も繰り返されて、完全な画像が生成されます。
手、特に指は複雑で、正確に捉える必要がある細部がたくさんあります。
各指の位置、長さ、方向は、画像によって大きく異なる場合があります。
テキストによる説明から画像を生成する場合、モデルは手の正確なポーズと構造について多くの仮定を行う必要があり、これが異常を引き起こす可能性があります。
チャットGPT
ChatGPT は、自然言語処理タスク用に設計されたトランスフォーマー ベースのモデルである GPT-3.5 アーキテクチャに基づいています。
- 入力:会話をシミュレートするためのプロンプトまたは一連のメッセージ。
- 処理: ChatGPT は、さまざまなインターネット テキストからの膨大な知識を使用して応答を生成します。 会話で提供されたコンテキストを考慮し、最も適切で一貫した応答を生成しようとします。
- 出力:会話を継続するか、会話に答えるテキスト応答。
専門
ChatGPT の強みは、さまざまなトピックを処理し、人間のような会話をシミュレートできる機能にあり、チャットボットや仮想アシスタントに最適です。
吟遊詩人 + 検索生成エクスペリエンス (SGE)
特定の詳細は独自の情報である可能性がありますが、Bard は他の最先端の言語モデルと同様に、トランスフォーマー AI 技術に基づいています。 SGE は同様のモデルに基づいていますが、Google が使用する他の ML アルゴリズムが組み込まれています。
SGE はおそらく、トランスフォーマーベースの生成モデルを使用してコンテンツを生成し、検索のランキング ページから回答をファジー抽出します。 (これは真実ではないかもしれません。実際に遊んでみてどう機能するかに基づいた推測にすぎません。私を訴えないでください!)
- 入力:プロンプト/コマンド/検索
- 処理: Bard は入力を処理し、他の LLM と同じように動作します。 SGE は同様のアーキテクチャを使用しますが、内部知識 (トレーニング データから得られる) を検索して適切な応答を生成するレイヤーを追加します。 プロンプトの構造、コンテキスト、および関連するコンテンツを作成する意図が考慮されます。
- 出力:ストーリー、回答、またはその他のタイプのテキストとなる生成されたコンテンツ。
生成型 AI の応用 (およびその論争)
アートとデザイン
生成 AI はアートワーク、音楽、さらには製品デザインさえも作成できるようになりました。 これにより、創造性と革新性への新たな道が開かれました。
論争
アートにおけるAIの台頭は、クリエイティブな分野での雇用喪失についての議論を引き起こしている。
さらに、次のような懸念もあります。
- 労働違反、特に AI によって生成されたコンテンツが適切な帰属や補償なしに使用された場合。
- 幹部らが作家をAIに置き換えると脅迫したことは、作家らのストライキを引き起こした問題の1つである。
自然言語処理 (NLP)
AI モデルは現在、チャットボット、言語翻訳、その他の NLP タスクに広く使用されています。
汎用人工知能 (AGI) の夢を除けば、LLM は「ジェネラリスト」NLP モデルに近いため、これが LLM の最適な用途です。
論争
多くのユーザーは、チャットボットが非人間的で、時には煩わしいと感じています。
さらに、AI は言語翻訳において大きな進歩を遂げましたが、人間の翻訳者がもたらすニュアンスや文化的理解を欠いていることが多く、印象的で欠陥のある翻訳につながっています。
医学と創薬
AI は膨大な量の医療データを迅速に分析し、潜在的な薬剤化合物を生成することで、創薬プロセスをスピードアップします。 多くの医師はすでに LLM を使用してメモや患者とのコミュニケーションを作成しています
論争
医療目的で LLM に依存すると、問題が発生する可能性があります。 医療には正確さが求められ、AIによる誤りや見落としは重大な結果を招く可能性があります。
医学にもすでに偏見があり、LLM を使用するとさらに偏見が定着します。 以下で説明するように、プライバシー、有効性、倫理に関しても同様の問題があります。
ゲーム
多くの AI 愛好家は、ゲームでの AI の使用に興奮しています。彼らは、AI が現実的なゲーム環境、キャラクター、さらにはゲーム プロット全体を生成し、ゲーム エクスペリエンスを向上させることができると言っています。 これらのツールを使用することで、NPC の会話を強化できます。
論争
ゲームデザインにおける意図性については議論があります。
AI は膨大な量のコンテンツを生成できますが、人間のデザイナーがもたらす意図的なデザインや物語の一貫性が AI には欠けていると主張する人もいます。
Watchdogs 2 にはプログラムによる NPC がありましたが、ゲーム全体の物語の一貫性を高めるにはほとんど役に立ちませんでした。
マーケティングや広告
AI は消費者の行動を分析し、パーソナライズされた広告やプロモーション コンテンツを生成して、マーケティング キャンペーンをより効果的にすることができます。
LLM には他の人が書いたコンテキストが含まれているため、ユーザー ストーリーやより微妙なプログラムのアイデアを生成するのに役立ちます。 LLM は、テレビを購入したばかりの人にテレビを勧めるのではなく、誰かが欲しがるかもしれないアクセサリを代わりに勧めることができます。
論争
マーケティングにおける AI の使用には、プライバシーに関する懸念が生じます。 AI を使用して消費者の行動に影響を与えることの倫理的影響についても議論があります。
さらに深く掘り下げる:マーケティングにおける大規模な言語モデルの使用を拡張する方法
LLMS に関する継続的な問題
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。