
SEO における情報の獲得: それが何であり、なぜ重要なのか
公開: 2023-07-25「情報獲得スコア」に関する Google の特許は 2022 年 6 月に取得されました。その後、役立つコンテンツの更新を含むいくつかのアルゴリズムの更新が行われたのは偶然ではないと思います。
情報獲得スコアは、Google が「EEAT の品質を示すオリジナルで高品質、人間優先のコンテンツ」である貴重なコンテンツを優先するための重要な方法ですか?
私の仮説:はい。 その理由は次のとおりです。
情報獲得スコアとは何ですか?
情報獲得スコアは、基本的に、コンテンツがコーパスの残りの部分と比べてどの程度ユニークであるかを示す尺度です。 ここで、コーパスは、検索された特定のクエリのランキングにおいて Google が分析するすべての潜在的なドキュメントになります。
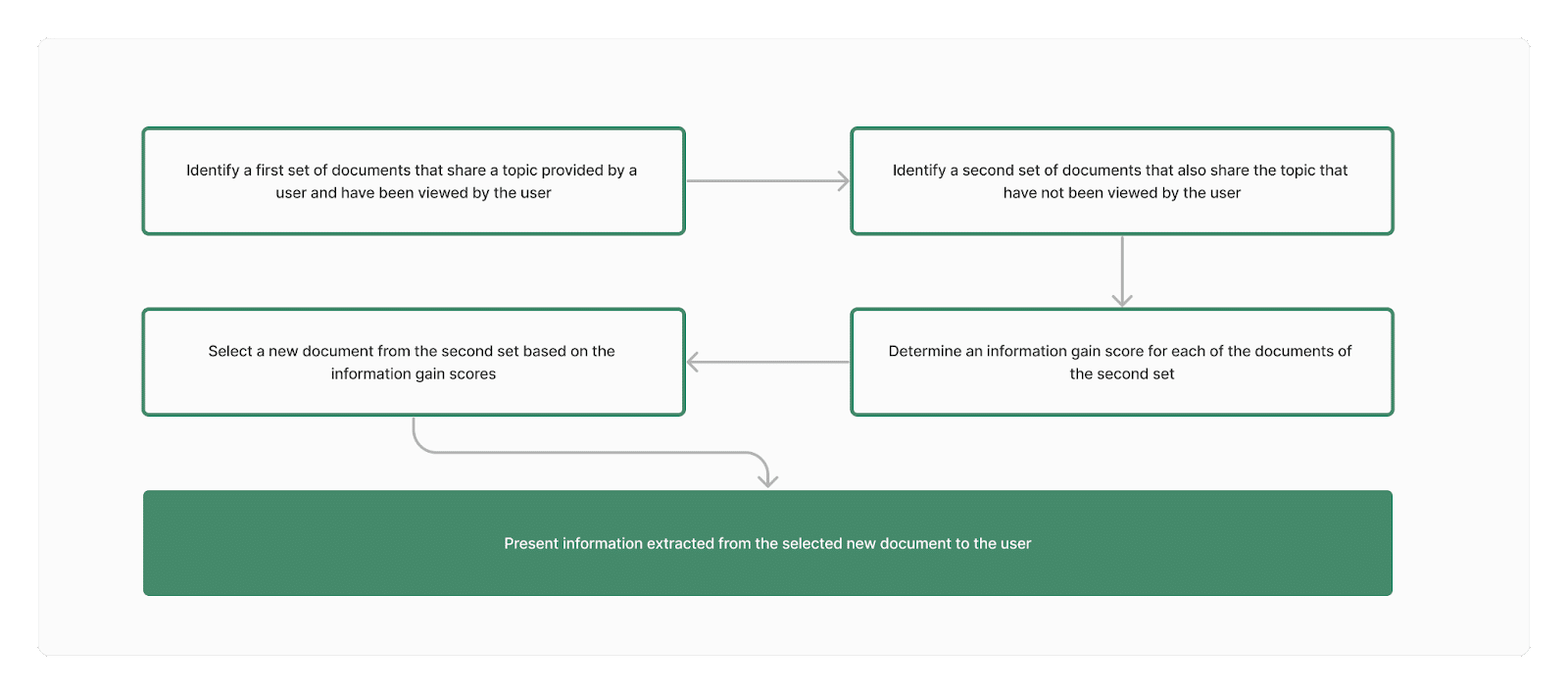
この特許では、情報獲得スコアを計算するために与えられたシナリオのほとんどは、後続のクエリまたはドキュメント ビューおよび検索結果ビューの後に実行されます。 これは、個人および/またはその人が探しているトピックに固有の学習プロセスです。
故ビル・スロースキー氏は、特許がまだ審査中の 2020 年にこのプロセスの技術的詳細を書きました。
特許用語で私が見た興味深い点の 1 つは次のとおりです。
Google は、情報獲得スコアをアルゴリズムで計算し、機械学習モデル全体のトレーニング データとして適用する余地を与えています。
情報獲得スコアを計算するための最初の文書セットの必要性は、将来的には不要になる可能性があります。
「一部の実装では、2 番目の文書セットの各文書からのデータが、入力として機械学習モデル全体に適用される場合があります。」
情報の獲得は検索ランキングにどのように影響しますか?
現実世界の観点から見ると、これは Google を意味します。
- コンテンツがそのトピック領域の残りのコンテンツと比べてどの程度ユニークであるかを計算する方法があります。
- 差異または同一性のレベルに基づいて、コンテンツを積極的に昇格または降格するための指標があります。
情報獲得スコアは、AI 生成コンテンツと新しいコンテンツ ファームを対象とした新しいアルゴリズム要素を示唆しています。
したがって、コンテンツが独自性を欠いている場合は、たとえ異なる単語が異なる配置で構成されている場合でも、コンテンツが降格される可能性があります。
Skyscraper コンテンツは、この対象を絞った降格の一部となる可能性があります。
情報獲得スコアと役立つコンテンツ システムは、現在「完全に最適化された」コンテンツの海が存在する状況でイノベーションを推進しています。
マーケティング担当者が頼りにする毎日のニュースレター検索を入手します。
規約を参照してください。

情報を得ることでウェブサイトの可視性が向上するでしょうか?
取得した情報を使用してコンテンツを作成または更新するには、2 つのプロセスがあります。
- データのソースを分析します。
- 市場機会を特定します。
理想的なシナリオでは、「SEO 要件」や Google を使用せずにクライアントの X 問題を解決することについて書くよう依頼された場合、専門家や営業マネージャーが何を生み出すことができるかを見るのは興味深いでしょう。 その結果、驚くほど革新的で適切な対応が得られるかもしれません。
私たちのほとんどには、そのような暗闇の中で撮影する余裕はなく、コンテンツの作成方法を変更、更新、適応させるには、もう少し構造が必要です。
それでは、そのアプローチをどのように変更できるかを詳しく見てみましょう。
どこから情報を入手していますか?
一歩後退したように感じるかもしれませんが、コンテンツのリサーチにこれまで以上に時間を費やす準備をしてください。
Web とランク付けしたい SERP からのみ情報を取得している場合、あなたも問題の一部である可能性があります。 みんなやっているけど、ちょっと怠惰ですよね?
優れた高品質のコンテンツには時間がかかります。
私たちが公開し、企業、ブランド、そして私たち自身を宣伝する方法として拡大および使用しているコンテンツは、「ソート リーダーシップ」の基準を満たすことができる必要があります。
それには何が必要ですか? ソート リーダーシップの基礎は基本的に情報に基づいた意見です。
そのためには、自分の立場をとったり、特定の意見を持ったり、特定の結論に達したりする必要があります。
そのためには、その意見を裏付ける情報が必要です、あるいはそうすべきです。
どの企業でも、クライアントや顧客向けの記事やツールで使用するのを待っている次のような独自のデータを持っているでしょう。
- カスタマーサービスチームからのフィードバックとログ。
- あなたのレビュー。
- 営業チームからのフィードバックと営業電話。
- 製品の使用状況データ (集計して公開できる場合)。
これらはすべて、競合他社が簡単に複製できないコンテンツ ソースです。
また、Google では作成できないリッチ メディア エクスペリエンスに変えることもできます。
また、実際の顧客とその実際の経験からも情報が得られます。
検索結果で作成するように「指示」されているコンテンツの多くは、実際には顧客にとって適切ではない可能性があります。
自分のデータから始めると、純粋に検索エンジン用に書かれた多くのコンテンツが自然に除外されます。
市場にはどのような機会があるでしょうか?
Google や Bing にアクセスして、検索結果で上位に表示される記事の形式に従いたくなるかもしれませんが、Google がその記事を最高位にランク付けしているのは、アクセスできる記事の中で最高のものであるという理由だけであることに注意してください。
コンテンツがまだ存在しない場合、ユーザーが検索しているものに正確に答える独自のコンテンツを (まだ) 作成することはできません。
したがって、コンテンツのランキングは、実際の専門知識を満たし、確かな答えを提供するという意味ではまったくゴミになる可能性がありますが、最悪の中の最良のものであるため、ランク付けされます。
したがって、新しいコンテンツを作成するときは、トピックの関連性や、おそらく他の競合他社が活用していない、執筆しているトピックに関連する領域にも目を向ける必要があります。
競合他社の既存の話題の関係を確認するのに役立つツールには、次のものがあります。
- 自然言語 API のデモ
- Diffbot のデモ
- 軌道上
主要トピック (競合他社がカバーしていない可能性があるもの) の意味論的なトピック関係を理解するために使用できるツールには、次のものがあります。
- マーケットミューズ
- Ryte経由のTF-IDF
- Semrush によるキーワード クラスタリング (有料)
- 潜在ディリクレ割り当てと Python を使用して独自のトピック モデリング ツールを作成します (未テスト)
これらのツールにはそれぞれ独自のトレードオフと考慮事項があり、組織が行っているデータの侵害と比較検討する必要があります。
他のものと同様、これらも Google の検索エンジンのランキング システムの仕組みの近似値です。
また、最近公開された AI によるコンテンツの大量発生は、Google にとって現実世界のコストに影響を与えるということも覚えておくと良いでしょう。
コンテンツが増えると、電気料金も徐々に高くなることを意味するため、彼らは 3 つのクローラーすべてを通過する前に、できるだけ多くのコンテンツを削除することに関心を持っています。
したがって、顧客と Google の両方に利益をもたらすコンテンツを作成する方法を見つけてください。
この記事で表明された意見はゲスト著者の意見であり、必ずしも Search Engine Land とは限りません。 スタッフの著者はここにリストされています。