
2016年の締めくくりとして、CROテストの締めくくりについてお話しましょう
公開: 2021-10-23さらにもう1年の締めくくりに近づき、「このテストはいつ終了できるのか」という質問があります。 それでも少なくとも週に1回は会話に出てきますが、座ってテストの結論プロセスとこの決定に影響するすべての変数を書き出す時が来たように感じました。
今日は、結論に近づくときに覚えておくべき2つのヒントを紹介します。次に、この決定に近づくときに検討する4つの変数について説明します。 あなたがずっと前に埋めたその統計教科書からほこりを吹き飛ばして、始めましょう。
序文のヒント#1:データがきれいで堅牢であることを確認する
テストを設定する前に、目標が何であるかをすでに知っている必要があります。 そこで私が「目標」と言ったことに注目してください。 はい、一元化された変換が必要であることは誰もが知っています。 ユーザーを動かしている1つの大きなこと。 しかし、変更がそれらの相互作用にも影響を与えたかどうかを観察するために追跡できるサイトとの相互作用は他にもたくさんあります。 いくつかの例については、以下の画像を参照してください。

テストデータを分析する前に、データがすべて同じ競技場にあることを再確認してください。 1つのデータ文字列を歪めることなくデータポイントを適切に比較できるように、同じ正確な日付範囲の各目標のデータを取得したことを確認してください。 ここにいる間、すべての目標データが「正常」に見えること、および何のアクションも見たことがない失火した目標や死んだ目標を疑わないことも確認してください。
序文のヒント#2:単一の変数で結論を出さないでください
結論を下す決定は、1つの変数に依存することはできません。 これらの4つの変数のそれぞれを考慮に入れ、変数の大部分が互いに補完し合う場合は、自信を持って結論を出すことができます。
すべての変数が互いに矛盾している場合は、さまざまなシナリオを検討している可能性があります。 しかし、その時点で、あなたが結論を下すならば、あなたは費用のかかる結果を伴う非論理的な決定をしている可能性があります。
これらの各変数は、他の変数の少なくとも1つに影響されるか、影響を受けます。 したがって、補完的なデータはそれ自体をサポートしますが、矛盾するデータはドットを嘘の網に接続することを強制します。 しないでください!
変数#1:サンプルサイズ
サンプルサイズは重要です。 サンプルサイズにより、母集団(総ユーザー数)と許容誤差(100ゴールの統計的有意性)に基づいて、行動を自信を持って一般化できます。
それは本当にプロポーションがすべてですが、トラフィックの変動がほとんどない同じサイトを一貫して見ている場合は、作業の最終的な目標を設定できます。
テストの各セグメントへの100人のユーザーは、正当な最低限です。 トラフィックの少ないサイトでも、少数のユーザーのデータに基づいて行動を一般化することは非常に困難です。 したがって、より多くのメリットがあります。 サンプルサイズを大きくすると、外れ値から見えるスキューを無効にすることもできます。
ただし、1日あたり少なくとも1,000人のユーザーを取り込むかなり大規模なeコマースサイトでは、100人の適切なサンプルサイズのユーザーを検討する方法はありません。 それはすべてプロポーションとあなたのサイトの定期的な典型的なユーザーボリュームです。
この変数には、考慮に入れる目標のコンバージョンとユーザーが含まれます。 コンバージョン率の低いサイトを使用している場合でも、0回のコンバージョンと2回のコンバージョンを比較すると、技術的にコンバージョンする唯一のバリエーションであるため、2回のコンバージョンのバリエーションが最も確実に勝ちます。
コンバージョンが少なくとも2桁であることを確認してください。 それが最低限(2桁)である場合は、他の3つの変数に強力な補完アクションがあることを確認してください。
または、統計設定でのサンプルサイズの経験があまりない場合は、この便利でダンディなサンプルサイズ計算機を使用して、適切なサンプルサイズを決定できます。
変数#2:テスト期間
理想的には、2〜6週間のどこかでテストを実行します。
変数が「良い」または「悪い」週を持ち、幸せなトラフィックを運ぶか、意欲の低いトラフィックを追い払う可能性を無効にするため、2週間は確実な最小値です。 6週間は、目に見える変動をキャプチャするのに十分な幅の一時的なネットであるため、素敵な最大値です。
ただし、テストを永久に実行すると、テストに悪影響を与える可能性があることに注意してください。 テスト結果の大きな要因は、新しい刺激に対するユーザーの反応です。 したがって、最初にテストを開始したとき、ゲートから大きな飛躍が見られる傾向があり、1つのバリエーションが劇的に失われ、他のバリエーションはその連勝で惰性で進みます。 時間の経過とともに、バリエーション間のこの大きなギャップは正常化して閉じる傾向があります。これは、「新しい」が使い果たされ、リピーターが以前ほど新しい変更の影響を受けないためです。 したがって、テストの実行時間が長くなるほど、変更の目新しさが少なくなり、リターンユーザーの動作への影響が少なくなります。
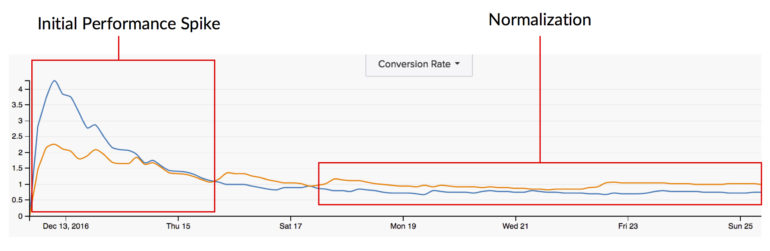
変数#3:統計的有意性
結論で「自信」を宣言するには統計的有意性が重要ですが、それは非常に誤解を招く可能性もあります。
統計的有意性は、2つの率の変化が通常の分散によるものか、外部要因によるものかを決定します。 したがって、理論的には、強い統計的有意性に達すると、変更がユーザーに影響を与えたことがわかります。
理想的には、可能な限り100%に近い統計的有意性を目指します。 100%に近づくほど、許容誤差は小さくなります。 これは、結果をより一貫性のある方法で再現できることを意味します。 統計的有意性が高いほど、勝利のバリエーションを実装した場合に、そのコンバージョン率の上昇を維持する可能性が高くなります。 95%は目標とするのに良い高い目標です。 90%は落ち着くのに良い場所です。 90%未満の場合、実際に「自信を持って」結論を出すことができるというリスクがあります。
ここでの脅威は、サンプルサイズが本当に重要であるということです。 数日で98%の統計的有意性に達する可能性があり、文字通り合計16人のユーザーのみを調べていますが、これは明らかに信頼できるサンプルサイズではありません。
統計的有意性は、テストが最初に開始されたときに以前に参照したパフォーマンスのその巨大なスパイクをキャプチャすることもできます。 テストにはフリップフロップのすべての機能があり、時間の経過とともにデータが正常化することもわかっています。 したがって、統計的有意性の測定が早すぎると、その変更がより長期的にユーザーにどのように影響する可能性が高いかについて、完全に不正確な状況が生じる可能性があります。
さらに、すべてのテストで統計的有意性が得られるわけではありません。 行った変更の中には、通常の変動よりも大きく見えるほどユーザーの行動に強く影響しないものもあります。 そして、それは大丈夫です! つまり、ユーザーの注意をもう少し引くには、より大きな変更をテストする必要があるということです。
変数#4:データの一貫性
これは、そこにあるすべてのフリップフロップテストに出かけます。 正規化を拒否し、明確な勝者を提示することを拒否するいくつかのテストがあります。 彼らは勝者としてあなたに異なるバリエーションを提示するために毎日を費やし、彼らはあなたを絶対に狂わせるでしょう。
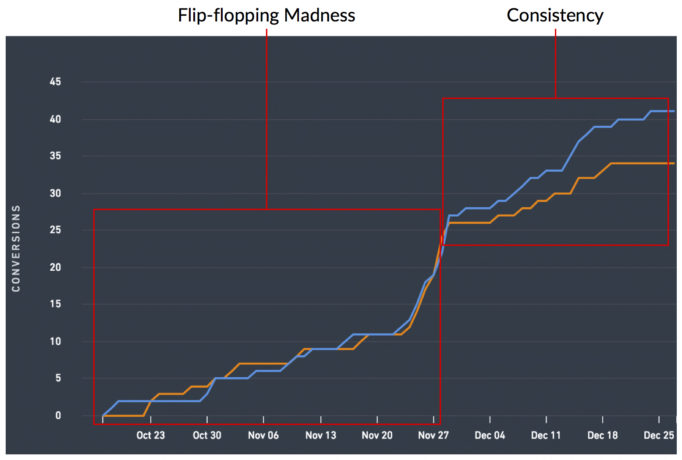
しかし、それらは存在し、一貫したデータの方向性を探すことが非常に重要である理由です。 あなたが勝者と宣言しているバリエーションは常に勝者でしたか? そうでなければ、なぜそれが常に勝者ではなかったのですか? 「なぜ」に自信を持って答えられないのなら。 次に、勝者としてパレードするバリエーションを実装すると、勝者を実装すると収益が損なわれる可能性があります。
また、コントロールの変換率とバリエーションの変換率(別名「リフト」または「ドロップ」)の差を測定します。 テストが最初のスパイクフェーズから外れていることを確認できるように、このメトリックも一貫していることを確認します。
統計的有意性を定期的に計算して、このメトリックがどの程度一貫しているかを確認することも有益です。
最終的な考え
あらゆる種類のテストを終了することは冗談ではなく、プレッシャーに満ちています。 間違った電話をかけ、データが別の方法で示している間に「感じた」ものを実装すると、収益とユーザーが苦しむことになります。
実行可能なあらゆる角度から結論にアプローチして、データに基づいた真に自信のある結論を確実に得られるようにします。