
ウィキペディア Web スクレイピング 2023: 分析のためのデータの抽出
公開: 2023-03-29オンライン スクレイピングを使用すると、価格比較、市場調査、広告検証などの目的で Web サイトからオープン データを収集できます。
通常、必要な公開データは大量に抽出されますが、封鎖に直面すると、抽出が困難になる可能性があります。
制限は、レート ブロッキングまたは IP ブロッキングのいずれかです (要求の IP アドレスは、禁止されたエリアや禁止された種類の IP などから発信されているため、制限されます)。 (複数のリクエストを行ったため、IP アドレスはブロックされています)。

有用な知識や情報をスクレイピングしたい場合は、大量の情報が掲載されている知識の百科事典であるウィキペディアをスクレイピングすることを検討したに違いありません。
ウィキペディアの Web スクレイピングについていくつか理解しましょう。
目次
ウィキペディアの Web スクレイピング
Web スクレイピングは、インターネットからデータを収集する自動化された方法です。 この記事では、Web スクレイピング、Web クローリングとの比較、および Web スクレイピングを支持する議論についての詳細な情報を提供します。
目的は、さまざまな Web スクレイピング手法を使用してウィキペディアのホームページからデータを収集し、それを解析することです。
さまざまな Web スクレイピング方法、Python Web スクレイピング ライブラリ、およびデータの抽出と処理の手順に慣れることができます。
Web スクレイピングと Python
Webスクレイピングは基本的に、プログラミング言語で作成されたソフトウェアを使用して多数のWebサイトから大量のデータから構造化データを抽出し、できればExcelシート、JSON、またはスプレッドシートでデバイスにローカルに保存するプロセスです.
これは、プログラマーが小規模プロジェクトと大規模プロジェクトの両方で論理的でわかりやすいコードを作成するのに役立ちます。
Python は主に、Web スクレイピングに最適な言語と見なされています。 Web クローリング関連のタスクの大部分を効果的に処理でき、より万能です。
ウィキペディアからデータをスクレイピングするには?
データは、さまざまな方法で Web ページから抽出できます。
たとえば、Python などのコンピューター言語を使用して自分で実装できます。 ただし、技術に精通していない限り、このプロセスで多くのことができるようになる前に、多くのことを勉強する必要があります.
また、ウィキペディアのページを手動でくまなく調べるのと同じくらい時間がかかります。 さらに、オンラインで無料の Web スクレイパーにアクセスできます。 しかし、彼らはしばしば信頼性に欠けており、サプライヤーは怪しげな意図を持っている可能性があります.
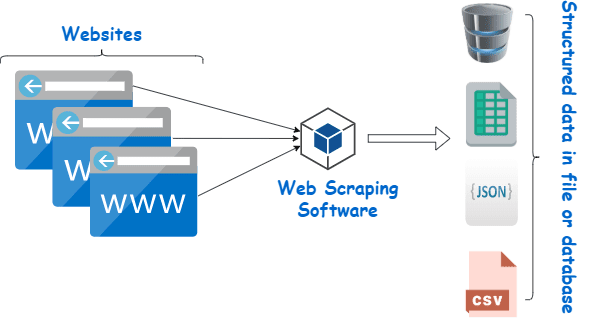
評判の良いサプライヤーのまともな Web スクレイパーに投資することが、Wiki データを収集するための最良の方法です。
次のステップは、プロバイダーがスクレーパーのインストール方法と使用方法に関する指示を提供するため、通常は単純で複雑ではありません.
プロキシは、Wiki スクレイパーと組み合わせて使用することで、より効果的にデータをスクレイピングできるツールです。 Scrapy、Scraping Robot、Beautiful Soup などの Python ベースのフレームワークは、この言語を使用して簡単にスクレイピングできることを示すほんの一例です。
ウィキペディアからデータをスクレイプするためのプロキシ
データを効果的にスクレイピングするには、非常に高速で安全に使用でき、必要なときにダウンしないことが保証されているプロキシが必要です。 このようなプロキシは、合理的な価格で Rayobyte から入手できます。
ユーザーごとに好みやユースケースが異なることを認識しているため、さまざまなプロキシを提供するよう努めています。
ウィキペディアの Web スクレイピング用のローテーション プロキシ
プロキシのインスタンスは、IP アドレスを定期的にローテーションするものです。 また、中断を防ぐために、禁止が発生するとすぐにIPアドレスが変更されます。 これにより、この特定のプロキシはサイトのスクレイピングに最適です。
対照的に、静的プロキシには 1 つの IP アドレスしかありません。 ISP が自動置換を有効にしていない場合、アクセスできる IP アドレスが 1 つしかなく、それがブロックされると、壁に突き当たります。 このため、静的プロキシは Web スクレイピングに最適なオプションではありません。
Wiki データを Web スクレイピングするためのレジデンシャル プロキシ
レジデンシャル プロキシは、インターネット サービス プロバイダー (ISP) が配布し、特定の世帯に関連付けられているプロキシ IP アドレスです。 それらは実在の人物からのものであるため、取得するのは非常に困難です。 その結果、それらは希少であり、比較的高価です。


住宅用プロキシを使用してデータをスクレイピングすると、実際の個人のアドレスにリンクされているため、日常のユーザーのように見えます.
そのため、レジデンシャル プロキシを使用すると、発見されてブロックされる可能性が大幅に減少します。 したがって、これらはデータスクレイピングの優れた候補です。
ウィキ データを収集するための住宅用プロキシのローテーション
先ほど説明した 2 つのタイプを組み合わせたローテーション レジデンシャル プロキシは、Wikipedia の Web スクレイピングに最適なプロキシです。
頻繁にローテーションするプロキシを使用して、多数のホーム IP にアクセスできます。
これは非常に重要です。なぜなら、住宅用プロキシを特定することは困難ですが、それらが生成する大量のリクエストは、最終的にスクレイピングされた Web サイトの注意を引くことになるからです。
ローテーションにより、IP アドレスがやむを得ずブラックリストに登録された場合でも、プロジェクトを続行できます。
そのため、複数のデータセンター プロキシを使用する場合でも、少数の住宅用プロキシに投資する場合でも、必要なものが揃っています。
1 GBS の速度で動作するプロキシ、無制限の帯域幅、24 時間体制のカスタマー サポートにより、最高の Web スクレイピング エクスペリエンスをお楽しみいただけます。
あなたも読むかもしれません
- 最高のWebスクレイピングテクニック:実践ガイド
- Octoparse レビュー それは本当に良い Web スクレイピング ツールですか?
- 最高の Web スクレイピング ツール
- Webスクレイピングとは? - どのように使われるのか? ビジネスにどのように役立つか
ウィキペディアをスクレイピングする必要があるのはなぜですか?
ウィキペディアは、現在オンラインの世界で最も信頼され、情報が豊富なサービスの 1 つです。 このプラットフォームで考えられるほぼすべての種類のトピックに対する回答と情報があります。
したがって、当然のことながら、ウィキペディアはデータをスクレイピングするための優れた情報源です。 ウィキペディアをスクレイピングする必要がある主な理由について説明しましょう。
学術研究のための Web スクレイピング
データ収集は、研究に関わる最も骨の折れる作業の 1 つです。 すでに説明したように、Web スクレイパーを使用すると、この手順がより迅速かつ簡単になり、時間と労力を大幅に節約できます。
Web スクレイパーを使用すると、多数の Wiki ページをすばやくスキャンして、必要なすべてのデータを整理された方法で収集できます。
ここで、うつ病と日光への曝露が国によって異なるかどうかを判断することが目標であると仮定します。
ウィキペディアの多数のエントリを調べなくても、ウィキ スクレーパーを使用して、さまざまな国でのうつ病の蔓延や晴れた時間などの情報を見つけることができます。
評判管理
ウィキペディアの投稿は Google の最初のページに頻繁に表示されるため、ウィキペディアのページを作成することは、現代のさまざまな種類のビジネスにとって必須のマーケティング戦略となっています。
しかし、ウィキペディアにページを掲載したからといって、マーケティング活動が終了するわけではありません。 ウィキペディアはクラウドソースのプラットフォームであるため、荒らしはかなり頻繁に発生します。
その結果、誰かがあなたの会社のページに不利な情報を追加し、あなたの評判を損なう可能性があります。 または、関連する Wiki 記事であなたのビジネスを中傷する可能性があります。
このため、Wiki ページや、作成されたビジネスについて言及している他のページに注意を払う必要があります。 これは、Wiki スクレーパーを使用して簡単に行うことができます。
ウィキペディアのページを定期的に検索して、あなたのビジネスへの言及を探し、そこにある破壊行為の事例を指摘することができます。
ブーストSEO
ウィキペディアを利用して、ウェブサイトへのトラフィックを増やすことができます。
Wiki データ スクレーパーを使用して、ビジネスとターゲット ユーザーに関連するページを見つけ、変更したい記事のリストを作成します。
記事を読むことから始めて、サイトへの貢献者としての信頼を得るために役立つ調整をいくつか行ってください。
ある程度の信頼性を確立したら、リンクが切れている場所や引用が必要な場所に Web サイトへの接続を追加できます。
クイックリンク
- 最高のフランスのプロキシ
- トップベストSpotifyプロキシ
- 最高のナイキプロキシ
Web スクレイピングに使用される Python ライブラリ
すでに述べたように、Python は世界で最も人気があり評判の良いプログラミング言語であり、Web スクレイピング ツールです。 では、現在利用可能な Python Web スクレイピング ライブラリを見てみましょう。
Requests (HTTP for Humans) Web スクレイピング用ライブラリ
GET や POST など、さまざまな HTTP 要求を送信するために使用されます。 すべてのライブラリの中で、これは最も基本的であるだけでなく、最も重要でもあります。
Web スクレイピング用の lxml ライブラリ
Web サイトからの HTML および XML テキストの非常に高速で高性能な解析は、lxml パッケージによって提供されます。 巨大なデータベースをスクレイピングする場合は、これを選択してください。
Web スクレイピング用の美しいスープ ライブラリ
その作業は、コンテンツを解析するための解析ツリーを構築することです。 初心者が始めるのに最適な場所であり、非常にユーザーフレンドリーです。
Web スクレイピング用の Selenium ライブラリ
このライブラリは、上記のすべてのライブラリが抱える問題、つまり、動的に入力された Web ページからコンテンツをスクレイピングするという問題を解決します。
もともとは、Web アプリケーションの自動テスト用に設計されました。 このため、速度が遅く、産業レベルでのタスクには適していません。
Scrapy for Web スクレイピング
非同期使用を使用する完全な Web スクレイピング フレームワークは、すべてのパッケージの BOSS です。 これにより、効率が向上し、非常に高速になります。
結論
以上が、ウィキペディアの Web スクレイピングについて知っておくべき最も重要な側面でした。 Web スクレイピングに関する有益な投稿や、その他多数の情報をお届けしますので、お見逃しなく!
クイックリンク
- 旅行運賃の集計に最適なプロキシ
- 最高のフランスのプロキシ
- 最高のトリップアドバイザー プロキシ
- 最高の Etsy プロキシ
- IPRoyalクーポンコード
- 最高のTikTokプロキシ