
1 年間の SEO ケース スタディ: Googlebot について知っておくべきこと
公開: 2019-08-30編集者注: JetOctopus クローラーの CEO、Serge Bezborodov が、Googlebot にとって魅力的な Web サイトにする方法について、専門的なアドバイスを提供します。 この記事のデータは、1 年間の調査と 3 億のクロールされたページに基づいています。
数年前、私は 500 万ページの求人情報サイトのトラフィックを増やそうとしていました。 トラフィックが屋根を通り抜けることを期待して、SEO 代理店サービスを利用することにしました。 しかし、私は間違っていました。 包括的な監査の代わりに、タロットカードを読んでもらいました. そのため、私は振り出しに戻り、包括的なオンページ SEO 分析用の Web クローラーを作成しました。
私は 1 年以上にわたって Googlebot をスパイしてきましたが、その行動についての洞察を共有する準備が整いました。 私の観察は、少なくとも Web クローラーがどのように機能するかを明確にし、せいぜいページ上の最適化を効率的に行うのに役立つと期待しています。 新しい Web サイトまたは数千ページの Web サイトに役立つ、最も意味のあるデータを収集しました。
あなたのページはSERPに表示されていますか?
どのページが検索結果に含まれているかを確実に知るには、Web サイト全体のインデックス可能性を確認する必要があります。 ただし、1,000 万ページを超える Web サイトの各 URL を分析すると、新車と同じくらいの費用がかかります。
代わりにログ ファイル分析を使用しましょう。 検索ボットと同じようにウェブページをクロールし、半年分収集したログファイルを分析します。 ログには、ボットが Web サイトにアクセスしたかどうか、クロールされたページ、およびボットがページにアクセスした日時と頻度が表示されます。
クロールとは、検索ボットが Web サイトにアクセスし、Web ページ上のすべてのリンクを処理し、これらのリンクをインデックス化のために並べるプロセスです。 クロール中、ボットは処理されたばかりの URL を既にインデックスにある URL と比較します。 したがって、ボットはデータを更新し、検索エンジン データベースからいくつかの URL を追加/削除して、ユーザーに最も関連性の高い最新の結果を提供します。
これで、これらの結論を簡単に導き出すことができます。
- 検索ボットが URL にない限り、この URL はおそらくインデックスに含まれません。
- Googlebot が 1 日に数回 URL にアクセスする場合、その URL は優先度が高いため、特別な注意が必要です。
全体として、この情報は、あなたのウェブサイトの有機的な成長と発展を妨げているものを明らかにします. これで、やみくもに操作する代わりに、チームは Web サイトを賢く最適化できます。
ウェブサイトが小さい場合、Googlebot は遅かれ早かれすべてのウェブページをクロールするため、私たちは主に大規模なウェブサイトを扱っています。
逆に、100,000 以上のページを持つ Web サイトでは、Web マスターには見えないページにクローラーがアクセスすると、問題に直面します。 これらの無用または有害なページで、貴重なクロール バジェットが浪費される可能性があります。 同時に、ウェブサイトの構造が混乱しているため、ボットが収益性の高いページを見つけられない可能性があります.
クロール バジェットは、Googlebot がウェブサイトで使用できる限られたリソースです。 何をいつ分析するかを優先するために作成されました。 クロール バジェットのサイズは、Web サイトのサイズ、構造、ユーザーのクエリの量と頻度など、多くの要因によって異なります。
検索ボットは、Web サイトを完全にクロールすることには関心がないことに注意してください。
検索エンジン ボットの主な目的は、リソースの損失を最小限に抑えて、最も関連性の高い回答をユーザーに提供することです。ボットは、主な目的に必要なだけのデータをクロールします。 したがって、ボットが最も有益で収益性の高いコンテンツを選択できるようにするのはあなたの仕事です。
Googlebot のスパイ
昨年、大規模な Web サイトで 3 億を超える URL と 60 億のログ行をスキャンしました。 このデータに基づいて、Googlebot の行動を追跡し、次の質問に答えました。
- どのタイプのページが無視されますか?
- 頻繁にアクセスされるページは?
- ボットの注目すべき点は何ですか?
- 価値のないものは何ですか?
以下は私たちの分析と調査結果であり、Google Webmasters Guidelines を書き直したものではありません。 実際、証明されていない不当な推奨事項はありません。 各ポイントは、便宜上、事実に基づく統計とグラフに基づいています。
では、本題に入って調べてみましょう。
- Googlebot にとって本当に重要なことは何ですか?
- ボットがページにアクセスするかどうかを決定するものは何ですか?
次の要因を特定しました。
インデックスからの距離
DFI は Distance From Index の略で、URL からメイン/ルート/インデックス URL までのクリック数です。 これは、Googlebot のアクセス頻度に影響を与える最も重要な基準の 1 つです。 DFI の詳細については、こちらの教育ビデオをご覧ください。
DFI は、たとえば次のような URL ディレクトリ内のスラッシュの数ではないことに注意してください。
site.com/shop/iphone/iphoneX.html – DFI– 3__ _
したがって、DFI はメイン ページからの CLICKS によって正確にカウントされます。
https://site.com/shop/iphone/iphoneX.html
https://site.com iPhone カタログ → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
以下は、Googlebot の DFI を含む URL への関心が、先月と過去 6 か月間で徐々に減少していることを示しています。
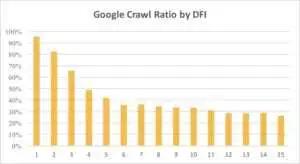
ご覧のとおり、DFI が 5 t0 6 の場合、Googlebot はウェブページの半分しかクロールしません。 また、DFI が大きいほど、処理されたページの割合は減少します。 表中の指標は1800万ページ分統一。 データは、特定の Web サイトのニッチによって異なる場合があることに注意してください。
何をすべきか?
この場合の最善の戦略は、5 を超える DFI を避けること、ナビゲートしやすい Web サイト構造を構築すること、リンクに特別な注意を払うことなどであることは明らかです。
真実は、これらの対策は、100,000 ページを超える Web サイトでは非常に時間がかかるということです。 通常、大規模な Web サイトには、再設計と移行の長い歴史があります。 そのため、Web マスターは DFI が 10、12、さらには 30 のページを削除するべきではありません。また、頻繁にアクセスするページから 1 つのリンクを挿入しても問題は解決しません。
長い DFI に対処する最適な方法は、これらの URL が関連性があり、収益性があるかどうか、SERP での位置を確認して推定することです。
DFI が長いが、SERP での順位が高いページは、高い可能性を秘めています。 高品質のページでトラフィックを増やすには、ウェブマスターは次のページからのリンクを挿入する必要があります。 具体的な進歩には、1 つまたは 2 つのリンクでは不十分です。
下のグラフから、ページに 10 個を超えるリンクがある場合、Googlebot がより頻繁に URL にアクセスすることがわかります。
リンク
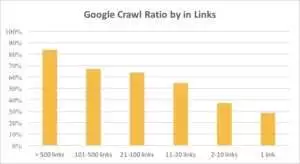
実際、ウェブサイトが大きくなればなるほど、ウェブページ上のリンクの数はより重要になります。 このデータは、実際には 100 万ページを超える Web サイトからのものです。

収益性の高いページに 10 個未満のリンクしかないことに気付いた場合でも、慌てる必要はありません。 まず、これらのページが高品質で収益性が高いかどうかを確認します。 その際は、各ステップの後にログを分析して、急いで短い繰り返しで高品質のページにリンクを挿入します。
コンテンツサイズ
コンテンツは、SEO 分析の最も一般的な側面の 1 つです。 もちろん、関連性の高いコンテンツが Web サイトにあるほど、クロール率は高くなります。 以下は、500 語未満のページで Googlebot の関心が劇的に低下する様子を示しています。
何をすべきか?
私の経験によると、 500 ワード未満のページの半分近くがゴミページです。 服のサイズだけが掲載されたページが 70,000 ページもある Web サイトがあったため、これらのページの一部のみがインデックスに登録されていました。
したがって、まずそれらのページが本当に必要かどうかを確認してください。 これらの URL が重要な場合は、関連するコンテンツを追加する必要があります。 追加するものが何もない場合は、リラックスしてこれらの URL をそのままにしておいてください。 役に立たないコンテンツを公開するよりも、何もしない方がよい場合もあります。
その他の要因
次の要因は、クロール率に大きな影響を与える可能性があります。
読み込み時間
Web ページの速度は、クロールとランキングにとって非常に重要です。 ボットは人間のようなものです。Web ページが読み込まれるのを長時間待つことを嫌います。 Web サイトに 100 万を超えるページがある場合、検索ボットは、5 秒で読み込まれる 1 つのページを待つのではなく、1 秒の読み込み時間で 5 つのページをダウンロードする可能性があります。
何をすべきか?
実際、これは技術的な作業であり、より大きなサーバーを使用するなどの「1 つの方法ですべてに対応できる」ソリューションはありません。 主なアイデアは、問題のボトルネックを見つけることです。 Web ページの読み込みが遅い理由を理解する必要があります。 理由が明らかになった後でのみ、行動を起こすことができます。
独自コンテンツとテンプレート化コンテンツの比率
一意のデータとテンプレート化されたデータのバランスが重要です。 たとえば、ペットの名前のバリエーションを持つ Web サイトがあるとします。 このトピックに関して、どれだけ関連性のある独自のコンテンツを実際に収集できますか?
ルナは最も人気のある「有名人」の犬の名前で、ステラ、ジャック、マイロ、レオがそれに続きました。
検索ボットは、この種のページにリソースを費やすことを好みません。
何をすべきか?
バランスを保つ。 ユーザーとボットは、複雑なテンプレート、大量の外部リンク、およびコンテンツの少ないページにアクセスすることを好みません。
孤立したページ
孤立したページは、Web サイトの構造に含まれていない URL であり、これらのページについてはわかりませんが、これらの孤立したページはボットによってクロールされる可能性があります。 明確にするために、下の図のオイラーの円を見てください。

しばらく構造が変わっていない、若いウェブサイトの通常の状況を見ることができます。 あなたとクローラーが分析できるページは 900,000 ページあります。 約 500,000 ページがクローラーによって処理されますが、Google では不明です。 この 500,000 の URL をインデックス可能にすれば、トラフィックは確実に増加します。
注意: 若い Web サイトでも、Web サイトの構造には含まれていないがボットが定期的にアクセスするページ (図の青い部分) が含まれています。
また、これらのページには、不要な自動生成された訪問者のクエリなどの不要なコンテンツが含まれている可能性があります。
しかし、大規模な Web サイトがそれほど正確であることはめったにありません。 多くの場合、履歴のある Web サイトは次のようになります。

もう 1 つの問題は、Google があなたよりもあなたの Web サイトについてよく知っていることです。 削除されたページ、JavaScript または Ajax 上のページ、壊れたリダイレクトなどがある可能性があります。 プログラマーのミスにより、サイトマップに 500,000 個の壊れたリンクのリストが表示されるという状況に直面したことがあります。 3 日後、バグが見つかり修正されましたが、Googlebot はこれらの壊れたリンクに半年間アクセスしていました。
多くの場合、これらの孤立したページでクロール バジェットが浪費されます。
何をすべきか?
この潜在的な問題を修正するには 2 つの方法があります。 ウェブサイトの構造を整理し、内部リンクを正しく挿入し、インデックスされたページからのリンクを追加して孤立したページを DFI に追加し、プログラマーのタスクを設定して、次の Googlebot の訪問を待ちます。
2 番目の方法は迅速です。孤立したページのリストを収集し、関連性があるかどうかを確認します。 答えが「はい」の場合は、これらの URL を使用してサイトマップを作成し、Google に送信してください。 この方法は簡単で高速ですが、孤立したページの半分だけがインデックスに含まれます。
次のレベル
検索エンジンのアルゴリズムは 20 年間にわたって改善されてきましたが、検索のクロールがいくつかのグラフで説明できると考えるのは単純です。
ページごとに 200 を超えるさまざまなパラメーターを収集しており、年末までにこの数が増えると予想しています。 Web サイトが 100 万行 (ページ) のテーブルであり、これらの行に 200 列を掛けると想像してください。単純なサンプルでは、包括的で技術的な監査には不十分です。 同意しますか?
私たちはさらに深く掘り下げることにし、機械学習を使用して、それぞれのケースで Googlebot のクロールに影響を与えるものを見つけました。

1 つは Web サイトのリンクが重要であり、もう 1 つはコンテンツが重要な要素です。
このタスクの主なポイントは、複雑で大量のデータから簡単に答えを得ることでした: あなたのウェブサイトでインデックス化に最も影響を与えるものは何ですか? 同じ要素に関連付けられている URL のクラスターはどれですか? それらを包括的に扱うことができるように。
HotWork アグリゲーターの Web サイトでログをダウンロードして分析する前は、ボットには表示されるが、私たちには表示されない孤立したページに関する話は、私には非現実的に思えました。 しかし、実際の状況にはさらに驚かされました。Crawl は 301 リダイレクトで 500 ページを表示しましたが、Yandex は同じステータス コードで 700,000 ページを検出しました。
通常、技術マニアはログ ファイルを保存することを好みません。このデータはディスクを「過負荷」にするからです。 しかし、客観的に見て、1 か月あたり最大 1,000 万回のアクセスがあるほとんどの Web サイトでは、ログ保存の基本設定は完全に機能しています。
ログの量について言えば、最善の解決策は、アーカイブを作成して Amazon S3-Glacier にダウンロードすることです (わずか 1 ドルで 250 GB のデータを保存できます)。 システム管理者にとって、このタスクはコーヒーを淹れるのと同じくらい簡単です。 今後、履歴ログは、技術的なバグを明らかにし、Google の更新が Web サイトに与える影響を見積もるのに役立ちます。