
Apache Apex – 소개
게시 됨: 2015-12-29Apache Hadoop은 안정적이고 확장 가능하며 분산된 대규모 컴퓨팅을 위한 사실상의 소프트웨어 프레임워크가 되었습니다. 처음부터 Hadoop은 일괄 처리를 위한 첫 번째 선택 프레임워크였습니다. 대형 은행에서 온라인 소매 대기업에 이르기까지 모든 사람들이 정기적인 보고서 생성, 계산 및 더 많은 사용 사례에 Hadoop을 사용하고 있습니다. 일반적으로 이러한 사용 사례는 배치 지향 프로세스이며 데이터에서 의미를 얻기까지 몇 시간이 걸립니다. 오늘날의 급변하는 세상은 원시 데이터가 생성되는 거의 그 시점에 원시 데이터의 의미 또는 조치를 요구합니다. 이것은 스트림 처리의 개념으로 이어졌습니다. Hadoop은 원래 스트림 처리에 적합하지 않은 것으로 간주되었지만 YARN(Hadoop 2.0)의 발명으로 인해 Hadoop이 좋은 후보가 되었습니다. 현재 Hadoop 생태계에는 여러 스트림 처리 프레임워크가 있으며 Apex는 이 혼잡한 시장에 진입한 새로운 것입니다.
Apache Apex란 무엇입니까?
Apache Apex는 애플리케이션 개발자가 스트림 지향 및 배치 지향 애플리케이션을 작성하는 데 도움이 되는 기본 YARN 기반 플랫폼입니다. 이동 중인 데이터를 분산, 고성능, 내결함성 방식으로 처리하도록 설계되었습니다. 이것에 대한 Icing은 사용자가 스트림 처리에 대한 제한된 지식으로 Java 코드를 작성할 수 있도록 하는 쉬운 API입니다.
Apex는 별도의 기능 및 작동 사양을 기반으로 합니다. 따라서 애플리케이션 개발자는 분산 환경에서 어떻게 작동할지 생각할 필요 없이 사용자 정의 함수를 작성하는 데 집중할 수 있습니다.
Apache Apex에는 일반적으로 사용되는 풍부한 기능 라이브러리가 있습니다. 이들은 Apache Apex-Malhar 라이브러리의 일부로 추가됩니다. 이 라이브러리에는 다양한 파일 시스템, 데이터베이스, 메시지 대기열에 액세스하는 연산자가 있습니다. 커뮤니티는 응용 프로그램 개발자의 삶을 더 쉽게 만들어주는 운영자의 일상을 추가하고 있습니다.
Apache Apex의 핵심 블록은 무엇입니까?
Apex의 아키텍처는 매우 간단합니다. Apex에는 작업할 운영자 라이브러리 및 핵심 엔진인 Malhar가 있습니다. Apex의 핵심은 다음과 같이 나타낼 수 있으며 종종 Apache Apex의 주요 블록이라고 합니다.
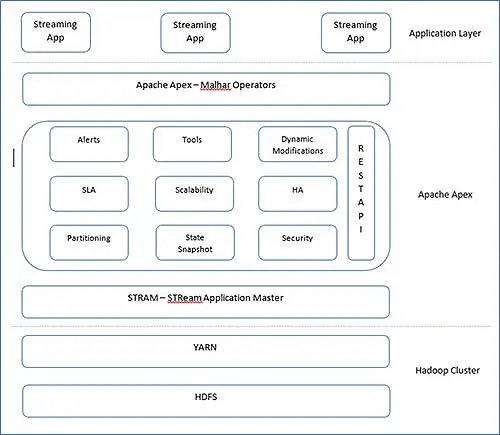
레이어를 명확하게 구분할 수 있고 어디에 맞는 개요를 얻을 수 있습니다. 이 블록에 대한 정보를 살펴보겠습니다.
- StrAM ( 스트림 A 애플리케이션 마스터)
StrAM은 YARN 애플리케이션 마스터입니다. 그 책임에는 스트림 애플리케이션 시작, 리소스 할당, 논리적 DAG 스케줄링이 포함됩니다. 이러한 YARN 작업과 함께 StrAM은 연산자인 스트림을 초기화합니다. StrAM은 또한 자식으로부터 통계를 수집합니다. - 상태 스냅샷
스트림 처리 프레임워크는 처리된 결과를 잃을 수 없습니다. 또한 장애 복구 후 기록을 올바르게 처리하기 위해서는 처리량을 알아야 합니다. 따라서 주기적으로 검사 포인팅은 스트림 처리에서 중요합니다. Apex에서 StrAM은 체크 포인팅을 추적하고 운영자 경계에서 HDFS에서 주기적으로 체크 포인팅이 수행됩니다. - REST API
StrAM은 REST API에 대한 액세스 포인트입니다. 외부 도구는 이 REST API에 액세스할 수 있으며 모든 외부 응용 프로그램과 통합할 수 있습니다. - 도구
Apex는 Apex 애플리케이션을 시작하고 모니터링하기 위한 CLI를 제공합니다. REST API를 사용하여 자체적으로 빌드할 수도 있습니다. CLI와 함께 애플리케이션은 자동 실행을 위한 정적 구성 스크립트로 구성할 수 있습니다. - 파티셔닝
- 동적 수정
- SLA 분석
Apache Apex는 자체적으로 주기적으로 SLA 분석을 수행합니다. 대기 시간, 병목 현상 및 처리량 분석을 수행하고 구성된 SLA를 충족하기 위해 더 많은 리소스를 추가합니다. - 보안
- 고가용성
Apache Apex는 YARN의 다시 시작 기능을 활용하고 마지막 체크 포인트 상태에서 다시 시작합니다. - 말하르
Apache Apex –Malhar는 수많은 운영자가 있는 운영자 라이브러리입니다. 이러한 연산자는 다음과 같이 분류됩니다. - 입력/출력 연산자 –
이 범주에서 현재 Malhar에는 읽기/쓰기 연산자가 있습니다. - 파일 시스템
- RDBMS
- NoSQL 스토어
- 메시지 대기열
- 인메모리 데이터베이스
- 소셜 미디어
- 계산 연산자 –
- 패턴 매칭
- 통계 및 수학
- 기계 학습
- 파서
- 소셜 미디어
- 버퍼 서버
Apex는 키 및 동적 로드 밸런싱을 기반으로 파티셔닝을 제공합니다. 사용자도 자신의 파티션 구성표를 정의할 수 있습니다.
Apache Apex에는 이 매우 유용하고 고유한 기능이 있습니다. 논리적 DAG 변경, 물리적 실행 계획 변경을 지원합니다.
Apex는 Kerberos를 지원합니다. 보안 Hadoop 클러스터를 기반으로 고유한 Kerberos 통합으로 액세스할 수 있습니다.
Malhar에는 실제 비즈니스 논리 구현에 도움이 되는 많은 연산자가 있습니다. 이 라이브러리에는
버퍼 서버는 각 운영자 경계에 있습니다. 데이터의 경우 로컬 연산자 버퍼 서버는 연산자 문자열 뒤에 올 수 있습니다. 주요 목적은 다음으로 전달하기 전에 가장자리에서 데이터를 임시로 유지하는 것입니다. 노드가 장애에서 복구될 때 중요한 역할을 합니다. 버퍼 서버는 마지막 체크 포인트 상태에서 데이터를 로드하여 재생합니다.
Apex 애플리케이션 프로그래밍 모델이란 무엇입니까?
여기에는 풍부한 프레임워크와 Malhar 라이브러리가 포함되어 있어 애플리케이션 개발자가 운영자를 연결하고 애플리케이션을 실행하기만 하면 됩니다. 따라서 응용 프로그램은 일련의 연산자에 불과합니다.

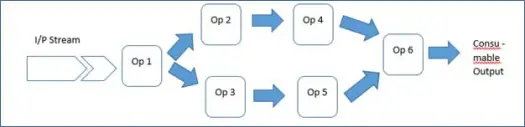
이것이 바로 풍부한 프레임워크가 개발자의 삶을 쉽게 만드는 방법입니다. 이 데모 애플리케이션이 어떻게 실행되는지 봅시다
아파치 에이펙스 데모
Apache Apex를 사용한 단어 수의 작은 데모인 ' Hello World of Big Data J '부터 시작하겠습니다.
Apache Apex 설정
이 데모를 실행하려면 Apex를 구성해야 합니다. 기존 클러스터에 Apache Apex를 설치하거나 시험해 볼 수 있는 간단한 방법이 있습니다. 여기에서 DataTorrent 웹 사이트에서 사전 설치 샌드박스 VM을 다운로드할 수 있습니다. 이 데모에서는 사전 설치된 VM을 사용합니다.
연습 Apex UI 콘솔
Apex는 응용 프로그램을 시작, 모니터링 및 관리하는 데 사용할 수 있는 매우 직관적이고 아름답게 디자인된 UI 콘솔과 함께 제공됩니다. 여기에는 배포된 다양한 구성 요소에 대한 다양한 통계가 포함됩니다.
그런 다음 샌드박스 VM을 다운로드하고 압축을 풀고 좋아하는 VM 플레이어에 로드합니다(저는 VMWare VM 플레이어를 사용합니다). Apex를 실행하는 데 필요한 모든 소프트웨어와 도구는 이미 이 VM에 구성되어 있으며 모든 시작 스크립트는 OS 부팅 시 실행되도록 구성되어 있습니다. 따라서 VM이 가동되면 Apache Apex 인스턴스를 실행하게 됩니다. 이제 콘솔을 보려면 즐겨 사용하는 웹 브라우저에서 http://locahost:9090을 누르고 콘솔에 로그인하면 됩니다. 기본 사용자 이름: 샌드박스 VM의 비밀번호는 dtadmin: dtadmin입니다. 아래와 같이 콘솔이 보입니다.
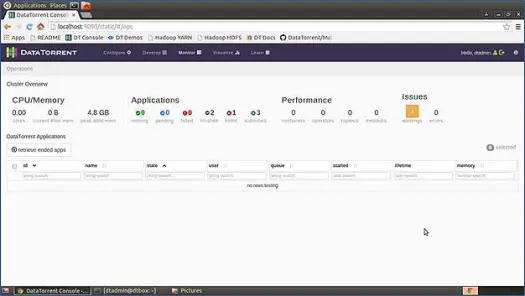
이 페이지는 CPU 및 메모리 사용량, 응용 프로그램, 성능, 문제 등과 같은 모든 시스템에 대한 완전한 개요를 제공합니다.
애플리케이션을 배포하려면 페이지 상단의 개발 탭으로 이동합니다.
여기에서 애플리케이션 패키지를 배포하고 Apex 내부 데이터에 대한 튜플 스키마를 관리할 수 있습니다.
Apex는 즉시 사용할 수 있는 여러 응용 프로그램을 제공하며 아래에 나열된 것을 볼 수 있습니다.
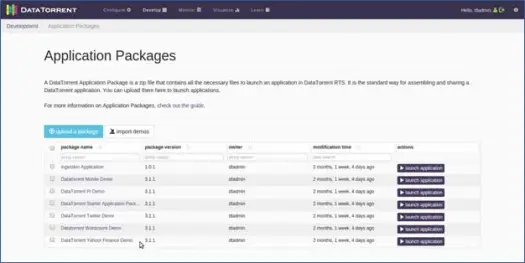
WordCount 데모
이제 wordcount 애플리케이션을 실행해 보겠습니다. DataTorrent Wordcount Demo 옆에 있는 시작 애플리케이션 옵션을 클릭하면 됩니다. 다음으로 필요한 경우 애플리케이션에 다른 정보를 제공하고 구성 세부 정보를 수정할 수 있습니다(대부분의 기본값이 제대로 작동하므로 그렇게 하지 않겠습니다. 앱 이름을 "MyWordCountDemo"로 수정하겠습니다). 응용 프로그램에 대한 링크와 함께 응용 프로그램이 성공적으로 배포되었다는 메시지가 표시됩니다. 해당 링크를 클릭하십시오.

새 페이지가 열립니다. 응용 프로그램 상태가 수락됨에서 실행 중으로 변경될 때까지 몇 초 동안 기다립니다. 이제 다양한 통계 및 정보로 가득 찬 페이지가 표시됩니다. 다음 두 스크린샷은 그들을 묘사합니다.
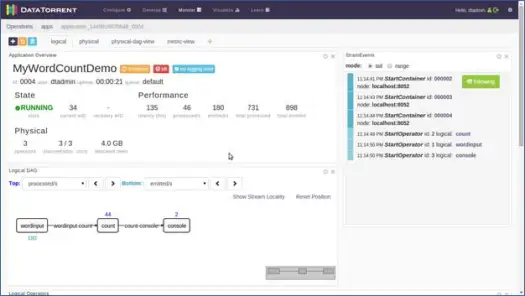
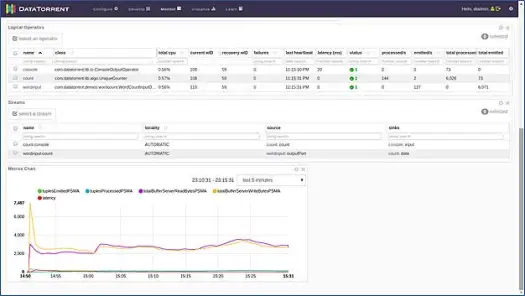
이 페이지는 애플리케이션에 의해 초당 처리되는 다양한 튜플/레코드의 통계와 함께 애플리케이션의 논리적, 물리적 및 메트릭 뷰와 같은 다양한 정보를 보여줍니다. 방출되는 튜플과 대기 시간 등의 그래픽 표현을 보여줍니다.
논리 연산자 중 하나를 클릭하고 해당 레코드를 검사하고 샘플을 기록할 수도 있습니다. 콘솔 운영자를 위해 그렇게 합시다. 콘솔 운영자를 클릭하면 아래와 같이 운영자에 대한 자세한 정보를 얻을 수 있습니다.
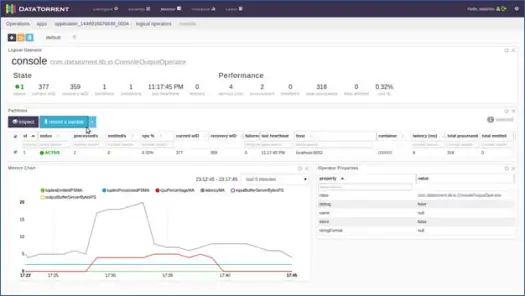
그런 다음 파티션 중 하나를 선택하고 샘플 기록을 클릭합니다.
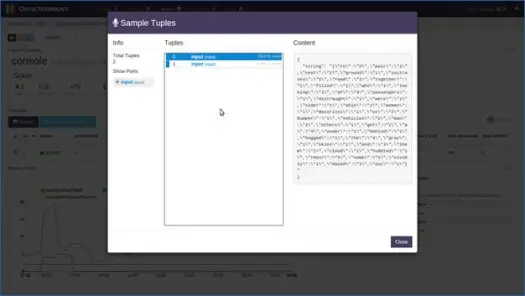
몇 초 후에 튜플이 채워진 것을 볼 수 있습니다. 해당 내용을 보려면 튜플을 클릭하십시오. 내용에서 알 수 있듯이 응용 프로그램은 창을 기반으로 데이터에 대한 단어 수를 수행했으며 이 창의 0번째 입력 튜플에는 2개의 "to", 4개의 "the", 4개의 "a" 등이 있었습니다. 이제 응용 프로그램의 메인 페이지에서 "종료" 또는 "종료"를 클릭하여 응용 프로그램을 중지할 수 있습니다.
그게 다야, 우리는 성공적으로 wordcount 애플리케이션을 배포하고 실행했습니다.
결론
이것이 새로운 스트리밍 도구인 Apache Apex를 소개하고 Apache Apex에서 애플리케이션을 성공적으로 실행하는 것이었습니다. Apache Apex에는 후속 게시물에서 다루게 될 다른 기존 프레임워크보다 우위에 있는 많은 두드러진 기능이 있습니다.