
Apache Spark: 빅 데이터 창공의 빛나는 별.
게시 됨: 2015-09-24- 수백만 개의 제품을 올바른 고객에게 추천합니다.
- 검색 기록을 추적하고 항공편 여행에 대해 할인된 가격을 제공합니다.
- 사람의 기술 능력을 비교하고 당신의 분야에서 연결할 사람들을 적절하게 제안합니다.
- 수십억 개의 모바일 개체, 네트워크 타워 및 통화 트랜잭션의 패턴을 이해하고 통신 네트워크 최적화를 계산하거나 네트워크 허점을 찾습니다.
- 수백만 개의 센서 기능을 연구하고 센서 네트워크의 오류를 분석합니다.
위의 모든 작업에 대해 올바른 결과를 얻는 데 사용되는 기본 데이터는 비교적 매우 큽니다. 기존 시스템으로는 효율적으로(공간과 시간 면에서) 처리할 수 없습니다.
이는 모두 빅 데이터 시나리오입니다.
이러한 종류의 방대한 데이터를 수집, 저장 및 계산하려면 특수 클러스터 컴퓨팅 시스템이 필요합니다. Apache Hadoop 은 우리를 위해 이 문제를 해결했습니다.
분산 저장 시스템(HDFS) 과 병렬 컴퓨팅 플랫폼(MapReduce)을 제공합니다.
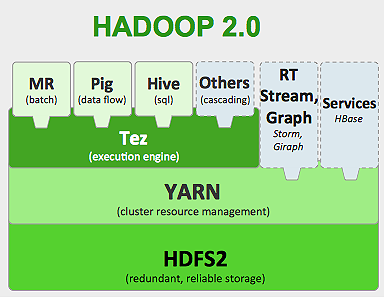
Hadoop 프레임워크 는 다음과 같이 작동합니다.
- 대용량 데이터 파일을 개별 시스템에서 처리할 수 있도록 더 작은 청크로 나눕니다(Distributing Storage).
- 더 긴 작업을 병렬 방식으로 실행할 더 작은 작업으로 나눕니다(병렬 계산).
- 실패를 자동으로 처리합니다.
하둡의 한계
Hadoop 은 생태계에 다양한 작업을 수행할 수 있는 전문 도구를 보유하고 있습니다. 따라서 애플리케이션의 전체 수명 주기를 실행하려면 여러 도구를 사용해야 합니다. 예를 들어 SQL 쿼리의 경우 hive/pig 스트리밍 소스의 경우 Hadoop 내장 스트리밍 또는 Apache Storm (하둡 에코시스템의 일부가 아님)을 사용해야 하거나 기계 학습 알고리즘의 경우 Mahout 을 사용해야 합니다. 단일 데이터 파이프라인 사용 사례를 구축하기 위해 이러한 모든 시스템을 통합하는 것은 상당한 작업입니다.
맵리듀스 작업에서
- 모든 맵 작업 출력은 로컬 디스크(또는 HDFS)에 덤프됩니다.
- Hadoop은 모든 스필 파일을 더 큰 파일로 병합하여 리듀서 수에 따라 정렬 및 분할합니다.
- 그리고 작업을 줄이려면 메모리에 다시 로드해야 합니다.
이 프로세스는 디스크 I/O 및 네트워크 I/O를 유발하여 작업을 느리게 만듭니다. 이것은 또한 Mapreduce를 동일한 데이터 그룹에 계속해서 기계 학습 알고리즘을 적용해야 하는 반복 처리에 적합하지 않게 만듭니다.
Apache Spark의 세계로 들어가십시오:
Apache Spark 는 2009년 UC Berkeley AMPLAB 에서 개발되었으며 2010년에는 현재까지 Apache 최고 기여 오픈 소스 프로젝트가 되었습니다.
Apache Spark 는 일괄 작업과 스트리밍 작업을 동시에 실행할 수 있는 보다 일반화된 시스템입니다. 메모리에서 데이터를 더 빠르게 처리하는 기능을 추가하여 속도 면에서 이전 MapReduce를 대체합니다. 디스크에서도 더 효율적입니다. 기본 데이터 단위인 RDD(Resilient Distributed Dataset)를 사용하여 메모리 처리에 활용합니다. 작업의 전체 수명 주기 동안 메모리에 가능한 한 많은 데이터 세트를 보유하므로 디스크 I/O가 절약됩니다. 일부 데이터는 메모리 상한선 이후에 디스크를 넘을 수 있습니다.
아래 그래프는 로지스틱 회귀 계산을 위한 Apache Hadoop 및 Spark의 실행 시간(초)을 보여줍니다. 하둡은 110초가 걸렸고 스파크는 0.9초 만에 동일한 작업을 완료했습니다.
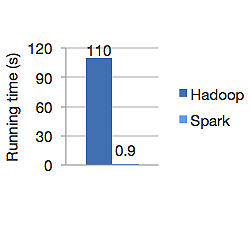
Spark는 모든 데이터를 메모리에 저장하지 않습니다. 그러나 데이터가 메모리에 있는 경우 LRU 캐시를 최대한 활용하여 더 빠르게 처리합니다. 메모리에서 데이터를 계산하는 동안 100배 빠르며 디스크에서는 여전히 Hadoop보다 빠릅니다.
Spark의 분산 데이터 스토리지 모델인 RDD(복원력 있는 분산 데이터 세트)는 내결함성을 보장하여 네트워크 I/O를 최소화합니다. 스파크 페이퍼는 다음과 같이 말합니다.

"RDD는 계보의 개념을 통해 내결함성을 달성합니다. RDD의 파티션이 손실된 경우 RDD는 해당 파티션만 다시 작성할 수 있도록 다른 RDD에서 파생된 방법에 대한 충분한 정보를 가지고 있습니다."
따라서 내결함성을 달성하기 위해 데이터를 복제할 필요가 없습니다.
Spark MapReduce에서 매퍼 출력은 OS 버퍼 캐시에 보관되고 리듀서는 출력이 디스크에 유출되어 다시 읽는 Hadoop과 달리 이를 옆으로 당겨 메모리에 직접 씁니다.
Spark의 메모리 캐시는 동일한 데이터를 계속해서 사용해야 하는 기계 학습 알고리즘에 적합합니다. Spark는 DAG(Direct Acyclic Graph)를 사용하여 복잡한 작업, 여러 단계의 데이터 파이프라인을 실행할 수 있습니다.
Spark는 Scala로 작성되었으며 JVM(Java Virtual Machine)에서 실행됩니다. Spark는 Java, Scala, Python 및 R 언어용 개발 API를 제공합니다. Spark는 Hadoop YARN, Apache Mesos에서 실행되며 자체 독립 실행형 클러스터 관리자가 있습니다.
2014년에는 100TB 데이터(1조 레코드) 벤치마크를 단 23분 만에 정렬하는 세계 기록 1위를 확보했는데, 이는 이전 야후의 하둡 기록이 약 72분이었다. 이것은 스파크가 정렬된 데이터를 3배 더 빠르고 10배 적은 기계로 처리한다는 것을 증명합니다. 모든 정렬은 실제로 스파크 인메모리 캐시 기능을 사용하지 않고 디스크(HDFS)에서 발생했습니다.
스파크 생태계
Spark는 다음 구성 요소를 제공하기 위해 한 번에 고급 분석 을 수행하기 위한 것입니다.
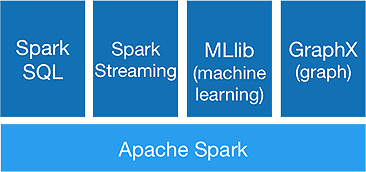
1.스파크 코어:
Spark core API는 Apache Spark 프레임워크의 기반으로 작업 스케줄링, 작업 분배, 메모리 관리, I/O 작업 및 장애 복구를 처리합니다. 스파크의 주요 논리 데이터 단위는 RDD(Resilient Distributed Dataset) 라고 하며, 나중에 병렬로 처리할 수 있도록 데이터를 분산 방식으로 저장합니다. 연산을 게으르게 계산합니다. 따라서 메모리를 항상 점유할 필요가 없으며 다른 작업에서 이를 활용할 수 있습니다.
2. 스파크 SQL:
대기 시간이 짧은 대화형 쿼리 기능을 제공합니다 . 새로운 DataFrame API는 구조화된 데이터와 반구조화된 데이터를 모두 보유할 수 있으며 모든 SQL 작업과 함수가 계산을 수행할 수 있도록 합니다.
3.스파크 스트리밍:
마이크로 배치로 데이터를 수집하고 처리하는 실시간 스트리밍 API 를 제공합니다.
들어오는 데이터에 대한 비즈니스 논리를 계산하고 결과를 즉시 생성하기 위해 연속적인 RDD 시퀀스인 Dstreams 를 사용합니다.
4.MLlib :
분류, 회귀, 협업 필터링 등과 같은 통계 알고리즘뿐만 아니라 기계 학습을 제공하는 스파크의 기계 학습 라이브러리 (Mahout보다 거의 9배 빠름)입니다.
5.그래프X :
GraphX API는 그래프를 처리하고 그래프 병렬 계산을 수행하는 기능을 제공합니다. PageRank와 같은 그래프 알고리즘과 그래프 분석을 위한 다양한 기능이 포함되어 있습니다.
Spark가 Hadoop 시대의 끝을 알릴까요?
Spark는 Hadoop만큼 성숙하지 않은 아직 젊은 시스템입니다. HBase와 같은 NOSQL용 도구는 없습니다. 더 빠른 데이터 처리를 위한 높은 메모리 요구 사항을 고려할 때 상용 하드웨어에서 실행된다고 말할 수는 없습니다. Spark에는 자체 스토리지 시스템이 없습니다. 이를 위해 HDFS에 의존합니다.
따라서 Hadoop MapReduce는 여전히 많은 데이터 파이프라이닝을 포함하지 않는 특정 배치 작업에 적합합니다.
“새로운 기술은 결코 오래된 것을 완전히 대체하지 않습니다. 둘 다 공존하기를 원합니다.”
결론
이 블로그에서는 Spark와 같은 도구가 필요한 이유와 클러스터 컴퓨팅 시스템 및 핵심 구성 요소를 더 빠르게 만드는 도구를 살펴보았습니다. 다음 부분에서는 Spark 핵심 API RDD, 변환 및 작업에 대해 자세히 알아보겠습니다.