
차원의 저주
게시 됨: 2015-07-08차원의 저주란?
차원의 저주는 고차원 공간*에서 작업할 때 관찰되는 데이터의 비직관적 속성을 말하며, 특히 거리 및 부피의 유용성 및 해석과 관련이 있습니다. 이것은 기계 학습 및 통계에서 내가 가장 좋아하는 주제 중 하나입니다. 광범위한 응용 프로그램(기계 학습 방법에 국한되지 않음)이 있고 매우 반직관적이어서 경외감을 불러일으키며 모든 분석 기술에 대한 심오한 응용 프로그램을 가지고 있기 때문입니다. 그것은 어떤 이집트의 저주처럼 '멋진' 무서운 이름을 가지고 있습니다!
빠른 이해를 위해 다음 예를 고려하십시오. 예를 들어 100미터 선에 동전을 떨어뜨렸다고 가정해 보겠습니다. 어떻게 찾나요? 간단합니다. 줄을 서서 검색하기만 하면 됩니다. 그러나 그것이 100 x 100 sq. m라면 어떨까요? 들? (대략) 축구장에서 동전 하나를 찾기 위해 노력하는 것은 이미 어려워지고 있습니다. 하지만 100 x 100 x 100 cu.m 공간이라면?! 축구장은 이제 30층 높이입니다. 행운을 빕니다 거기에서 동전을 찾으십시오! 그것은 본질적으로 "차원의 저주"입니다.
많은 ML 방법은 거리 측정을 사용합니다.
대부분의 세분화 및 클러스터링 방법은 관측치 간의 거리 계산에 의존합니다. 잘 알려진 k-평균 분할은 가장 가까운 중심에 점을 할당합니다. DBSCAN 및 계층적 클러스터링에도 거리 메트릭이 필요했습니다. 분포 및 밀도 기반 이상값 감지 알고리즘은 다른 거리에 상대적인 거리를 사용하여 이상값을 표시합니다.
k-최근접 이웃 방법과 같은 지도 분류 솔루션은 또한 관찰 사이의 거리를 사용하여 클래스를 알 수 없는 관찰에 할당합니다. Support Vector Machine 방법은 관찰과 커널 사이의 거리를 기반으로 선택된 커널 주변의 관찰을 변환하는 것을 포함합니다.
추천 시스템 의 일반적인 형태는 사용자 및 항목 속성 벡터 간의 거리 기반 유사성을 포함합니다. 다른 형태의 거리를 사용하더라도 차원의 수는 해석 설계에서 중요한 역할을 합니다.
가장 일반적인 거리 측정법 중 하나는 다차원 초공간에서 두 점 사이의 단순한 선형 거리인 유클리드 거리 측정법입니다. n차원 공간에서 점 i와 점 j에 대한 유클리드 거리는 다음과 같이 계산할 수 있습니다.
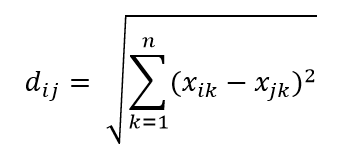
고차원에서 거리가 큰 영향을 미칩니다.
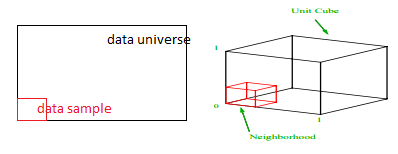
데이터 샘플링의 간단한 프로세스를 고려하십시오. 그림 1의 검은색 외부 상자가 전체 볼륨에 걸쳐 데이터 포인트가 균일하게 분포된 데이터 유니버스이고 빨간색 내부 상자로 둘러싸인 관측치의 1%를 샘플링하려고 한다고 가정합니다. 블랙박스는 각 측면이 해당 차원의 값 범위를 나타내는 다차원 공간의 하이퍼 큐브입니다. 그림 1의 간단한 3차원 예제의 경우 다음 범위를 가질 수 있습니다.
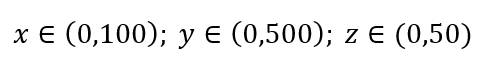
그림 1 : 샘플링
1% 샘플을 얻기 위해 샘플링해야 하는 각 범위의 비율은 얼마입니까? 2차원의 경우 범위의 10%가 전체 1% 샘플링을 달성하므로 x∈(0,10) 및 y∈(0,50)를 선택하고 모든 관찰의 1%를 캡처할 것으로 예상할 수 있습니다. 10%2=1%이기 때문입니다. 3차원에서 이 비율이 더 높거나 낮을 것으로 예상하십니까?
우리의 검색이 이제 추가 방향에 있지만 비례는 실제로 21.5%로 증가합니다. 증가할 뿐만 아니라 차원을 하나 더 추가하면 두 배가 됩니다! 그리고 전체의 100분의 1을 얻으려면 각 차원의 거의 1/5을 커버해야 한다는 것을 알 수 있습니다! 10차원에서 이 비율은 63%이고 100차원(실제 기계 학습에서 드문 차원 수가 아닙니다)에서는 관찰의 1%를 샘플링하기 위해 각 차원을 따라 범위의 95%를 샘플링해야 합니다! 이러한 놀라운 결과는 고차원에서 데이터 포인트가 균일하게 퍼진 경우에도 데이터 포인트의 퍼짐이 더 커지기 때문에 발생합니다.

이것은 실험 및 샘플링의 설계 측면에서 결과를 가져옵니다. 표본 크기가 모집단보다 훨씬 작음에도 불구하고 표본 추출이 모집단에 점근적으로 접근하는 경우에도 프로세스는 계산 비용이 매우 많이 듭니다.
고차원의 또 다른 거대한 결과를 고려하십시오. 많은 알고리즘은 미리 정의된 거리 임계값을 참조하여 일종의 근접성( DBSCAN , Kernels, k-Nearest Neighbour)을 정의하기 위해 두 데이터 포인트 사이의 거리를 측정합니다. 2차원에서는 한 점이 다른 점의 특정 반경 내에 있으면 두 점이 가깝다고 상상할 수 있습니다. 그림 2의 왼쪽 이미지를 고려하십시오. 검은색 사각형 내에서 균일한 간격의 점들이 빨간색 원 안에 속하는 비율은 얼마입니까? 그것은 약
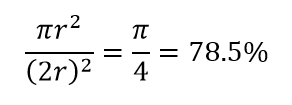
그림 2 : 근접성
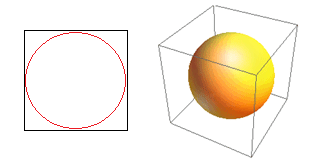
따라서 정사각형 안에 가능한 가장 큰 원을 맞추면 정사각형의 78%를 덮게 됩니다. 그러나 큐브 내부에서 가능한 가장 큰 구체는
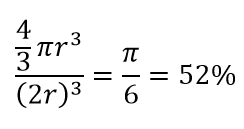
볼륨의. 이 볼륨은 10차원에 대해 0.24%로 기하급수적으로 감소합니다! 본질적으로 고차원 세계에서 모든 단일 데이터 포인트가 모서리에 있고 실제로 볼륨 중심이 아니라는 것, 즉 (거의) 중심이 없기 때문에 중심 볼륨이 아무것도 없다는 것을 의미합니다! 이것은 거리 기반 클러스터링 알고리즘의 엄청난 결과를 낳습니다. 모든 거리가 동일하게 보이기 시작하고 다른 거리보다 많거나 작은 모든 거리는 비유사성의 척도라기보다는 데이터의 더 무작위적인 변동입니다!
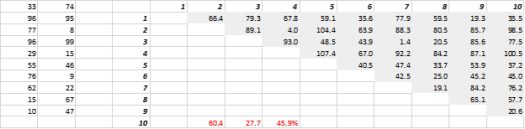
그림 3은 무작위로 생성된 2차원 데이터와 해당하는 all-to-all 거리를 보여줍니다. 표준편차를 평균으로 나누어 계산한 거리 변동 계수는 45.9%입니다. 유사하게 생성된 5-D 데이터의 해당 수는 26.5%이고 10-D의 경우 19.1%입니다. 분명히 이것은 하나의 샘플이지만 경향은 고차원에서 모든 거리가 거의 동일하고 가깝거나 멀거나 한 것이 없다는 결론을 뒷받침합니다!
그림 3 : 거리 클러스터링
고차원은 다른 것들에도 영향을 미칩니다
거리와 부피와는 별도로 차원의 수는 다른 실제 문제를 만듭니다. 솔루션 런타임 및 시스템 메모리 요구 사항은 종종 차원 수가 증가함에 따라 비선형적으로 증가합니다. 실현 가능한 솔루션의 기하급수적인 증가로 인해 많은 최적화 방법이 전역 최적에 도달할 수 없으며 로컬 최적과 관련이 있습니다. 또한, 최적화는 폐쇄형 솔루션 대신 기울기 하강법, 유전 알고리즘 및 시뮬레이션된 어닐링과 같은 검색 기반 알고리즘을 사용해야 합니다. 더 많은 차원은 상관 관계의 가능성을 도입하고 회귀 접근 방식에서는 매개변수 추정이 어려워질 수 있습니다.
고차원 다루기
이 자체는 별도의 블로그 게시물이지만 상관 분석, 클러스터링, 정보 값, 분산 인플레이션 요인, 주성분 분석은 차원 수를 줄일 수 있는 몇 가지 방법입니다.
* 데이터 포인트가 구성되는 변수, 관찰 또는 기능의 수를 데이터 차원이라고 합니다. 예를 들어, 공간의 모든 점은 길이, 너비, 높이의 3가지 좌표를 사용하여 나타낼 수 있으며 3차원을 갖습니다.