
일반적인 JavaScript SEO 문제 진단 가이드
게시 됨: 2023-07-10솔직히 말해서 자바스크립트와 SEO가 항상 잘 어울리는 것은 아닙니다. 일부 SEO의 경우 주제가 복잡함의 베일에 가려진 것처럼 느껴질 수 있습니다.
희소식: 레이어를 벗겨내면 많은 JavaScript 기반 SEO 문제가 검색 엔진 크롤러가 처음에 JavaScript와 상호 작용하는 방식의 기본으로 돌아옵니다.
따라서 이러한 기본 사항을 이해하면 문제를 파헤치고 그 영향을 이해하고 개발자와 협력하여 중요한 문제를 해결할 수 있습니다.
이 문서에서는 사이트가 JS 프레임워크에 구축될 때 발생하는 몇 가지 일반적인 문제를 진단하는 데 도움이 됩니다. 또한 렌더링과 관련하여 모든 기술적 SEO에 필요한 기본 지식을 분석합니다.
간단히 말해서 렌더링
보다 세분화된 내용을 다루기 전에 큰 그림을 살펴보겠습니다.
검색 엔진이 JavaScript로 구동되는 콘텐츠를 이해하려면 페이지를 크롤링 하고 렌더링해야 합니다.
문제는 검색 엔진이 사용할 리소스가 너무 많기 때문에 언제 사용할 가치가 있는지 선택해야 한다는 것입니다. 크롤러가 페이지를 렌더링 대기열로 보내더라도 페이지가 렌더링되는 것은 아닙니다.
페이지를 렌더링하지 않도록 선택하거나 콘텐츠를 제대로 렌더링할 수 없는 경우 문제가 될 수 있습니다.
프런트 엔드가 초기 서버 응답에서 HTML을 제공하는 방식으로 귀결됩니다.
URL이 브라우저에 구축되면 React, Vue 또는 Gatsby와 같은 프런트 엔드가 페이지의 HTML을 생성합니다. 크롤러는 결과 콘텐츠를 볼 수 있도록 렌더링을 기다리는 URL을 보내기 전에 해당 HTML이 서버에서 이미 사용 가능한지("미리 렌더링된" HTML) 확인합니다.
미리 렌더링된 HTML을 사용할 수 있는지 여부는 프런트 엔드가 구성된 방식에 따라 다릅니다. 서버 또는 클라이언트 브라우저를 통해 HTML을 생성합니다.
서버측 렌더링
이름이 모든 것을 말해줍니다. SSR 설정에서 크롤러는 추가 JS 실행 및 렌더링 없이 완전히 렌더링된 HTML 페이지를 제공받습니다.
따라서 페이지가 렌더링되지 않더라도 검색 엔진은 여전히 모든 HTML을 크롤링하고 페이지를 컨텍스트화(메타데이터, 사본, 이미지)하고 다른 페이지와의 관계(이동 경로, 표준 URL, 내부 링크)를 이해할 수 있습니다.
클라이언트 측 렌더링
CSR에서 HTML은 모든 JavaScript 구성 요소와 함께 브라우저에서 생성됩니다. JavaScript는 HTML을 크롤링할 수 있으려면 먼저 렌더링해야 합니다.
렌더링 서비스가 대기열로 전송된 페이지를 렌더링하지 않도록 선택하면 크롤러는 복사본, 내부 URL, 이미지 링크 및 메타데이터를 계속 사용할 수 없습니다.
결과적으로 검색 엔진은 검색 쿼리에 대한 URL의 관련성을 이해할 컨텍스트가 거의 또는 전혀 없습니다.
참고 : 초기 HTML 응답에 제공되는 HTML과 렌더링(표시)을 위해 JS를 실행해야 하는 HTML이 혼합되어 있을 수 있습니다. 몇 가지 요인에 따라 달라지며 가장 일반적인 요인에는 프레임워크, 개별 사이트 구성 요소가 구축되는 방식 및 서버 구성이 포함됩니다.
자바스크립트 SEO 툴킷
JavaScript 관련 SEO 문제를 식별하는 데 도움이 되는 도구가 분명히 있습니다.
브라우저 도구와 Google Search Console을 사용하여 많은 조사를 할 수 있습니다. 견고한 툴킷을 구성하는 후보 목록은 다음과 같습니다.
- 소스 보기: 페이지를 마우스 오른쪽 버튼으로 클릭하고 "소스 보기"를 클릭하면 페이지의 미리 렌더링된 HTML(초기 서버 응답)을 볼 수 있습니다.
- 실제 URL 테스트(URL 검사): Google Search Console의 URL 검사 탭에서 렌더링된 페이지의 스크린샷, HTML 및 기타 중요한 세부 정보를 봅니다. ('소스 보기'에서 사전 렌더링된 HTML과 GSC에서 라이브 URL을 테스트하여 렌더링된 HTML을 비교하면 많은 렌더링 문제를 찾을 수 있습니다.)
- Chrome 개발자 도구: 페이지를 마우스 오른쪽 버튼으로 클릭하고 "검사"를 선택하여 JavaScript 오류 등을 볼 수 있는 도구를 엽니다.
- Wappalyzer: 이 무료 Chrome 확장 프로그램을 설치하여 모든 사이트가 구축된 스택을 확인하고 프레임워크별 통찰력을 얻으십시오.
일반적인 JavaScript SEO 문제
문제 1: 미리 렌더링된 HTML은 보편적으로 사용할 수 없습니다.
앞에서 언급한 크롤링 및 컨텍스트화에 대한 부정적인 영향 외에도 검색 엔진이 페이지를 렌더링하는 데 소요될 수 있는 시간과 리소스 문제도 있습니다.
크롤러가 렌더링 프로세스를 통해 URL을 입력하도록 선택하면 렌더링 대기열에 있게 됩니다. 이것은 크롤러가 미리 렌더링된 HTML 구조와 렌더링된 HTML 구조 사이의 불일치를 감지할 수 있기 때문에 발생합니다. (미리 렌더링된 HTML이 없다면 말이 됩니다!)
URL이 웹 렌더링 서비스를 기다리는 시간에 대한 보장은 없습니다. WRS를 적시에 렌더링하도록 하는 가장 좋은 방법은 현장에서 URL의 중요성을 설명하는 주요 권위 신호가 있는지 확인하는 것입니다(예: 상단 탐색에 링크, 표준으로 참조되는 많은 내부 링크). 권한 신호도 크롤링해야 하기 때문에 조금 복잡해집니다.
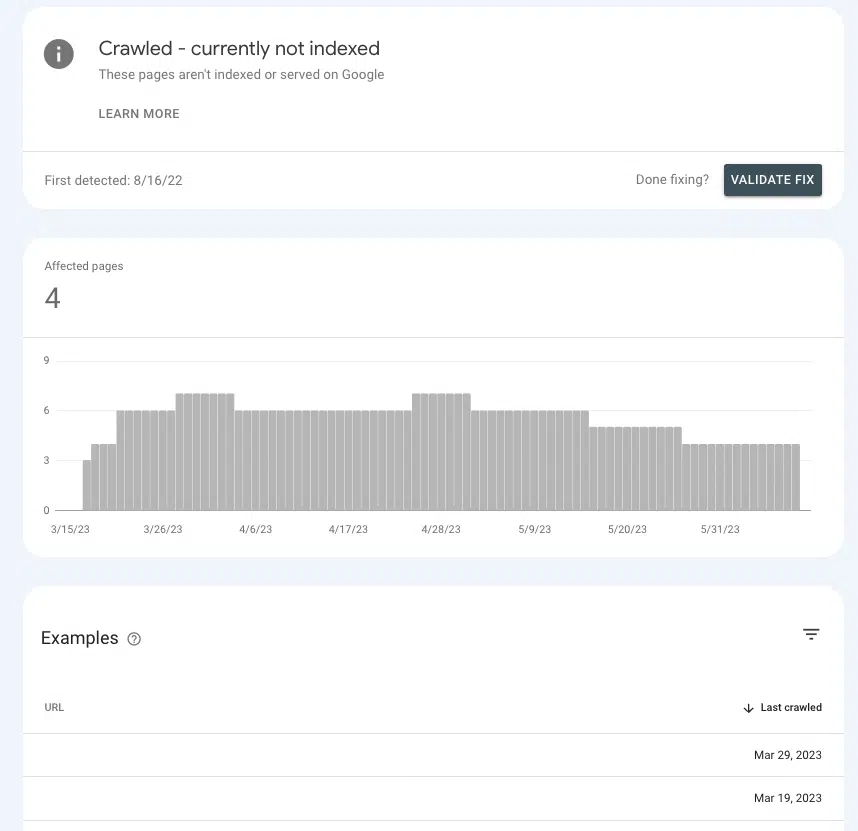
Google Search Console에서 주요 페이지에 올바른 권한 신호를 보내고 있는지 또는 림보에 앉게 하는지 여부를 파악할 수 있습니다.
페이지 > 페이지 인덱싱 > 크롤링 – 현재 인덱싱되지 않음 으로 이동하여 목록 내에서 우선 순위 페이지가 있는지 확인합니다.
그들이 대기실에 있다면, Google에서 리소스를 소비할 만큼 중요한지 여부를 확인할 수 없기 때문입니다.
일반적인 원인
기본 설정
대부분의 인기 있는 프런트 엔드는 클라이언트 측 렌더링으로 설정된 "즉시" 제공되므로 기본 설정이 범인일 가능성이 상당히 높습니다.
대부분의 프런트엔드가 기본적으로 CSR을 사용하는 이유가 궁금하다면 성능 이점 때문입니다. 개발자가 항상 SSR을 좋아하는 것은 아닙니다. 사이트 속도를 높이고 특정 상호 작용 요소(예: 페이지 간 고유한 전환)를 구현하는 가능성을 제한할 수 있기 때문입니다.
단일 페이지 애플리케이션
사이트가 단일 페이지 애플리케이션인 경우 사이트는 완전히 JavaScript로 래핑되며 브라우저에서 페이지의 모든 구성 요소(일명 모든 것)를 생성하고 클라이언트 측에서 렌더링되며 새 페이지는 새로고침 없이 제공됩니다.
이는 몇 가지 부정적인 영향을 미치며 아마도 가장 중요한 것은 페이지를 잠재적으로 발견할 수 없다는 것입니다.
SPA를 보다 SEO 친화적인 방식으로 설정하는 것이 불가능하다는 말은 아닙니다. 그러나 기회는 그것을 실현하기 위해 필요한 몇 가지 중요한 개발 작업이 있을 것입니다.
문제 2: 크롤러가 일부 페이지 콘텐츠에 액세스할 수 없음
모든 요소를 크롤링할 수 있는 경우에만 검색 엔진에서 URL을 렌더링하는 것이 좋습니다. 페이지를 렌더링하고 있지만 액세스할 수 없는 페이지 섹션이 있는 경우 어떻게 합니까?
예를 들어 SEO는 내부 링크 분석을 수행하고 여러 페이지에 연결된 URL에 대해 보고된 내부 링크를 거의 또는 전혀 찾지 못합니다.
Test Live URL 도구에서 렌더링된 HTML에 링크가 표시되지 않으면 Google에서 액세스할 수 없는 JavaScript 리소스에 링크가 제공되었을 수 있습니다.
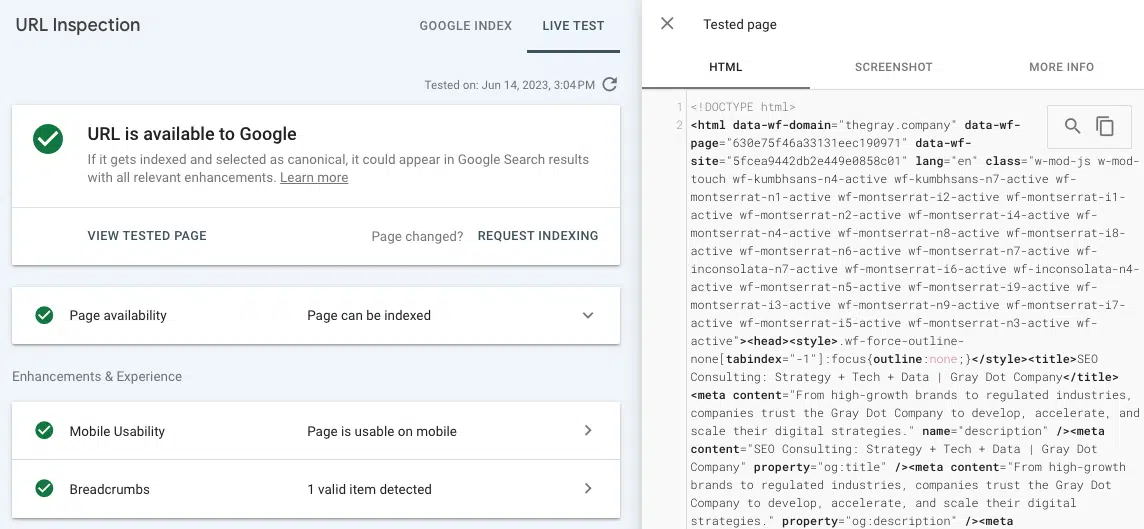
범인의 범위를 좁히려면 누락된 페이지 콘텐츠 또는 내부 링크가 URL 전체에서 페이지의 위치와 관련하여 공통점을 찾는 것이 좋습니다.
예를 들어 모든 제품 페이지의 동일한 섹션에 표시되는 FAQ 링크인 경우 개발자가 수정 범위를 좁히는 데 큰 도움이 됩니다.
일반적인 원인
자바스크립트 오류
여기서 면책 조항부터 시작하겠습니다. 발생하는 대부분의 JavaScript 오류는 SEO에 중요하지 않습니다.
따라서 오류를 찾기 위해 긴 목록을 개발자에게 가져가서 "이 모든 오류는 무엇입니까?"로 대화를 시작하면 제대로 수신하지 못할 수 있습니다.
그들이 JavaScript 전문가가 될 수 있도록 문제에 대해 말함으로써 "이유"에 접근하십시오(그들은 전문가이기 때문입니다!).
즉, 페이지의 나머지 부분을 구문 분석할 수 없게 만드는 구문 오류가 있습니다(예: "렌더링 차단"). 이 경우 렌더러는 개별 HTML 요소를 분리하거나 DOM의 콘텐츠를 구조화하거나 관계를 이해할 수 없습니다.
일반적으로 이러한 유형의 오류는 브라우저 보기에도 일종의 영향을 미치기 때문에 인식할 수 있습니다.
시각적 확인 외에도 페이지를 마우스 오른쪽 버튼으로 클릭하고 "검사"를 선택한 다음 "콘솔" 탭으로 이동하여 JavaScript 오류를 볼 수도 있습니다.
검색 마케터가 의존하는 일일 뉴스레터를 받으세요.
용어를 참조하십시오.

콘텐츠에 사용자 상호작용이 필요합니다.
렌더링에 대해 기억해야 할 가장 중요한 사항 중 하나는 Google이 사용자가 페이지와 상호작용해야 하는 콘텐츠를 렌더링할 수 없다는 것입니다. 또는 간단히 말해서 "클릭"할 수 없습니다.
그게 왜 중요한가요? 우리의 오래되고 믿음직한 친구인 아코디언 드롭다운과 얼마나 많은 사이트에서 제품 세부 정보 및 FAQ와 같은 콘텐츠를 구성하는 데 사용하는지 생각해 보십시오.
아코디언이 코딩된 방식에 따라 JS가 실행될 때까지 콘텐츠가 채워지지 않으면 Google에서 드롭다운의 콘텐츠를 렌더링하지 못할 수 있습니다.
확인하려면 페이지를 "검사"하고 "숨겨진" 콘텐츠(아코디언을 클릭하면 표시되는 내용)가 HTML에 있는지 확인할 수 있습니다.
그렇지 않은 경우 Googlebot 및 기타 크롤러가 페이지의 렌더링된 버전에서 이 콘텐츠를 볼 수 없음을 의미합니다.
문제 3: 사이트 섹션이 크롤링되지 않음
Google은 페이지를 크롤링하여 대기열로 보내는 경우 페이지를 렌더링하거나 렌더링하지 않을 수 있습니다. 페이지를 크롤링하지 않으면 해당 기회조차 불가능합니다.
Google이 페이지를 크롤링하는지 여부를 이해하기 위해 설정 > 크롤링 통계 보고서에서 크롤링 통계 보고서를 사용할 수 있습니다.
지난 3개월 동안 200개 상태 페이지의 모든 크롤링 인스턴스를 보려면 크롤링 요청: 확인(200)을 선택합니다. 그런 다음 필터링을 사용하여 개별 URL 또는 전체 디렉터리를 검색합니다.
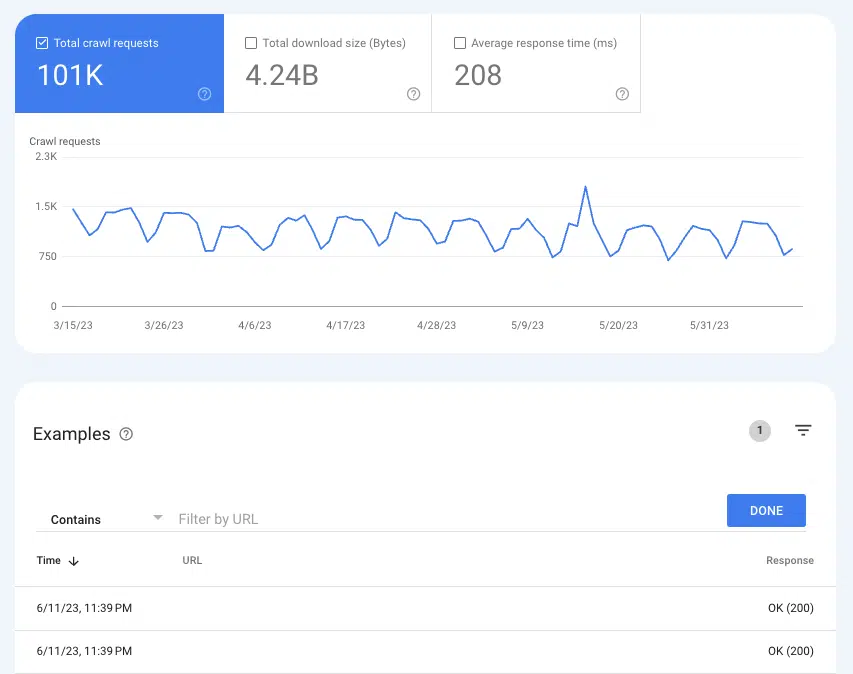
URL이 크롤링 로그에 표시되지 않으면 Google이 페이지를 검색하여 크롤링하지 못하거나 200페이지가 아니므로 완전히 다른 문제일 수 있습니다.
일반적인 원인
내부 링크는 크롤링할 수 없습니다.
링크는 크롤러가 새 페이지로 이동하는 도로 표지판입니다. 이것이 고아 페이지가 큰 문제인 이유 중 하나입니다.
잘 연결된 사이트가 있고 사이트 감사에서 고아 페이지 팝업이 표시되는 경우 미리 렌더링된 HTML에서 링크를 사용할 수 없기 때문일 가능성이 큽니다.
확인하는 쉬운 방법은 신고된 고아 페이지로 연결되는 URL로 이동하는 것입니다. 페이지를 마우스 오른쪽 버튼으로 클릭하고 "소스 보기"를 클릭합니다.
그런 다음 CMD + f를 사용하여 고아 페이지의 URL을 검색합니다. 사전 렌더링된 HTML에는 나타나지 않지만 브라우저에서 렌더링될 때 페이지에 나타나는 경우 4번 문제로 건너뜁니다.
XML 사이트맵이 업데이트되지 않음
XML 사이트맵은 Google이 새 페이지를 찾고 크롤링에서 우선 순위를 지정할 URL을 이해하는 데 도움이 되는 데 중요합니다.
XML 사이트맵이 없으면 다음 링크를 통해서만 페이지 검색이 가능합니다.
따라서 미리 렌더링된 HTML이 없는 사이트의 경우 오래되었거나 누락된 사이트맵은 Google이 페이지를 렌더링하고, 다른 페이지에 대한 내부 링크를 따르고, 대기하고, 렌더링하고, 링크를 따라가는 등의 작업을 기다리는 것을 의미합니다.
사용 중인 프런트 엔드에 따라 동적 XML 사이트맵을 만들 수 있는 플러그인에 액세스할 수 있습니다.
맞춤화가 필요한 경우가 많기 때문에 SEO는 사이트맵에 있어서는 안 되는 URL과 그 이유에 대한 논리를 부지런히 문서화하는 것이 중요합니다.
선호하는 SEO 도구를 통해 사이트맵을 실행하면 비교적 쉽게 확인할 수 있습니다.
문제 4: 내부 링크가 누락됨
크롤러에 대한 내부 링크를 사용할 수 없는 것은 잠재적인 검색 문제일 뿐만 아니라 형평성 문제이기도 합니다. 링크는 참조 URL에서 대상 URL로 SEO 자산을 전달하므로 페이지 및 도메인 권위를 모두 높이는 데 중요한 요소입니다.
홈페이지의 링크가 좋은 예입니다. 일반적으로 웹사이트에서 가장 권위 있는 페이지이므로 홈페이지에서 다른 페이지로 연결되는 링크는 많은 비중을 차지합니다.
이러한 링크를 크롤링할 수 없다면 광선검이 부러진 것과 같습니다. 가장 강력한 도구 중 하나가 쓸모 없게 됩니다.
일반적인 원인
링크에 도달하는 데 필요한 사용자 상호 작용
이전에 사용한 아코디언 예제는 콘텐츠가 사용자 상호 작용 뒤에 숨겨진 하나의 인스턴스일 뿐입니다. 광범위한 영향을 미칠 수 있는 또 다른 요인은 특히 상당한 제품 카탈로그가 있는 전자 상거래 사이트의 경우 무한 스크롤 페이지 매김입니다.
무한 스크롤 설정에서 상품 목록(카테고리) 페이지의 수많은 상품은 사용자가 특정 지점을 넘어 스크롤(지연 로딩)하거나 "더보기" 버튼을 탭하지 않으면 로드되지 않습니다.
따라서 JavaScript가 렌더링되더라도 크롤러는 아직 로드되지 않은 제품의 내부 링크에 액세스할 수 없습니다. 그러나 이러한 모든 제품을 한 페이지에 로드하면 페이지 성능이 저하되어 사용자 경험에 부정적인 영향을 미칩니다.
이것이 SEO가 일반적으로 결과의 모든 페이지에 고유하고 크롤링 가능한 URL이 있는 진정한 페이지 매김을 선호하는 이유입니다.
사이트에서 지연 로드를 최적화하고 사전 렌더링된 HTML에 모든 제품을 추가하는 방법이 있지만 이로 인해 렌더링된 HTML과 사전 렌더링된 HTML 간에 차이가 발생합니다.
사실상 이것은 렌더링 대기열에 더 많은 페이지를 보내고 크롤러가 필요 이상으로 더 열심히 일하게 만드는 이유를 만듭니다. 우리는 이것이 SEO에 좋지 않다는 것을 알고 있습니다.
최소한 무한 스크롤 최적화에 대한 Google의 권장 사항을 따르십시오.
제대로 코딩되지 않은 링크
Google이 사이트를 크롤링하거나 대기열의 URL을 렌더링할 때 페이지의 상태 비저장 버전을 다운로드합니다. 이것이 적절한 href 태그와 앵커(가장 자주 보는 연결 구조)를 사용하는 것이 중요한 이유의 큰 부분입니다. 크롤러는 라우터, 스팬 또는 onClick과 같은 링크 형식을 따를 수 없습니다.
팔로우 가능:
- <a href="https://example.com">
- <a href="/relative/경로/파일">
팔로우 불가:
- <a routerLink="일부/경로">
- <span href="https://example.com">
- <아>
개발자의 목적을 위해 이들은 모두 링크를 코딩하는 유효한 방법입니다. SEO 영향은 컨텍스트의 추가 계층이며 알아야 할 작업이 아니라 SEO입니다.
좋은 SEO가 하는 일의 큰 부분은 문서를 통해 개발자에게 해당 컨텍스트를 제공하는 것입니다.
문제 5: 메타데이터가 누락됨
HTML 페이지에서 제목, 설명, 표준 URL 및 메타 로봇 태그와 같은 메타데이터는 모두 헤드에 중첩됩니다.
분명한 이유로 메타데이터 누락은 SEO에 해롭지만 SPA에는 더욱 그렇습니다. 자체 참조 표준 URL과 같은 요소는 JS 페이지가 렌더링 대기열을 성공적으로 통과할 가능성을 높이는 데 중요합니다.
미리 렌더링된 HTML에 있어야 하는 모든 요소 중에서 헤드는 인덱싱에 가장 중요합니다.
다행스럽게도 이 문제는 사이트에서 위생 보고를 위해 사용하는 SEO 도구에서 메타데이터 누락에 대한 많은 오류를 유발하기 때문에 매우 쉽게 잡을 수 있습니다. 그런 다음 소스 코드에서 헤드를 찾아 확인할 수 있습니다.
일반적인 원인
메타데이터 차량이 부족하거나 잘못 구성됨
JS 프레임워크에서 플러그인은 헤드를 생성하고 메타데이터를 헤드에 삽입합니다. (가장 인기 있는 예는 React Helmet입니다.) 플러그인이 이미 설치되어 있어도 일반적으로 올바르게 구성해야 합니다.
다시 말하지만, 모든 SEO가 할 수 있는 영역은 개발자에게 문제를 가져오고, 이유를 설명하고, 잘 문서화된 승인 기준을 위해 긴밀히 작업하는 것입니다.
문제 6: 리소스가 크롤링되지 않음
스크립트 파일과 이미지는 렌더링 프로세스의 필수 구성 요소입니다.
자체 URL도 있으므로 크롤링 가능성의 법칙도 적용됩니다. 파일 크롤링이 차단된 경우 Google은 페이지를 파싱하여 렌더링할 수 없습니다.
URL이 크롤링되고 있는지 확인하려면 GSC 크롤링 통계에서 과거 요청을 볼 수 있습니다.
- 이미지: 설정 > 크롤링 통계 > 크롤링 요청: 이미지 로 이동합니다.
- JavaScript: 설정 > 크롤링 통계 > 크롤링 요청: 이미지 로 이동합니다.
일반적인 원인
robots.txt에 의해 차단된 디렉토리
스크립트 및 이미지 URL은 일반적으로 자체 전용 하위 도메인 또는 하위 폴더에 중첩되므로 robots.txt의 disallow 표현식은 크롤링을 방지합니다.
일부 SEO 도구는 스크립트 또는 이미지 파일이 차단되었는지 알려주지만 이미지 및 스크립트 파일이 중첩된 위치를 알고 있으면 문제를 쉽게 발견할 수 있습니다. robots.txt에서 해당 URL 구조를 찾을 수 있습니다.
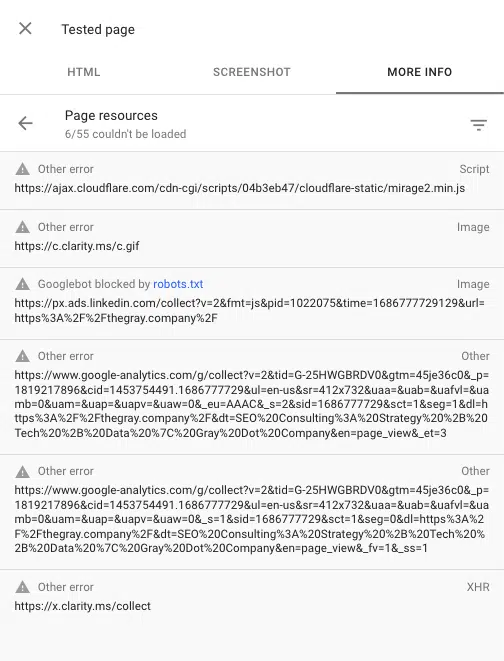
Google Search Console의 URL 검사 도구를 사용하여 페이지를 렌더링할 때 차단된 스크립트를 볼 수도 있습니다. "라이브 URL 테스트"를 선택한 다음 테스트된 페이지 보기 > 추가 정보 > 페이지 리소스 로 이동합니다.
여기에서 렌더링 프로세스 중에 로드에 실패한 모든 스크립트를 볼 수 있습니다. 파일이 robots.txt에 의해 차단된 경우 차단된 것으로 표시됩니다.
자바스크립트와 친해지기
예, JavaScript에는 일부 SEO 문제가 있을 수 있습니다. 그러나 SEO가 발전함에 따라 모범 사례는 훌륭한 사용자 경험과 동의어가 되고 있습니다.
훌륭한 사용자 경험은 종종 JavaScript에 달려 있습니다. 따라서 SEO의 임무는 JavaScript를 코딩하는 것이 아니지만 검색 엔진이 JavaScript와 상호 작용하고 렌더링하고 사용하는 방법을 알아야 합니다.
JS 프레임워크의 렌더링 프로세스와 몇 가지 일반적인 SEO 문제에 대한 확실한 이해를 통해 문제를 식별하고 개발자의 강력한 동맹이 될 수 있습니다.
이 기사에 표현된 의견은 게스트 작성자의 의견이며 반드시 검색 엔진 랜드가 아닙니다. 교직원 저자는 여기에 나열됩니다.