
Apache Spark는 어떻게 항공사 분석에 날개를 달 수 있습니까?
게시 됨: 2015-10-30글로벌 항공 산업은 계속해서 빠르게 성장하고 있지만 일관되고 견고한 수익성은 아직 확인되지 않았습니다. 국제항공운송협회(IATA)에 따르면 이 산업의 매출은 2005년 3,690억 달러에서 2015년 7,270억 달러로 지난 10년 동안 두 배 증가했습니다.

상업용 항공 부문에서는 공항, 항공기 제조업체, 제트 엔진 제조업체, 여행사 및 서비스 회사와 같은 가치 사슬의 모든 참여자가 순익을 얻습니다.
이러한 모든 플레이어는 항공편 거래의 높은 변동으로 인해 매우 많은 양의 데이터를 개별적으로 생성합니다. 수요를 식별하고 포착하는 것은 항공사가 차별화할 수 있는 훨씬 더 큰 기회를 제공하는 핵심입니다. 따라서 항공 산업은 빅 데이터 통찰력을 활용하여 매출을 높이고 이윤을 높일 수 있습니다.
빅데이터는 기존의 데이터 처리 시스템이나 DBMS 도구로 처리할 수 없을 정도로 크고 복잡한 데이터 세트의 집합체를 의미합니다.
Apache Spark는 대화형 쿼리 및 반복 알고리즘을 위해 특별히 설계된 오픈 소스 분산 클러스터 컴퓨팅 프레임워크입니다.
Spark DataFrame 추상화는 R의 기본 데이터 프레임 또는 Pythons pandas 패키지와 유사하지만 클러스터 환경에 저장되는 테이블 형식 데이터 개체입니다.
Fortunes의 최신 설문 조사에 따르면 Apache Spark는 2015년 가장 인기 있는 기술입니다.
최대 Hadoop 공급업체인 Cloudera도 Hadoops MapReduce에 작별을 고하고 Spark에 Hello를 말하고 있습니다.
Spark가 Hadoop보다 우위에 있는 것은 속도 입니다. Spark는 메모리 에서 대부분의 작업 을 처리합니다. 분산된 물리적 저장소에서 훨씬 빠른 논리적 RAM 메모리로 복사합니다. 이는 Hadoops MapReduce 시스템에서 수행해야 하는 느리고 투박한 기계식 하드 드라이브에 대한 쓰기 및 읽기에 소요되는 시간을 줄여줍니다.
또한 Spark에는 사물 인터넷 이라고도 하는 연결된 장치의 과거 데이터를 결합하여 실시간 데이터 분석과 같은 비즈니스 목표를 지원하기 위해 잘 만들어진 도구(실시간 처리, 기계 학습 및 대화형 SQL)가 포함되어 있습니다.
오늘은 Apache Spark 를 사용하여 샘플 공항 데이터에 대한 몇 가지 통찰력을 수집해 보겠습니다.
이전 블로그에서 우리는 새로운 Dataframes API를 사용하여 Spark에서 정형 및 반정형 데이터를 처리하는 방법과 JSON 데이터를 효율적으로 처리하는 방법을 다루었습니다.
이 블로그에서는 SQL을 사용하여 DataFrames의 데이터를 쿼리 하고 CSV 형식으로 파일 시스템에 출력을 저장하는 방법을 이해합니다.
Databricks CSV 구문 분석 라이브러리 사용
이를 위해 저는 Creators of Apache Spark가 설립하고 현재 Spark 개발 및 배포를 처리하는 회사인 Databricks에서 제공하는 CSV 구문 분석 라이브러리를 사용할 것입니다.
Spark 커뮤니티 는 기여자 수 측면에서 오픈 소스 소프트웨어의 주요 관리 기관인 전체 Apache Software Foundation에서 가장 활발한 프로젝트인 약 600명의 기여자로 구성됩니다.
Spark-csv 라이브러리는 스파크에서 csv 데이터를 구문 분석하고 쿼리하는 데 도움이 됩니다. 모든 Hadoop 호환 파일 시스템에서 csv 데이터를 읽고 쓰는 데 이 라이브러리를 사용할 수 있습니다.
Spark DataFrame에 데이터 로드
Databricks의 spark-csv 구문 분석 라이브러리를 사용하여 입력 파일을 Spark DataFrames에 로드할 수 있습니다.
–packages com.databricks: spark-csv_2.10:1.0.3 을 지정하여 Spark 셸에서 이 라이브러리를 사용할 수 있습니다.
아래와 같이 쉘을 시작하는 동안:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
이 명령을 내리면 spark-csv 패키지가 자동으로 다운로드되기 때문에 인터넷에 연결되어 있어야 합니다. 나는 스파크 1.4.0 버전을 사용하고 있습니다
이미 생성된 SparkContext(sc) 객체로 sqlContext를 생성할 수 있습니다.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
이제 스키마가 아래와 같은 Airports.csv(airport csv github) 파일에서 csv 데이터를 로드할 수 있습니다.
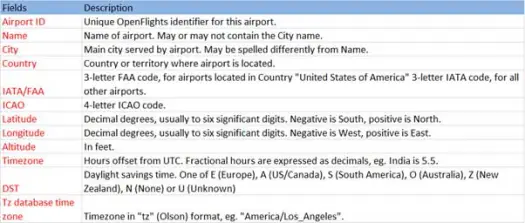
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))로드 작업은 Databricks spark-csv 라이브러리를 사용하여 *.csv 파일을 구문 분석하고 파일의 첫 번째 헤더 행과 동일한 열 이름을 가진 데이터 프레임을 반환합니다.
다음은 load 메소드에 전달되는 매개변수입니다.
- 소스 : "com.databricks.spark.csv" 는 spark에 csv 파일로 로드할 것임을 알려줍니다.
- 옵션:
- path – 파일이 있는 경로.
- 헤더 : "header" -> "true" 는 결과 데이터 프레임의 열 이름에 파일의 첫 번째 줄을 매핑하도록 spark에 지시합니다.
Dataframe의 스키마가 무엇인지 봅시다.
데이터 프레임에서 샘플 데이터 확인
scala> airportDF.show

임시 테이블을 사용하여 CSV 데이터 쿼리:
테이블에 대해 쿼리를 실행하려면 SQLContext에서 sql() 메서드를 호출합니다.
우리는 공항 DataFrame을 생성하고 CSV 데이터를 로드했습니다. 이 DF 데이터를 쿼리하려면 공항이라는 임시 테이블로 등록해야 합니다.
>
scala> airportDF.registerTempTable("airports")
데이터 세트의 남동부에 몇 개의 공항이 있는지 알아 보겠습니다.
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]

Spark의 SQL 쿼리에서 집계를 수행할 수 있습니다.
각 국가에 공항이 있는 독특한 도시가 몇 개인지 알아보겠습니다.
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
각 국가에 있는 공항의 평균 고도(피트)는 얼마입니까?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
이제 각 시간대별로 몇 개의 공항이 운영되고 있는지 알아볼까요?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
각 국가의 공항에 대한 평균 위도와 경도도 계산할 수 있습니다.
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
얼마나 많은 다른 DST가 있는지 계산할 수 있습니다.
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
CSV 형식으로 데이터 저장
지금까지 csv 데이터를 로드하고 쿼리했습니다. 이제 CSV 형식으로 결과를 파일 시스템에 다시 저장하는 방법을 살펴보겠습니다.
모든 국가의 북서부에 있는 모든 공항에 대한 보고서를 클라이언트에게 보내려고 한다고 가정합니다.
먼저 계산해 보겠습니다.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
그리고 CSV 파일로 저장
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
다음은 save 메소드에 전달되는 매개변수입니다.
- 소스 : 데이터를 csv로 저장하도록 spark에 지시하는 com.databricks.spark.csv 로드 메소드와 동일합니다.
- SaveMode : 주어진 출력 경로가 이미 존재하는 경우 수행해야 할 작업을 사용자가 미리 지정할 수 있습니다. 기존 데이터가 실수로 손실/덮어쓰기되지 않도록 합니다. 오류를 던지거나 추가하거나 덮어쓸 수 있습니다. 여기에서 기존 파일을 덮어쓰고 싶지 않기 때문에 ErrorIfExists 오류가 발생했습니다.
- 옵션 : 이 옵션은 load 메소드에 전달한 것과 동일합니다. 옵션:
- path – 파일이 저장되어야 하는 경로.
- 헤더 : "header" -> "true" 는 데이터 프레임의 열 이름을 결과 출력 파일의 첫 번째 줄에 매핑하도록 spark에 지시합니다.
다른 데이터 형식을 CSV로 변환
이 라이브러리를 사용하여 JSON, 쪽모이 세공 마루, 텍스트와 같은 다른 데이터 형식을 CSV로 변환할 수도 있습니다.
이전 블로그에서 우리는 json 데이터를 생성했습니다. github에서 찾을 수 있습니다
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
그냥 CSV로 저장하자.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
결론:
이 게시물에서 우리는 SparkSQL 대화형 쿼리를 사용하여 공항 데이터에 대한 몇 가지 통찰력을 수집했습니다.
Spark에서 csv 구문 분석 라이브러리를 탐색했습니다.
다음 블로그에서는 Spark Streaming과 같은 Spark의 매우 중요한 구성 요소를 살펴보겠습니다.
Spark Streaming을 사용하면 사용자가 실시간 데이터를 Spark로 수집하고 발생하는 대로 처리하고 결과를 즉시 제공할 수 있습니다.