
Google 항목 및 GPT-4를 사용하여 기사 개요를 만드는 방법
게시 됨: 2023-06-06이 기사에서는 일부 스크래핑과 Google 지식 그래프를 사용하여 잘 작성된 기사에 대한 개요와 요약을 생성하는 자동화된 프롬프트 엔지니어링을 수행하는 방법을 배우게 됩니다.
근본적으로 우리는 GPT-4에게 당신이 선택한 좋은 순위 페이지에서 찾은 키워드와 상위 엔터티를 기반으로 기사 개요를 생성하도록 지시하고 있습니다.
엔터티는 돌출 점수에 따라 정렬됩니다.
"왜 현저성 점수입니까?" 당신은 물어볼 수 있습니다.
Google은 API 문서에서 현저성을 다음과 같이 설명합니다.
“엔티티의 현저성 점수는 전체 문서 텍스트에 대한 해당 엔터티의 중요성 또는 중심성에 대한 정보를 제공합니다. 0에 가까운 점수는 덜 두드러지고 1.0에 가까운 점수는 매우 두드러집니다.”
작성하려는 콘텐츠에 어떤 엔터티가 존재해야 하는지에 영향을 미치는 데 사용하기에 꽤 좋은 지표인 것 같습니다. 그렇죠?
시작하기
이에 대해 다음 두 가지 방법을 사용할 수 있습니다.
- 약 5분(컴퓨터를 설정해야 하는 경우 10분)을 사용하고 컴퓨터에서 스크립트를 실행하거나…
- 내가 만든 Colab으로 이동하여 바로 플레이를 시작하세요.
나는 첫 번째에 부분적이지만 하루에 Colab 한두 개로 뛰어 들었습니다. 😀
아직 여기에 있고 자신의 컴퓨터에 이 설정을 원하지만 아직 Python이 설치되어 있지 않거나 IDE(통합 개발 환경)가 없다고 가정하면 먼저 컴퓨터를 사용하도록 설정하는 방법에 대한 빠른 읽기를 안내해 드리겠습니다. 주피터 노트북. 약 5분 이상 걸리지 않아야 합니다.
이제 출발할 시간입니다!
Google 항목 및 GPT-4를 사용하여 기사 개요 작성
쉽게 따라할 수 있도록 지침을 다음과 같이 형식화하겠습니다.
- 단계 : 진행 중인 단계에 대한 간략한 설명입니다.
- Code : 해당 단계를 완료하는 코드입니다.
- 설명 : 코드가 수행하는 작업에 대한 간단한 설명입니다.
1단계: 원하는 것을 말해주세요
아웃라인을 만들기 전에 원하는 것을 정의해야 합니다.
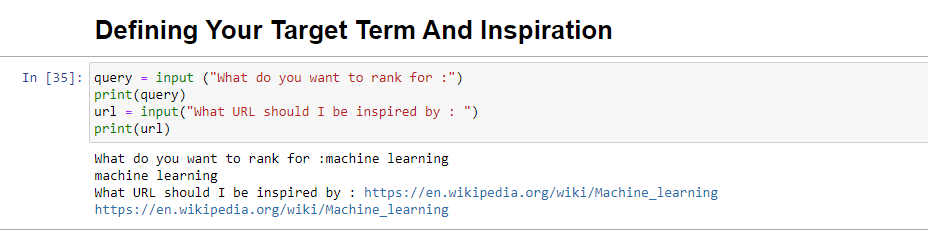
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)이 블록을 실행하면 사용자(아마도 귀하)에게 기사 순위를 매길/순위를 매길 쿼리를 입력하고 원하는 기사의 URL을 입력할 장소를 제공하라는 메시지가 표시됩니다. 영감을 받는 작품.
순위가 높고 사이트에 적합한 형식이며 사이트의 강점뿐만 아니라 기사의 가치만으로 순위를 매길 자격이 있다고 생각하는 기사를 제안합니다.
실행하면 다음과 같이 표시됩니다.
2단계: 필수 라이브러리 설치
다음으로 우리는 마법을 일으키는 데 사용할 모든 라이브러리를 설치해야 합니다.
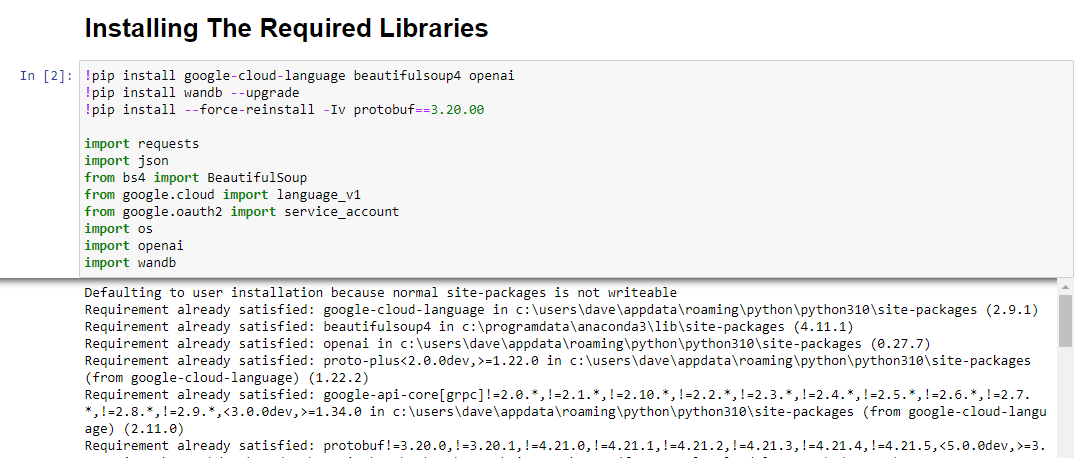
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandb다음 라이브러리를 설치하고 있습니다.
- 요청 : 이 라이브러리를 사용하면 웹사이트 또는 웹 API에서 콘텐츠를 검색하기 위해 HTTP 요청을 할 수 있습니다.
- JSON : JSON 문자열을 Python 개체로 구문 분석하고 Python 개체를 JSON 문자열로 직렬화하는 등 JSON 데이터로 작업하는 기능을 제공합니다.
- BeautifulSoup : 이 라이브러리는 웹 스크래핑 목적으로 사용됩니다. HTML 또는 XML 문서를 구문 분석 및 탐색하고 문서에서 관련 정보를 추출하는 데 도움이 됩니다.
- Google.cloud.language_v1 : 자연어 처리 기능을 제공하는 Google Cloud의 라이브러리입니다. 텍스트 데이터에 대한 감정 분석, 엔터티 인식 및 구문 분석과 같은 다양한 작업을 수행할 수 있습니다.
- Google.oauth2.service_account : 이 라이브러리는 Google OAuth2 Python 패키지의 일부입니다. Google Cloud 프로젝트의 리소스에 대한 제한된 액세스 권한을 부여하는 방법인 서비스 계정을 사용하여 Google API 인증을 지원합니다.
- OS : 이 라이브러리는 운영 체제와 상호 작용하는 방법을 제공합니다. 파일 작업, 환경 변수 및 프로세스 관리와 같은 다양한 기능에 액세스할 수 있습니다.
- OpenAI : 이 라이브러리는 OpenAI Python 패키지입니다. GPT-4(및 3)를 포함하여 OpenAI의 언어 모델과 상호 작용할 수 있는 인터페이스를 제공합니다. 이를 통해 개발자는 텍스트를 생성하고 텍스트 완성을 수행하는 등의 작업을 수행할 수 있습니다.
- Pandas : 데이터 조작 및 분석을 위한 강력한 라이브러리입니다. 테이블이나 CSV 파일과 같은 구조화된 데이터를 효율적으로 처리하고 분석하기 위한 데이터 구조와 기능을 제공합니다.
- WandB : 이 라이브러리는 "Weights & Biases"의 약자이며 실험 추적 및 시각화를 위한 도구입니다. 메트릭, 하이퍼 매개 변수 및 기계 학습 실험의 기타 중요한 측면을 기록하고 시각화하는 데 도움이 됩니다.
실행하면 다음과 같이 표시됩니다.
검색 마케터가 의존하는 일일 뉴스레터를 받으세요.
용어를 참조하십시오.
3단계: 인증
우리의 인증을 제자리에 갖다 놓기 위해 잠시 우리를 곁길로 옮겨야 할 것입니다. OpenAI API 키와 Google Knowledge Graph 검색 자격 증명이 필요합니다.
이 작업은 몇 분 밖에 걸리지 않습니다.
OpenAI API 받기
현재 대기자 명단에 등록해야 할 가능성이 높습니다. 저는 API에 일찍 액세스할 수 있어서 운이 좋았고, 그래서 여러분이 API를 받자마자 설정하는 데 도움이 되고자 이 글을 씁니다.
등록 이미지는 GPT-3에서 가져온 것이며 모든 사용자가 흐름을 사용할 수 있게 되면 GPT-4용으로 업데이트됩니다.
GPT-4를 사용하기 전에 액세스하려면 API 키가 필요합니다.
하나를 얻으려면 OpenAI의 제품 페이지로 이동하여 시작하기 를 클릭하십시오.
가입 방법을 선택하고(저는 Google을 선택했습니다) 인증 절차를 진행합니다. 이 단계를 위해 문자 메시지를 받을 수 있는 휴대전화에 액세스해야 합니다.
완료되면 API 키를 생성합니다. 이것은 OpenAI가 스크립트를 계정에 연결할 수 있도록 하기 위한 것입니다.
그들은 누가 무엇을 하고 있는지 알고 귀하가 하고 있는 일에 대해 귀하에게 청구해야 하는지 여부와 금액을 결정해야 합니다.
OpenAI 가격
가입하면 5달러 크레딧을 받을 수 있으며 실험만 해보면 놀라울 정도로 멀리 갈 수 있습니다.
이 글을 쓰는 시점에서 과거 가격은 다음과 같습니다.

OpenAI 키 생성
키를 생성하려면 오른쪽 상단의 프로필을 클릭하고 API 키 보기를 선택합니다.
...그런 다음 키를 생성합니다.
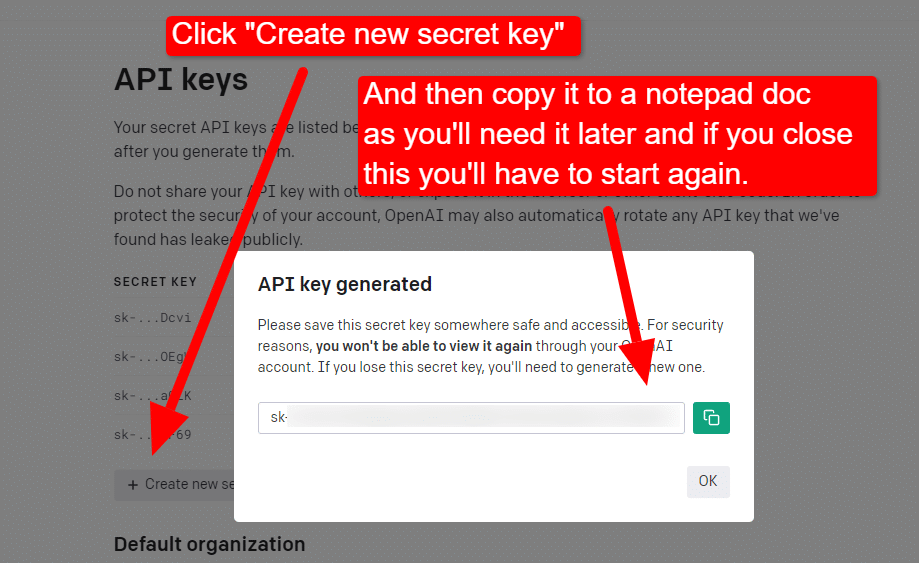
라이트박스를 닫으면 키를 볼 수 없으며 키를 다시 만들어야 하므로 이 프로젝트의 경우 간단히 메모장 문서에 복사하여 곧 사용할 수 있습니다.
참고: 키를 저장하지 마십시오(데스크톱의 메모장 문서는 보안 수준이 높지 않음). 잠시 사용한 후에는 메모장 문서를 저장하지 않고 닫습니다.
Google Cloud 인증 받기
먼저 Google 계정에 로그인해야 합니다. (당신은 SEO 사이트에 있으므로 하나 있다고 가정합니다. 🙂)
그런 다음 원하는 경우 Knowledge Graph API 정보를 검토하거나 API 콘솔로 바로 이동하여 시작할 수 있습니다.
콘솔에 있으면 다음을 수행하십시오.
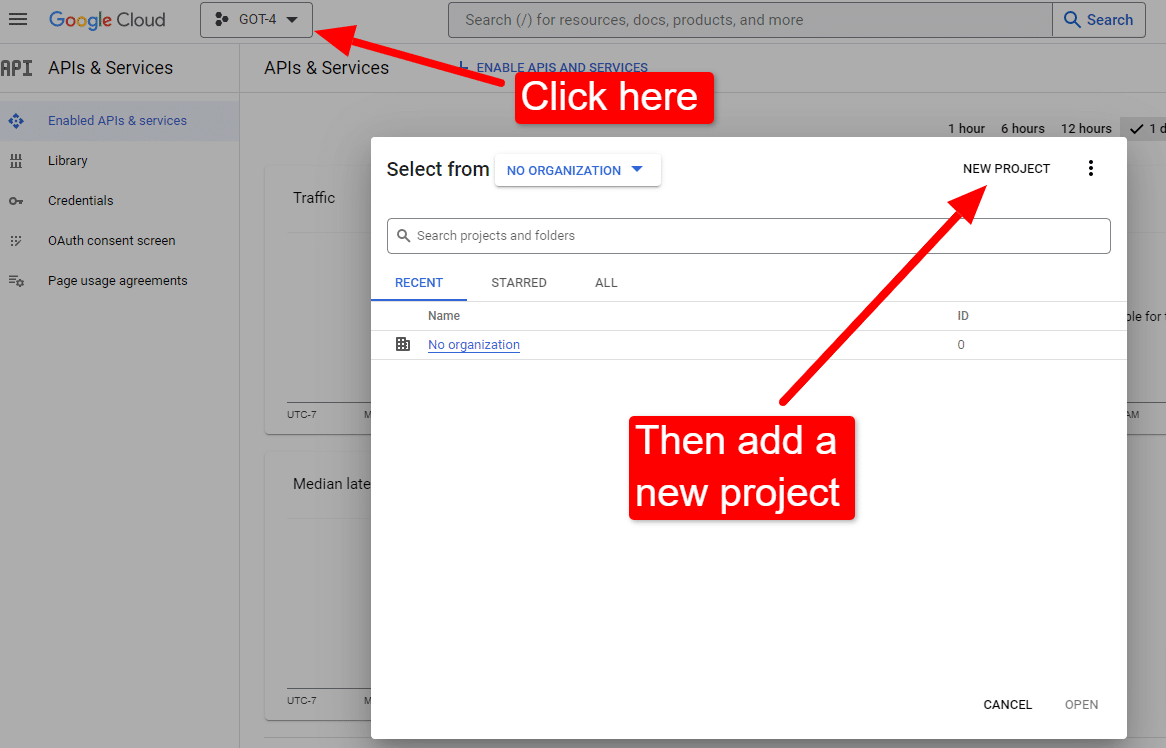
"Dave's Awesome Articles"와 같은 이름을 지정합니다. 알다시피… 기억하기 쉽습니다.
다음으로 Enable APIs and services 를 클릭하여 API를 활성화합니다.
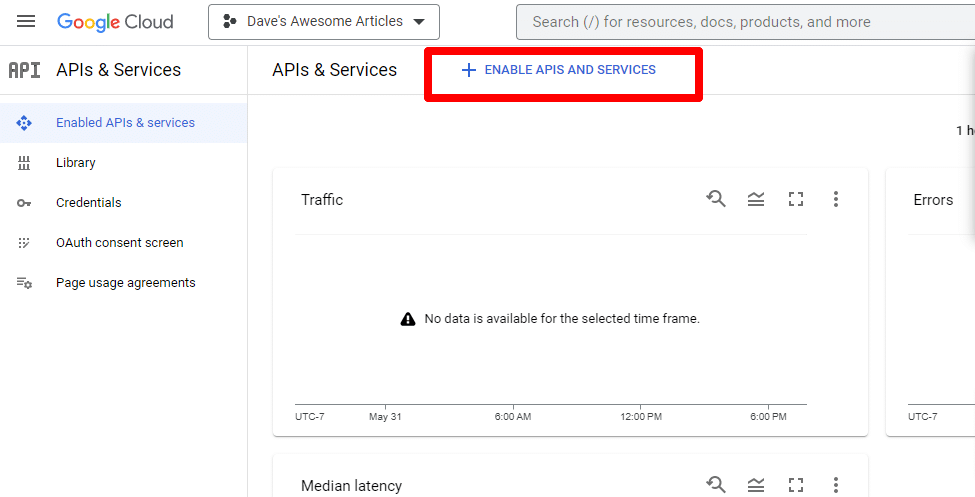
Knowledge Graph Search API를 찾아 활성화합니다.
그런 다음 자격 증명을 만들 수 있는 기본 API 페이지로 돌아갑니다.
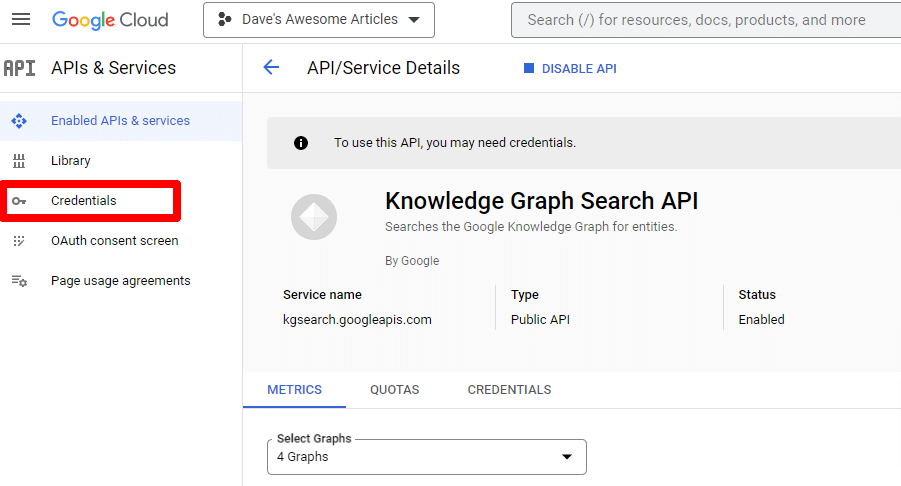
그리고 서비스 계정을 만들 것입니다.

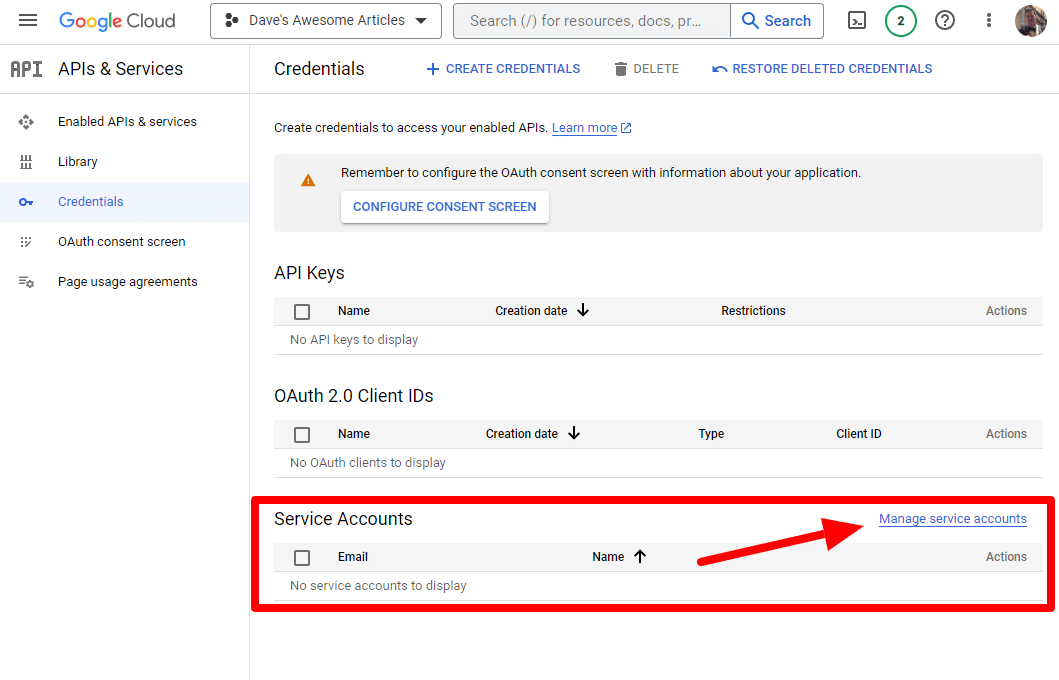
간단히 서비스 계정을 만드세요.
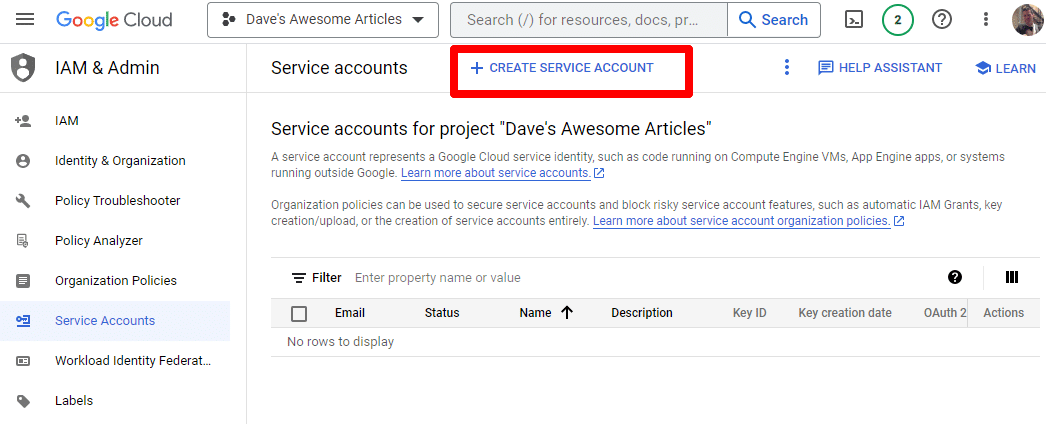
필수 정보를 입력합니다.
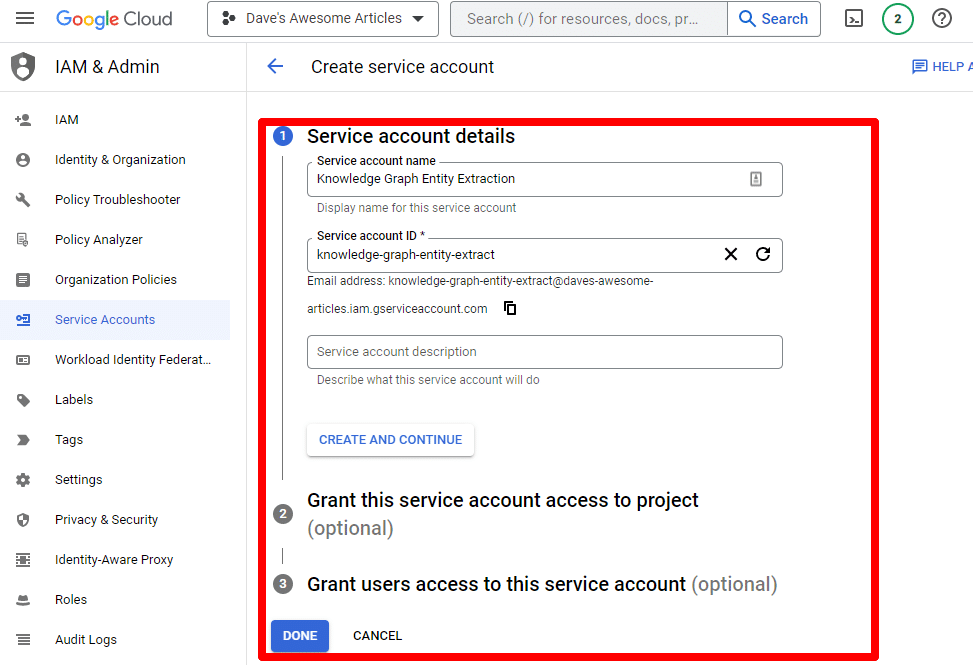
(이름을 지정하고 소유자 권한을 부여해야 합니다.)
이제 서비스 계정이 생겼습니다. 남은 것은 키를 만드는 것입니다.
작업 아래의 점 세 개를 클릭하고 키 관리 를 클릭합니다.
키 추가를 클릭한 다음 새 키 만들기를 클릭합니다.
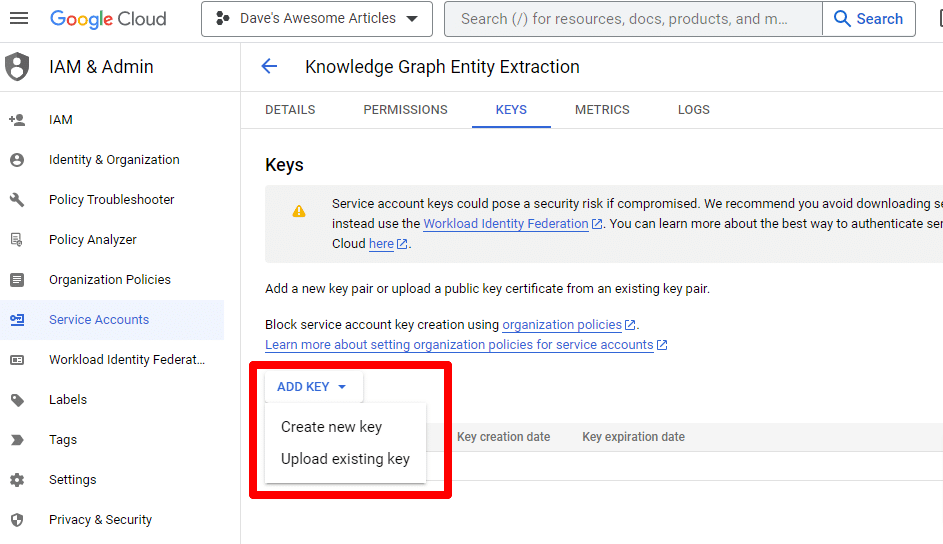
키 유형은 JSON입니다.
즉시 기본 다운로드 위치로 다운로드되는 것을 볼 수 있습니다.
이 키는 API에 대한 액세스 권한을 부여하므로 OpenAI API와 마찬가지로 안전하게 보관하십시오.
좋아요… 돌아왔습니다. 스크립트를 계속 사용할 준비가 되셨습니까?
이제 API 키와 다운로드한 파일의 경로를 정의해야 합니다. 이를 수행하는 코드는 다음과 같습니다.
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") YOUR_OPENAI_API_KEY 자신의 키로 교체합니다.
또한 /PATH-TO-FILE/FILENAME.JSON 파일 이름을 포함하여 방금 다운로드한 서비스 계정 키의 경로로 바꿉니다.
셀을 실행하면 계속 진행할 준비가 된 것입니다.
4단계: 함수 만들기
다음으로 다음 기능을 생성합니다.
- 위에서 입력한 웹페이지를 스크랩합니다.
- 콘텐츠를 분석하고 엔터티를 추출합니다.
- GPT-4를 사용하여 기사를 생성합니다.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()이것은 의견이 설명하는 것과 거의 같습니다. 위에서 설명한 목적을 위해 세 가지 기능을 만들고 있습니다.
예리한 눈은 다음을 알 수 있습니다.
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, 콘텐츠를 편집할 수 있고( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) ChatGPT가 수행할 역할을 설명할 수 있습니다. 어조를 추가할 수도 있습니다(예: "당신은 친근한 작가입니다...").
5단계: URL 스크랩 및 엔터티 인쇄
이제 우리는 손을 더럽히고 있습니다. 다음을 수행할 시간입니다.
- 위에서 입력한 URL을 스크랩합니다.
- 단락 태그 내에 있는 모든 콘텐츠를 가져옵니다.
- Google Knowledge Graph API를 통해 실행합니다.
- 빠른 미리보기를 위해 엔터티를 출력합니다.
기본적으로 이 단계에서 무엇이든 보고 싶을 것입니다. 아무것도 보이지 않으면 다른 사이트를 확인하십시오.
content = scrape_url(url) entities = analyze_content(content)1번째 줄이 우리가 처음 입력한 URL을 스크랩하는 함수를 호출하는 것을 볼 수 있습니다. 두 번째 줄은 콘텐츠를 분석하여 엔터티 및 주요 메트릭을 추출합니다.
analyze_content 함수의 일부는 빠른 참조 및 확인을 위해 찾은 엔터티 목록도 인쇄합니다.
6단계: 엔터티 분석
내가 처음 스크립트를 가지고 놀기 시작했을 때, 나는 20개의 엔터티로 시작했고 그것이 보통 너무 많다는 것을 빨리 발견했습니다. 그런데 기본값(10)이 맞나요?
알아보기 위해 쉽게 평가할 수 있도록 데이터를 W&B Tables에 기록합니다. 향후 평가를 위해 데이터를 무기한 보관합니다.
먼저 가입하는 데 약 30초가 소요됩니다. (걱정하지 마세요. 이런 종류의 것은 무료입니다!) https://wandb.ai/site에서 할 수 있습니다.
이 작업을 완료하면 이 작업을 수행하는 코드는 다음과 같습니다.
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()실행하면 출력은 다음과 같습니다.
링크를 클릭하여 달리기를 보면 다음을 확인할 수 있습니다.
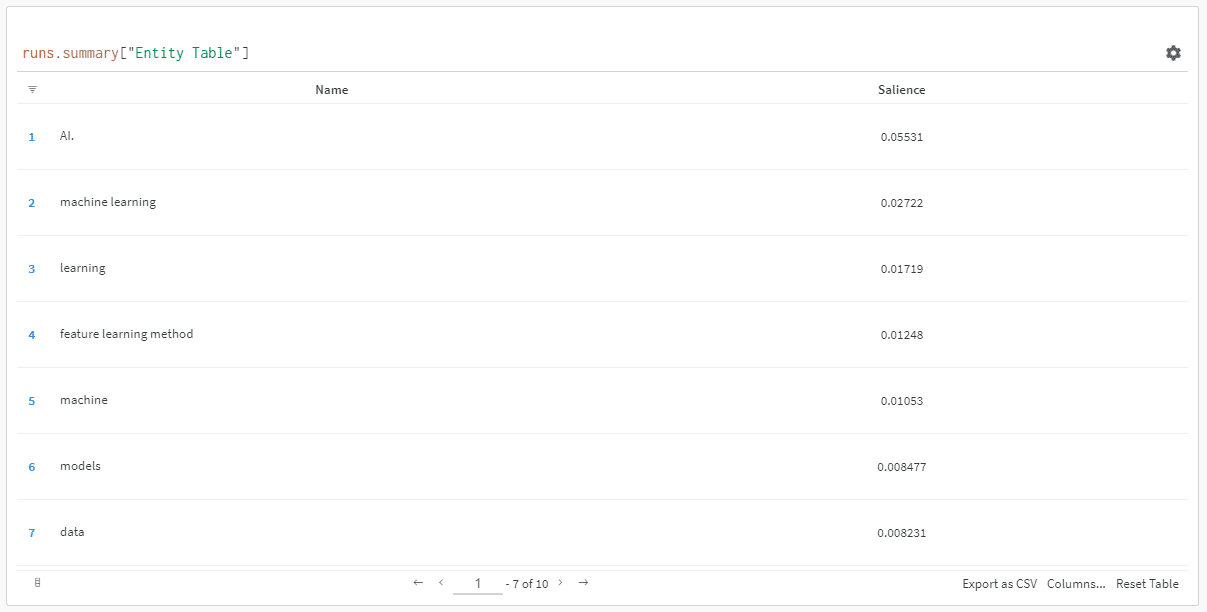
현저성 점수가 떨어지는 것을 볼 수 있습니다. 이 점수는 해당 검색어가 검색어가 아니라 페이지에서 얼마나 중요한지를 계산한다는 점을 기억하세요.
이 데이터를 검토할 때 중요도를 기반으로 하거나 관련 없는 용어 팝업이 표시되는 경우에만 엔터티 수를 조정하도록 선택할 수 있습니다.
엔터티 수를 조정하려면 함수 셀로 이동하여 다음을 편집합니다.
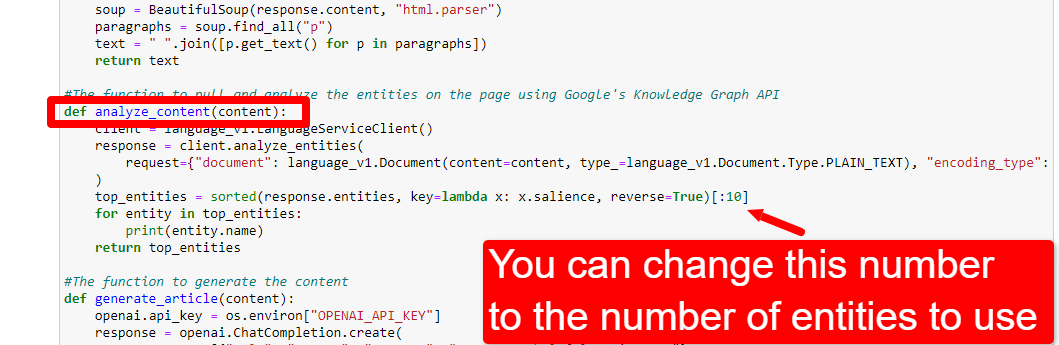
그런 다음 셀을 다시 실행하고 새 엔터티 수를 사용하기 위해 내용을 스크랩하고 분석하기 위해 실행한 셀을 실행해야 합니다.
7단계: 기사 개요 생성
모두가 기다려온 순간이 기사 개요를 생성할 때입니다.
이것은 두 부분으로 이루어집니다. 먼저 셀을 추가하여 프롬프트를 생성해야 합니다.
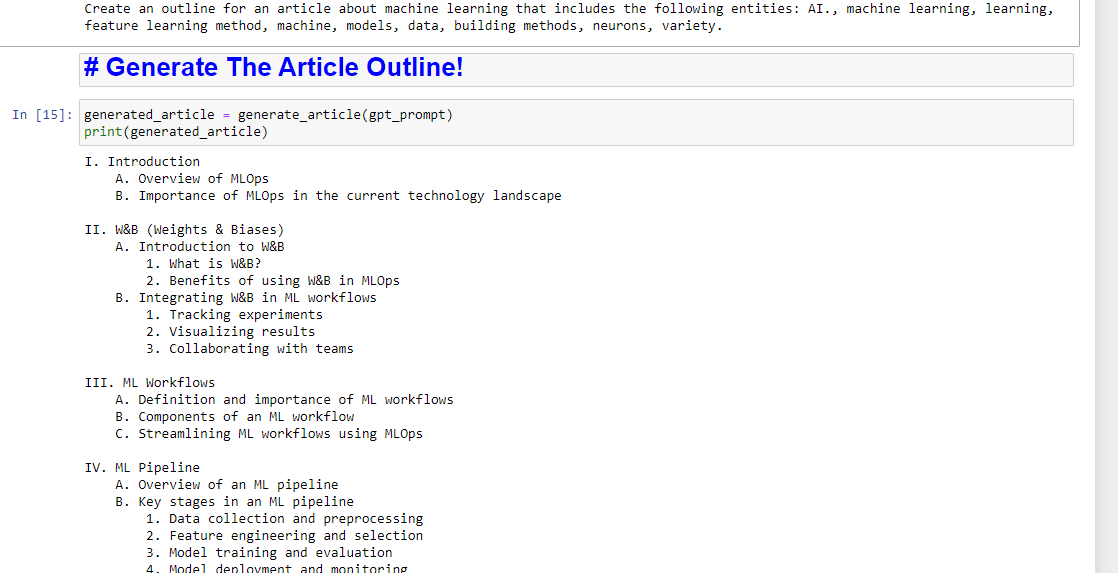
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)이것은 본질적으로 기사를 생성하라는 프롬프트를 생성합니다.

그런 다음 남은 것은 다음을 사용하여 문서 개요를 생성하는 것입니다.
generated_article = generate_article(gpt_prompt) print(generated_article)다음과 같이 생성됩니다.
또한 요약을 작성하려면 다음을 추가할 수 있습니다.
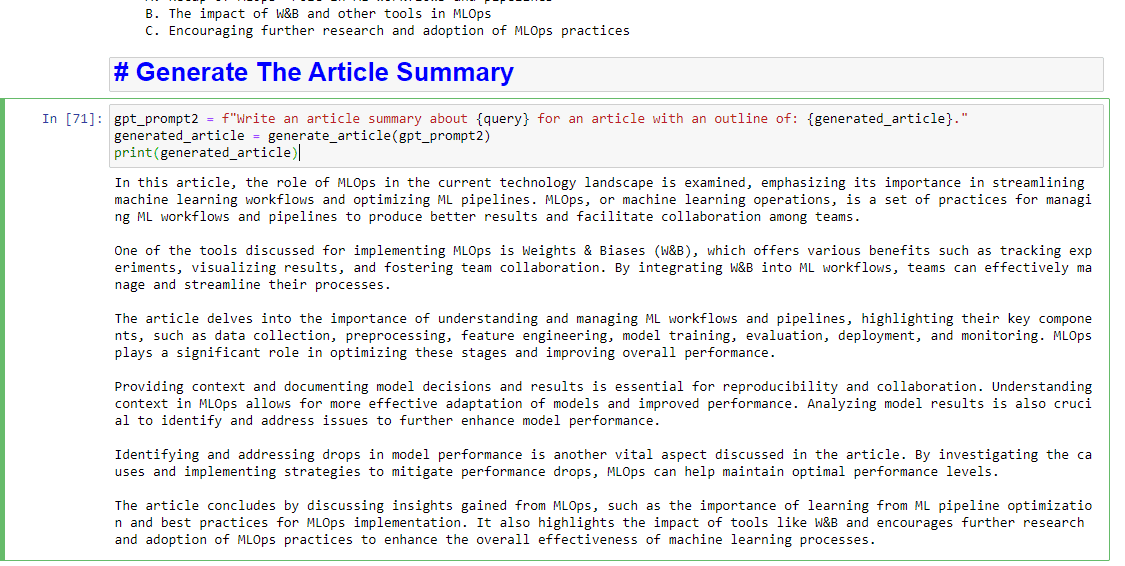
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)다음과 같이 생성됩니다.
이 기사에 표현된 의견은 게스트 작성자의 의견이며 반드시 검색 엔진 랜드가 아닙니다. 교직원 저자는 여기에 나열됩니다.