
Google은 스팸 및 AI 콘텐츠 감지 및 웹사이트 순위 지정을 위해 ChatGPT와 유사한 시스템을 사용하고 있나요?
게시 됨: 2023-02-01헤드라인은 의도적으로 오해의 소지가 있지만 "ChatGPT"라는 용어를 사용하는 경우에만 해당됩니다.
"ChatGPT와 같은"은 시스템을 "GPT-2 또는 GPT-3과 같은 텍스트 생성 모델"로 설명하는 대신 독자가 내가 언급하는 기술 유형을 즉시 알 수 있도록 합니다. (또한 후자는 실제로 클릭할 수 없을 것입니다...)
이 기사에서 살펴볼 내용은 오래되었지만 관련성이 높은 2020년 Google 논문인 "Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study"입니다.
그 논문은 무엇에 관한 것입니까?
저자에 대한 설명부터 시작하겠습니다. 그들은 주제를 다음과 같이 소개합니다.
“많은 사람들이 인간처럼 보이는 텍스트를 대규모로 생산할 수 있는 능력 때문에 야생에서 신경 텍스트 생성기의 잠재적 위험에 대해 우려를 제기했습니다.
인간과 기계 생성 텍스트를 구별하도록 훈련된 분류기는 최근 웹에서 기계 생성 텍스트의 존재를 모니터링하기 위해 사용되었습니다 [29]. 그러나 레이블을 요구하지 않는 매력적인 특성에도 불구하고 이러한 분류기를 다른 용도에 적용하는 작업은 거의 수행되지 않았습니다. 인간 텍스트 모음과 생성 모델만 있으면 됩니다. 이 작업에서 엄격한 인간 평가를 통해 기성 인간 대 기계 판별자가 페이지 품질의 강력한 분류자 역할을 한다는 것을 보여줍니다 . 즉, 기계로 생성된 것처럼 보이는 텍스트는 일관성이 없거나 이해할 수 없는 경향이 있습니다. 야생에서 낮은 페이지 품질의 존재를 이해하기 위해 우리는 분류기를 5억 개의 영어 웹페이지 샘플에 적용합니다.”
본질적으로 그들이 말하는 것은 동일한 모델을 사용하여 AI 기반 복사를 감지하기 위해 개발된 동일한 분류기가 저품질 콘텐츠를 감지하는 데 성공적으로 사용될 수 있다는 것을 발견했다는 것입니다.
물론 이것은 우리에게 중요한 질문을 남깁니다.
이것은 인과관계 (즉, 시스템이 진정으로 능숙하기 때문에 이를 선택하는 것입니까)입니까, 아니면 상관관계 (즉, 현재 많은 스팸이 더 나은 도구로 쉽게 우회할 수 있는 방식으로 생성됩니까)입니까?
그러나 이에 대해 살펴보기 전에 저자의 작업과 결과를 살펴보겠습니다.
설정
참고로 그들은 실험에서 다음을 사용했습니다.
- 두 가지 텍스트 생성 모델 , OpenAI의 RoBERTa 기반 GPT-2 검출기(GPT-2 출력과 함께 RoBERTa 모델을 사용하고 AI 생성 가능성 여부를 예측하는 검출기) 및 GLTR 모델 GPT-2 출력 및 유사하게 작동합니다.
위의 문서에서 복사한 콘텐츠에서 이 모델의 출력 예를 볼 수 있습니다.
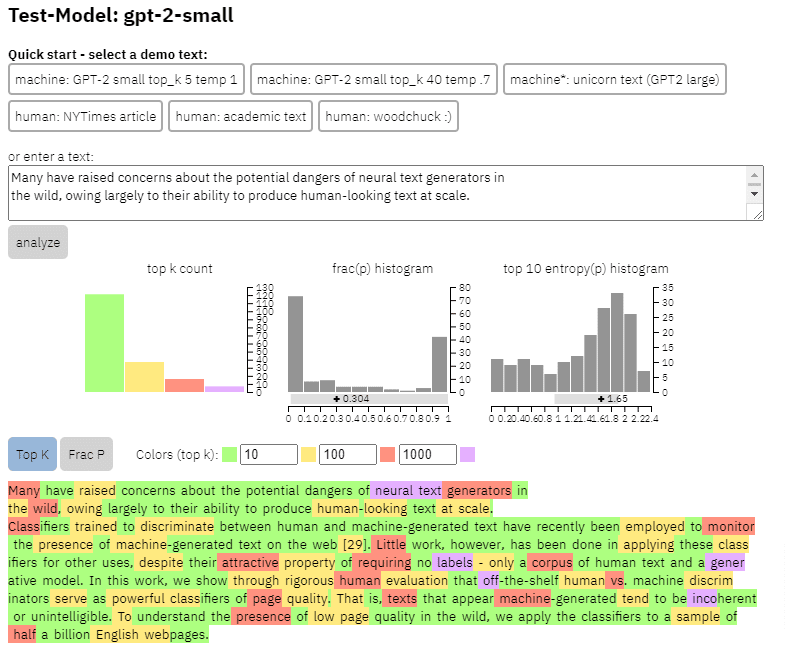
- 세 가지 데이터 세트 Web500M(5억 개의 영어 웹페이지 무작위 샘플링), GPT-2 출력(250k GPT-2 텍스트 생성) 및 Grover-Output(사전 학습된 Grover-Base 모델을 사용하여 내부적으로 120만 개의 기사 생성) 가짜 뉴스를 탐지하기 위해).
- Enron Spam Email Dataset에서 훈련된 분류 기인 Spam Baseline . 그들은 이 분류자를 사용하여 할당할 언어 품질 번호를 설정했습니다. 따라서 모델이 0.2의 확률로 문서가 스팸이 아니라고 판단한 경우 할당된 언어 품질(LQ) 점수는 0.2였습니다.
검색 마케터가 의존하는 일일 뉴스레터를 받으세요.
용어를 참조하십시오.
스팸 확산에 대한 여담
저자가 우연히 발견한 몇 가지 흥미로운 발견에 대해 논의하기 위해 잠깐 자리를 비우고 싶었습니다. 하나는 다음 그림에 설명되어 있습니다(논문의 그림 3).
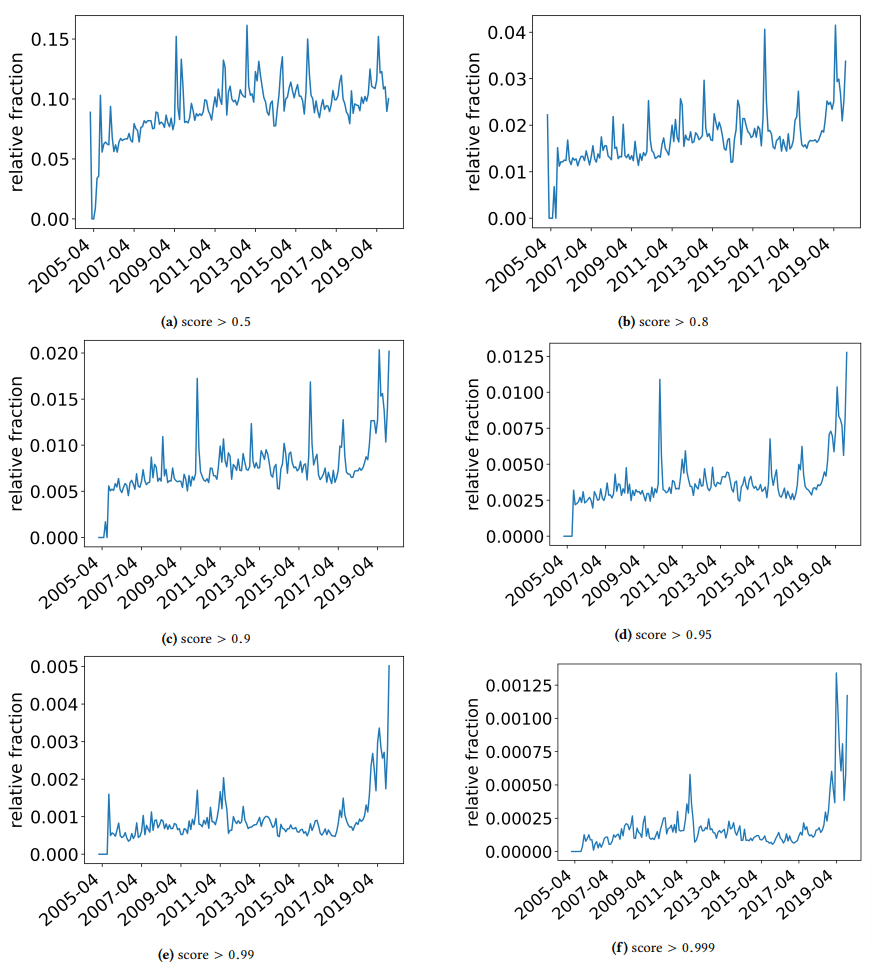
각 그래프 아래의 점수를 확인하는 것이 중요합니다. 1.0으로 향하는 숫자는 콘텐츠가 스팸이라는 확신으로 이동하고 있습니다. 우리가 보고 있는 것은 2017년부터 그리고 2019년에는 급격하게 증가한 저품질 문서가 널리 퍼졌다는 것입니다.
또한 그들은 저품질 콘텐츠의 영향이 일부 부문에서 다른 부문보다 더 높다는 것을 발견했습니다(점수가 높을수록 스팸 가능성이 높다는 것을 기억함).
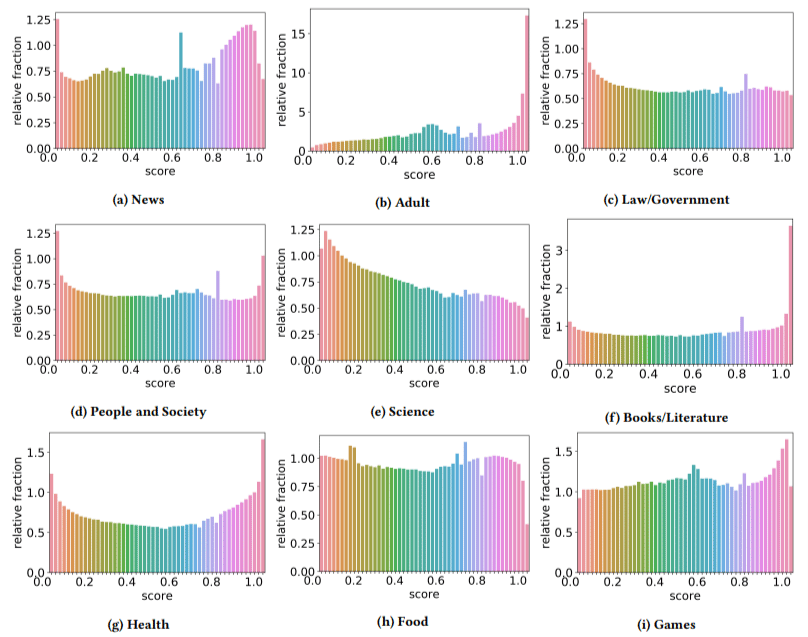
나는 이것들 중 몇 가지에 내 머리를 긁었다. 성인은 분명히 이해가 되었습니다.
하지만 책과 문학은 조금 놀랐습니다. 그리고 건강도 마찬가지였습니다. 저자가 비아그라 및 기타 "성인 건강 제품" 사이트를 "건강"으로, 에세이 팜을 "문학"으로 언급하기 전까지는 말입니다.
그들의 발견
2019년 섹터 및 급증에 대해 논의한 내용 외에도 저자는 특히 ChatGPT와 같은 도구에 의존하기 시작하면서 SEO가 배울 수 있고 염두에 두어야 할 여러 가지 흥미로운 사항을 발견했습니다.
- 저품질 콘텐츠는 길이가 짧은 경향이 있습니다(최대 3,000자).
- 텍스트가 기계에 의해 작성되었는지 여부를 결정하도록 훈련된 탐지 시스템은 낮은 수준과 높은 수준의 콘텐츠를 잘 분류합니다.
- 그들은 순위를 매기기 위해 설계된 우리의 콘텐츠를 특정 범인이라고 부르지만, 우리 모두가 거기에 있으면 안 된다는 것을 알고 있는 쓰레기를 언급하고 있는 것 같습니다.
저자는 이것이 최후의 해결책이라고 주장하는 것이 아니라 오히려 출발점이며 지난 몇 년 동안 기준을 앞으로 이동했다고 확신합니다.
AI 생성 콘텐츠에 대한 참고 사항
언어 모델도 수년에 걸쳐 발전했습니다. 이 논문이 작성될 당시 GPT-3가 존재했지만, 그들이 사용하고 있던 탐지기는 상당히 열등한 모델인 GPT-2를 기반으로 했습니다.
GPT-4가 곧 출시될 가능성이 높으며 Google의 Sparrow는 올해 후반에 출시될 예정입니다. 즉, 전장의 양쪽(콘텐츠 생성기 대 검색 엔진)에서 기술이 향상될 뿐만 아니라 조합이 더 쉬워질 것입니다.
Google에서 Sparrow 또는 GPT-4로 만든 콘텐츠를 감지할 수 있나요? 아마도.
하지만 Sparrow로 생성한 다음 재작성 프롬프트와 함께 GPT-4로 보낸다면 어떨까요?
기억해야 할 또 다른 요소는 이 백서에서 사용된 기술이 자동 회귀 모델을 기반으로 한다는 것입니다. 간단히 말해서, 그들은 그 단어가 선행하는 단어에 주어질 것이라고 예측하는 것을 기반으로 단어에 대한 점수를 예측합니다.
모델이 더 높은 수준의 정교함을 발전시키고 한 단어 다음에 다른 단어가 아닌 한 번에 완전한 아이디어를 생성하기 시작하면 AI 감지가 미끄러질 수 있습니다.
반면에 단순히 쓰레기 콘텐츠의 탐지가 확대되어야 합니다. 이는 승자가 될 유일한 "저품질" 콘텐츠가 AI 생성 콘텐츠임을 의미할 수 있습니다.
이 기사에 표현된 의견은 게스트 작성자의 의견이며 반드시 검색 엔진 랜드가 아닙니다. 교직원 저자는 여기에 나열됩니다.