
하둡 생태계와 그 구성요소
게시 됨: 2015-04-23빅데이터는 2008년부터 IT 업계에 떠도는 화두입니다. 소셜 네트워크, 제조, 소매, 주식, 통신, 보험, 은행, 의료 산업에서 생성되는 데이터의 양은 상상을 초월합니다.
하둡이 등장하기 전에는 빅데이터를 저장하고 처리하는 것이 큰 도전이었다. 그러나 이제 Hadoop을 사용할 수 있게 되면서 기업은 빅 데이터가 비즈니스에 미치는 영향과 이 데이터를 이해하는 것이 성장을 이끄는 방식을 깨달았습니다. 예를 들어:
• 은행 부문은 충성도가 높은 고객, 대출 불이행자 및 사기 거래를 더 잘 이해할 수 있습니다.
• 소매 부문은 이제 수요를 예측하기에 충분한 데이터를 보유하고 있습니다.
• 제조 부문은 품질 테스트를 위해 값비싼 메커니즘에 의존할 필요가 없습니다. 센서 데이터를 캡처하고 분석하면 많은 패턴이 드러날 것입니다.
• 전자 상거래, 소셜 네트워크는 고객의 관심사에 따라 페이지를 개인화할 수 있습니다.
• 주식 시장은 엄청난 양의 데이터를 생성하며, 때때로 상관 관계를 통해 아름다운 통찰력을 얻을 수 있습니다.
빅 데이터에는 유용하고 통찰력 있는 응용 프로그램이 많이 있습니다.
Hadoop은 빅 데이터 처리에 대한 정답입니다. Hadoop 생태계는 비즈니스 문제를 해결하는 데 능숙한 기술의 조합입니다.
주어진 비즈니스 문제에 대한 올바른 솔루션을 구축하기 위해 Hadoop Ecosytem의 구성 요소를 이해하겠습니다.
하둡 생태계:
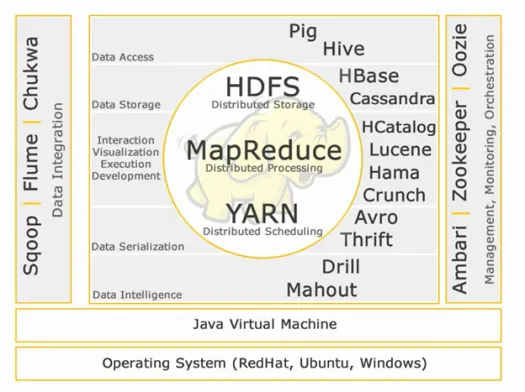

코어 하둡:
HDFS:
HDFS는 대용량, 속도 및 다양성으로 빅 데이터 세트를 관리하기 위한 Hadoop Distributed File System의 약자입니다. HDFS는 마스터 슬레이브 아키텍처를 구현합니다. 마스터는 이름 노드이고 슬레이브는 데이터 노드입니다.
특징:
• 확장성
• 믿을 수있는
• 상품 하드웨어
HDFS는 빅 데이터 스토리지로 잘 알려져 있습니다.
맵 축소:
Map Reduce는 대용량 분산 데이터를 처리하도록 설계된 프로그래밍 모델입니다. 플랫폼은 더 나은 예외 처리를 위해 Java를 사용하여 구축되었습니다. Map Reduce에는 Job tracker와 Task Tracker의 두 가지 데몬이 포함되어 있습니다.
특징:
• 함수형 프로그래밍.
• 빅 데이터에서 매우 잘 작동합니다.
• 대규모 데이터 세트를 처리할 수 있습니다.
Map Reduce는 빅 데이터 처리로 알려진 주요 구성 요소입니다.
실:
YARN은 Yet Another Resource Negotiator의 약자입니다. MapReduce 2(MRv2)라고도 합니다. MRv1에서 Job Tracker의 두 가지 주요 기능인 자원 관리 및 작업 스케줄링/모니터링은 ResourceManager, NodeManager 및 ApplicationMaster인 별도의 데몬으로 분할됩니다.
특징:
• 더 나은 리소스 관리.
• 확장성
• 클러스터 리소스의 동적 할당.
데이터 접근:
돼지:
Apache Pig는 간단한 임시 데이터 분석 프로그램으로 대규모 데이터 세트를 분석하기 위해 MapReduce 위에 구축된 고급 언어입니다. Pig는 데이터 흐름 언어라고도 합니다. 파이썬과 매우 잘 통합되어 있습니다. 처음에는 야후에서 개발했습니다.
돼지의 두드러진 특징:
• 프로그래밍 용이성
• 최적화 기회
• 확장성.
Pig 스크립트는 내부적으로 맵 축소 프로그램으로 변환됩니다.

하이브:
Apache Hive는 데이터 요약, 쿼리 및 분석을 제공하기 위해 Hadoop을 기반으로 구축된 또 다른 고급 쿼리 언어 및 데이터 웨어하우스 인프라입니다. 처음에는 야후에서 개발했으며 오픈 소스로 만들었습니다.
하이브의 두드러진 특징:
• HQL이라는 쿼리 언어와 같은 SQL.
• 더 빠른 데이터 처리를 위한 파티셔닝 및 버킷팅.
• Tableau와 같은 시각화 도구와의 통합.
Hive 쿼리는 내부적으로 맵 축소 프로그램으로 변환됩니다.
빅데이터 분석가가 되고 싶다면 이 두 가지 고급 언어는 반드시 알아야 합니다!!

데이터 저장고:
H베이스:
Apache HBase는 Hadoop 상용 하드웨어 시스템 위에 수십억 개의 행과 수백만 개의 열이 있는 대형 테이블을 호스팅하기 위해 구축된 NoSQL 데이터베이스입니다. 빅 데이터에 대한 임의의 실시간 읽기/쓰기 액세스가 필요할 때 Apache Hbase를 사용하십시오.
특징:
• 엄격하게 일관된 읽기 및 쓰기. 메모리 작업에서.
• 클라이언트 액세스를 위해 사용하기 쉬운 Java API.
• 돼지, 벌집 및 sqoop과 잘 통합됩니다.
• CAP 정리에서 일관성 있고 파티션 허용 시스템입니다.

카산드라:
Cassandra는 선형 확장성과 고가용성을 위해 설계된 NoSQL 데이터베이스입니다. Cassandra는 키-값 모델을 기반으로 합니다. Facebook에서 개발했으며 쿼리에 대한 더 빠른 응답으로 유명합니다.
특징:
• 열 인덱스
• 비정규화 지원
• 구체화된 뷰
• 강력한 내장 캐싱.

상호 작용 - 시각화 - 실행 - 개발:
카탈로그:
HCatalog는 다른 Hadoop 애플리케이션에 대한 하이브 메타데이터의 통합을 제공하는 테이블 관리 계층입니다. Apache pig, Apache MapReduce 및 Apache Hive와 같은 다양한 데이터 처리 도구를 사용하는 사용자는 데이터를 보다 쉽게 읽고 쓸 수 있습니다.

특징:
• 다양한 형식에 대한 표 보기.
• 데이터 가용성 알림.
• 외부 시스템이 메타데이터에 액세스하기 위한 REST API.
루신:
Apache LuceneTM은 완전히 Java로 작성된 고성능의 완전한 기능을 갖춘 텍스트 검색 엔진 라이브러리입니다. 전체 텍스트 검색, 특히 크로스 플랫폼이 필요한 거의 모든 애플리케이션에 적합한 기술입니다.
특징:
• 확장성, 고성능 – 인덱싱.
• 강력하고 정확하며 효율적인 검색 알고리즘.
• 크로스 플랫폼 솔루션.
하마:
Apache Hama는 BSP(Bulk Synchronous Parallel) 컴퓨팅 기반의 분산 프레임워크입니다. 행렬, 그래프 및 네트워크 알고리즘과 같은 방대한 과학적 계산을 수행할 수 있고 잘 알려져 있습니다.
특징:
• 간단한 프로그래밍 모델
• 반복 알고리즘에 적합
• YARN 지원
• 협업 필터링 비지도 머신 러닝.
• K-평균 클러스터링.
결정적 시기:
Apache crunch는 간단하고 효율적인 MapReduce 프로그램을 파이프라이닝하기 위해 구축되었습니다. 이 프레임워크는 MapReduce 파이프라인을 작성, 테스트 및 실행하는 데 사용됩니다.
특징:
• 개발자 중심.
• 최소한의 추상화
• 유연한 데이터 모델.
데이터 직렬화:
아브로:
Apache Avro는 언어 중립적인 데이터 직렬화 프레임워크입니다. 언어 이식성을 위해 설계되어 데이터가 언어를 읽고 쓸 수 있는 것보다 잠재적으로 오래 사용할 수 있습니다.

절약:
Thrift는 Hadoop에 구축된 기술과 상호 작용하기 위한 인터페이스를 구축하기 위해 개발된 언어입니다. 다양한 언어에 대한 서비스를 정의하고 생성하는 데 사용됩니다.
데이터 인텔리전스:
송곳:
Apache Drill은 Hadoop 및 NoSQL용 저지연 SQL 쿼리 엔진입니다.
특징:
• 민첩성
• 유연성
• 친숙함.

코끼리 부리는 사람:
Apache Mahout은 빅 데이터에 대한 예측 분석을 구축하도록 설계된 확장 가능한 기계 학습 라이브러리입니다. Mahout은 이제 메모리 컴퓨팅 속도를 높이기 위해 Apache Spark를 구현했습니다.
특징:
• 협업 필터링.
• 분류
• 클러스터링
• 차원 축소

데이터 통합:
아파치 스쿱:

Apache Sqoop은 관계형 데이터베이스와 Hadoop 간의 대량 데이터 전송을 위해 설계된 도구입니다.
특징:
• HDFS에서 가져오기 및 내보내기.
• Hive에서 가져오기 및 내보내기.
• HBase로 가져오기 및 내보내기.
아파치 플룸:
Flume은 대량의 로그 데이터를 효율적으로 수집, 집계 및 이동할 수 있는 안정적이고 사용 가능한 분산 서비스입니다.
특징:
• 견고함
• 내결함성
• 스트리밍 데이터 흐름을 기반으로 하는 간단하고 유연한 아키텍처.

아파치 추콰:
대규모 분산 파일 시스템을 모니터링하는 데 사용되는 확장 가능한 로그 수집기.
특징:
• 수천 개의 노드로 확장됩니다.
• 안정적인 배송.
• 데이터를 무기한 저장할 수 있어야 합니다.

관리, 모니터링 및 오케스트레이션:
아파치 암바리:
Ambari는 Apache Hadoop 클러스터를 프로비저닝, 관리 및 모니터링하기 위한 인터페이스를 제공하여 Hadoop 관리를 단순화하도록 설계되었습니다.
특징:
• Hadoop 클러스터를 프로비저닝합니다.
• 하둡 클러스터를 관리합니다.
• Hadoop 클러스터를 모니터링합니다.

아파치 사육사:
Zookeeper는 구성 정보를 유지 관리하고, 이름을 지정하고, 분산 동기화를 제공하고, 그룹 서비스를 제공하도록 설계된 중앙 집중식 서비스입니다.
특징:
• 직렬화
• 원자성
• 신뢰성
• 간단한 API

아파치 오지:
Oozie는 Apache Hadoop 작업을 관리하는 워크플로 스케줄러 시스템입니다.
특징:
• 확장 가능하고 안정적이며 확장 가능한 시스템.
• Map-Reduce, Hive, Pig 및 Sqoop과 같은 여러 유형의 Hadoop 작업을 지원합니다.
• 간단하고 사용하기 쉽습니다.

다음 기사에서 구성 요소에 대해 자세히 논의할 것입니다. 계속 지켜봐 주세요.