비즈니스의 속도와 품질을 보장하는 IT 메트릭
게시 됨: 2021-05-04이 기사에서
무엇이든 지표는 프로세스의 효율성을 모니터링하고 잠재적인 문제를 식별하며 가능한 개입을 이해하는 데 필수적입니다. 올바른 메트릭을 사용하면 마케팅과 마찬가지로 정보 기술에서도 더 나은 성과를 얻을 수 있습니다. 그 이유를 알아보자.
"권력은 통제할 수 없는 것이 아니다" 는 제가 거의 20년 전에 일했던 유명 회사의 슬로건이었습니다. 여기저기서 보았고, 마음에 들었고, 머리에서 지울 수 없었습니다. 아마도 이러한 이유로 나는 전문가들 사이에서 잘 알려져 있고 속도와 품질 의 균형을 기반으로 하는 일련의 IT 메트릭의 MailUp 구현을 구성하는 도전을 기꺼이 받아들였습니다.
IT 메트릭은 무엇이며 무엇을 위한 것입니까?
IT 메트릭이란 무엇입니까? 정보 기술 세계에서 중요한 변수를 측정하여 프로세스를 제어하고 개선하는 데 도움이 됩니다. 모든 복잡한 프로세스와 마찬가지로 기술은 제한된 수의 측정 가능한 수량을 정렬하는 데 있습니다. 이는 우리 제품의 프로세스와 성능에 대한 좋은 지표가 될 뿐만 아니라 가치를 변화 시키는 표적 개입을 통해 두 가지 측면 을 모두 개선할 수 있게 해줍니다 .
복잡한? 약간— 이 유형의 활성 제어에 대한 최상의 측정항목을 식별하는 것이 쉽지 않기 때문입니다. 내부적으로 정의된 몇 가지 메트릭을 시도한 후 "가속 - 가속화: 린 소프트웨어 및 DevOps의 과학"에 아주 잘 요약되어 있는 메트릭을 사용하기로 결정했습니다. 이는 2012년부터 DevOps 연례 보고서 현황 보고서의 주요 주제 중 하나이기도 합니다.
개선 조치: IT 메트릭이 비즈니스 성과를 가속화하는 방법
수천 개의 기업을 대상으로 한 수년간의 광범위한 연구 결과, 앞서 언급한 간행물의 저자 는 디지털 부문 기업의 우수한 IT 성과와 동등하게 우수한 비즈니스 결과 사이에 직접적인 상관 관계가 있음을 확인합니다 . 이 연구에서는 모든 최고 IT 성과(가장 크고 가장 전위적인 기업)가 우수한 결과를 달성하는 5가지 주요 지표 를 확인했습니다. 이들 회사는 동일한 지표를 채택했으며 5가지 지표 모두에서 "엘리트 성과자"의 가치를 일치시켰습니다. 실제로, 그들은 다른 것보다 훨씬 더 나은 성장률을 보였고, 이는 KPI의 IT 세트를 구현하는 것이 얼마나 매우 효과적이고 중요한지를 확인시켜줍니다. 요컨대, 기술 성과의 우수성 은 비즈니스 수준에서 성과를 가속화할 수 있는 요소가 됩니다.
비즈니스의 속도와 품질을 보장하는 IT 메트릭
지금까지 이야기한 5가지 IT 메트릭은 속도와 품질이라는 정말 간단한 개념을 기반으로 합니다 . 메시지는 다음과 같습니다. 고객에게 신속하고 지속적으로 자주 가치를 전달합니다 . y. 속도가 빠를수록 실수할 위험이 커집니다. 또한 오류 빈도와 오작동 후 필요한 복원 시간을 주시해야 합니다.
이 개념을 숫자로 변환 하여 5개의 측정 가능한 수량을 메트릭으로 얻 습니다.
- 변경 리드 타임 (LTFC): 프로세스 시작부터 고객에게 제공될 때까지의 평균 시간("생산 중").
- 배포 빈도 : 프로덕션에서 뉴스 또는 업데이트가 릴리스되는 빈도.
- 변경 실패율 (CFR): 최근 업데이트로 인해 발생한 문제를 복구하기 위한 프로덕션 업데이트 수.
- 평균 복구 시간 (MTTR): 심각한 프로덕션 문제가 고객에게 영향을 미친 후 평균 복구 시간. 그리고
- 가용성 : 플랫폼 서비스가 완전히 사용 가능한 시간의 백분율(모든 복구 시간의 합계를 뺀 값).
MailUp의 IT 메트릭
MailUp 에서는 2020년 9월부터 이러한 지표를 사용하고 있습니다. 자동 측정 도구를 통해 다음과 같은 연속 프로세스를 설정하여 수행했습니다.

- 우리는 진행 상황을 모니터링합니다.
- 우리는 목표를 설정합니다 ; 그리고
- 우리는 거기에 도달하기 위한 행동을 식별합니다.
급격한 속도 향상은 낮은 품질과 연결될 수 있으므로 주의가 필요합니다.
메트릭이 프로세스를 개선하기 위한 간접적인 지표라는 사실을 잊는 것이 일반적입니다. 핵심은 측정 자체가 목적이 아니라는 것입니다. 오히려 중요한 것은 측정을 변경할 때 프로세스와 제품에 미치는 영향입니다.
수치와 관련 하여 MailUp에서 이러한 메트릭을 계산하는 방법을 자세히 살펴보겠습니다.
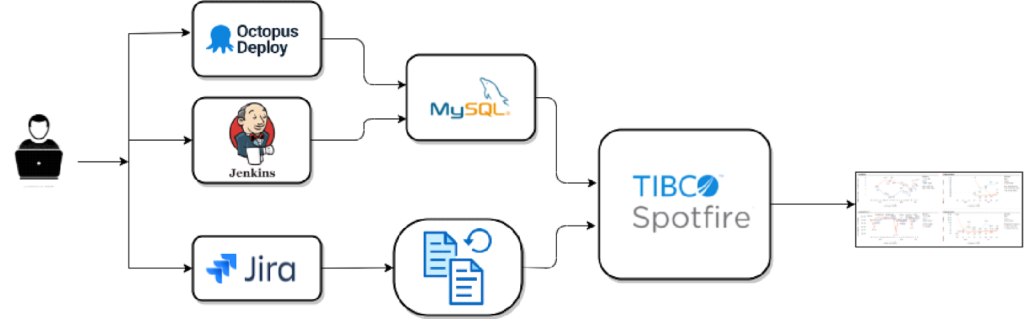
변경 리드 타임 은 Jira 문제에 해당하는 스토리(또는 작업) 가 처리 시작부터 게시까지 걸리는 마지막 3개월 평균 기간으로 계산합니다 . 여기에서 Atlassian Jira 제품군이 도움이 됩니다. 이를 통해 스토리의 "상태에 있는 시간", 즉 워크플로의 각 전환에 대해 문제가 특정 상태에 있었던 시간을 측정할 수 있습니다. 가져오고 집계된 데이터는 Jira Control Chart 또는 Tibco Spotfire로 만든 것과 같은 임시 대시보드를 통해 볼 수 있습니다.
문제는 모든 프로젝트의 빌딩 블록을 형성합니다. 이는 해결해야 할 문제(예: 버그) 또는 팀 또는 일부 구성원의 일반 작업을 나타낼 수 있습니다. 사실 Jira 소프트웨어는 문제를 모니터링할 뿐만 아니라 전체 워크플로를 추적하기 위해 만들어졌습니다. MailUp에서는 Jira의 4가지 표준 문제 유형을 사용합니다. 스토리(사용자가 관심을 가질 만한 것), 버그(해결해야 할 문제), 작업(완료해야 할 것) 및 에픽(한 형식으로 구성할 수 있는 큰 이야기 적은 수의 이야기).
MailUp에서는 배포 리드 타임, 즉 프로덕션의 마지막 변경에서 소스 코드까지의 시간 도 측정 합니다 .
배포 빈도 및 CFR 의 경우 자동 프로덕션 릴리스 프로세스 (배포 파이프라인) 를 데이터베이스 측정항목과 관련된 정보를 기록하는 흐름과 통합했습니다 . 프로덕션 환경에 개입하는 기술자는 일반 릴리스인지, 핫픽스(빠른 수정) 또는 롤백(이전 버전 복원)인지 지정하기만 하면 됩니다.
MTTR 및 가용성은 "사고"의 정의를 기반으로 합니다 . 내부적으로 우리는 이것을 특정 임계값 이상의 영향과 심각도로 생산 중단으로 정의했습니다. 각 사건에 대해 Atlassian Jira에서 "사건 양식"을 작성해야 합니다 . 기간, 원인, 결과, 영향 및 해결 유형과 같은 다양한 요소를 나타냅니다. 그런 다음 사고 카드의 데이터는 자동 프로세스에 의해 추출되어 그래픽으로 표시됩니다.
추세는 이러한 각 메트릭에 대한 시간 경과에 따른 성능과 관련이 있습니다. 우리는 고립된 피크 또는 너무 큰 평가 창의 관성과 같은 오해의 소지가 있는 요소를 컨텍스트화하고 보상하기 위한 참조로 지난 3~4개월 동안의 이동 평균 을 사용하는 것이 매우 유용하다는 것을 알게 되었습니다.
이 측정항목으로 충분합니까? 우리의 미래 지평에 이미 두 단계 가 더 있더라도 기술적인 건강 상태를 이해하기 위한 훌륭한 출발점이 될 것입니다.
- 이러한 메트릭을 플랫폼 페이지에 대한 액세스 속도와 같은 다른 주요 측정과 통합합니다. 그리고
- "드릴다운"(심층 분석) 하위 메트릭을 통해 세부적으로 기존 지표 에 대해 더 높은 수준의 특정성을 도입합니다 .
결론
이 간략한 개요는 IT 메트릭 세트를 사용하여 전반적인 비즈니스 성과를 높이는 이면의 의미와 이점을 정확히 보여줍니다. 측정항목과 측정 방법에 대해 자세히 알아보려면 이 링크를 클릭하세요!