
TW-BERT: 엔드 투 엔드 검색어 가중치와 Google 검색의 미래
게시 됨: 2023-09-14Seth Godin이 2005년에 쓴 것처럼 검색은 어렵습니다.
SEO가 어렵다고 생각한다면, 다음과 같은 세상에서 검색 엔진을 구축하려고 한다고 상상해보세요.
- 사용자는 매우 다양하며 시간이 지남에 따라 선호도도 변경됩니다.
- 그들이 검색에 접근하는 기술은 나날이 발전하고 있습니다.
- 경쟁자들은 끊임없이 당신의 뒤를 바짝 쫓고 있습니다.
또한 알고리즘을 조작 하려는 성가신 SEO를 상대하면서 방문자를 위한 최선의 최적화 방법에 대한 통찰력을 얻을 수 있습니다.
그러면 상황이 훨씬 더 어려워질 것입니다.
이제 발전하기 위해 의지해야 하는 주요 기술에 한계가 있고, 더 나쁜 경우 막대한 비용이 드는 경우를 상상해 보십시오.
글쎄, 당신이 최근에 출판된 논문 "End-to-End Query Term Weighting"의 저자 중 한 명이라면 이것이 빛을 발할 기회라고 생각할 것입니다.
엔드투엔드 검색어 가중치란 무엇인가요?
엔드 투 엔드 쿼리 용어 가중치는 수동으로 프로그래밍되거나 기존의 용어 가중치 체계 또는 기타 독립적 모델에 의존하지 않고 쿼리의 각 용어의 가중치가 전체 모델의 일부로 결정되는 방법을 나타냅니다.
그것은 어떻게 생겼나요?
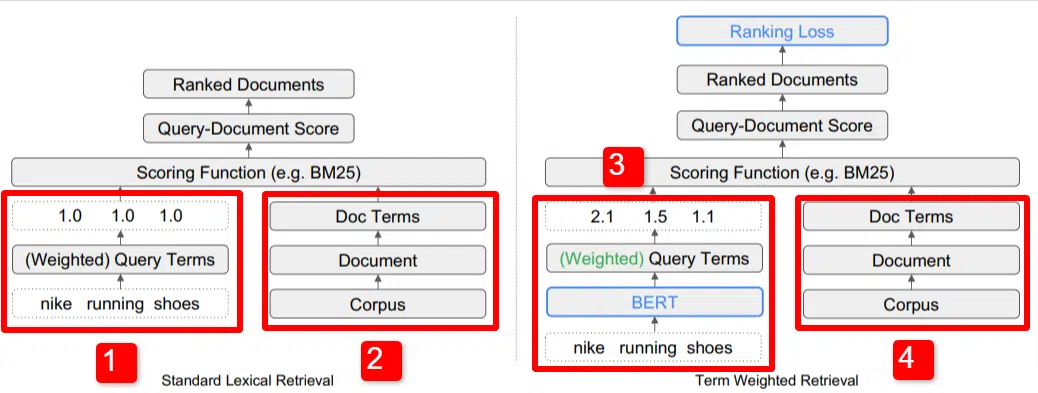
여기서는 논문에 설명된 모델의 주요 차별화 요소 중 하나를 보여줍니다(구체적으로 그림 1).
표준 모델(2)의 오른쪽에는 제안된 모델(4)과 동일한 내용이 표시됩니다. 이는 코퍼스(인덱스의 전체 문서 집합)로 문서로 연결되고 용어로 연결됩니다.
이는 시스템의 실제 계층 구조를 보여 주지만, 위에서 아래로 거꾸로 생각해도 무방합니다. 우리에게는 조건이 있습니다. 우리는 해당 용어가 포함된 문서를 찾습니다. 그 문서는 우리가 알고 있는 모든 문서의 집합체입니다.
표준 정보 검색(IR) 아키텍처의 왼쪽 하단(1)에는 BERT 레이어가 없다는 것을 알 수 있습니다. 그림에 사용된 쿼리(나이키 운동화)가 시스템에 입력되고 가중치는 모델과 독립적으로 계산되어 전달됩니다.
여기 그림에서는 가중치가 쿼리의 세 단어 간에 동일하게 전달됩니다. 그러나 반드시 그럴 필요는 없습니다. 이는 단순히 기본값이며 좋은 예시입니다.
이해해야 할 중요한 점은 가중치가 모델 외부에서 할당되어 쿼리와 함께 입력된다는 것입니다. 이것이 왜 중요한지 잠시 후에 다루겠습니다.
오른쪽의 용어 가중치 버전을 보면 "nike running Shoes"라는 쿼리가 BERT(구체적으로는 Term Weighting BERT 또는 TW-BERT)에 입력되어 가중치를 할당하는 데 사용되는 것을 볼 수 있습니다. 해당 쿼리에 가장 잘 적용됩니다.
거기에서 두 가지 모두 유사한 경로를 따르며 채점 기능이 적용되고 문서 순위가 지정됩니다. 하지만 새 모델에는 중요한 최종 단계가 있습니다. 이것이 바로 순위 손실 계산의 핵심입니다.
위에서 언급한 이 계산은 모델 내에서 결정되는 가중치를 매우 중요하게 만듭니다. 이를 가장 잘 이해하기 위해 손실 함수에 대해 잠시 논의해 보겠습니다. 이는 여기서 무슨 일이 일어나고 있는지 실제로 이해하는 데 중요합니다.
손실 함수란 무엇입니까?
기계 학습에서 손실 함수는 기본적으로 손실이 0에 최대한 가까워지도록 학습하는 시스템이 얼마나 잘못되었는지 계산하는 것입니다.
주택 가격을 결정하기 위해 설계된 모델을 예로 들어 보겠습니다. 집에 대한 모든 통계를 입력하여 가치가 $250,000로 나왔지만 집이 $260,000에 팔렸다면 그 차이는 손실(절대 가치)로 간주됩니다.
수많은 예를 통해 모델은 최상의 결과를 얻을 때까지 주어진 매개변수에 서로 다른 가중치를 할당하여 손실을 최소화하도록 학습됩니다. 이 경우 매개변수에는 평방 피트, 침실, 마당 크기, 학교와의 근접성 등이 포함될 수 있습니다.
이제 검색어 가중치로 돌아가서
위의 두 가지 예를 되돌아보면, 우리가 집중해야 할 것은 순위 손실 계산의 하위 퍼널 용어에 가중치를 제공하는 BERT 모델의 존재입니다.
다르게 말하면, 기존 모델에서는 항의 가중치가 모델 자체와 독립적으로 수행되어 전체 모델의 성능에 응답할 수 없었습니다. 가중치를 개선하는 방법을 배울 수 없습니다.
제안된 시스템에서는 이것이 변경됩니다. 가중치는 모델 자체 내에서 수행되므로 모델이 성능을 개선하고 손실 함수를 줄이려고 할 때 용어 가중치를 방정식으로 가져오는 데 이러한 추가 다이얼이 있습니다. 문자 그대로.

엔그램
TW-BERT는 단어가 아닌 ngram으로 작동하도록 설계되었습니다.
논문의 저자는 "nike running shoe"라는 검색어에서 단순히 단어에 가중치를 부여하면 nike, running 및 Shoes라는 단어가 언급된 페이지가 심지어 높은 순위를 차지할 수 있다는 점을 지적하면서 단어 대신 ngram을 사용하는 이유를 잘 설명합니다. '나이키 런닝 양말'과 '스케이트 신발'을 논하고 있다면요.
기존 IR 방법은 쿼리 통계와 문서 통계를 사용하며 이와 같은 문제나 유사한 문제가 있는 페이지를 표시할 수 있습니다. 이 문제를 해결하려는 과거의 시도는 동시 발생과 순서에 중점을 두었습니다.
이 모델에서 ngram은 이전 예의 단어처럼 가중치가 부여되므로 다음과 같이 끝납니다.
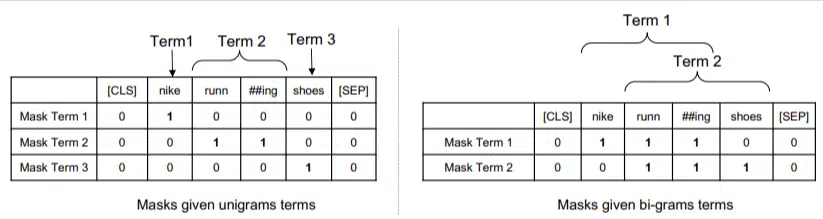
왼쪽에서는 쿼리에 유니그램(1단어 ngram)으로 가중치가 부여되고 오른쪽에서는 바이그램(2단어 ngram)으로 가중치가 부여되는 방식을 볼 수 있습니다.
시스템에는 가중치가 내장되어 있기 때문에 빈도와 같은 통계에만 의존하는 대신 모든 순열을 훈련하여 최상의 ngram과 각 순열에 대한 적절한 가중치를 결정할 수 있습니다.
제로샷
이 모델의 중요한 특징은 제로 쇼트 작업에서의 성능입니다. 저자는 다음을 테스트했습니다.
- MS MARCO 데이터 세트 – 문서 및 구절 순위를 위한 Microsoft 데이터 세트
- TREC-COVID 데이터 세트 – COVID 기사 및 연구
- Robust04 – 뉴스 기사
- 공통 핵심 – 교육 기사 및 블로그 게시물
소수의 평가 쿼리만 있었고 미세 조정에는 아무것도 사용하지 않았으므로 모델이 이러한 도메인에서 문서의 순위를 구체적으로 지정하도록 훈련되지 않았다는 점에서 이는 제로 샷 테스트가 되었습니다. 결과는 다음과 같습니다.
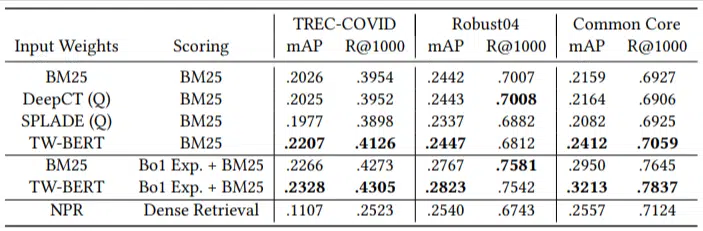
대부분의 작업에서 뛰어난 성능을 보였으며 더 짧은 쿼리(1~10단어)에서 가장 좋은 성능을 보였습니다.
그리고 그것은 플러그 앤 플레이입니다!
좋습니다. 지나치게 단순화했을 수도 있지만 저자는 다음과 같이 썼습니다.
“TW-BERT를 검색 엔진 스코어러와 정렬하면 이를 기존 프로덕션 애플리케이션에 통합하는 데 필요한 변경 사항이 최소화되는 반면, 기존 딥 러닝 기반 검색 방법에는 추가 인프라 최적화 및 하드웨어 요구 사항이 필요합니다. 학습된 가중치는 표준 어휘 검색기 및 쿼리 확장과 같은 기타 검색 기술에서 쉽게 활용할 수 있습니다.
TW-BERT는 현재 시스템에 통합되도록 설계되었기 때문에 통합은 다른 옵션보다 훨씬 간단하고 저렴합니다.
이 모든 것이 당신에게 의미하는 바
기계 학습 모델을 사용하면 SEO로서 무엇을 할 수 있는지 예를 예측하기가 어렵습니다(Bard 또는 ChatGPT와 같은 가시적인 배포는 제외).
이 모델의 순열은 개선 및 배포 용이성(설명이 정확하다고 가정)으로 인해 의심할 여지 없이 배포될 것입니다.
즉, 이는 Google의 삶의 질 향상으로, 저렴한 비용으로 순위와 제로 샷 결과를 향상시킬 것입니다.
우리가 실제로 의지할 수 있는 것은 구현하면 더 나은 결과가 더 안정적으로 나타날 것이라는 것입니다. 이는 SEO 전문가에게 좋은 소식입니다.
이 기사에 표현된 의견은 게스트 작성자의 의견이며 반드시 Search Engine Land일 필요는 없습니다. 직원 작성자는 여기에 나열되어 있습니다.