
키워드 클러스터링 위시리스트에 있어야 할 10가지 유형의 데이터
게시 됨: 2023-06-26
모두가 키워드 클러스터에 대해 이야기하고 있습니다. 핵심은 매우 간단합니다. 관련 키워드를 함께 그룹화하는 것입니다. 쉬운 것 같죠?
일부 무료 도구는 중복을 제거하고 키워드 간의 의미론적 유사성을 찾는 데 도움이 되는 몇 가지 기본적인 자연어 처리(NLP)를 안내합니다. 거기에서 시작하는 데 아무런 문제가 없지만 필연적으로 제한됩니다. 반면에 Google은 기본 키워드 조작보다 더 많은 컨텍스트를 제공하는 페이지 데이터 및 링크를 포함하여 알고리즘에 제공할 수 있는 훨씬 더 많은 데이터를 보유하고 있습니다.
Google이 세상을 보는 방식을 진정으로 이해하려면 SERP 데이터를 수집하여 어떤 페이지가 어떤 용어에 대해 순위를 매기는지 확인해야 합니다. 대규모로 상위 10개 결과에서 겹치는 URL 수를 비교하면 어떤 SERP가 관련되어 있는지 매우 명확하게 파악할 수 있습니다. 이 방법은 최근 Nozzle, Cluster AI 등에서도 사용할 수 있는 Keyword Insights에 의해 대중화되었습니다.
수동으로 함께 그룹화했을 키워드를 발견하면 계속해서 놀라움을 금치 못하지만 Google에서는 겹치는 URL이 전혀 표시되지 않으며 그 반대의 경우도 마찬가지입니다. 이러한 경우 Google이 "올바른" 것인지 여부는 중요하지 않습니다. Google의 세상이고 우리는 그 안에 살고 있습니다.
광고를 제거하고 "SEO 에이전시"와 "SEO 회사"를 나란히 검색했을 때의 결과는 다음과 같습니다. 상위 10개 중 8개가 동일하다는 것을 알 수 있습니다!
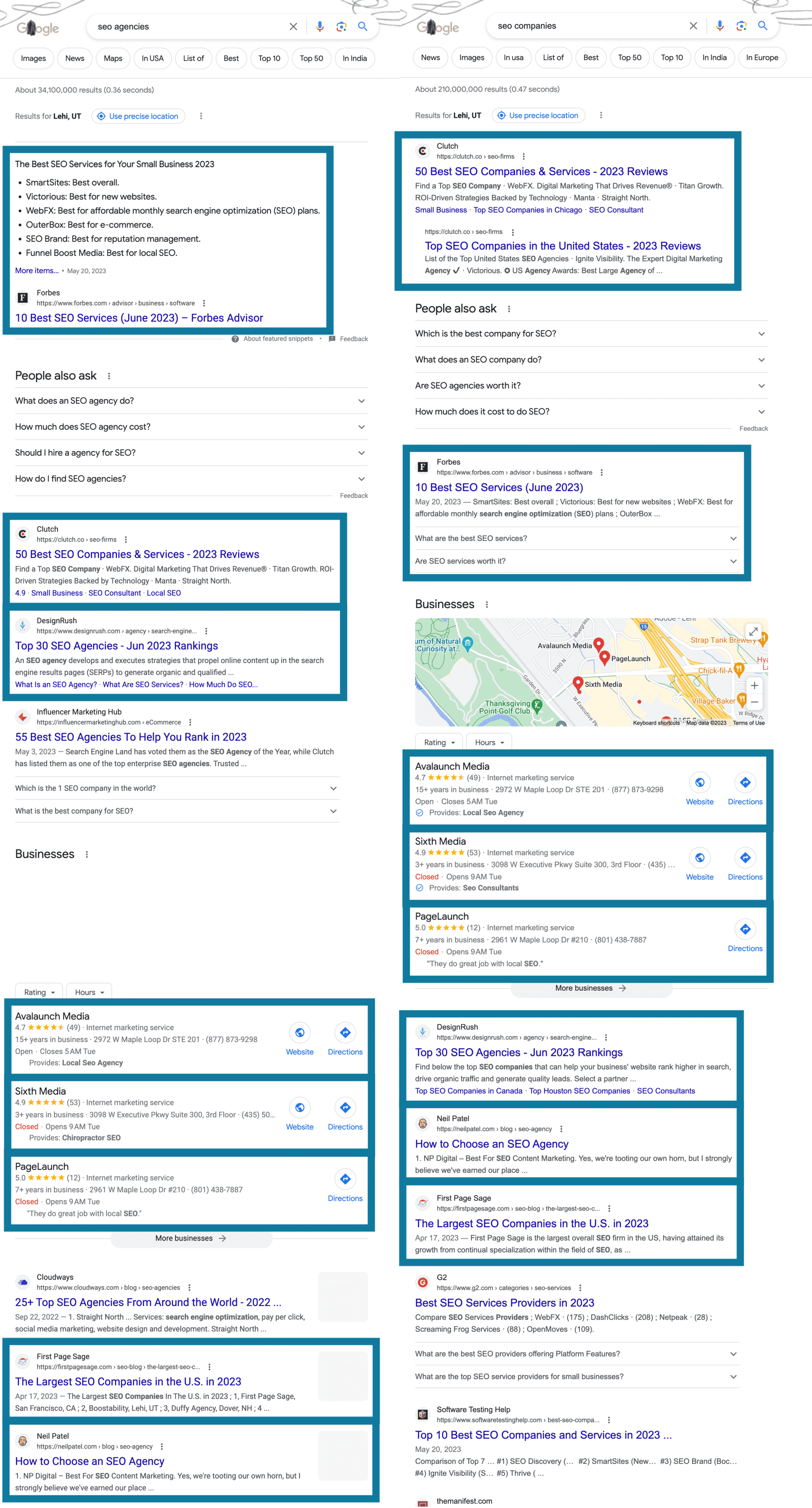
이러한 겹치는 페이지를 수동으로 찾는 것은 대규모로 수행하는 것이 거의 불가능하지만 좋은 도구에서는 사소한 일입니다. 몇 년 동안 키워드 목록을 관리하는 데 도움이 되지만 더 깊이 파고들지 못하는 다양한 도구가 있었습니다. 블록에 기본 클러스터링을 제공하는 큰 새 아이도 있지만 2,000개의 키워드 제한이 실망스럽습니다.
키워드를 자동으로 클러스터링하는 것은 훌륭하지만 여기에서 대부분의 도구가 끝납니다. 키워드 목록, 검색량 및/또는 순위가 될 수 있습니다. 다음은 키워드 클러스터의 맥락에서 매우 중요한 10가지 데이터 유형의 위시리스트입니다. 대부분은 지금까지 사용할 수 없었습니다.
- 순위 URL
- 구체화 기준
- PAA
- 자주하는 질문
- SERP 기능
- 검색 의도
- 랭킹 포지션
- 목소리의 점유율
- 엔티티
- 카테고리
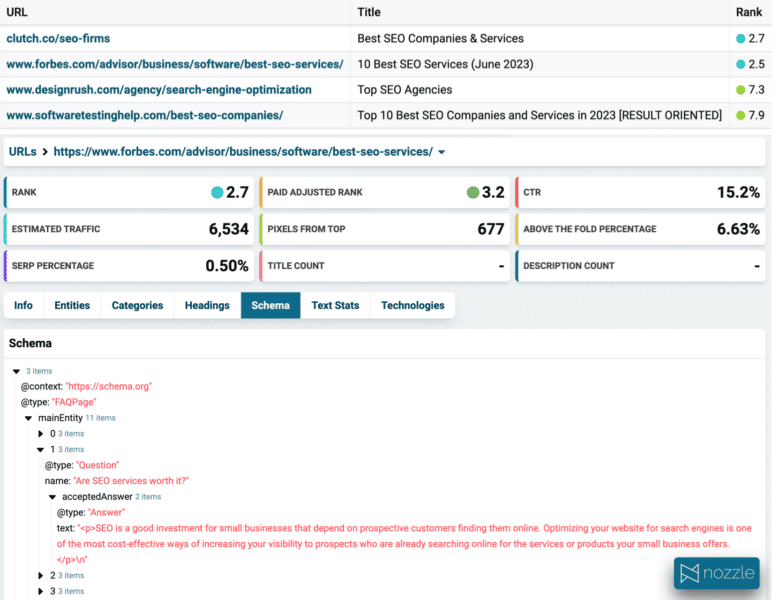
1. URL/페이지 랭킹
기존 도구는 클러스터의 모든 키워드 간에 공유되는 페이지를 정확히 표시하지 않아 Google이 보상하는 내용을 파악하기가 매우 어렵습니다. 또한 URL 수를 알면 클러스터의 강도/강도에 대한 중요한 통찰력을 얻을 수 있습니다. 위의 예에서와 같이 URL 10개 중 8개를 공유하는 것은 매우 타이트한 클러스터이며 겹치는 페이지가 3-4개만 적당히 타이트합니다.
또한 대부분의 도구는 계산을 시작하기 전에 얼마나 많은 중복 URL을 계산해야 하는지 결정해야 합니다. 이는 데이터를 보기 전에는 알기 어렵습니다. 클러스터링 프로세스를 다시 실행하기 위해 비용을 지불하지 않고 탐색하면서 이 값을 동적으로 변경할 수 있어야 합니다.
콘텐츠 작성 도구에 대한 경험이 있는 경우 단일 키워드에 대한 상위 결과를 스크랩하여 볼 수 있습니다. 클러스터의 모든 키워드에 대한 URL 순위를 스크랩하는 것이 훨씬 더 효과적입니다!
제목, 스키마 및 단어 수/학년 수준과 같은 텍스트 통계에 대한 자세한 정보를 보면 유용한 가이드가 될 수 있습니다.
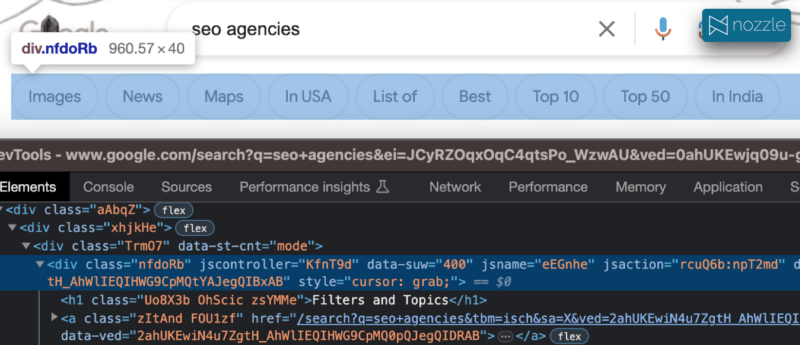
2. 세분화
관련 주제 정보에 대해 범죄적으로 간과되는 한 소스는 모든 SERP의 맨 위에 숨겨져 있으며 숨겨진 H1 태그인 "필터 및 주제"로 유용하게 레이블이 지정되어 있습니다.
이미지, 뉴스, 지도(검색에서 검색으로 변경)와 같은 몇 가지 기존 탭 다음에 Google은 일반적으로 현재 키워드 구문에 주제를 추가하거나 추가하는 관련 주제에 대한 링크를 제공합니다. 이들은 일반적으로 수동으로 식별하기 쉽고 HTML 마크업/CSS 클래스로 구별할 수도 있습니다.
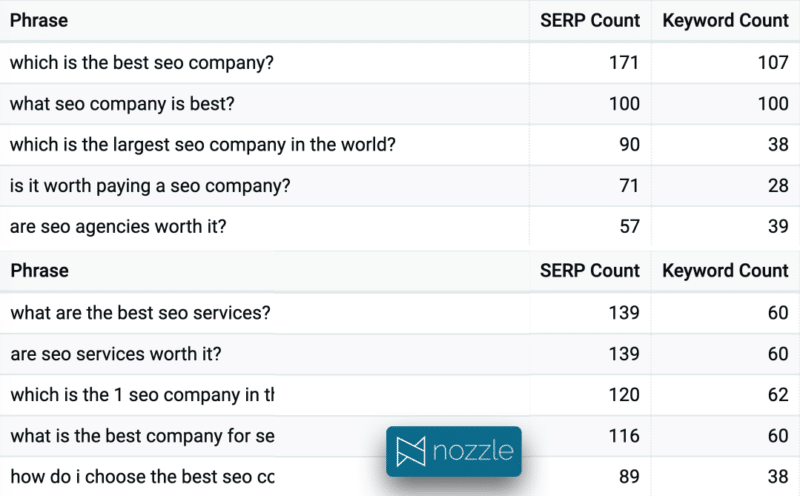
3 및 4. PAA(People Also Ask) 및 자주 묻는 질문(FAQ)
People Also Ask 질문은 Google이 콘텐츠에서 답변해야 할 청사진을 제공하므로 콘텐츠 제작자에게 금광입니다. 또한 PAA는 기존 검색 결과보다 변동성이 훨씬 크기 때문에 대부분의 도구에서 사용하는 일회성 스크랩이 아니라 시간 경과에 따라 집계하여 가장 자주 나타나는 질문을 식별할 수 있습니다. 위의 예에서 SERP는 거의 동일했지만 중복되는 질문은 없었습니다.
먼저 지난 30일 동안 이 특정 클러스터에 대한 상위 10개 질문이 있습니다. SERP 수는 그들이 나타난 SERP의 총 수이고 키워드 수는 질문을 보여준 고유 키워드의 수입니다.
다음은 PAA와 매우 유사하며 올바른 schema.org 마크업을 구현하여 사이트에 훨씬 더 많은 시각적 공간을 제공하기 위해 Google이 주제와 충분히 관련이 있다고 판단한 질문입니다.
5. SERP 기능
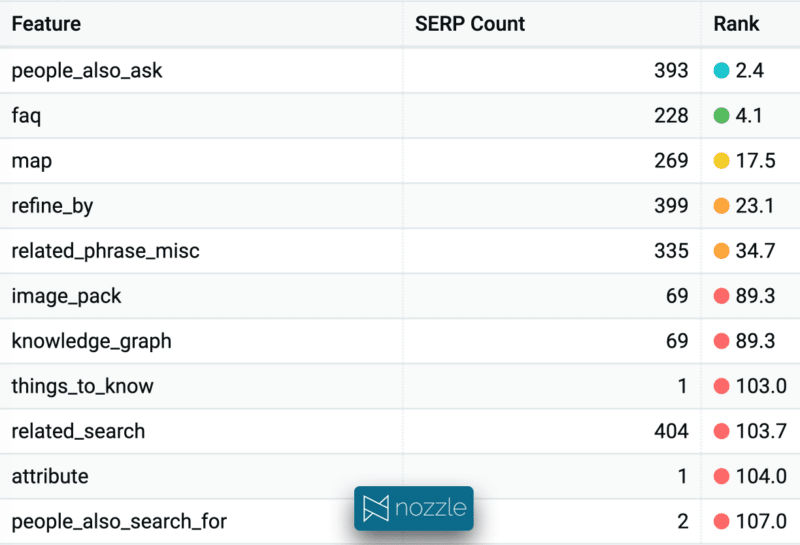
클러스터에 대한 특정 SERP 기능의 유무는 콘텐츠 전략에 영향을 미칩니다. PAA 및 FAQ는 일반적으로 SERP에서 매우 높은 가시성을 얻습니다. 이 클러스터의 경우 순위는 각각 2.5 및 4.2이므로 올바른 마크업을 추가하고 올바른 질문에 답하면 캡처할 수 있는 경우 상당한 트래픽을 유도할 수 있습니다. 지도에는 65%의 시간이 표시되며 이는 일부 분열된 의도를 나타냅니다. Things_to_know는 단일 SERP에서만 볼 수 있지만 최적화하면 성장 기회를 나타낼 수 있습니다.

6. 검색 의도
검색 의도는 전체 전략에 영향을 미치므로 혼합 의도를 포함하여 전체 클러스터 의도를 아는 것이 훌륭한 전략에 매우 중요합니다. 단일 SERP에서 여러 페이지의 순위를 매길 수 있는 기회를 식별하는 데 도움이 되도록 전체 집계 점수 외에도 검색 의도를 결과별로 사용할 수 있어야 합니다. Google Ads 측정항목과 같이 의도를 알리는 데이터가 있는 것도 유용합니다.
7. 랭킹 순위
현재 순위를 보고하는 것이 중요합니다. 현재 순위가 전혀 없는 경우 단순히 콘텐츠 격차가 있고 충분한 시사적 권위가 있으면 게시만으로 순위를 매길 수 있는 쉬운 결과가 있을 수 있습니다. 마찬가지로 순위가 8-15인 경우 약간의 추가 최적화만으로 트래픽을 10배 늘릴 수 있습니다.
픽셀 심도 및 스크롤 없이 볼 수 있는 비율과 같은 최신 메트릭을 포함하여 순위 이상의 것을 볼 수 있다면 보너스 포인트입니다.
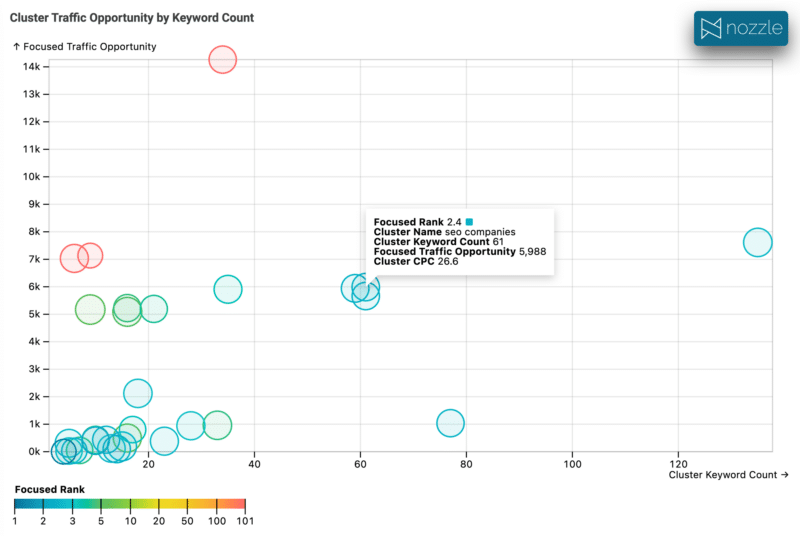
기회를 식별하기 위해 순위를 의미 있게 시각화할 수 없다면 순위를 사용할 수 있다고 해서 큰 의미가 없습니다.
이것은 CPC를 거품 반경으로, 순위를 거품 색상으로 사용하여 검색량에 대한 클러스터의 키워드 수를 보여줍니다. 기준과 일치하는 클러스터를 신속하게 식별하여 자세한 내용을 드릴할 수 있습니다.
8. 경쟁 개요/의견 공유
자신의 순위를 보는 것도 좋지만 동일한 데이터로 경쟁사를 염탐할 수 있다면 더 좋습니다. 도메인을 전환하면 경쟁자를 제압할 수 있는 신과 같은 힘을 얻을 수 있습니다.
모든 클러스터가 다르기 때문에 각 클러스터에는 서로 다른 경쟁자 세트가 있을 수 있으므로 클러스터당 음성 점유율에 대해 보고할 수 있는지 확인하십시오.
9. 법인
Google은 일치 검색 키워드를 통해 웹을 보는 것을 중단한 지 오래되었습니다. 자연어 처리(NLP)를 사용하여 페이지 콘텐츠에서 추출된 엔터티로 나타낼 수 있는 의미론적 유사성에 관한 것입니다.
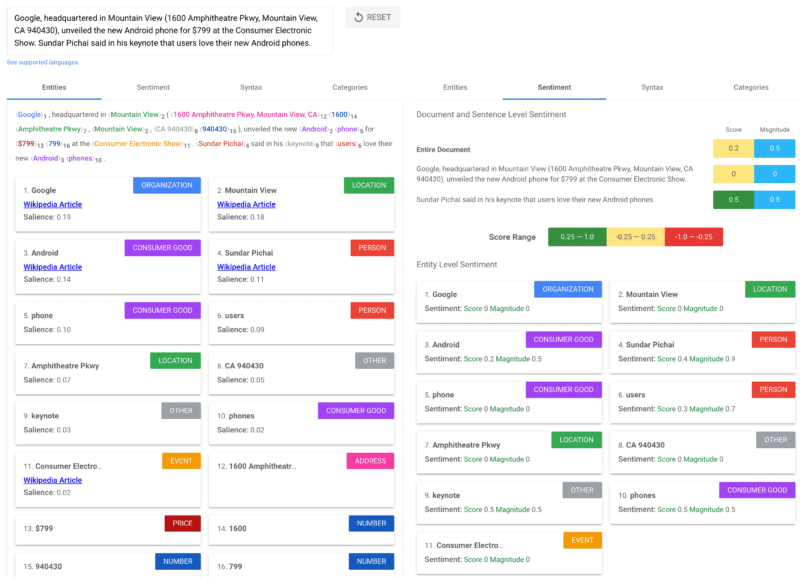
자세히 알아보려면 SEL에 관한 Timothy Warren의 기사 "Entity SEO: The definitive guide"를 읽어 보시기 바랍니다. 텍스트에서 데이터를 추출하기 위한 API 및 spaCy와 같은 오픈 소스 도구가 많이 있지만 저는 Google의 API를 사용하는 것을 선호하며 아래와 같이 텍스트의 중요한 부분을 식별하는 데모가 있습니다.
- 현저성 : 텍스트에 대한 엔터티의 중요성.
- 감정 점수 : -1부터 1까지, -1은 가장 부정적인 것, 0은 중립적인 것, 1은 가장 긍정적인 것입니다.
- 감정 크기 : 문서 내에 얼마나 많은 감정 콘텐츠가 있는지 나타냅니다.
키워드 클러스터를 대상으로 하는 콘텐츠 작가로서 바라건대 키워드 밀도를 넘어 진화했습니다. 그러나 Google이 알고 관심을 갖고 있는 항목을 올바르게 타겟팅하는지 확인하는 것은 여전히 중요합니다.
이제 우리가 Bruce Clay를 위해 글을 쓰고 있고 이 "SEO 회사" 클러스터 예제를 대상으로 하기로 결정했다고 가정해 보겠습니다. 일반적으로 작업 흐름에는 작성자가 몇 가지 중요한 페이지를 스캔한 다음 기존 페이지를 업데이트하는 작업이 포함됩니다. 엔터티를 사용하면 콘텐츠 최적화에 접근하는 새로운 방법이 있습니다. 동일한 NLP를 사용하여 매핑된 페이지에서 엔터티를 추출한 다음 클러스터 엔터티와 비교할 수 있습니다.
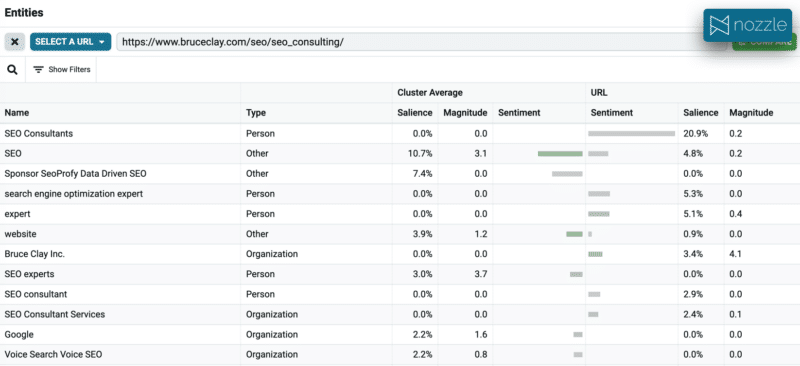
이 경우 전체 불일치가 있음이 매우 분명합니다. 비교하려는 페이지가 이미 다른 클러스터에 대해 순위가 매겨졌다고 가정하면 이는 이 클러스터를 대상으로 하는 새 콘텐츠를 만들어야 한다는 강력한 신호입니다.
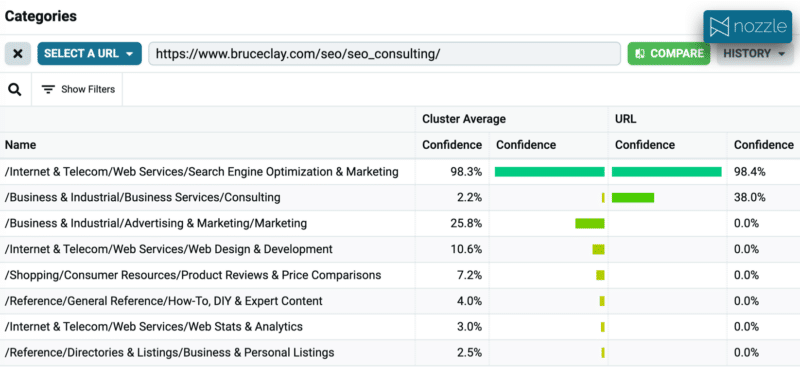
10. 콘텐츠 분류
엔터티에 대한 접근 방식과 유사하게 콘텐츠를 분류하고 클러스터와 비교하여 불일치를 식별할 수 있습니다.
Google에는 여러 언어에서 작동하는 약 1,100개의 카테고리가 포함된 분류 API가 있습니다. 당연히 SEO는 이 클러스터의 일치 URL에 대한 주요 범주이지만 범주 #4는 "제품 리뷰 및 가격 비교"입니다.
해당 신뢰 수준에서 이는 페이지에 비교 테이블을 실행하고 추가해야 한다는 의미는 아니지만 이것이 잠재 고객에게 가치를 더할 수 있는지 고려해 볼 가치가 있습니다.
결론
지금까지 이 데이터의 일부라도 보려면 서로 다른 도구를 결합해야 했습니다. 오늘 Nozzle은 이 모든 데이터를 손쉽게 사용할 수 있는 Product Hunt의 키워드 클러스터링 도구를 출시합니다. 무료로 나만의 키워드로 체험해보세요!